




最近某业务需要用到Doris冷热分离的功能,为了方便后续的问题定位以及性能调优,笔者梳理了Doris冷热分离功能的内核原理,并在梳理过程中发现若干优化点,并贡献给了社区
需求场景
在数据分析的实际场景中,冷热数据往往面临着不同的查询频次及响应速度要求。例如在日志分析场景中,历史数据的访问频次很低,但需长时间备份以保证后续的审计和回溯的工作;在行为分析场景中,需支持近期流量数据的高频查询且时效性要求高,但为了保证历史数据随时可查,往往要求数据保存周期更为久远;往往历史数据的应用价值会随着时间推移而降低,且需要应对的查询需求也会随之锐减。而随着历史数据的不断增多,如果我们将所有数据存储在本地,将造成大量的资源浪费。
为了解决满足以上问题,冷热数据分层技术应运而生,以更好满足企业降本增效的趋势。顾名思义,冷热分层是将冷热数据分别存储在成本不同的存储介质上,例如热数据存储在成本更高的 SSD 盘上、以提高时效数据的查询速度和响应能力,而冷数据则存储在相对低成本的 HDD 盘甚至更为廉价的对象存储上,以降低存储成本。Doris还可以根据实际业务需求进行灵活的配置和调整,以满足不同场景的要求。
冷热分层一般适用于以下需求场景:
• 数据存储周期长:面对历史数据的不断增加,存储成本也随之增加;
• 冷热数据访问频率及性能要求不同:热数据访问频率高且需要快速响应,而冷数据访问频率低且响应速度要求不高;
• 数据备份和恢复成本高:备份和恢复大量数据需要消耗大量的时间和资源。
• ......
在 Apache Doris 2.0 版本中支持三级存储,分别是 SSD、HDD 和对象存储。用户可以配置使数据从 SSD 下沉到 HDD,并使用冷热分层功能将数据从 SSD 或者 HDD 下沉到对象存储中。
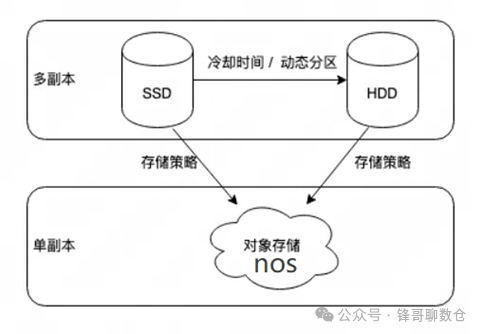
由于使用HDD 盘做冷热分离的数据处理逻辑与SSD盘相同,故本文本文将主要介绍基于对象存储的冷热分层。
如何使用
若要使用Doris 的冷热分层功能,首先需要准备一个对象存储的 Bucket 并获取对应的 AK/SK。目前支持 AWS、Azure、阿里云、华为云、腾讯云、百度云等多个云的对象存储。对应我们公司内部,可以选择nos作为对象存储,笔者的测试见:Doris & nos 冷热存储分离测试。当准备就绪之后,下面为具体的使用步骤:
1. 创建 Resource
可以使用对象存储的 Bucket 以及 AK/SK 创建 Resource。
CREATE RESOURCE IF NOT EXISTS "${resource_name}"
PROPERTIES(
"type"="s3",
"s3.endpoint" = "${S3Endpoint}",
"s3.region" = "${S3Region}",
"s3.root.path" = "path/to/root",
"s3.access_key" = "${S3AK}",
"s3.secret_key" = "${S3SK}",
"s3.connection.maximum" = "50",
"s3.connection.request.timeout" = "3000",
"s3.connection.timeout" = "1000",
"s3.bucket" = "${S3BucketName}"
);
2. 创建 Storage Policy
可以通过 Storage Policy 控制数据冷却时间,目前支持相对和绝对两种冷却时间的设置。
CREATE STORAGE POLICY testPolicy
PROPERTIES(
"storage_resource" = "remote_s3",
"cooldown_ttl" = "1d"
);
例如上方代码中名为 testPolicy
的 storage policy
设置了新导入的数据将在一天后开始冷却,并且冷却后的冷数据会存放到 remote_s3
所表示的对象存储的 root path
下。除了设置 TTL 以外,在 Policy 中也支持设置冷却的时间点,可以直接设置为:
CREATE STORAGE POLICY testPolicyForTTlDatatime
PROPERTIES(
"storage_resource" = "remote_s3",
"cooldown_datetime" = "2023-06-07 21:00:00"
);
3. 给表或者分区设置 Storage Policy
在创建出对应的 Resource 和 Storage Policy 之后,我们可以在建表的时候对整张表设置 Cooldown Policy,也可以针对某个 Partition 设置 Cooldown Policy。这里以 TPCH 测试数据集中的 lineitem 表举例。如果需要将整张表都设置冷却的策略,则可以直接在整张表的 properties 中设置:
CREATE TABLE IF NOT EXISTS lineitem1 (
L_ORDERKEY INTEGER NOT NULL,
L_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATEV2 NOT NULL,
L_COMMITDATE DATEV2 NOT NULL,
