zStorage
01 前言
由于硬件测试环境的限制,MR合入之前的"门禁测试"的自动化用例集中,并没有包含性能测试用例。如果不做性能验证,随着MR合入逐渐增多,一旦出现性能下降,事后再来排查则会投入更多工作量。zStorage 在MR合入之后,对每个MR做了性能测试,这是成本较低的方法,可以快速发现性能下降问题。通过合入后的MR性能测试,可以把导致性能下降的问题定位到某一个具体的MR,这样分析性能下降原因更加容易。
zStorage 的性能测试采用Jenkins自动化测试流水线,自动选择MR、编译、打包、部署、性能测试、输出性能结果。每个MR的性能测试结果,都会长期保存,以供后续分析。
zStorage
02 定位性能下降的MR
要保持性能持续上升,首先需要知道是哪个MR导致了下降。知道哪个MR下降了,先回退该MR的修改,然后责任人深挖原因,修复问题以后,再重新提MR即可。所以,zStorage 坚持每日测试新合入主干的MR的性能,形成性能走势图。
如图1所示,横坐标是时间线,纵坐标是IOPS数据,单位是千IOPS。对每天新提的MR,每晚随机选择部分MR做性能测试,这些性能测试数据会长时间保存。然后用一个自动化脚本提取性能测试结果数据,绘制出性能走势图。由于每日新增的MR可能比较多,所以一般情况下不会把每个MR都测试一次性能。比较高效的方法是选择其中部分MR,每个MR跑3~5次性能测试。这样不仅效率更高,并且通过求取平均值,使得性能结果更准确。
观察性能走势图,可以快速定位到性能出现下降和上升的区间。假设在某两个点出现了明显的下降,可以找到两个对应的MR,再把这两个MR之间的全部MR过滤出来逐一review,找出可疑的MR。当然更加简单有效的方法是,直接把这个两个MR之间的全部MR依次测试多次,精准找到导致下降的那个。
