




一、摘要
以腾讯去年的一篇文章为引,研究自动生成小说,本文为系列的第一篇。
二、引入
前两年江湖流传很多自媒体使用机器人自动生成文章,一定程度上引起了一些讨论如:
未来,人工智能会抢走作家的“饭碗”吗 [12]
文学翻译会被人工智能取代吗 [13]
文学如何直面人工智能的“战书” [14]
最后的作家,最后的文学 [15]
事实上大多数这些文章讨论的都是套路式的文章,比如NBA比赛报告或突发新闻的描述,其写作策略是固定的,这只是一种工具而已,没有讨论价值,但最近的一些研究让我们感受到有些不一样了。
今天分享腾讯的Lili Yao写的一篇文章《Plan-and-Write: Towards Better Automatic Storytelling》,作者希望实现这样一个目标:给一个关键词,机器人就能够据此写一篇小说出来。这让我想到之前见过的一个根据图片写小说的文章和它对应的开源工程[4-5],但是根据图片生成故事和根据关键词生成故事并不是一种东西。
根据图片生成故事主要策略是先从图片中提取一组概念,然后将这组概念进行组合整理,比如[6]中是对工程结果的一些示例(为便于理解,把生成的英文翻译为中文,如果想看更多的示例可以在[6]的网站上继续欣赏):

我们能见到的是生成的故事的语言风格很厉害,但是故事几乎毫无逻辑性,基本上是各种图片元素描述的排列组合。从概念生成故事,本质上和图片提取概念后类似,但是条件从数据集变为单独的一个概念后,对模型的召回能力的要求就非常高了,而且单独的概念本身没有故事性,那么还要考虑怎么解决概念的故事性的问题。
作者在这个文章中将故事生成分成两个阶段:
生成故事规划(大纲)
基于大纲,填充故事
如下图所示即是这个过程:
