




https://www.modb.pro/doc/124130 ptcp v6 题库
https://www.modb.pro/doc/123201 ptca v6 题库
一、RocksDB
1.1 RocksDB 简介
RocksDB 作为 TiKV 的核心存储引擎,每个 TiKV 实例中有两个 RocksDB 实例。RocksDB 实例独占 WAL 文件,RocksDB 实例内不同的 CF 是独立的 LSM tree,但是共享 WAL。
raftdb:存储 Raft 日志
kvdb:存储用户数据以及 MVCC 信息
kvdb 中有四个 ColumnFamily:raft、lock、default、write:
raft 列:用于存储各个 Region 的元信息。仅占极少量空间,用户可以不必关注。
lock 列:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后, lock cf 中对应的数据会很快删除掉,因此大部分情况下 lock cf 中的数据也很少(少于 1GB)。如果 lock cf 中的数据大量增加,说明有大量事务等待提交,系统出现了 bug 或者故障。
write 列:用于存储用户真实的写入数据以及 MVCC 信息(该数据所属事务的开始时间以及提交时间)。当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储 write 列中,否则的话该行数据会被存入到 default 列中。由于 TiDB 的非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 writecf 的空间。
default 列:用于存储超过 255 字节长度的数据。
1.2 RocksDB 空间占用
多版本:RocksDB 作为一个 LSM-tree 结构的键值存储引擎,MemTable 中的数据会首先被刷到 L0。L0 层的 SST 之间的范围可能存在重叠(因为文件顺序是按照生成的顺序排列),因此同一个 key 在 L0 中可能存在多个版本。当文件从 L0 合并到 L1 的时候,会按照一定大小(默认是 8MB)切割为多个文件,同一层的文件的范围互不重叠,所以 L1 及其以后的层每一层的 key 都只有一个版本。
空间放大:RocksDB 的每一层文件总大小都是上一层的 x 倍,在 TiKV 中这个配置默认是 10,因此 90% 的数据存储在最后一层,这也意味着 RocksDB 的空间放大不超过 1.11 (L0 层的数据较少,可以忽略不计)
TiKV 的空间放大:TiKV 在 RocksDB 之上还有一层自己的 MVCC,当用户写入一个 key 的时候,实际上写入到 RocksDB 的是 key + commit_ts,也就是说,用户的更新和删除都是会写入新的 key 到 RocksDB。TiKV 每隔一段时间会删除旧版本的数据(通过 RocksDB 的 Delete 接口),因此可以认为用户存储在 TiKV 上的数据的实际空间放大为,1.11 加最近 10 分钟内写入的数据(假设 TiKV 回收旧版本数据足够及时)。详情见《TiDB in Action》。
1.3 LSM-Tree写入流程图
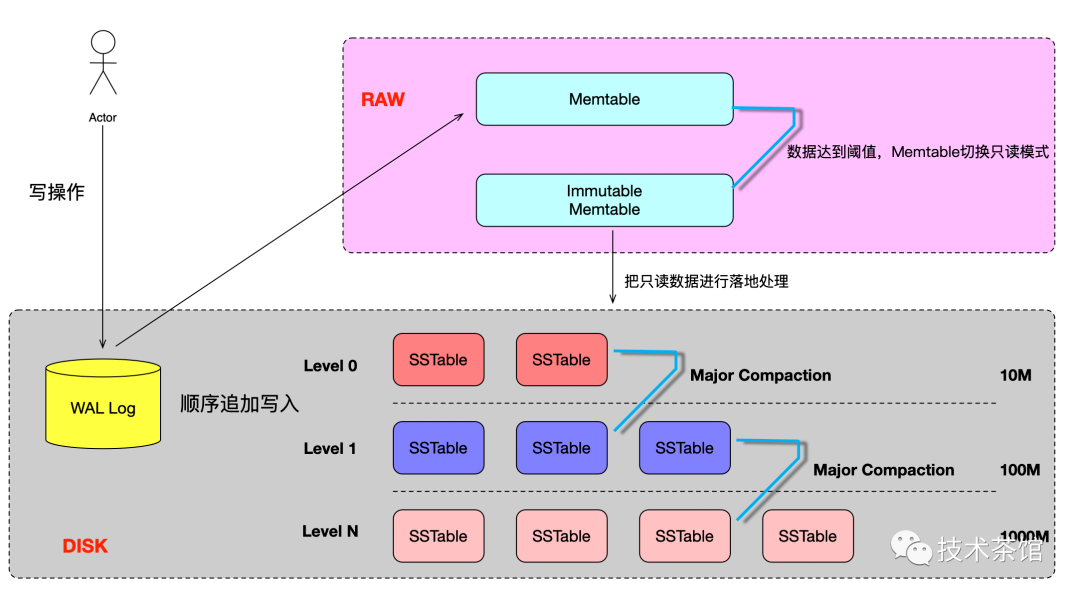
1.4 LSM-Tree读取流程图
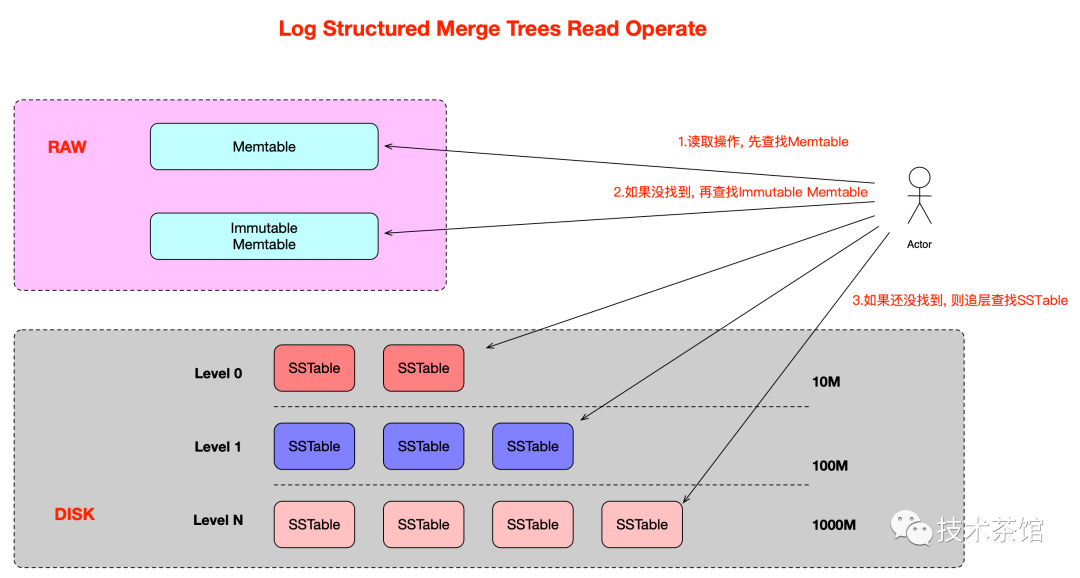