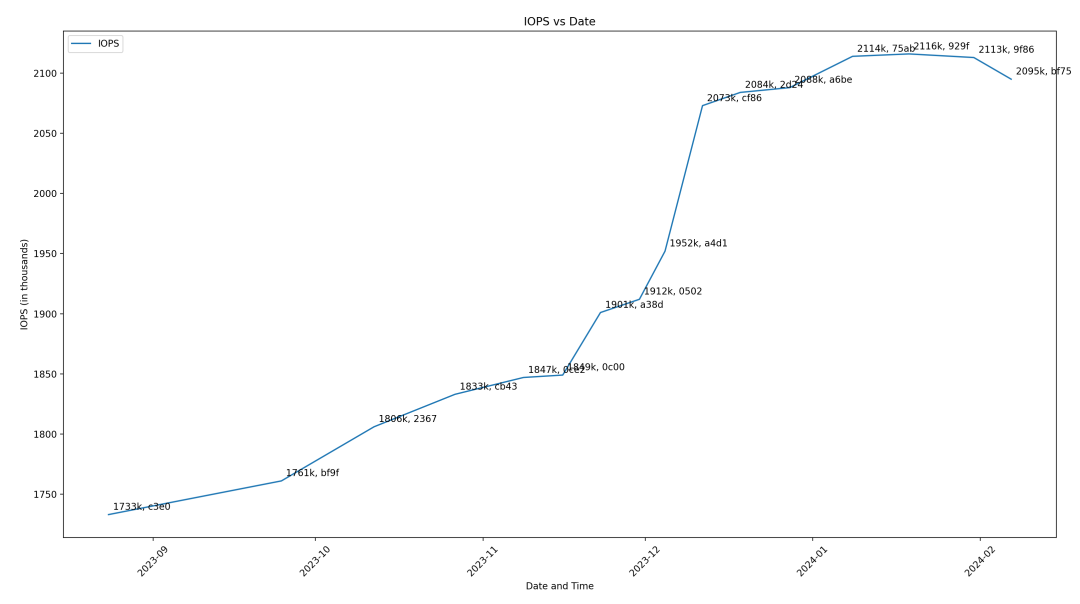
图1 性能走势
zStorage
03 优先解决性能波动大的Bug
正常情况下,zStroage 的性能测试数据波动范围在1万IOPS之内,通过3~5次测试,便可确定某个MR是否有明显的下降。如果某个Bug导致性能波动过大,例如在200万~210万IOPS之间波动,就需要通过多次测试求取平均值的方法才能摸清这个MR的真实性能,这会增加测试的时长和性能服务器的无效占用。如果不想被查找下降的MR给搞得晕头转向的话,必须先解决波动问题,否则这个波动MR之后的每个MR看起来都不正常,定位问题难度成倍增加。
zStorage
04 不要急于下结论
如果观察到某个MR性能下降,不要急于下结论,应该先进行更多测试。
如果某个MR进行了3次测试,平均性能下降了0.5万,这并不一定意味着真正的性能下降。需要等到接下来的几天里再次测试其他MR,如果连续几天性能持续下降了0.5万,那么可以基本确认是真正的性能下降。但如果后续的测试表现为性能下降后又回升了,那么很可能只是正常的波动,无需过度担心。正如图2所示,第2个位置看似下降,但实际上在第3个位置又恢复了原样。
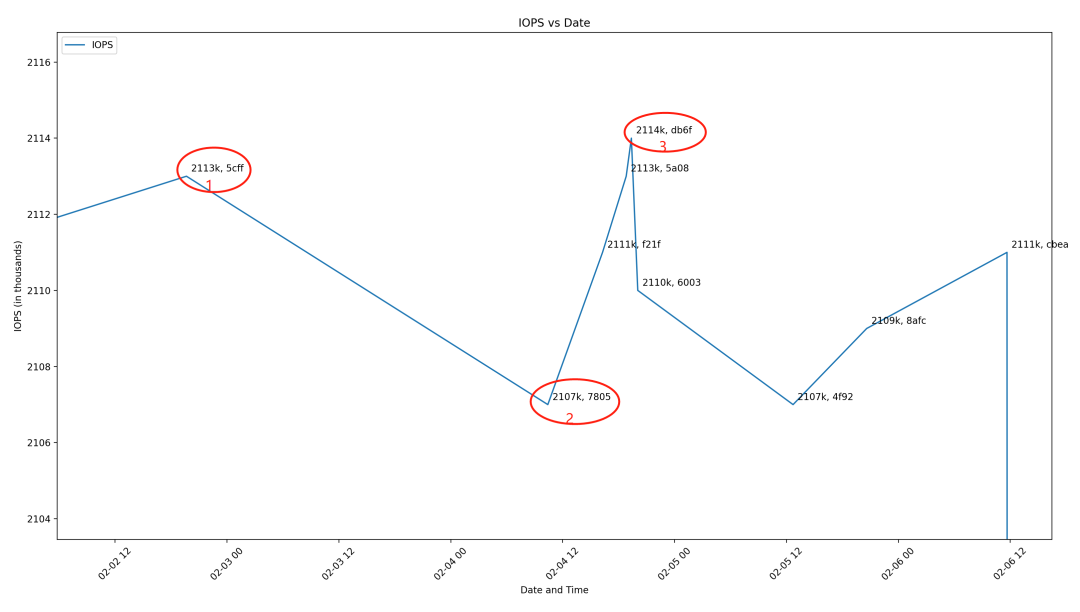
zStorage
05 避免误判
在进行性能测试之前,应该先排除常见问题,以免误判、浪费时间。zStorage 有一套检查性能测试环境的工具脚本,在每次测试之前用它做例行检查,对软硬件配置和工作状态进行确认。
如图3所示,若某个节点的IB网卡出现问题,在性能测试时可能不会立即报错,但测试结果可能会出现1%~2%或更大的性能差异。最终,通过排查,发现是IB卡降级导致的问题,如果花费很多时间去找业务代码逻辑问题,得不偿失。图3中列出了两项检查内容:一是确认存储节点的硬盘数量是否足够,另一是检查IB网卡的状态是否正常。图中显示的IB网卡状态均为正常。异常情况可能包括降级(downgrade)、不可用(inactive)等情况。除了图中所列的检查项外,还有许多其他检查内容未在图中列出。