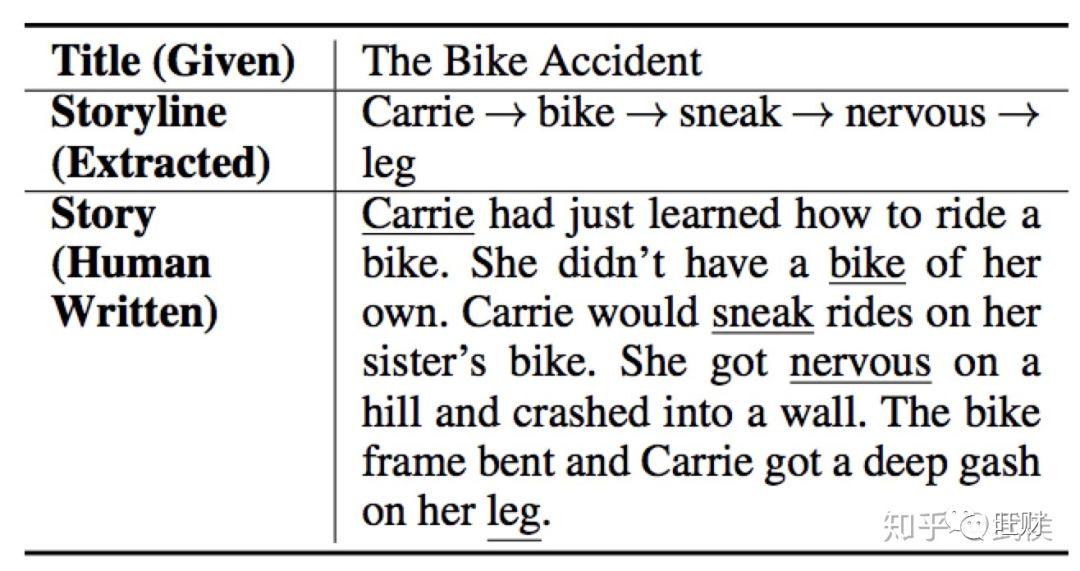
作者专门做了一个网站来展示他的系统运行起来的样子[7],大家感兴趣可以自己试一下,我这里尝试在网站输入apple后的结果:
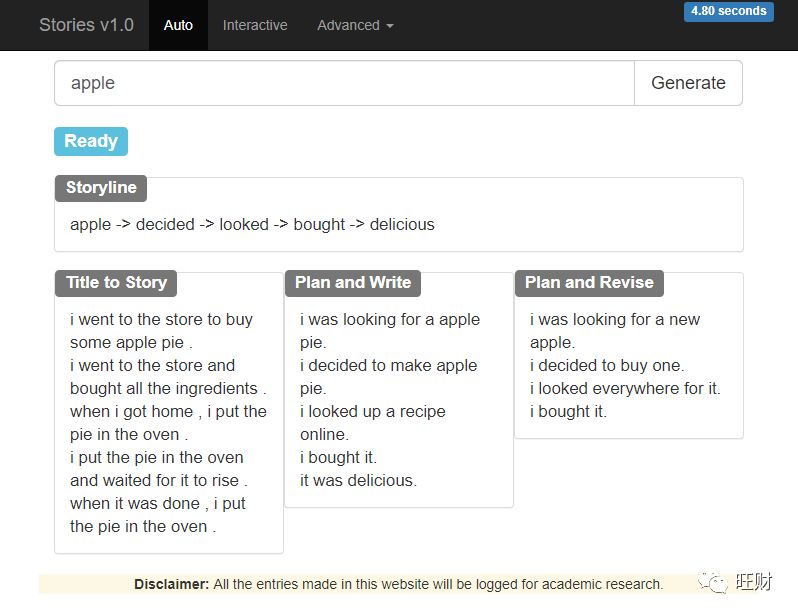
我们先关心一下作者实现这个模型的训练数据是什么样的,作者选用了ROCStories[8-9]数据集,并从这个数据集中提取了大约10w个有标题的故事,分为8:1:1用作训练、验证和测试。每个故事由5句话组成,平均每句话10个单词。这个数据集提出的时候主要用来进行二分类任务,即给定前4句话组成的一个小故事,在候选的两句话中选出更合适作为当前故事的结尾的那句。这一构建场景意味着组成故事的每句话之间的逻辑性更强,本文的作者也看中了这一点所以干脆决定用这个数据集训练出N套故事逻辑套路出来。我们从上图也能看出,所有大纲都是由5个关键词,猜测每个关键词也许对应的是训练故事集中每句话的一个主题。
这个数据集是EMNLP2016年的会议上由Mostafazadeh贡献的,基于此数据集的研究还很不少:
但并不都是用这个数据集来做故事生成的,有人用这个数据集来推理[10],有人用这个数据集来做阅读理解[11],很出名的数据集。我从论文提供的地址下载了一份数据,是两个csv文件,14M(17年)+12M(16年),本身并不大,里面的内容大体如下:
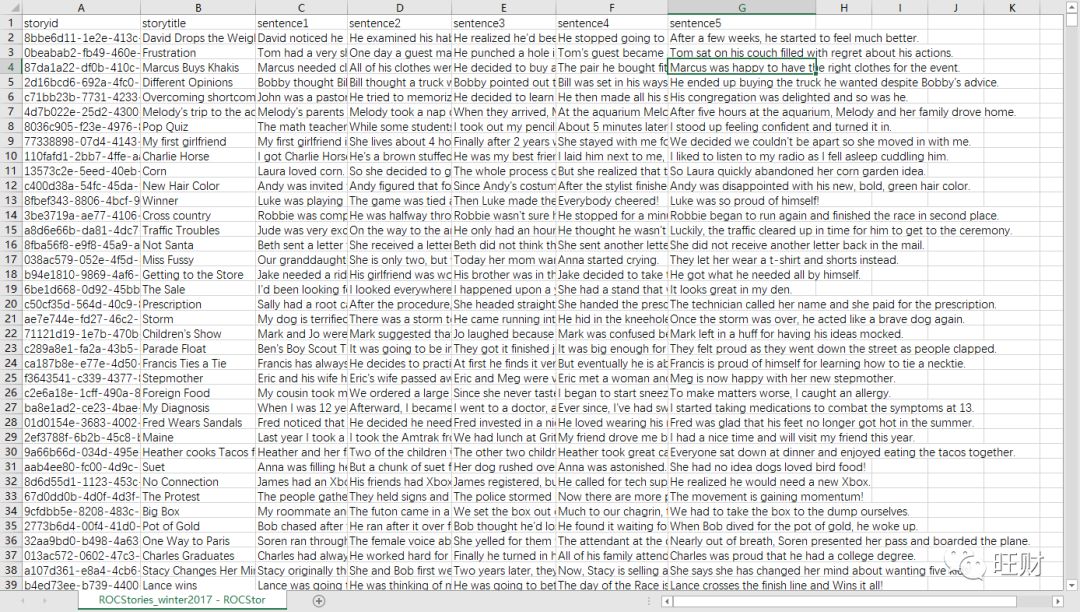
一般情况下,模型的质量超过一半都依赖于数据的质量,这个数据集的生成是作者通过Amazon Mechanical Turk找人完成的,这个平台是一个标注外包平台[16],那么这样生产的故事质量有保证吗?