日志先行,先写 WAL 位于kv节点的db目录(.log后缀就是wal文件),再写入 Memtable,Memtable 写满以后,将数据写入磁盘中的 SST 文件,对应 logfile 里的 log 会被安全删除。
二、RocksDB写入流程
2.1 写入流程
1、产生写入请求(put\delete)
TiKV-Details -> RocksDB KV/RocksDB raft -> Write operations (正常情况下with_wal、done 的数量应该是保持一致)
2、写入操作系统缓存。如果配置sync-log=true,则同时执行刷盘操作fsync写入本地文件
先写 WAL 日志文件,方便 crash recovery 的时候可以根据日志恢复。配置sync-log=false,把数据写进了操作系统的缓存区就返回了,进行下一步
TiKV-Details -> RocksDB KV/RocksDB raft -> Write WAL duration (在进行 WAL 时所花费的时间)
TiKV-Details -> RocksDB KV/RocksDB raft -> WAL sync operations (调用操作系统 fsync 的次数)
TiKV-Details -> RocksDB KV/RocksDB raft -> WAL sync duration (调用操作系统 fsync 将数据持久化到硬盘上耗时)
3、将请求写入到 memtable 中,并返回写入成功信息给客户端。数据后台进行compact
TiKV-Details -> RocksDB KV/RocksDB raft -> Write Durtion (收到 put/delete 请求到完成请求返回给 client 所花费的时间)
至此数据已经写入完毕并返回客户端执行成功,剩下的就是flush与compact操作
2.2 memtable flush
当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。写满之后的转化为immutable,然后进行刷盘flush。当达到 memtable 最大个数限制,就会触发 RocksDB 的 write stall 。
### 可配置到 rocksdb.writecf 、rocksdb.defaultcf
rocksdb.writecf.write-buffer-size: 256MB # memtable 大小
rocksdb.writecf.min-write-buffer-number-to-merge: 1 # immutable 达到多少个则进行刷盘flush
rocksdb.writecf.max-write-buffer-number: 24 # memtable 最大个数
rocksdb.writecf.max-background-flushes: 2 # memtable 刷写的最大后台线程数TiKV-Details -> RocksDB KV/RocksDB raft -> Write Stall Reason 或者 RocksDB 日志(查找 Stalling 关键字)确认是否是 level0 sst 文件过多导致 write stall
2.3 immutable compaction 到 L0 层
immutable 数量达到 min-write-buffer-number-to-merge 之后就会触发 flush。
