




目录
为什么需要半朴素贝叶斯分类器
如何确定依赖
编辑:
校对:
版本:
zhang
zhang
python3
朴素贝叶斯
在朴素的分类中,我们假定了各个属性之间的独立,这是为了计算方便,防止过多的属性之间的依赖导致的大量计算。这正是朴素的含义。
基于朴素贝叶斯分类的原理如下:
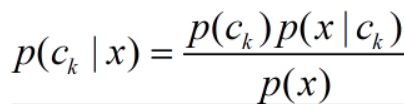
为什么需要半朴素贝叶斯分类器
虽然朴素贝叶斯的分类效果不错,但是属性之间毕竟是有关联的,某个属性依赖于另外的属性,于是就有了半朴素贝叶斯分类器。简单总结如下:
1:后验概率P(ck|x)计算起来比较困难。
2:属性条件独立性假设在现实任务中往往很难成立。
为了计算量不至于太大,假定每个属性只依赖另外的一个。为了可以准确描述真实情况,公式就变成:
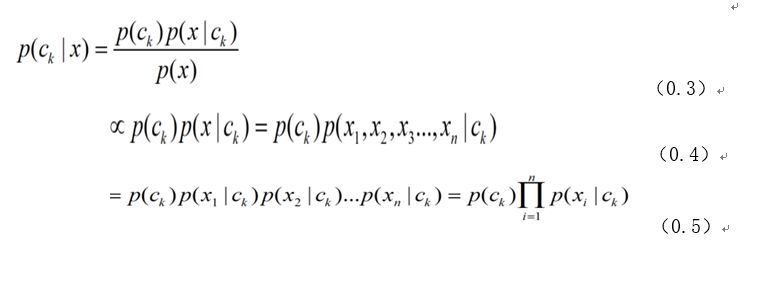
其中, (0.3) 是贝叶斯定理, (0.4) 是因为分母的概率 p(x)与我们关心的类没有关系(这里符号 ∝ 是 “成比例” 的意思), 而 (0.5) 是因为假定了 观测值 x1,x2,...,xn在给定了ck的条件独立性.
如何确定依赖
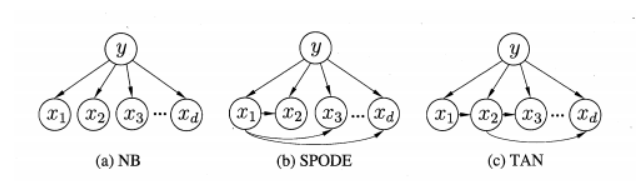
1.SOPDE方法。这种方法是假定所有的属性都依赖于共同的一个父属性。
2.TAN方法。每个属性依赖的另外的属性由最大带权生成树来确定。
(1)先求每个属性之间的互信息来作为他们之间的权值。
(2)构件完全图。权重是刚才求得的互信息。然后用最大带权生成树算法求得此图的最大带权的生成树。
(3)找一个根变量,然后依次将图变为有向图。
(4)添加类别y到每个属性的的有向边。
思考——学而不思则罔
那如何使用python来实现贝叶斯分类呢?先尝试一下吧,我们下次进行代码演示。

理解编程语言,探索数据奥秘
每日练习|干货分享|新闻资讯|公益平台。
每天学习一点点,你将会见到全新的自己。

长按识别二维码关注
文章转载自云南高校数据化运营管理工程中心,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