Mostafazadeh首先对故事进行了定义:故事是任何以因果或逻辑关联的涉及同一批角色并以一系列事件的形式讲述的内容。并且为了根据上文来选择最后一句,作者只关心“一个真正有逻辑意义的故事的本质”,而不关心“故事有多有趣或多么戏剧化”。也就是说,这批数据集生成之初,其核心就在于“故事性”。
Mostafazadeh通过这两个文章[17-18]对“故事性”做了量化:
故事性是指,随着故事的发展,读者可能会产生问题和期望,期望是读者根据故事内容做的“常识性逻辑推理”
Mostafazadeh给写手每人提供了一个参考故事表:

并要求这些写手遵循以下要求:
实事求是
有明确的开头和结尾
不陈述任何与故事无关的东西
并且Mostafazadeh自己的团队中有三人专门负责对这个故事集的所有故事进行评分,对于不合格的故事不予录用。这些策略下就有了这份故事集,我们可以看出这样的故事集天然的存在很强的语句之间的逻辑关系。换句话说,这份数据集本身就让这个研究成功了一半。
三、本文模型
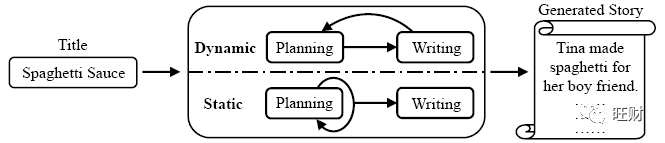
作者的整体系统如上图所示,可以看出其中最重要的部分是planning和writing,而且作者将其分为两种来进行实现,一种是动态的,一种是静态的。如下图所示,动态模型中,大纲的产生和上句话有关,静态模型中则无关。
首先作者对问题进行量化描述:
输入:标题 t={ t_1, t_2, ..., t_n } 其中 t_i 是标题中第 i 个单词
大纲:大纲 l={ l_1, l_2, ..., l_m } 其中 l_i 是一个单词,一个标题生成一个大纲
输出:故事 s={ s_1, s_2, ..., s_m } 其中 s_i 是故事中第 i 个语句,每句话对应大纲中的一个单词 l_i
【大纲提取】
大纲实际上就是作者通过对训练集故事进行训练后对每一句故事提取的主题词序列
提取大纲主要通过RAKE算法,这种算法的主要特点是对短故事和OOV的词支持较为良好。[19]
【动态模型】
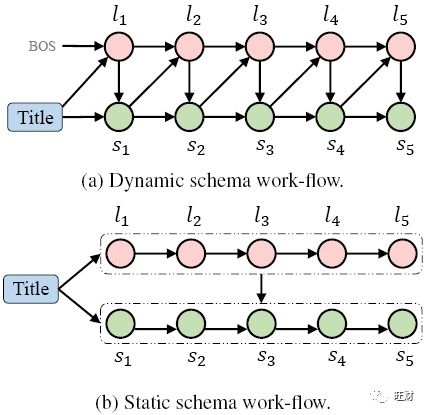
如图(a)所示,动态模型的每个步骤中生成大纲中的下一个单词和故事中的下一个句子。
大纲生成
故事情节是根据上下文(标题和前面生成的句子作为上下文)和故事情节中的前一个单词来规划的。
我们将其表示为一个内容引入生成问题,其中新内容(大纲中的下一个单词)是基于上下文和一些附加信息(大纲中的最新单词)生成的。
式中,令 ctx = [t, s_1:i-1] 表示上下文, s_1:i-1 表示故事中前 i-1 的句子。
模型可以描述为 p( l_i | ctx, l_i-1 ; θ)
我们实现了Yao等人[2017]提出的内容引入方法,该方法首先使用双向门控循环单元(BiGRU)将上下文编码成向量,然后将辅助信息(即大纲中的前一个单词)合并到解码过程中。
事实上动态模型比较类似于对话过程,而作者在这里取了个巧,将自己之前发的关于人机对话的模型[20]用在了这里。
换句话说,本文我认为其实更适合静态模型,因为一切都是围绕着大纲,可能作者一部分也是想增加一下模型复杂度吧因为单纯的大纲模型看起来有点简单
这个模型如下图所示,本质上是一个seq2seq模型的变体:
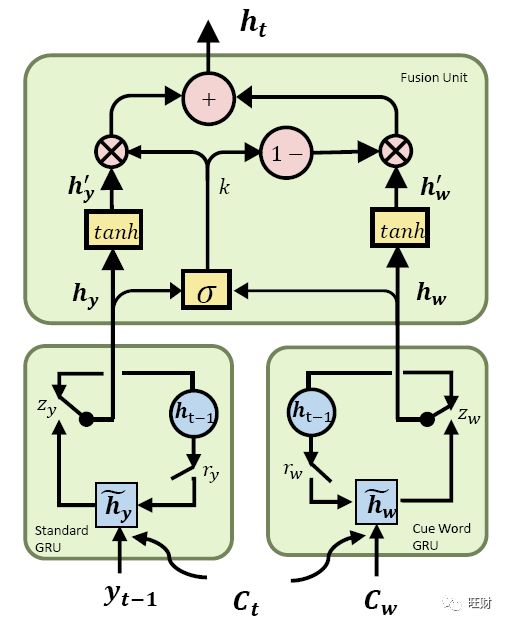
形式上,上下文的隐藏向量计算为