L0 层上包含的文件,是由内存中的memtable dump到磁盘上生成的,单个文件内部按key有序,文件之间无序。可能存在多个相同的key在 L0 层
L1~L6层上的文件都是按照key有序的。也就是每层只会存在一个key。
SST 文件命名格式
SST 文件以 storeID_regionID_regionEpoch_keyHash_cf 的格式命名。格式名的解释如下:
storeID:TiKV 节点编号
regionID:Region 编号
regionEpoch:Region 版本号
keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性
cf:RocksDB 的 ColumnFamily(默认为
default或write)
2.4 L0 层 compaction 到 L1 层
### 可配置到 rocksdb.writecf 、rocksdb.defaultcf
rocksdb.writecf.level0-file-num-compaction-trigger: 4 # 触发 L0 向 L1 合并的 L0 文件数
rocksdb.writecf.level0-slowdown-writes-trigger: 32 # 触发 write stall 的 L0 文件数
rocksdb.writecf.level0-stop-writes-trigger: 64 # 触发完全阻塞写入的 L0 文件数
### 向 L1 的compaction不可以与其他level compaction并行。需单独配置此参数
rocksdb.max-sub-compactions: 2
2.5 L1~L6层 compaction
L1~Ln 层是否需要 Compaction 是依据每一层 SST 文件大小是否超过阈值。可根据以下参数进行配置。
### 可配置到 rocksdb.writecf 、rocksdb.defaultcf
rocksdb.writecf.target-file-size-base: 8MB # SSTable 文件大小,文件从 L0 合并到 L1
rocksdb.writecf.max-bytes-for-level-base: 512MB # base LEVEL (L1) 最大字节数,一般设置为 memtable 大小 4 倍
rocksdb.writecf.max-bytes-for-level-multiplier: 10 # 每一层的默认放大倍数。默认值 : 10
rocksdb.writecf.num-levels: 7 # 文件最大层数。默认值 : 7
rocksdb.writecf.compression-per-level: ["no","no","lz4","lz4","lz4","zstd","zstd"] # 每层压缩算法2.5.1 Compaction 策略
每层大小当超过以下阈值时则会进行 Compaction ,把数据合并到下一层。
| Level | L1 | L2 | L3 | L4 | L5 | L6 | |
|---|---|---|---|---|---|---|---|
| Size | 512MB | 5GB | 50GB | 500GB | 5TB | 50TB | |
当多个 Level 都满足触发Compaction的条件,该如何选择?