L_RECEIPTDATE DATEV2 NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)
PARTITION BY RANGE(`L_SHIPDATE`)
(
PARTITION `p202301` VALUES LESS THAN ("2017-02-01"),
PARTITION `p202302` VALUES LESS THAN ("2017-03-01")
)
DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3
PROPERTIES (
"replication_num" = "3",
"storage_policy" = "${policy_name}"
)
也可以对某个具体的 Partition 设置 Storage Policy,只需要在 Partition 的 Properties 中加上具体的 Policy Name 即可
4. 查看数据信息
一般可以通过 show tablets from lineitem1
直接查看这张表的 Tablet 信息。Tablet 信息中区分了 LocalDataSize 和 RemoteDataSize,前者表示存储在本地的数据,后者表示已经冷却并移动到对象存储上的数据。
下方为数据刚导入到 BE 时的数据信息,可以看到数据还全部存储在本地。
*************************** 1. row ***************************
TabletId: 2749703
ReplicaId: 2749704
BackendId: 10090
SchemaHash: 1159194262
Version: 3
LstSuccessVersion: 3
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 73001235
RemoteDataSize: 0
RowCount: 1996567
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 3
QueryHits: 0
PathHash: -8567514893400420464
MetaUrl: http://***.16.0.8:6781/api/meta/header/2749703
CompactionStatus: http://***.16.0.8:6781/api/compaction/show?tablet_id=2749703
CooldownReplicaId: 2749704
CooldownMetaId:
当数据到达冷却时间后,再次进行 show tablets from table
可以看到对应的数据变化。
*************************** 1. row ***************************
TabletId: 2749703
ReplicaId: 2749704
BackendId: 10090
SchemaHash: 1159194262
Version: 3
LstSuccessVersion: 3
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 0
RemoteDataSize: 73001235
RowCount: 1996567
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 3
QueryHits: 0
PathHash: -8567514893400420464
MetaUrl: http://***.16.0.8:6781/api/meta/header/2749703
CompactionStatus: http://***.16.0.8:6781/api/compaction/show?tablet_id=2749703
CooldownReplicaId: 2749704
CooldownMetaId: TUniqueId(hi:-8697097432131255833, lo:9213158865768502666)
冷热分层技术的具体实现
存储结构
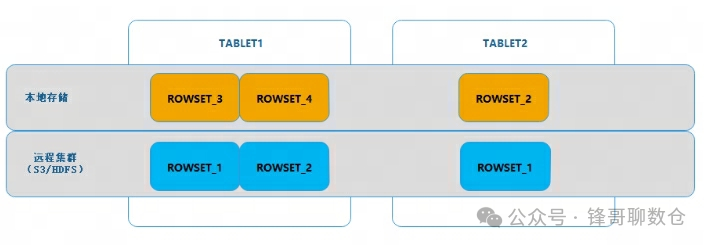
从上一篇文章:Apache Doris入门10问, 可以知道,BE在存储TABLET数据的时候,TABLET下面还会有ROWSET和SEGMENT的划分。其中ROWSET代表着数据导入批次,同一个ROWSET一般代表着一个批次的导入任务,比如一次stream load,一个begin/commit事务等,都对应一个ROWSET。ROWSET的这种特性,意味着其具有着事务的特点,即是说,同一个ROWSET可以作为一个独立的数据单元存在,其中的数据要么全部有效,要么全部无效。
正因为如此,以ROWSET为基本单元对数据进行冷热转换,可以更容易的解决冷热数据迁移过程中有新数据写入的问题。
如下图所示,对于进入冷热数据转换状态的TABLET,其ROWSET被分成两部分:
• 一部分在本地,这部分数据往往是新写入的数据,还未触发上传操作。
• 另一部分在远程存储集群(S3),这部分数据相对较早,是在此前已经触发上传到了存储集群上的数据。
两部分合在一起才是完整的一个TABLET。
那么冷数据是何时以及如何上传到对象存储的呢?