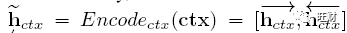
其中 <h_ctx 和 >h_ctx 分别是由正向GRU和反向GRU生成的隐藏向量。
[;]表示元素级联。
条件概率计算为:
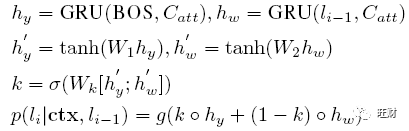
BOS表示解码的开始位置。
C_att 表示从 ~h_ctx 计算得到的基于注意力的上下文。
g()表示多层感知器(MLP)。
故事生成
故事是通过计划和写作交替进行而逐步生成的。
我们将其表示为另一个内容—引入生成问题,生成基于上下文和附加的大纲单词作为线索的故事句。
模型结构与大纲生成完全相同。
然而,故事情节和故事生成之间有两个不同之处。
一方面,前者的目标是生成一个单词,而后者生成一个可变长度的序列。
另一方面,他们使用的辅助信息是不同的。
使用负对数概率作为优化函数:
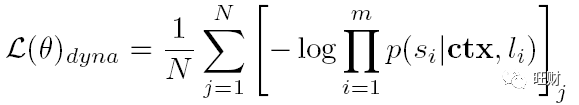
其中N为训练数据中的故事数;m表示一个故事中句子的数量。根据前一节中描述的提取的大纲,分别训练大纲和故事生成模型。端到端生成以管道方式进行。
【静态模型】
静态的灵感来自于写作者通常在充实整个故事之前画的草图,生成故事的过程中完全依赖于大纲而不依赖上一句。
这牺牲了写作的灵活性,但可能增强故事的连贯性,因为它提供了对接下来发生的事情的“展望”。
大纲生成
与动态模式不同的是,静态模式的大纲规划完全基于标题t。
我们将其表述为一个条件生成问题,其中大纲中每个单词的生成概率取决于大纲中的前一个单词和标题。
模型可以描述为 p( l_i | t, l_1:i-1 ; θ)
我们采用了一个序列到序列(Seq2Seq)的条件生成模型,该模型首先使用双向长短时记忆网络(BiLSTM)将标题编码为向量,然后使用另一个单向LSTM生成故事情节中的单词。
形式上,标题的隐藏向量~h计算为
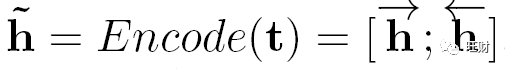
条件概率由:
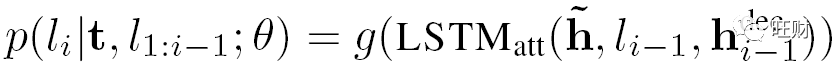
LSTM_att 对应一个有attention机制的LSTM单元
h^dec_i-1 对应的是隐藏解码器的状态单元
g() 是一个多层感知机 MLP
故事生成
故事是在计划好整个大纲之后生成的。
我们把它表示成另一个条件生成问题。
具体地说,我们训练的Seq2Seq模型编码的标题和计划中的故事情节到一个低维向量首先连接用特殊符号<EOT>之间
并与BiLSTMs编码:
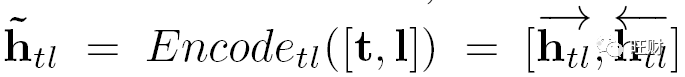
使用负对数概率作为优化函数:
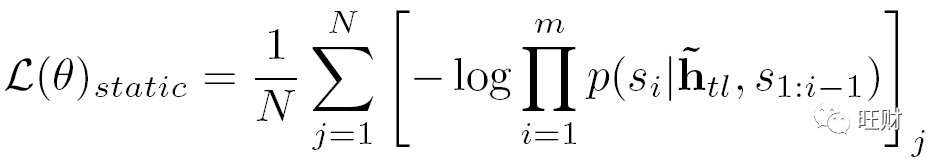
相比动态模型,静态模型看起来就容易接受多了。整个系统实际的运行测试如下:

作者的项目开源了,项目地址在[1]中有提供,感兴趣可以下载下来看一看,我这边可能因为网速问题下了很久也没下载下来,所以就不提供代码的简单分析了。
这个模型生成的故事本身有很大的局限性,其最主要的制约在:
数据集数据不够,做阅读理解可以,但做生成还是不足,可以考虑生成模型
大纲的提取和召回上,RAKE算法效率高,但是只能把原始语句中的词拿出来做主题,这意味着大纲的召回多样性会很弱
数据集本身每句话之间的逻辑关系非常强,本文产生的结果的逻辑关系多大程度上和数据集本身相关而不是因为模型对大纲的提取才导致的?