对于L1-L6,score = 该level文件的总长度 / 阈值。已经正在做Compaction的文件不计入总长度中
对于L0,score = max{文件数量 / level0-file-num-compaction-trigger, L0文件总长度 / max-bytes-for-level-base} 并且 L0文件数量 > level0-file-num-compaction-trigger
2.5.2 数据存放策略
RocksDB 默认开启 dynamic-level-bytes, 所以数据文件会优先放更底层。
如果当前数据总大小低于 max-bytes-for-level-base(默认为 512MB),则所有数据都会在 L6。此时 L6 实际上相当于 L1。
如果当前数据总大小低于 max-bytes-for-level-base * max-bytes-for-level-multiplier , 则 L6 视作 L2,L5 视作 L1。
但是无论如何,除了 L0 以外的各层数据比例都按照上层比下层 1:10 进行分布。
2.5.3 compaction 关键参数
rocksdb.max-background-jobs: 16 # Compact 和 Flush 任务的最大线程池
rocksdb.rate-bytes-per-sec: 0KB # 限制后台 compaction 任务的磁盘流量,默认不限制
soft-pending-compaction-bytes-limit: 64GB # Compaction pending bytes达到限制之后,RocksDB会放慢写入速度
hard-pending-compaction-bytes-limit: 256GB # Compaction pending bytes达到限制之后,RocksDB会停止写入
rocksdb.use-direct-io-for-flush-and-compaction: true # 设置为 true 数据(wal不支持)读写绕过文件系统缓存 https://github.com/facebook/rocksdb/wiki/Direct-IO,默认false
TiKV-Details -> RocksDB KV/RocksDB raft -> Compaction operations
记录的是 compaction 和 flush 操作的数量,immutable 刷到 L0 是 flush ,L0~L6 刷到下一层是 compaction。
TiKV-Details -> RocksDB KV/RocksDB raft -> Compaction reason
TiKV-Details -> RocksDB KV/RocksDB raft -> Compaction duration
TiKV-Details -> RocksDB KV/RocksDB raft -> Compaction flow
TiKV-Details -> RocksDB KV/RocksDB raft -> Compaction pending bytes
等待 compaction 的大小。Compaction pending bytes 太多会导致 stall
但是这个监控数据可能不太准确,可以根据 TiKV-Details -> RocksDB KV/RocksDB raft -> Write Stall Reason 或者 RocksDB 日志(查找 Stalling 关键字)确认是否有 compaction 导致 write stall 以及具体原因
2.6 其他关键参数
rocksdb.bytes-per-sync: 256MB # 异步Sync限速速率?默认1MB,一直弄不明白???
rocksdb.wal-bytes-per-sync: 256MB # WAL Sync限速速率
gc.max-write-bytes-per-sec # 控制GC流量,默认不限制。
storage.scheduler-concurrency: 2048000 # scheduler 内置一个内存锁机制,防止同时对一个 key 进行操作。
storage.scheduler-worker-pool-size: 8 # Scheduler 线程主要负责写入之前的事务一致性检查工作
readpool.coprocessor.use-unified-pool: true # 是否使用统一的读取线程池处理存储请求
readpool.storage.use-unified-pool: true # (clean-tidb:false,spider-tidb:true)