冷热分层
Doris通过BE的后台线程:cooldown_tasks_producer_thread,对本BE的所有存活的TABLET进行遍历,检查每个TABLET的配置信息。当发现该TABLET配置了storage_policy,说明需要对其进行冷热数据转换。根据storage_policy中的配置,BE将从缓存信息中的StoragePolicy列表中获取对应的规则信息,然后根据这个规则,判断当前tablet是否需要进行冷热数据转换,将数据存放于远程存储集群上(如S3)。
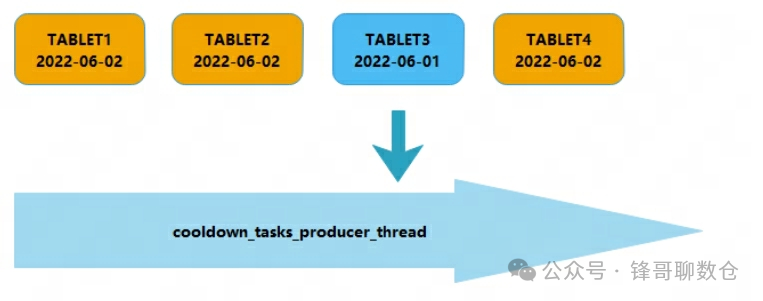
到这里,先思考一个问题:具体的数据转冷是怎么实现的呢?直接将冷数据拷贝到S3,然后删除本地文件就可以了嘛?
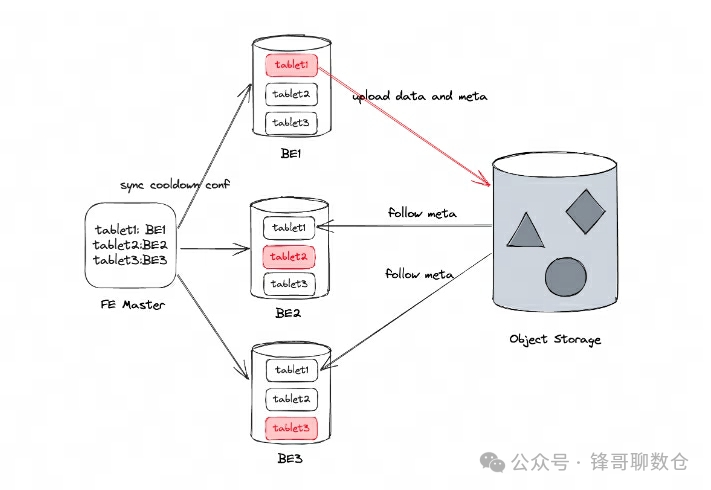
答案是否定的。这里不仅仅需要拷贝数据,还需要协调处理Be的元数据。因为BE之间的tablet副本,rowset id不同,compaction merge进度不同。Leader 上传完meta数据以后,slave副本就需要有办法去同步这个meta以完成冷却腾出本地盘的空间。具体的实现流程如下:
Doris 的 FE 会从 Tablet 的所有可用本地副本中选择一个本地副本作为上传数据的 Leader,并通过 Doris 的周期汇报机制同步 Leader 的信息给其它本地副本。在 Leader 上传冷却数据时,也会将冷却数据的元数据上传到对象存储,以便其他副本同步元数据。因此,任何本地副本都可以提供查询所需的数据,同时也保证了数据的高可用性和可靠性。
介绍完了原理,这里介绍下源码分析。
首先Be启动的时候,会基于线程池,创建一系列后台线程:
1. 冷热数据转换后台线程
2. 无效冷数据清理线程
3. 冷数据compaction线程
StorageEngine::start_bg_threads
|--> ThreadPoolBuilder("CooldownTaskThreadPool")
.set_min_threads(config::cooldown_thread_num)
.set_max_threads(config::cooldown_thread_num)
.build(&_cooldown_thread_pool);
|--> //冷热数据转换后台线程
|--> Thread::create(_cooldown_tasks_producer_callback(), _cooldown_tasks_producer_thread)
|--> //无效冷数据清理线程
|--> Thread::create(_remove_unused_remote_files_callback(), _remove_unused_remote_files_thread)
|--> //冷数据compaction线程
|--> Thread::create(_cold_data_compaction_producer_callback(), _cold_data_compaction_producer_thread)
该章节主要介绍冷热数据转换后台线程的实现:
_cooldown_tasks_producer_callback()
|--> /*dead loop*/
|--> //将所有需要转冷的tablet维护到tablets
|--> _tablet_manager->get_cooldown_tablets(&tablets, std::move(skip_tablet));
| |--> /*loop*/
| |--> get_cooldown_tablet
| | |--> //skip all the tablets which are not running
| | |--> //and those pending to do cooldown
| | |--> skip_tablet
| | |--> tablet->need_cooldown(Tablet::need_cooldown)
| | | |--> //判断是否有对应的storage_policy
| | | |--> get_storage_policy(id)
| | | |--> //We pick the rowset with smallest start version in local
| | | |--> //查找当前tablet最小版本号的rowset
| | | |--> Tablet::pick_cooldown_rowset
| | | | |--> /*loop for _rs_version_map with lock*/
| | | | |--> if (v.first < min_local_version) rowset = rs;
| | | | |--> /*end loop for _rs_version_map*/
| | | |--> //根据rowset判断是否符合转冷时间
| | | |--> if (newest_cooldown_time > UnixSeconds()) return;
| |--> /*end loop*/
|
|--> //遍历上个步骤获取到的tablets
|--> /*loop for tablets*/
|--> _running_cooldown_tablets.insert(tablet->tablet_id());