作为系列的第一篇,后面会加入其它的故事生成模型,欢迎关注。
四、参考文献
[1] Yao, L., Peng, N., Weischedel, R., Knight, K., Zhao, D., & Yan, R. (2018). Plan-And-Write: Towards Better Automatic Storytelling. ArXiv:1811.05701 [Cs]. Retrieved from http://arxiv.org/abs/1811.05701. source code: https://bitbucket.org/VioletPeng/language-model
[2] Goldfarb-Tarrant, S., Feng, H., & Peng, N. (2019). Plan, Write, and Revise: an Interactive System for Open-Domain Story Generation. ArXiv:1904.02357 [Cs]. Retrieved from http://arxiv.org/abs/1904.02357
[3] He, H., Peng, N., & Liang, P. (2019). Pun Generation with Surprise. ArXiv:1904.06828 [Cs]. Retrieved from http://arxiv.org/abs/1904.06828
[4] Gatys, L. A., Ecker, A. S., & Bethge, M. (2015). A Neural Algorithm of Artistic Style. ArXiv:1508.06576 [Cs, q-Bio]. Retrieved from http://arxiv.org/abs/1508.06576
[5] ryankiros, neural-storyteller, github, https://github.com/ryankiros/neural-storyteller
[6] Neural Artistic Captions, http://www.cs.toronto.edu/~rkiros/adv_L.html
[7] story_v1.0, http://cwc-story.isi.edu/
[8] Mostafazadeh, N.; Chambers, N.; He, X.; Parikh, D.; Batra, D.; Vanderwende, L.; Kohli, P.; and Allen, J. 2016a. A corpus and cloze evaluation for deeper understanding of commonsense stories. In NAACL.
[9] Mostafazadeh, N.; Grealish, A.; Chambers, N.; Allen, J.; and Vanderwende, L. 2016b. CaTeRS: Causal and temporal relation scheme for semantic annotation of event structures. In NAACL Workshop.
[10] Hongyu Lin, Le Sun, and Xianpei Han. Reasoning with Heterogeneous Knowledge for Commonsense Machine Comprehension. EMNLP 2017.
[11] Snigdha Chaturvedi, Haoruo Peng, and Dan Roth. Story Comprehension for Predicting What Happens Next. EMNLP 2017.
[12] 赵依雪. 未来. 人工智能会抢走作家的“饭碗”吗?[N]. 国际出版周报,2017-11-20(016).
[13] 蒋楚婷. 文学翻译会被人工智能取代吗?[N]. 文汇报,2017-06-19(W01).
[14] 黄桂元. 文学如何直面人工智能的“战书”[N]. 文艺报,2017-06-26(003).
[15] 王侃. 最后的作家,最后的文学[J].文艺争鸣,2017(10):1-3.
[16] 人工智能背后的劳工:AmazonMechanical Turk, 搜狐新闻, http://www.sohu.com/a/205355486_610498
[17] E.M. Forster. 1927. Aspects of the Novel. Edward Arnold, London.
[18] Paul Bailey. 1999. Searching for storiness: Storygeneration from a reader’s perspective. In AAAI Fall Symposium on Narrative Intelligence.
[19] Rose, S.; Engel, D.; Cramer, N.; and Cowley, W. 2010. Automatic keyword extraction from individual documents. In Text Mining: Applications and Theory.
[20] Yao, L.; Zhang, Y.; Feng, Y.; Zhao, D.; and Yan, R. 2017. Towards implicit content-introducing for generative short-text conversation systems. In EMNLP.