readpool.unified.max-thread-count: 16 # 统一处理读请求的线程池最大线程数,即UnifyReadPool线程池的大小
server.snap-max-write-bytes-per-sec: 100MB # 处理 snapshot 时最大允许使用的磁盘带宽
storage.scheduler-pending-write-threshold: 100MB # 写入数据队列的最大值,超过该值之后对于新的写入 TiKV 会返回 Server Is Busy 错误。监控指标:Scheduler writing bytes
TiKV 的读取请求分为两类:
一类是指定查询某一行或者某几行的简单查询,这类查询会运行在 Storage Read Pool 中。
另一类是复杂的聚合计算、范围查询,这类请求会运行在 Coprocessor Read Pool 中。
从 TiKV 5.0 版本起,默认所有的读取请求都通过统一的线程池进行查询。
从 TiKV 4.0 升级上来的 TiKV 集群且升级前未打开 readpool.storage 的 use-unified-pool 配置,则升级后所有的读取请求仍然继续使用独立的线程池进行查询,可以将 readpool.storage.use-unified-pool 设置为 true 使所有的读取请求通过统一的线程池进行查询。
在 UnifyRead Pool 线程池,读取操作将分为3个不同的优先级L0、L1、L2,执行快占用资源少的将会优先执行。在集群负载较高的时候,会发现一些慢SQL执行的更慢了。
三、共享 block-cache
所有 CF 共享一个 Block-cache,用于缓存数据块,加速 RocksDB 的读取速度。当开启时,为每个 CF 单独配置的 Block-cache将无效。
### 配置后所有CF共享一个block-cache,以下的 block-cache-size 不再需要手动设置:
### rocksdb.defaultcf.block-cache-size
### rocksdb.writecf.block-cache-size
### rocksdb.lockcf.block-cache-size
### raftdb.defaultcf.block-cache-size
storage.block-cache.capacity: 96GB3.1 内存占用计算
占用内存=block-cache.capacity + ( write-buffer-size * max-write-buffer-number * 4 )
kvdb中有4个CF所以乘以4,默认情况下每个CF的中参数配置不一样,单独计算更精确。配置的时候给系统预留25%以上的内存,避免OOM。
3.2 线程池介绍
在 TiKV 中,线程池主要由 gRPC、Scheduler、UnifyReadPool、Raftstore、Apply、RocksDB 以及其它一些占用 CPU 不多的定时任务与检测组件组成,这里主要介绍几个占用 CPU 比较多且会对用户读写请求的性能产生影响的线程池。
gRPC 线程池:负责处理所有网络请求,它会把不同任务类型的请求转发给不同的线程池。
Scheduler 线程池:负责检测写事务冲突,把事务的两阶段提交、悲观锁上锁、事务回滚等请求转化为 key-value 对数组,然后交给 Raftstore 线程进行 Raft 日志复制。
Raftstore 线程池:负责处理所有的 Raft 消息以及添加新日志的提议 (Propose)、将日志写入到磁盘,当日志在多数副本中达成一致后,它就会把该日志发送给 Apply 线程。
Apply 线程池:当收到从 Raftstore 线程池发来的已提交日志后,负责将其解析为 key-value 请求,然后写入 RocksDB 并且调用回调函数通知 gRPC 线程池中的写请求完成,返回结果给客户端。
RocksDB 线程池:RocksDB 进行 Compact 和 Flush 任务的线程池,关于 RocksDB 的架构与 Compact 操作请参考 RocksDB: A Persistent Key-Value Store for Flash and RAM Storage。
UnifyReadPool 线程池:由 Coprocessor 线程池与 Storage Read Pool 合并而来,所有的读取请求包括 kv get、kv batch get、raw kv get、coprocessor 等都会在这个线程池中执行。
gRPC 线程是 TiKV 所有请求的入口,他会将外界的请求转发给各个模块
写请求,转发给 Scheduler 线程