|--> _cooldown_thread_pool->offer(std::move(task));
| |--> task.work_function()
| | |--> tablet->cooldown()(Tablet::cooldown())
| | | |--> //对于主副本,执行数据传输工作
| | | |--> //if _cooldown_replica_id == replica_id()
| | | |--> //这里是数据转冷最核心的逻辑
| | | |--> _cooldown_data
| | | | |--> //拿到S3的一些句柄信息
| | | | |--> get_remote_file_system
| | | | |--> old_rowset = pick_cooldown_rowset
| | | | | |--> /*loop for _rs_version_map with lock*/
| | | | | |--> if (v.first < min_local_version) rowset = rs;
| | | | | |--> /*end loop for _rs_version_map*/
| | | | |--> //将rowset数据按照new_rowset_id传输到S3
| | | | |--> old_rowset->upload_to(BetaRowset::upload_to)
| | | | | |--> RemoteFileSystem::batch_upload
| | | | | | |--> S3FileSystem::batch_upload_impl
| | | | | | | |--> transfer_manager->UploadFile
| | | | |--> //根据new_rowset_id以及刚刚上传的远程目录,生成新的rowset rowset_meta
| | | | |--> new_rowset_meta = std::make_shared<RowsetMeta>(*old_rowset->rowset_meta());
| | | | |--> RowsetFactory::create_rowset(new_rowset_meta)
| | | | |--> //删除旧的rowsets
| | | | |--> delete_rowsets({std::move(old_rowset)}, false);
| | | | |--> //添加新的rowsets
| | | | |--> add_rowsets({std::move(new_rowset)});
| | | | |--> //将meta信息保存在本地
| | | | |--> Tablet::save_meta
| | | | | |--> TabletMeta::save_meta
| | | | | | |--> //本质是将pb存在rockdb,其中_db是一个rockdb实例
| | | | | | |--> TabletMetaManager::save
| | | | | | | |--> _db->Put
| | | | |--> //将rowset_meta数据写到S3
| | | | |--> //meta主要的信息是数据在s3上的路径
| | | | |--> //上传的不是一整个meta数据库,而是tablet粒度的
| | | | |--> async_write_cooldown_meta
| | | | | |--> write_cooldown_meta
| | | |--> //else
| | | |--> //对于从副本,需要同步元数据
| | | |--> //因为be之间的tablet副本,rowset id不同,compaction merge进度不同
| | | |--> //主副本自己冷却的数据自己是知道冷数据路径的,并且也会更新meta持久化在rocksdb
| | | |--> //从副本就需要有办法去同步这个meta以完成冷却腾出本地盘的空间
| | | |--> _follow_cooldowned_data
| | | | |--> get_remote_file_system
| | | | |--> //从S3上读取meta信息
| | | | |--> _read_cooldown_meta(fs, &cooldown_meta_pb)
| | | | | |--> //创建远程文件句柄
| | | | | |--> fs->open_file(remote_meta_path, &tablet_meta_reader)
| | | | | |--> //将远程meta信息读到buf
| | | | | |--> tablet_meta_reader->read_at(buf,file_size)
| | | | | |--> //将buf的数据反序列化到tablet_meta_pb
| | | | | |--> tablet_meta_pb->ParseFromArray(buf.get(), file_size)
| | | | |--> //从副本的tablet meta需要跟S3上的保持一致,所以需要看下哪些rowset需要删除
| | | | |--> to_delete(rs_it, overlap_rowsets.end());
