




随着大语言模型和 ChatGPT 的爆发,向量数据库现在非常热门。但什么是向量数据库?它是做什么用的呢?
下图显示了向量数据库与其他类型数据库的比较。
向量数据库可以将音频、视频、图像和文本等各种非结构化数据映射为高维向量(Embeddings)。然后,我们就可以计算非结构化数据之间的相似性。和其他类型的数据库类似,向量数据库也具有 CRUD 操作和水平扩展等功能。
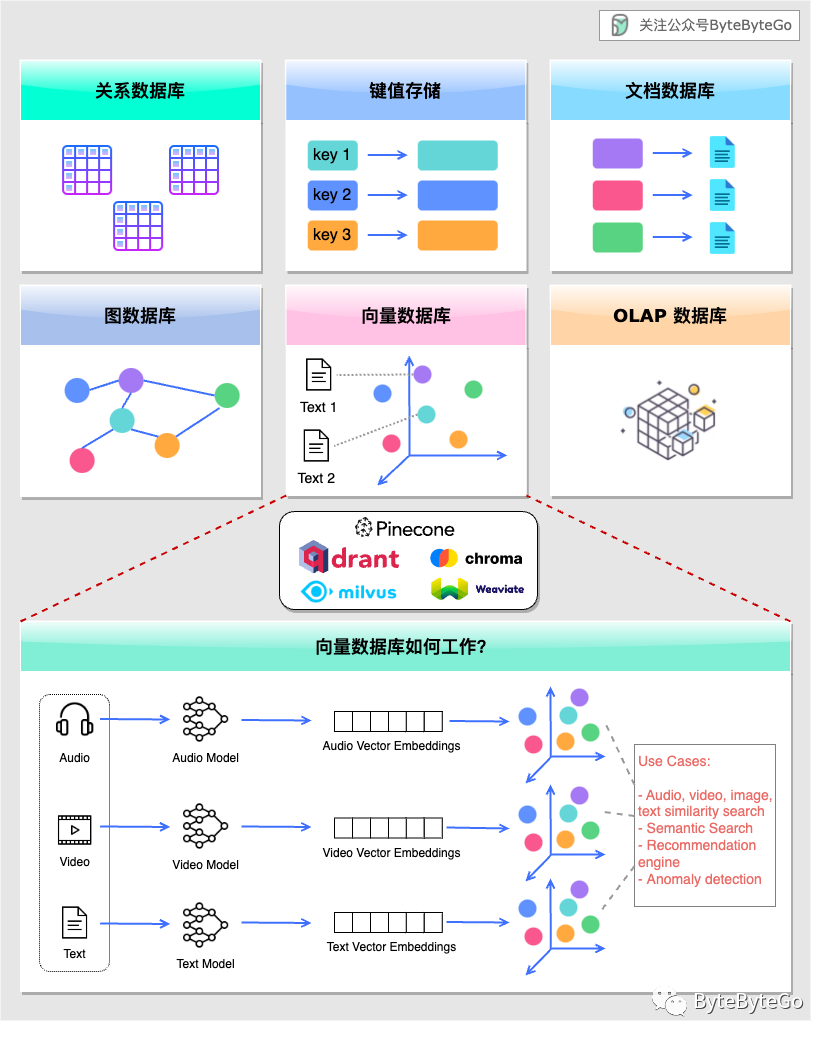
典型用例包括:
查找相似的图像或文本 推荐相似产品(找同款) 检测异常 大量输入数据映射为 embeddings 后的临时存储
向量数据库公司的融资情况也从一个侧面反映了其热门情况:
Pinecone: 1.38 亿美元 Milvus: 1.13 亿美元 Weaviate:6770 万美元 Chroma: 2000 万美元 Qdrant: 980万美元
我们来看看使用向量数据库搭建一个企业知识库问答系统是怎么做的。
01
知识库搜索
假设我们有很多知识库文档,传统的做法是使用对象存储(Amazon S3)和全文搜索引擎(ElasticSearch)来搭建一个搜索应用。
知识库在搭建的时候,会进行倒排索引的搭建。
用户最终获取的是包含搜索关键词的一些文档原文,然后用户需要自行在这些文档中找到问题的答案。