读请求,转发给 UnifyReadPool 线程
Scheduler 负责检测事务冲突,将复杂的事务操作转换为简单的 key-value 插入、删除,并送给 Raftstore 线程
Raftstore 负责执行 raft 日志复制,将数据复制给多个副本。当日志在多个副本上达成一致后,会发送给 Apply 线程
Apply 线程负责把写入 raft 日志的数据,再写入 kvdb。然后通知 gRPC 线程返回结果给客户端
四、Raftsotre 工作机制
官图镇楼,退退退~~~
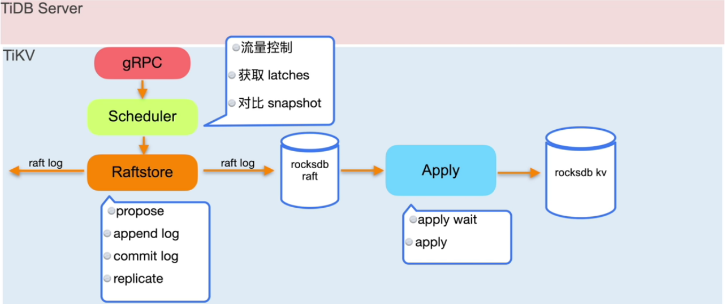
4.1 Scheduler
1、流量控制
storage.scheduler-pending-write-threshold: 100MB # 写入数据队列的最大值,超过该值之后对于新的写入 TiKV 会返回 Server Is Busy 错误。监控指标:Scheduler writing bytes
2、获取Latches
storage.scheduler-concurrency: 2048000 # scheduler 内置一个内存锁机制,防止同时对一个 key 进行操作。
3、对比 snapshot
4.2 Raftstore 的工作流程
一个 TiKV 实例上有多个 Region。Region 消息是通过 Raftstore 模块驱动 Raft 状态机来处理的。这些消息包括 Region 上读写请求的处理、Raft log 的持久化和复制、Raft 的心跳处理等。但是,Region 数量增多会影响整个集群的性能。
从 TiDB 发来的请求会通过 gRPC 和 storage 模块变成最终的 KV 读写消息,并被发往相应的 Region,而这些消息并不会被立即处理而是被暂存下来。Raftstore 会轮询检查每个 Region 是否有需要处理的消息。如果 Region 有需要处理的消息,那么 Raftstore 会驱动 Raft 状态机去处理这些消息,并根据这些消息所产生的状态变更去进行后续操作。例如,在有写请求时,Raft 状态机需要将日志落盘并且将日志发送给其他 Region 副本;在达到心跳间隔时,Raft 状态机需要将心跳信息发送给其他 Region 副本。
Propose 将写请求转化为 raft log
Append log 将 raft log 写入 raftdb 持久化
Replicate 将 raft log 并发复制到其他节点
Commit log 大多数节点都 Append log 后才会进行此步骤 (raft log Commit,到这一步用户仍然不能读取当前数据)
Apply 将 commit raft log 写入 kvdb ,客户端的 Commit 才算成功(会写入一条释放锁的日志,至此用户才能读取到数据)
4.3 raftstore 关键参数
raftstore.sync-log:false # log 落盘是否 sync(4.0.7开始已废弃,忽略此参数)
raftstore.apply-max-batch-size:8192 # 一轮处理数据落盘的最大请求个数
raftstore.store-max-batch-size:8192 # 一轮处理的最大请求个数
raftstore.apply-pool-size:8 # 数据落盘的线程数
raftstore.store-pool-size:8 # 处理 raft 的线程数
raftdb.max-background-jobs:8 # 这是干啥的?应该不需要调整
raftdb.max-sub-compactions:2 # 这是干啥的?应该不需要调整
raftstore.hibernate-regions:true # 如果 Region 长时间处于非活跃状态,即被自动设置为静默状态
raftstore.raft-max-inflight-msgs:16384 # 待确认的日志个数,如果超过,Raft 状态机会减缓发送日志的速度
五、 监控面板
Raft propose -> Raft log speed:发送到 raftstore 的流量?
Scheduler - prewrite -> Scheduler keys written:prewrite 命令写入 key 的个数
5.1 读取慢排查
【302-Lession 29】
Thread CPU --> Unified read pool CPU
TiKV Detail --> Coprocessor Detail --> Wait Duration 请求被调度+获取snapshot+构建handler的时间总和