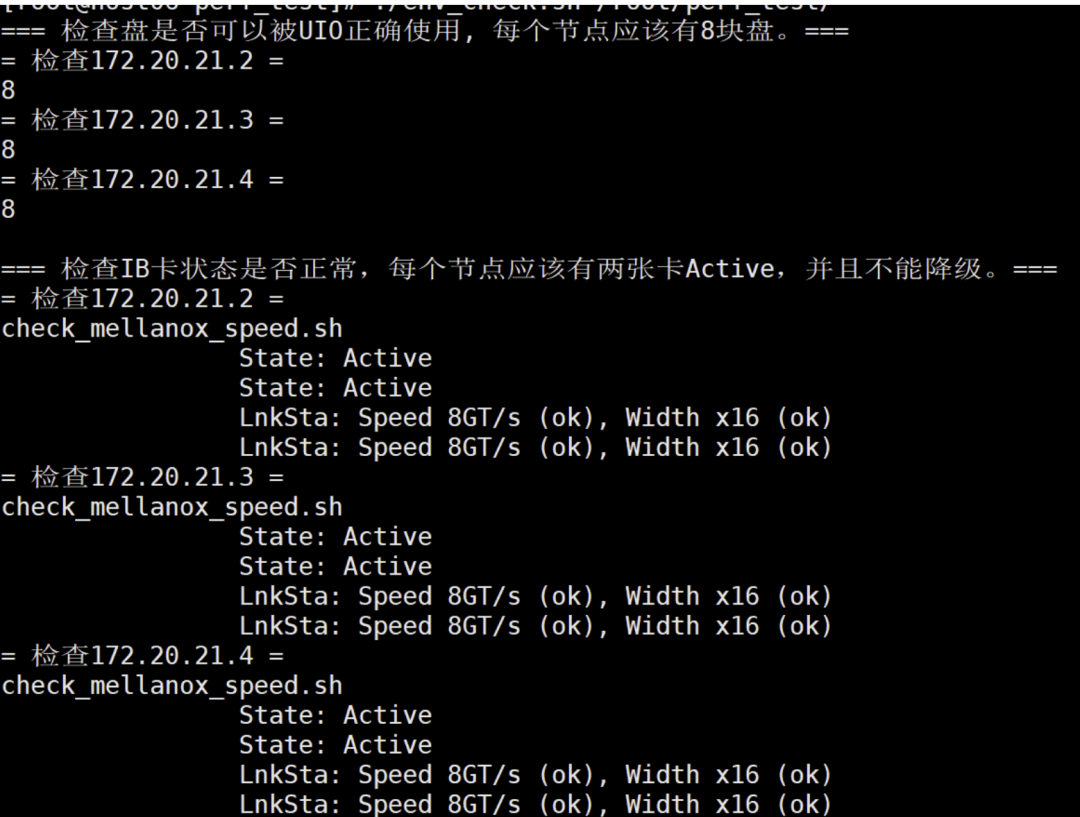
zStorage
06 比较火焰图
火焰图能够清晰地展示哪些函数、哪些流程消耗了大量的CPU资源。通过比较不同MR的火焰图,可以生成它们的差分火焰图。在差分火焰图上,颜色越红的地方表示相应部分的CPU占用增加越多。如果某个MR出现了性能问题,用这个MR的数据跟正常版本比较,生成差分火焰图,更容易发现问题函数。
除了观察CPU占用外,火焰图还可用于观察缓存未命中等指标。
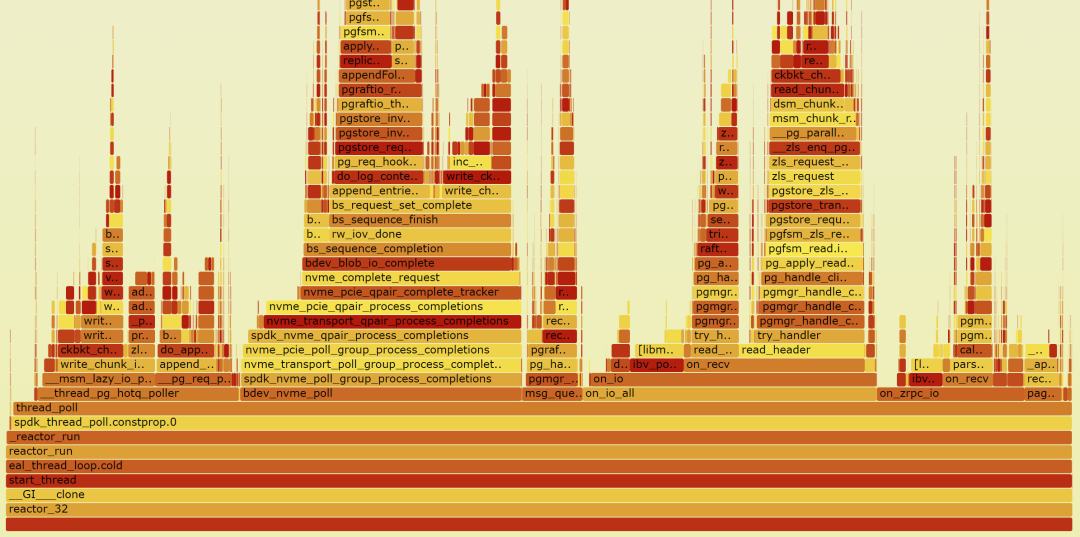
图4 火焰图

图5 差分火焰图
zStorage
07 时延分析和对比
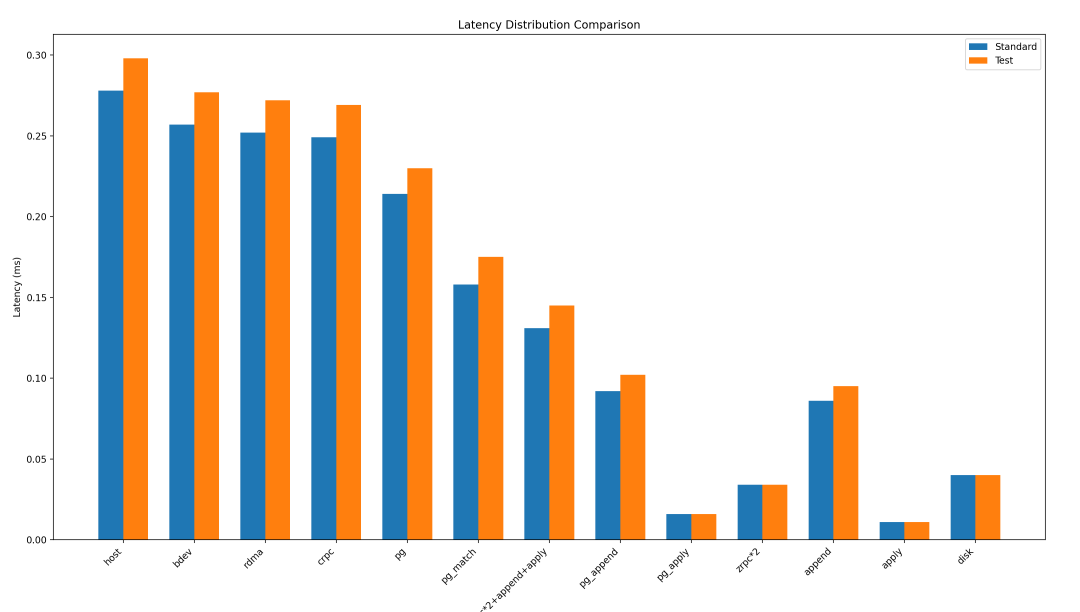
zStorage 内置了点位时延分析工具(zTrace),能够详细分析出一个IO请求在某个模块中的耗时情况。如图6所示,对比了两个MR的各个点位的时延情况,其中蓝色表示标准时延(性能正常的MR),而红色表示性能异常的MR。可以清晰地观察到在许多点位上,红色柱子的高度明显高于蓝色柱子。通过这种方式,可以准确定位是哪个模块导致了性能下降和时延增加。从图6中可以看出,本地存储模块的append点位时延增加,导致后续所有点位的时延逐步增加。这一情况非常明显地表明append点位存在问题,从而引发了性能下降。
zStorage
08 持续努力
性能调优如逆水行舟,不进则退,因此需要不断寻找新的优化点。