我们这个知识库搜索应用其实并不能理解用户的问题,需要用户将“怎么找到我的账户余额”之类的问题翻译成“账户、余额”来输入给这个应用。
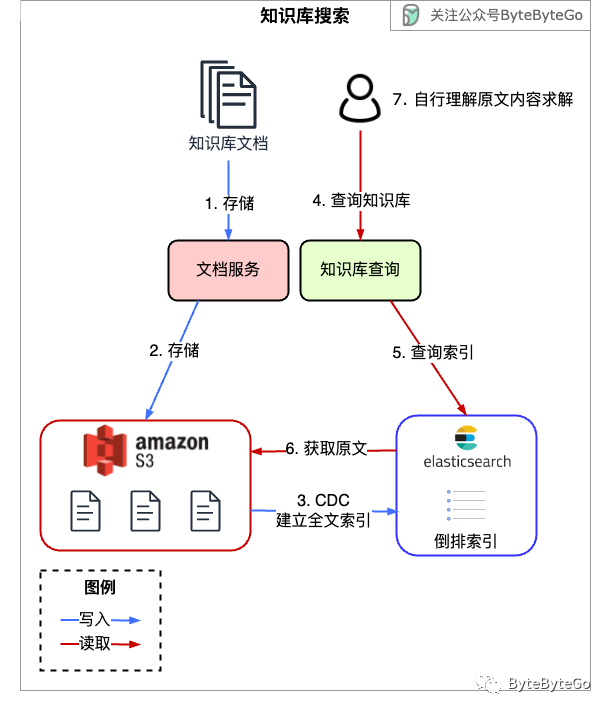
如果使用向量数据库和大语言模型的配合,那么用户体验就好多了。
02
知识库问答
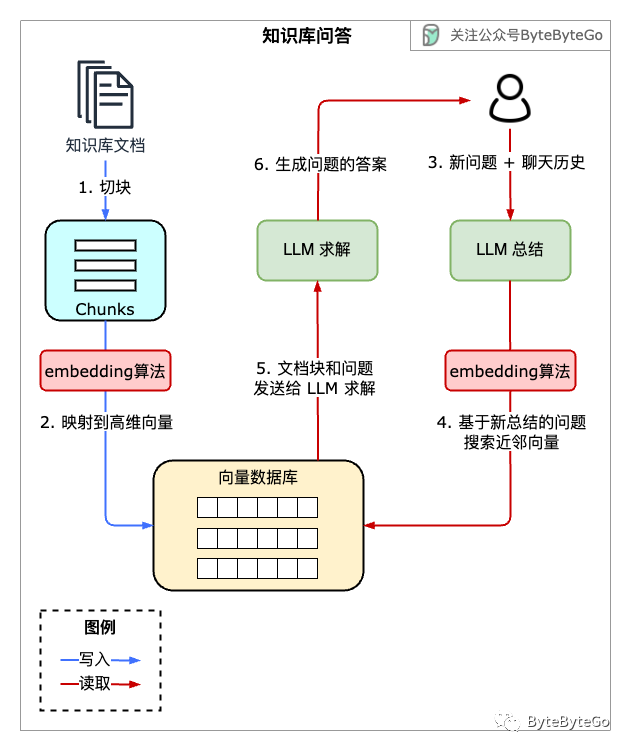
在建立知识库的时候,我们先将长文本切块。然后使用 embeddings 算法将每个文本块映射到高维空间,并存储在向量数据库里。需要注意的是,这种映射的目的并不是为了压缩数据,而是为了非结构化数据的搜索。高维向量占用的空间可能会比原文更大。
用户在使用知识库问答时,会输入一系列问题。前续问题被称为“上下文”,和新问的问题一起输入大语言模型。大语言模型将其总结后会生成一个新的问题。然后应用程序会在向量数据库里寻找这个新问题的近邻。这样我们就找到了最接近用户问题的文档块。
这些文档块会连同新问题一起输入到大语言模型中进行求解,生成最终给用户的答案。
由于知识库问答和用户的互动性较强,向量数据库搜索的速度就很重要了。很多向量数据库产品在搜索优化上做了很多工作。
那么看到这里,卖个小关子,你觉得向量数据库会成为专有数据库产品,还是会融入到已有的数据库产品中?我们是否可以基于 Redis 、ElasticSearch 或者 PostgreSQL 来构建向量数据库呢?