TiKV Detail --> Coprocessor Detail --> Handle Duration 执行扫描数据的耗时
TiKV Detail --> Coprocessor Detail --> 95% Handle duration by store 查看哪个store 慢
TiKV Detail --> Coprocessor Detail --> Total Ops Details (Index Scan)
Total Ops Details (Table Scan):coprocessor 中请求为 select 的 scan 过程中每秒钟各种事件发生的次数
Total Ops Details (Index Scan):coprocessor 中请求为 index 的 scan 过程中每秒钟各种事件发生的次数
5.2 写入慢排查
【302-Lession 28】
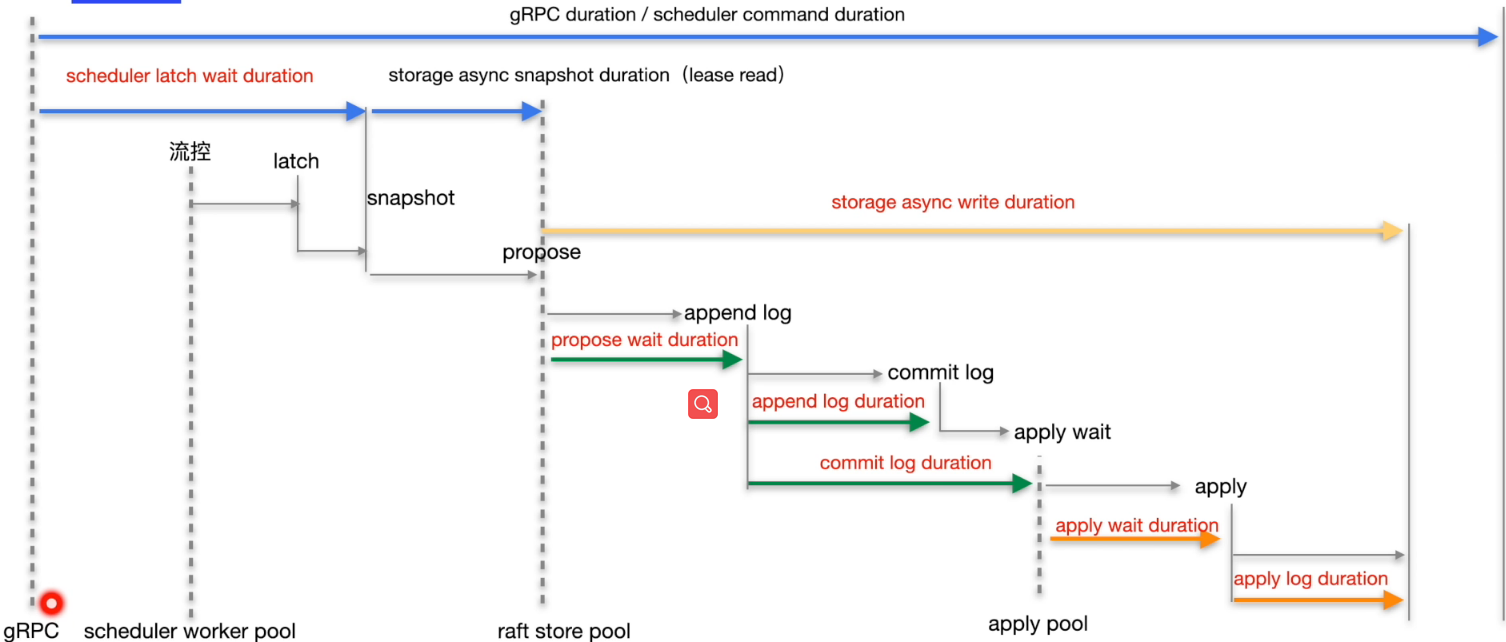
TiDB -> Duration 包括三部分耗时: TiDB、网络、TiKV的耗时。
TiDB -> KV Requst:TiDB 发送请求到 TiKV 执行后并返回 (不包括TiDB耗时)。
如果上面俩个监控指标耗时接近,那就可以排除掉TiDB,问题在 TiKV。
TiKV Detail -> gRPC -> 99% gRPC message duration 耗时: TiKV的耗时。
这个指标可以查看是哪种操作比较耗时
如果这个指标耗时和 Duration 接近,那就可以定位问题在 TiKV。
TiDB --> DistSQL --> Coprocessor Seconds 999 耗时: 扫描tikv数据耗时,读取。
TiKV Detail -> Scheduler prewrite -> Scheduler command duration 包括两部分耗时:latch、 Async write
TiKV 线程池调优
gRPC 线程池的大小默认配置 (
server.grpc-concurrency) 是 5。由于 gRPC 线程池几乎不会有多少计算开销,它主要负责网络 IO、反序列化请求,因此该配置通常不需要调整。- 如果部署的机器 CPU 核数特别少(小于等于 8),可以考虑将该配置 (
server.grpc-concurrency) 设置为 2。 - 如果机器配置很高,并且 TiKV 承担了非常大量的读写请求,观察到 Grafana 上的监控 Thread CPU 的 gRPC poll CPU 的数值超过了 server.grpc-concurrency 大小的 80%,那么可以考虑适当调大
server.grpc-concurrency以控制该线程池使用率在 80% 以下(即 Grafana 上的指标低于80% * server.grpc-concurrency的值)。
- 如果部署的机器 CPU 核数特别少(小于等于 8),可以考虑将该配置 (
Scheduler 线程池的大小配置 (
storage.scheduler-worker-pool-size) 在 TiKV 检测到机器 CPU 核数大于等于 16 时默认为 8,小于 16 时默认为 4。它主要用于将复杂的事务请求转化为简单的 key-value 读写。但是 scheduler 线程池本身不进行任何写操作。如果检测到有事务冲突,那么它会提前返回冲突结果给客户端。
如果未检测到事务冲突,那么它会把需要写入的 key-value 合并成一条 Raft 日志交给 Raftstore 线程进行 Raft 日志复制。
通常来说为了避免过多的线程切换,最好确保 scheduler 线程池的利用率保持在 50%~75% 之间。(如果线程池大小为 8 的话,那么 Grafana 上的 TiKV-Details.Thread CPU.scheduler worker CPU 应当在 400%~600% 之间较为合理)
Raftstore 线程池是 TiKV 中最复杂的一个线程池,默认大小 (由
raftstore.store-pool-size控制) 为 2。StoreWriter 线程池的默认大小 (由raftstore.store-io-pool-size控制) 为 0。当 StoreWriter 线程池大小为 0 时,所有的写请求都会由 Raftstore 线程以 fsync 的方式写入 RocksDB。此时建议采取如下调优操作:
- 将 Raftstore 线程的整体 CPU 使用率控制在 60% 以下。当把 Raftstore 线程数设为默认值 2 时,将 Grafana 监控上 TiKV-Details、Thread CPU、Raft store CPU 面版上的数值控制在 120% 以内。由于存在 I/O 请求,理论上 Raftstore 线程的 CPU 使用率总是低于 100%。
