




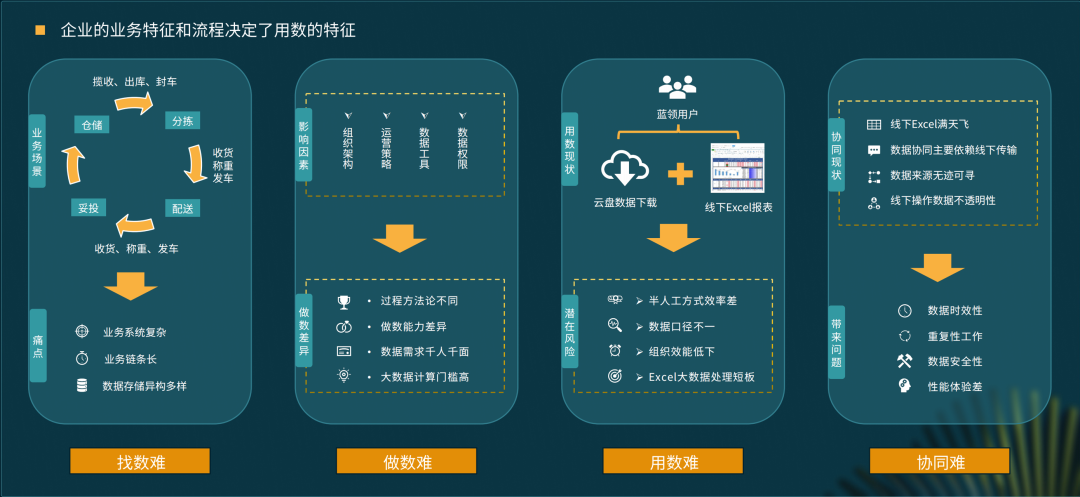
京东物流的用数特征和痛点
01
01
02
02
03
03
整个过程中有很多半人工方式,效率非常低;
每个省区的数据来源都不一致,可能会导致数据口径不统一;
Excel 对于大数据的处理能力有很多缺陷;
04
04
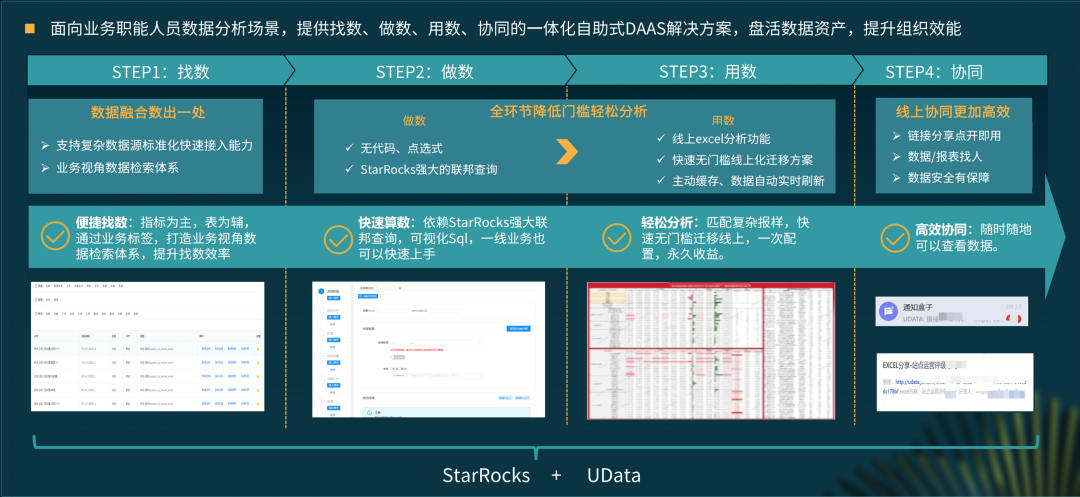
基于 StarRocks 的解决方案
数据服务:当数据通过 SQL 方式提供对外赋能时,SQL 比较固化,查询场景也比较固定;
数据分析:类似 Ad-hoc 查询,用户进行数据探索;
01