| | | | |--> //从副本的tablet meta需要跟S3上的保持一致,所以需要看下哪些rowset需要加进去
| | | | |--> add_rowsets(to_add)
| | | | |--> _tablet_meta->set_cooldown_meta_id
| | | | |--> //将新的meta信息进行本地持久化
| | | | |--> save_meta();
| | | |--> //end
冷数据Compaction
在一些场景下会有大量修补数据的需求,在大量补数据的场景下往往需要删除历史数据,删除可以通过 delete where
实现,Doris 在 Compaction 时会对符合删除条件的数据做物理删除。基于这些场景,冷热分层也必须实现对冷数据进行 Compaction,因此在 Doris 2.0 版本中支持了对冷却到对象存储的冷数据进行 Compaction(ColdDataCompaction)的能力,用户可以通过冷数据 Compaction,将分散的冷数据重新组织并压缩成更紧凑的格式,从而减少存储空间的占用,提高存储效率。
Doris 对于本地副本是各自进行 Compaction,这其实是有一些资源浪费的,理论上可以优化为单副本Compaction。在冷热分层场景中,由于冷数据只有一份,因此天然的单副本做 Compaction 是最优秀方案,同时也会简化处理数据冲突的操作。BE 后台线程会定期从冷却的 Tablet 按照一定规则选出 N 个 Tablet 发起 ColdDataCompaction。与数据冷却流程类似,只有 CooldownReplica 能执行该 Tablet 的 ColdDataCompaction。Compaction 下刷数据时每积累一定大小(默认 5MB)的数据,就会上传一个 Part 到对象,而不会占用大量本地存储空间。Compaction 完成后,CooldownReplica 将冷却数据的元数据更新到对象存储,其他 Replica 只需从对象存储同步元数据,从而大量减少对象存储的 IO 和节点自身的 CPU 开销。
_cold_data_compaction_producer_callback
|--> /*dead loop*/
|--> //在锁保护下,保证任务数小于compaction线程数
|--> //cold_data_compaction_thread_num表示冷数据compaction线程数
|--> //copied_tablet_submittedsize()表示正在执行compaction的tablet数
|--> if(cold_data_compaction_thread_num<copied_tablet_submitted.size()) continue
|--> //从冷却的Tablet中按照一定规则选出tablets
|--> tablets = _tablet_manager->get_all_tablet
|--> /*loop for tablets*/
|--> //对于master 副本,将tablet以及对于的compaction score维护到compact任务队列
|--> tablet_to_compact.emplace_back(t, score);
|--> //对于slave 副本,维护到follow任务队列
|--> tablet_to_follow.emplace_back(t, score)
|--> /*end loop for tablets*/
|
|--> /*loop for tablet_to_compact*/
|--> //将compaction任务丢到线程池
|--> _cold_data_compaction_thread_pool->submit_func
| |--> compaction->compact()-->ColdDataCompaction::compact()
| | |--> ColdDataCompaction::prepare_compact
| | | |--> ColdDataCompaction::pick_rowsets_to_compact
| | | | |--> _tablet->traverse_rowsets
| | | | |--> check_version_continuity
| | |--> ColdDataCompaction::execute_compact_impl
| | | |--> Compaction::do_compaction
| | | | |--> Compaction::do_compaction_impl
|--> /*end loop for tablet_to_compact*/
|
|--> /*loop for tablet_to_follow*/
|--> //将follow任务丢到线程池
|--> _cold_data_compaction_thread_pool->submit_func
| |--> //这里只是复用了函数,实际上不会执行数据cooldown,只会拉取元数据
| |--> Tablet::cooldown
| | |--> _follow_cooldowned_data()
冷数据Cache
