




先来介绍一下问题背景:
同事A申请了一台服务器S自行安装(非交维:没有移交到运维部门统一规范管理)MySQL 5.7.13当作测试环境,因申请时,只考虑作为测试环境使用,所以MySQL没有开启binlog,也没有备份。
阴差阳错地,服务器S交到了另一个同事B手上,此时,机器的定位尚不明确,但是同事B在正式使用服务器S之前让我协助帮他们每天做备份,备份也没有强一致的要求。随着开发的迭代,这个库慢慢成为了生产环境。但还是没有正式交维(我们的工作流:如需交维,是需要向我们运维部门提交工单的)、机器的OWNER没有发生变更还是同事A(没有交维的机器,我们不会接手进行规范管理的,懂得都懂~)。
就在昨晚,同事A提交了机器回收申请(回收逻辑是服务器OWNER两次确认手动输入'确认回收指定主机xx.xx.xx.xx'文字后,运管平台直接会将对应服务器铲除)。服务器S属于同事A,在回收的时候没有和同事B沟通确认,直接回收导致了这次事故。然后同事B准备登录时发现连接不上服务器S了,经过运维部门SA同事协助排查,发现机器已经被推掉。
PS:后来了解到,这个库虽然数据量不大,但数据非常重要。存放的是用于参加ISO-27001信息安全体系认证评审的数据。
 坑就是这样这样来的,没有开启binlog的MySQL服务器直接被推掉了,这种事情比删库还严重,唯一庆幸的是:每天必做的冷备份,并将备份文件传输到中间备份机。还有一点,文章素材有了
坑就是这样这样来的,没有开启binlog的MySQL服务器直接被推掉了,这种事情比删库还严重,唯一庆幸的是:每天必做的冷备份,并将备份文件传输到中间备份机。还有一点,文章素材有了 。
。
原环境情况介绍
/usr/local/mysql/bin/mysqldump -u root -pxxxxxx -A --default-character-set=utf8 --hex-blob > /tmp/mysql_fullbackup_`date +%Y-%m-%d_%H-%M-%S`.sql
需要注意几点:
1、-p选项后面跟的是用户密码,-p选项和密码之前是不能有空白字符' '的,会发生不识别的情况,其他选项如-u、-P、-h可以跟空白字符。
2、mysqldump工具的--hex-blob选项,是将BINARY、VARBINARY、BLOB、BIT等二进制类型数据导出为十六进制,否则导出的文件会出现“乱码”的情况,同时,这个“乱码”在传输过程中,很容易发生改变。
3、mysqldump进行一致性备份时必须使用的两个参数:--single-transaction、--master-data=2。
--single-transaction:https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html#option_mysqldump_single-transaction(官档描述)
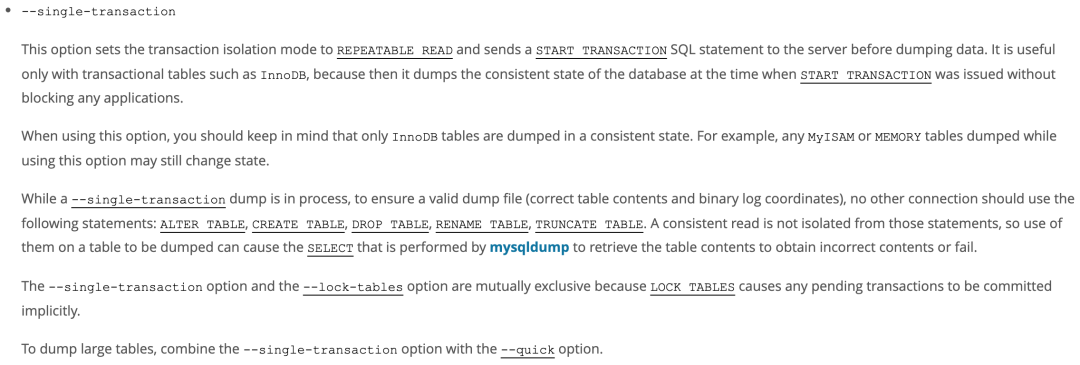
--master-data:https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html#option_mysqldump_master-data(官档描述)

本例中对备份无一致性要求且没有开启binlog,所以我们没有使用上述两个参数,直接进行了全实例的冷备份。
数据恢复 & 问题描述、定位、处理
数据恢复
MySQL Version:5.7.34(2台)MySQL Port:3306数据同步方式:ROW+GTID+增强半同步
环境搭建的流程如下:
1、主库环境安装MySQL,开启binlog、GTID;
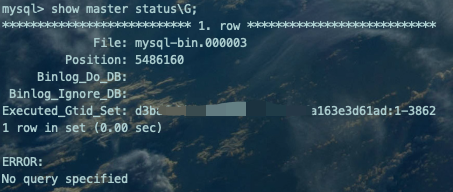
2、将备份文件导入新库,新库生成对应的GTID SET;
mysql3306 -p < mysql_fullbackup_`date +%Y-%m-%d_%H-%M-%S`.sqlshow master status\G;
CREATE USER 'repl'@'xx.xx.xx.%' IDENTIFIED BY 'xxxxxx';GRANT REPLICATION CLIENT,REPLICATION SLAVE on *.* to 'repl'@'xx.xx.xx.%';reset master;reset slave all;stop slave;CHANGE MASTER TO MASTER_HOST='xx.xx.xx.xx',MASTER_USER='repl',MASTER_PASSWORD='xxxxxx',MASTER_PORT=3306,master_auto_position=1;start slave;
4、在从库回放的过程中,我在从库设置并执行了备份操作,备份脚本核心备份语句如下:
xtrabackup --defaults-file=${mysqlconf} --lock-wait-timeout=300 --slave-info --safe-slave-backup --compress --parallel=${parallel} --user=${mysqluser} $([[ "${mysqlpassword}" = "" || ! "${mysqlpassword}" ]] || echo " --password=${mysqlpassword}") --tmpdir=${mysqlbackupdir} --stream=xbstream ${mysqlbackupdir} 2>>$backup_log | ssh -i ${scriptpath}/id_rsa backup@${backuphost} "xbstream -x -C ${backupdir}/${localhost}/mysql${mysqlport}/${time}" >>$backup_log 2>&1
问题描述