01
02
02

Udata 数据分析平台
01
01
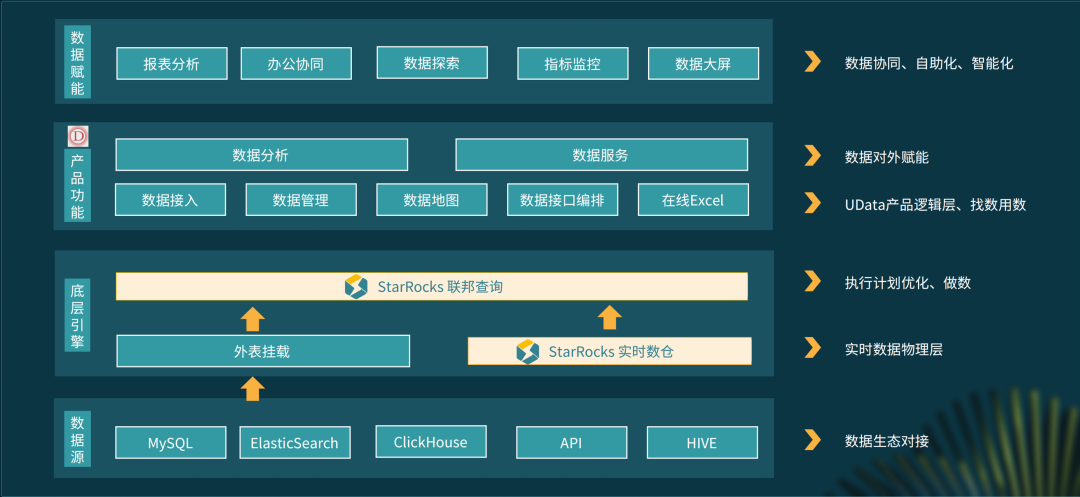
StarRocks 实时数仓,应用了 StarRocks 的数据快速摄入能力和高性能的数据查询能力。
基于 StarRocks 打造的联邦查询,实现各种数据源跨数据源跨集群的查询,只要数据接入到系统就能进行查询。
02
02
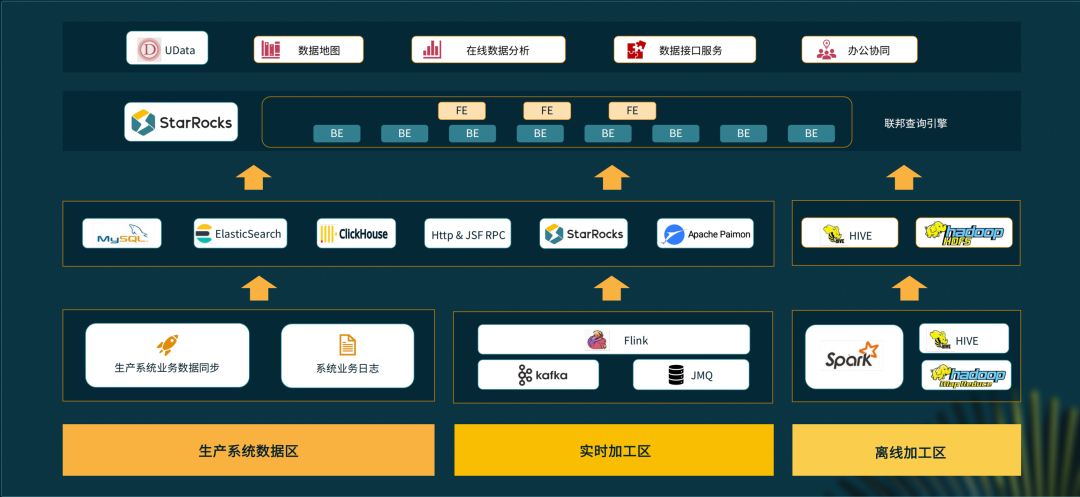
最下层左侧是生产系统数据区;中间是实时数据加工区,通过 Flink 接收众多系统接入的消息队列消息,然后加工到 OLAP 