假设 Table Lineitem1 中的所有数据都已经冷却并且上传到对象存储中,如果用户在 Lineitem1 上进行对应的查询,Doris 会根据对应 Partition 使用的 Policy 信息找到对应的 Bucket 的 Root Path,并根据不同 Tablet 下的 Rowset 信息下载查询所需的数据到本地进行运算。
Doris 2.0 在查询上进行了优化,冷数据第一次查询会进行完整的 S3 网络 IO,并将 Remote Rowset 的数据下载到本地后,存放到对应的 Cache 之中,后续的查询将自动命中 Cache,以此来保证查询效率。
而 Cache 的粒度大小直接影响 Cache 的效率,比较大的粒度会导致 Cache 空间以及带宽的浪费,过小粒度的 Cache 会导致对象存储 IO 效率低下,Apache Doris 采用了以 Block 为粒度的 Cache 实现。当远程数据被访问时会先将数据按照 Block 的粒度下载到本地的 Block Cache 中存储,且 Block Cache 中的数据访问性能和非冷热分层表的数据性能一致。
那具体是怎么实现的呢?
前文提到 Doris 的冷热分层是在 Rowset 级别进行的,当某个 Rowset 在冷却后其所有的数据都会上传到对象存储上。而 Doris 在进行查询的时候会读取涉及到的 Tablet 的 Rowset 进行数据聚合和运算,当读取到冷却的 Rowset 时,会把查询需要的冷数据下载到本地 Block Cache 之中。基于性能考量,Doris 的 Cache 按照 Block 对数据进行划分。Block Cache 本身采用的是简单的 LRU 策略,可以保证越是使用程度较高数据越能在 Block Cache 中存放的久。
具体源码实现如下:
CachedRemoteFileReader::_read_from_cache
| //session variable chooses to close file cache for this query
| //1. 会话级别的变量可能禁止当前SQL使用file cache
|--> if (!io_ctx->read_file_cache)
|--> //直接从S3读取文件
|--> _remote_file_reader->read_at(offset, result, bytes_read, io_ctx)
|--> S3FileReader::read_at_impl
|--> //end if
|
|--> //2. 否则则尝试从缓存读取
|--> //首先根据Block size进行一些IO对齐的操作
|--> _align_size(offset, bytes_req)
| |--> align_left = (left/file_cache_max_file_segment_size)*file_cache_max_file_segment_size;
| |--> align_right = (right/file_cache_max_file_segment_size + 1)*file_cache_max_file_segment_size;
|--> holder = _cache->get_or_set
|--> /*loop for holder.file_segments*/
|--> //如果cache miss,则需要需用从S3上读
|--> empty_segments.push_back(segment)
|--> /*end loop for holder.file_segments*/
|
|--> //2.1. 如果empty_segments不为空,即存在cash miss
|--> //发起一个IO,将cache miss的部分从S3读取文件
|--> empty_start = empty_segments.front()->range().left;
|--> empty_end = empty_segments.back()->range().right;
|--> _remote_file_reader->read_at(empty_start,empty_end)
|--> //读取完以后,异步的将数据存储的本地
|--> /*loop for empty_segments*/
|--> FileBlock::append
| |--> LocalWriterPtr::append
| | |--> LocalFileWriter::appendv
|--> FileBlock::finalize_write
| |--> FileBlock::set_downloaded
|--> /*end loop for empty_segments*/
|--> //todo:这里有一些前置条件,还没看明白
|--> //将读取到的数据拷贝到结果集中
|--> memcpy(result.data, src, copy_size);
|
|--> //2.2 遍历所有block,汇总最终的结果
|--> /*loop for holder.file_segments*/
|--> //从本地盘读取数据
|--> FileBlock::read_at
| |--> FileReader::read_at
|--> /*end loop for holder.file_segments*/
无效冷数据删除
冷数据在compaction以后,无效的冷数据如何删除呢?
