




随着春节假期的结束,我们迎来了充满希望的龙年,开源社区也呈现出一片繁荣的景象。在去年,通过众多社区贡献者的努力, 社区落地实现了很多需求,有兴趣的小伙伴可以看去年的年终报告:2023年终盘点:Apache SeaTunnel社区年度成就与展望
社区落地实现了很多需求,有兴趣的小伙伴可以看去年的年终报告:2023年终盘点:Apache SeaTunnel社区年度成就与展望

本次更新的Roadmap着重于增强Apache SeaTunnel的核心功能、扩展连接器生态系统、优化数据处理能力和提升用户体验。欢迎大家一起来共建!
支持在K8s和Yarn上运行
目前,Zeta引擎提交作业仅支持local模式和standalone模式,社区计划全面扩展Job运行环境,支持K8s和Yarn,特别针对CDC实时同步场景进行了优化,使得资源利用率和数据处理效率得到极大提升。这标志着SeaTunnel在面向大规模数据处理需求时,迈出了坚实的一步。
issue传送地:https://github.com/apache/seatunnel/issues/4386
支持更多的连接器
新增多个数据源和目标的连接器支持,进一步丰富了Apache SeaTunnel的应用场景。每一步扩展,都是我们为开发者打开更多可能性的实践。
Catalog支持更多连接器
类型转换器TypeConverter和数据类型转换器DataTypeConverter的设计和适配,TypeConverter的目标是让每种连接器更准确的描述数据库自身的数据类型和SeaTunnel数据类型之间的转换与逆转换,目前API层面应该完成了开发,后续需要所有的连接器进行适配实现,TypeConverter可以帮忙SeaTunnel更好的完成数据模型的推演以及自动建表时的建表语句生成。
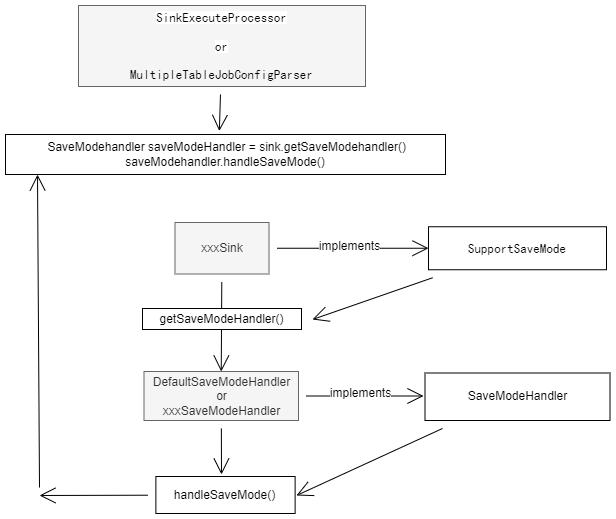
Savemode 设计图
DataTypeConverter将与TypeConverter一起帮SeaTunnel更好的完成数据类型在不同数据库之间的隐式转换,比如针对JDBC Oracle Sink的场景,写入SeaTunnel中的String类型时什么时候使用setString,什么时候使用blob需要DataTypeConverter将与TypeConverter结合来判断该字段的长度,目标端的字段类型等信息。
综上所述,通过引入Catalog适配、TypeConverter和DataTypeConverter,我们为数据结构的自动获取、数据类型的精确转换提供了强有力的支撑。
issue 传送地
Typeconverter:
https://github.com/apache/seatunnel/pull/5872
多表读取:
https://github.com/apache/seatunnel/issues/5677
多表写入:
https://github.com/apache/seatunnel/issues/5652
TableScouceFactory和TableSinkFactory:
https://github.com/apache/seatunnel/issues/5651
Savemode:
https://github.com/apache/seatunnel/issues/5390
事件通知机制
为了提升任务管理的效率和透明度,我们计划引入事件通知机制,使任务的各种状态和重要事件能够及时通知给用户。
表级别的监控
在最新的2.3.4版本中,随着多表同步功能的支持,表级别监控成为了必需。用户将能够通过监控信息了解到每张表的同步情况,进一步提升监控的细粒度。
脏数据收集
在数据同步过程中,无法写入目标端的数据将不再直接导致作业失败。通过脏数据收集功能,这些数据将被先行存储,不影响作业的正常运行,确保了数据处理流程的可持续性。
社区共建,共创未来
SeaTunnel社区正处于蓬勃发展之中,每一次更新都凝聚了社区成员的智慧和汗水,也社区的发展离不开每一位成员的贡献和支持,社区的里程远未结束,更多的挑战和机遇正等待着我们共同探索。
我们诚邀全球开发者、技术爱好者加入SeaTunnel社区,共同参与到这场创新的征程中来。
SeaTunnel社区的发展离不开每一位成员的贡献和支持。我们热情地邀请更多的开发者加入我们,不仅是为了共同推进这些激动人心的新功能,更是为了在开源的精神下,共同探索数据处理领域的无限可能。
"一人快跑,众人同行,方能远行。" —— SeaTunnel社区期待你的加入。
新手入门

最佳实践

测试报告
Apache SeaTunnel