 ),Slave_IO_Running: Yes、Slave_SQL_Running: No。
),Slave_IO_Running: Yes、Slave_SQL_Running: No。more /mysql/mysql3306/bj-xx-xx-mysql-prod-xxxx.xxxxxxxxx.com.err | grep -C 20 'ERROR'

stop slave sql_thread;触发提示:[Note] Error reading relay log event for channel '': slave SQL thread was killedstart slave sql_thread;触发报错:[ERROR] Error reading slave worker configuration[ERROR] Error creating relay log info: Failed to initialize the worker info structure.
于是乎,我在从库手动执行启动复制的语句:
mysql> start slave;ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
手动执行的时候也报错了,错误日志见上述报错截图的第二个红框。然后我又查询了一下表mysql.slave_master_info、mysql.slave_relay_log_info数据:
SELECT * FROM mysql.slave_master_info;SELECT * FROM mysql.slave_relay_log_info;
问题定位
根据手动执行启动复制命令得到错误信息:启动复制时,使用repository中信息初始化relay log结构失败了。错误日志中也提示创建relay log报错:无法初始化worker进程。
根据错误日志中的信息去主库排查一下对应binlog的日志(未发现问题):
/usr/local/mysql3306/bin/mysqlbinlog -v -v --base64-output=decode-rows --start-position=5442597 /mysql/mysql3306/mysql-bin.000003 | more

问题处理
reset slave;CHANGE MASTER TO MASTER_HOST='xx.xx.xx.xx',MASTER_USER='repl',MASTER_PASSWORD='xxxxxx',MASTER_PORT=3306,master_auto_position=1;start slave;
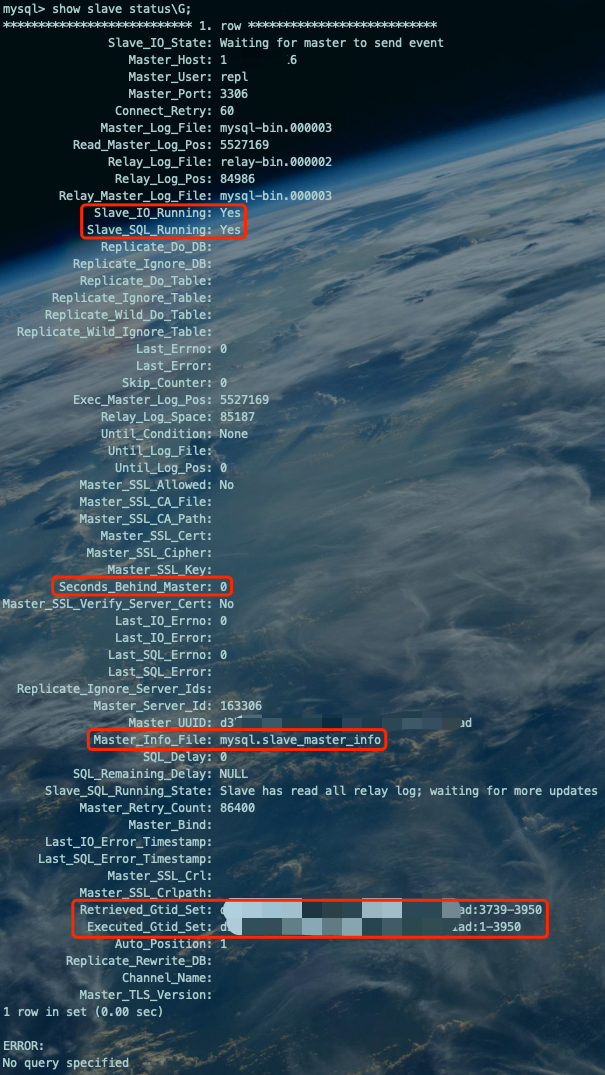
最后校验一下同步状态:
show slave status\G;
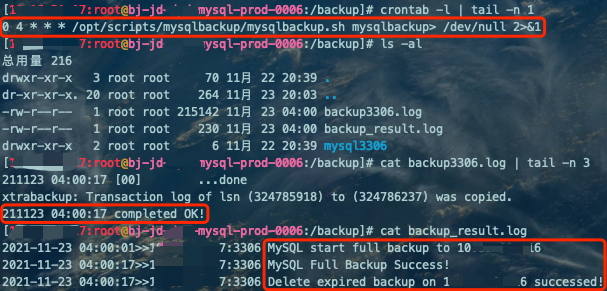
crontab -l | tail -n 1cat backup3306.log | tail -n 3cat backup_result.log
小结
。今天文中提到很多关于复制相关的知识点,后期也会慢慢更新有关复制原理的文章,大家拭目以待。又是干货满满的一天,我们下篇文章见,加油!~

end