层;右侧是离线加工区,京东有很多历史数据都存在 Hadoop 里,我们会通过 Spark、Hive 来加工,存到 HDFS、Hive 里。
往上一层是 OLAP 层,包含 MySQL、Elasticsearch、ClickHouse 等数据库,另外还有 StarRocks、Paimon。右则是离线区,采用了 Hive 和 HDFS。
再往上是采用 StarRocks 搭建的一个支持超级联邦查询的集群引擎。
最上层是 Udata 对外赋能提供的能力,包括数据地图、在线分析、数据服务、办公协同等。
为什么选择 StarRocks
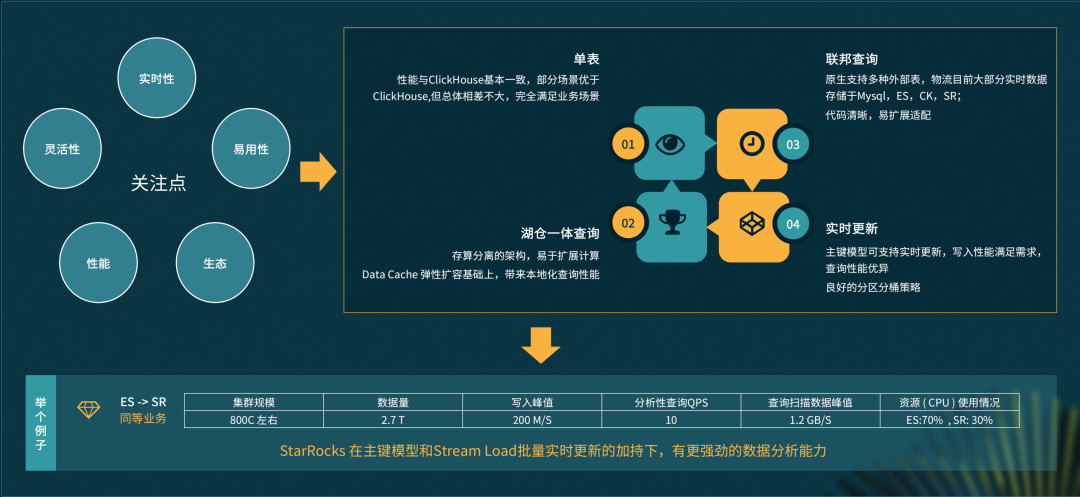