Doris是通过BE的一个后台线程去定期扫描,然后让对应的leader执行删除操作。由于S3上的冷数据只有一个副本,所以删除的这部分就要额外小点。因为Doris的tablet不像raft group一样有个明确的leader,所以每次删除前都需要跟FE确认,确认无误后才能执行删除。
具体源码如下:
_remove_unused_remote_files_callback
|--> /*dead loop*/
|--> Tablet::remove_unused_remote_files
| |--> //该buffer实际是是一个map,用来存储待删除文件的远程目录信息
| |--> unused_remote_files_buffer_t buffer;
| |--> //获取所有符合条件的tablets
| |--> tablets = StorageEngine::instance()->tablet_manager()->get_all_tablet
| |--> /*loop for tablets*/
| |--> //收集可以回收的无效文件
| |--> calc_unused_remote_files
| | |--> std::vector<io::FileInfo> files
| | |--> FileSystem::list(Path,files)
| | | |--> //通过S3接口,根据指定路径寻找可以删除的文件
| | | |--> S3FileSystem::list_impl(Path,files)
| | | | |--> /*loop for objs
| | | | |--> files->push_back(std::move(file_info));
| | | | |--> /*end for objs
| | |--> //获得当前tablet的cooldowned rowsets
| | |--> /*loop for t->_tablet_meta->all_rs_metas() */
| | |--> cooldowned_rowsets.insert(rs_meta->rowset_id());
| | |--> /*end loop for t->_tablet_meta->all_rs_metas() */
| | |--> files.erase(std::remove_if(files.begin(), files.end(), std::move(filter)), files.end());
| | | |--> //过滤掉不需要删除的文件
| | | |--> //返回false表示不需要删除
| | | |--> filter()
| | | | |--> return cooldowned_rowsets.contains(rowset_id) || pending_remote_rowsets().contains(rowset_id)
| | |--> buffer.insert({t->tablet_id(), {std::move(dest_fs), std::move(files)}});
| |--> //积攒一批后,统一进行回收
| |--> confirm_and_remove_files
| | |--> //跟fe确认需要删除的远程文件列表
| | |--> MasterServerClient::confirm_unused_remote_files
| | | |--> //先给FE发送请求
| | | |--> FrontendServiceClient::send_confirmUnusedRemoteFiles
| | | |--> //根据FE的回包来确认待删除信息
| | | |--> FrontendServiceClient::recv_confirmUnusedRemoteFiles
| | |--> /* loop for result.confirmed_tablets */
| | |--> //查询buffer中是否有需要对应的tablet_id
| | |--> if (auto it = buffer.find(id); LIKELY(it != buffer.end()))
| | |--> //获取需要删除的文件路径
| | |--> /* loop for files*/
| | |--> paths.push_back(std::move(file_path));
| | |--> /* end loop for files*/
| | |--> //批量删除文件
| | |--> FileSystem::batch_delete
| | | |--> S3FileSystem::batch_delete_impl
| | | | |--> //依次发送删除请求