- 不建议为了提升写性能而盲目增大 Raftstore 线程池大小,这样可能会适得其反,增加磁盘负担,导致性能变差。
当 StoreWriter 线程池大小不为 0 时,所有写请求都由 StoreWriter 线程以 fsync 的方式写入 RocksDB。此时建议采取如下调优操作:
仅在整体 CPU 资源比较充裕的情况下启用 StoreWriter 线程池,并将 StoreWriter 线程和 Raftstore 线程的 CPU 使用率控制在 80% 以下。
与写请求在 Raftstore 线程完成的情况相比,理论上 StoreWriter 线程处理写请求能够显著地降低写延迟和读的尾延迟。然而,写入速度变得更快意味着 Raft 日志也变得更多,从而导致 Raftstore 线程、Apply 线程和 gRPC 线程的 CPU 开销增多。在这种情况下,CPU 资源不足可能会抵消优化效果,反而还可能比原来的写速度更慢,因此若是 CPU 资源不充裕则不建议开启 StoreWriter 线程。由于 Raftstore 线程把绝大部分的 I/O 请求交给 StoreWriter,因此 Raftstore 线程的 CPU 使用率控制在 80% 以下即可。
大多数情况下将 StoreWriter 线程池的大小设为 1 或 2 即可。这是因为 StoreWriter 线程池的大小会影响 Raft 日志数量,所以该值不宜过大。如果 CPU 使用率高于 80%,可以考虑再增加其大小。
注意 Raft 日志增多对其他线程池 CPU 开销的影响,必要的时候需要相应地增加 Raftstore 线程、Apply 线程和 gRPC 线程的数量。
UnifyReadPool 负责处理所有的读取请求。默认配置 (
readpool.unified.max-thread-count) 大小为机器 CPU 数的 80% (如机器为 16 核,则默认线程池大小为 12)。通常建议根据业务负载特性调整其 CPU 使用率在线程池大小的 60%~90% 之间(如果用户 Grafana 上 TiKV-Details.Thread CPU.Unified read pool CPU 的峰值不超过 800%,那么建议用户将
readpool.unified.max-thread-count设置为 10,过多的线程数会造成更频繁的线程切换,并且抢占其他线程池的资源)。TiKV 从 v6.3.0 开始支持根据统一读线程池 (UnifyReadPool) 的 CPU 利用率自动动态调整线程池的线程数量,可以通过配置
readpool.unified.auto-adjust-pool-size开启此功能。对于重读并且峰值 CPU 利用率超过 80% 的集群,建议开启此配置。RocksDB 线程池是 RocksDB 进行 Compact 和 Flush 任务的线程池,通常不需要配置。
如果机器 CPU 核数较少,可将
rocksdb.max-background-jobs与raftdb.max-background-jobs同时设置为 4。如果遇到了 Write Stall,可查看 Grafana 监控上 RocksDB-kv 中的 Write Stall Reason 有哪些指标不为 0。
如果是由 pending compaction bytes 相关原因引起的,可将
rocksdb.max-sub-compactions设置为 2 或者 3(该配置表示单次 compaction job 允许使用的子线程数量,TiKV 4.0 版本默认值为 3,3.0 版本默认值为 1)。如果原因是 memtable count 相关,建议调大所有列的
max-write-buffer-number(默认为 5)。如果原因是 level0 file limit 相关,建议调大如下参数为 64 或者更高:
rocksdb.defaultcf.level0-slowdown-writes-trigger rocksdb.writecf.level0-slowdown-writes-trigger rocksdb.lockcf.level0-slowdown-writes-trigger rocksdb.defaultcf.level0-stop-writes-trigger rocksdb.writecf.level0-stop-writes-trigger rocksdb.lockcf.level0-stop-writes-trigger
持续完善中。