StarRocks 的性能提升优化和效果
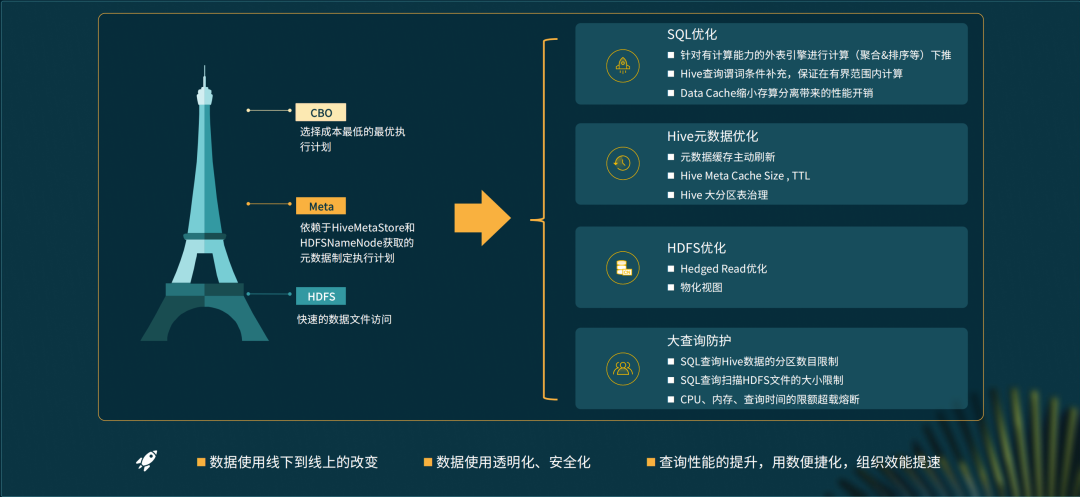
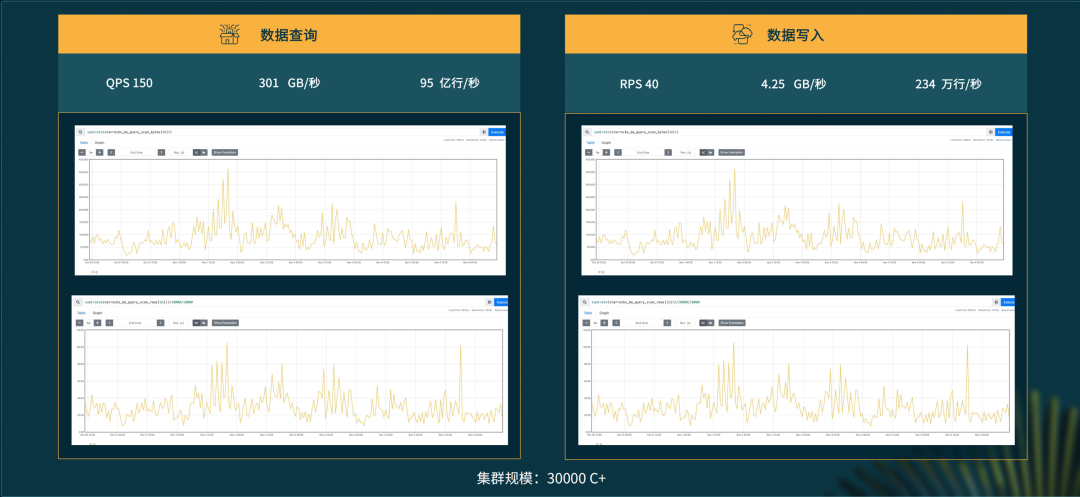
01
01
02
02
03
03
04
04
05
05
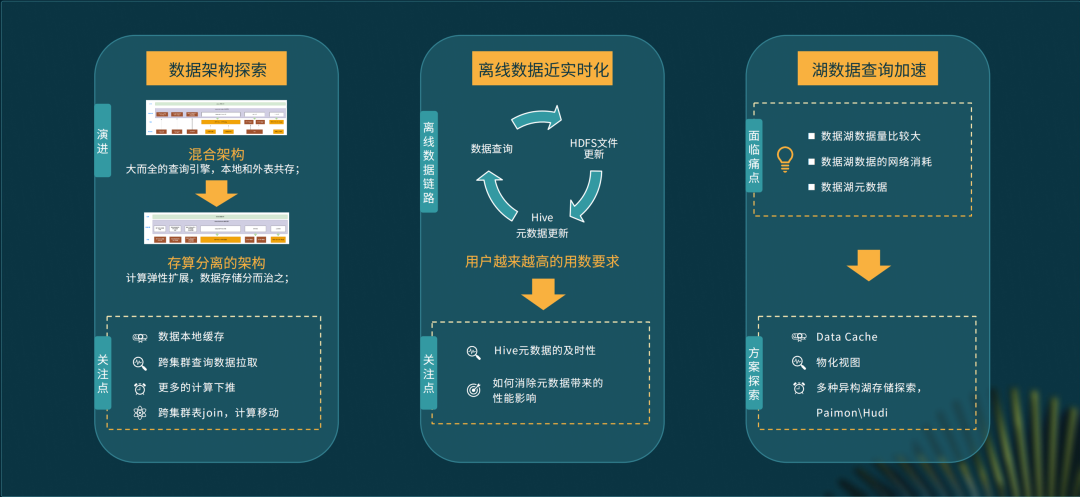
未来规划探索
01
01
02
02
03
03
关于 StarRocks


文章转载自锋哥聊DORIS数仓,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