| | | | |--> delete_request.SetDelete(std::move(del));
| | |--> end if
| | |--> /* end loop for result.confirmed_tablets */
| |--> /*end loop for tablets*/
|--> /*end loop*/
源码贡献
优化一:冷热分层----寻找合适rowset优化
问题描述:
cooldown_tasks_producer_thread在寻找tablet的时候,pick_cooldown_rowset调用了两次。其中pick_cooldown_rowset是在锁保护下遍历所有的rowset,如果tablet里的rowset比较多的话,会造成性能损耗。
社区这样做的原因是,上一轮选中的rowset可能被compaction merge掉了,所以又重新遍历了一遍。
问题解决:
1. 优化冷却的rowset大概率不会立即进行compaction,所以可以在采用一种乐观的事务类似的思路来处理。
2. 第一次遍历的时候记录rowset的状态信息、版本信息等
3. 第二次直接去tablet找下rowset是否还在version rowset map中。不如不在或者状态发生了变化,则再次执行遍历
优化前后的流程如下:

issue
https://github.com/apache/doris/issues/27055
pr
https://github.com/apache/doris/pull/27091
优化二:冷热分层----减少无效遍历
问题描述:
冷热分层后,slave 副本的be需要从S3同步元数据。需要在 _meta_lock
的保护下遍历 _rs_version_map
来获取对应的区间。由于遍历过程有一些判断操作,目前的源码 为了方便处理,直接 对 _rs_version_map
进行了两次遍历。由于整个过程是在锁保护下进行的,并且 _rs_version_map
,在高并发场景下较大,所以会对性能产生影响。
问题解决:
将两次遍历改成1次遍历,减少遍历的开销以及锁冲突
pr
https://github.com/apache/doris/pull/27118
优化三:冷热分层----锁区间优化
问题描述:
在执行冷热分层过程中,需要遍历所有tablet,并且判断tablet是否符合转冷条件。在判断是否符合转冷条件的时候,有一些检查需要锁保护,有一些不需要。而社区的代码处理的比较粗糙,直接加锁然后进行判断。
问题解决:
通过以下策略减少加锁时间:
1. 先判断并发安全的变量,如果不符合条件则直接返回;
2. 上一步通过后,再加锁进行判断
pr
https://github.com/apache/doris/pull/26984
优化四:无效冷数据清理----过滤优化
问题描述
在清理无效冷数据文件前需要获取所有的tablet。但是在冷热分层模式下,是有master 副本,slave 副本的概念的,只有master才能去清理文件。
问题解决:
在获取tablet时候增加过滤条件,防止获得大量无效的tablet,导致后续的无效遍历
pr
https://github.com/apache/doris/pull/27338
优化五:无效冷数据清理----容量判断优化
问题描述
在清理无效冷数据文件时,需要遍历所有待处理的file,判断file的rowset_id是否存在于cooldowned_rowsets中。这就导致就算没有合适的cooldowned_rowsets,也会去对file无效遍历。
问题解决:
在遍历待处理的file之前判断cooldowned_rowsets是否为空,如果为空则放弃这次清理操作。
pr
https://github.com/apache/doris/pull/27324
优化六:冷数据Compaction----排序优化
问题描述
在执行冷数据Compaction之前,需要获取所有Compaction sore中 top N的tablet,来保证获取最合适的tablet去Compaction。但是代码在这块的处理比较粗糙,每次遍历的时候都会进行一次全量排序。
问题解决:
增加了一些策略来减少排序次数
pr
https://github.com/apache/doris/pull/27147
关于作者
隐形(邢颖) 网易资深数据库内核工程师,毕业至今一直从事数据库内核开发工作,目前主要参与 MySQL 与 Apache Doris 的开发维护和业务支持工作。
作为 MySQL 内核贡献者,为 MySQL 上报了 60 多个 Bugfix 及优化patch,多个提交被合入 MySQL 8.0 版本。从 2023 年起加入 Apache Doris 社区,Apache Doris Active Contributor,已为社区提交并合入数十个 Commits。