随着特性MR的不断合入,代码量不断增加,性能就会逐渐下降。但是,只要我们能够持续地发现新的优化点,使性能提升的速度超过下降的速度,那么一些积累的微小性能下降也不会构成重大威胁。如图7所示,只有通过不断寻找新的优化点,性能才能够持续提升。

zStorage
09 总结
关于 zStorage
zStorage 是云和恩墨针对数据库应用开发的高性能全闪分布式块存储。三节点 zStorage 集群可以达到210万IOPS随机读写性能,同时平均时延<300μs、P99时延小于800μs。
zStorage 支持多存储池、精简配置、快照/一致性组快照、链接克隆/完整克隆、NVMeoF/NVMeoTCP、iSCSI、CLI和API管理、快照差异位图(DCL)、慢盘检测、亚健康管理、16KB原子写、2副本、强一致3副本、Raft 3副本、IB和RoCE、TCP/IP、后台巡检、基于Merkle树的一致性校验、全流程TRIM、QoS、SCSI PR、SCSI CAW。
zStorage 是一个存储平台,可作为数据库产品和存储产品的底座。欢迎发邮件至 marketing@enmotech.com 咨询。
关于作者

数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,以“数据驱动,成就未来”为使命,是智能的数据技术提供商。我们致力于将数据技术带给每个行业、每个组织、每个人,构建数据驱动的智能未来。
云和恩墨在数据承载(分布式存储、数据持续保护)、管理(数据库基础软件、数据库云管平台、数据技术服务)、加工(应用开发质量管控、数据模型管控、数字化转型咨询)和应用(数据服务化管理平台、数据智能分析处理、隐私计算)等领域为各个组织提供可信赖的产品、服务和解决方案,围绕用户需求,持续为客户创造价值,激发数据潜能,为成就未来敏捷高效的数字世界而不懈努力。