




点击上方蓝字关注我们

点击上方蓝字关注我们



融合多模型数据:在支持关系数据模型的基础之上支持 JSON, GIS,向量三种复杂数据类型 融合多种来源的数据:集群内部存储的数据,外部数据库,外部对象存储 融合开源生态组件:PostGIS,PostgresML, PGVector,等等 融合用户自定义算法:多语言(python, java, perl, lua, javascript, PL/SQL)存储过程。
XPanel: http://192.168.0.152:40180/KunlunXPanel/#/cluster 计算节点:192.168.0.152 ,端口: 47001 存储节点(shard1):192.168.0.153,端口:57003 (主) 存储节点(shard2):192.168.0.155,端口:57005 (主) 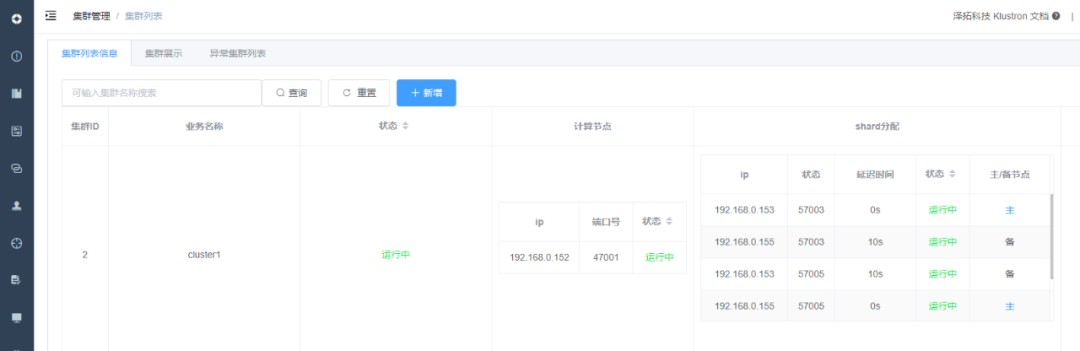
Klustron安装在kl用户下
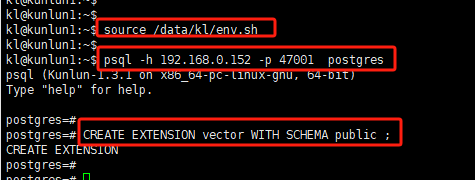
kl@kunlun1:~$ source data/kl/env.shkl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgrespostgres=# CREATE EXTENSION vector WITH SCHEMA public ;
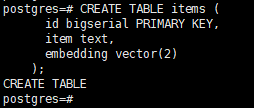
postgres=# CREATE TABLE items (id bigserial PRIMARY KEY,item text,embedding vector(2));
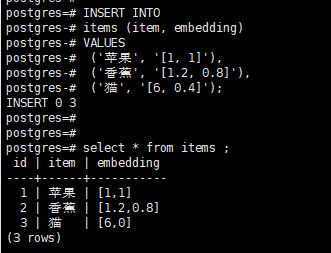
postgres=# INSERT INTO items (item, embedding)VALUES ('苹果', '[1, 1]'), ('香蕉', '[1.2, 0.8]'), ('猫', '[6, 0.4]');
postgres=# select * from items ;
postgres=# SELECT item, 1 - (embedding <=> '[6,0]') AS cosine_similarityFROM items ORDER BY cosine_similarity DESC;
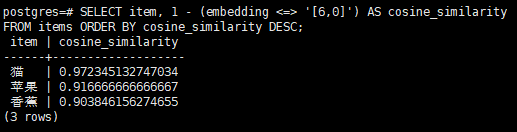
猫的结果为0.97,表示基本上最接近匹配; 苹果的结果为0.92,表示苹果与猫有一定相似; 香蕉的结果为0.90,表示香蕉与猫相似度更低。
root@kunlun1:/home/kl# pip3 install openai==0.28 psycopg2 tiktoken requests beautifulsoup4 numpy
kl@kunlun1:~$ source data/kl/env.shkl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgrespostgres=# CREATE TABLE rds_pg_help_docs (id bigserial PRIMARY KEY,title text, -- 文档标题description text, -- 描述doc_chunk text, -- 文档分块token_size int, -- 文档分块字数embedding vector(1024)); -- 文本嵌入信息
knowledge_chunk_storage.py---------------------------------------------import openaiimport psycopg2import tiktokenimport requestsfrom bs4 import BeautifulSoupEMBEDDING_MODEL = "text-embedding-ada-002"tokenizer = tiktoken.get_encoding("cl100k_base")# 连接Klustron数据库conn = psycopg2.connect(database="postgres",host="192.168.0.152",user="abc",password="abc",port="47001")conn.autocommit = True# OpenAI的API Keyopenai.api_key = '<Secret API Key>'# 自定义拆分方法(仅为示例用途)def get_text_chunks(text, max_chunk_size):chunks_ = []soup_ = BeautifulSoup(text, 'html.parser')content = ''.join(soup_.strings).strip()length = len(content)start = 0while start < length:end = start + max_chunk_sizeif end >= length:end = lengthchunk_ = content[start:end]chunks_.append(chunk_)start = endreturn chunks_# 指定需要拆分的网页url = 'https://help.aliyun.com/document_detail/148038.html'response = requests.get(url)if response.status_code == 200:# 获取网页内容web_html_data = response.textsoup = BeautifulSoup(web_html_data, 'html.parser')# 获取标题(H1标签)title = soup.find('h1').text.strip()# 获取描述(class为shortdesc的p标签内容)description = soup.find('p', class_='shortdesc').text.strip()# 拆分并存储chunks = get_text_chunks(web_html_data, 500)for chunk in chunks:doc_item = {'title': title,'description': description,'doc_chunk': chunk,'token_size': len(tokenizer.encode(chunk))}query_embedding_response = openai.Embedding.create(model=EMBEDDING_MODEL,input=chunk,)doc_item['embedding'] = query_embedding_response['data'][0]['embedding']cur = conn.cursor()insert_query = '''INSERT INTO rds_pg_help_docs(title, description, doc_chunk, token_size, embedding) VALUES (%s, %s, %s, %s, %s);'''cur.execute(insert_query, (doc_item['title'], doc_item['description'], doc_item['doc_chunk'], doc_item['token_size'],doc_item['embedding']))conn.commit()else:print('Failed to fetch web page')
替换 openai.api_key = '<Secret API Key>' 中的secret API key 为openai 的key; 替换 psycopg2.connect = …连接到你环境中的Klustron数据库。
kl@kunlun1:~$ export all_proxy="socks5h://127.0.0.1:1080" #本地代理配置示例kl@kunlun1:~$ python3 knowledge_chunk_storage.py
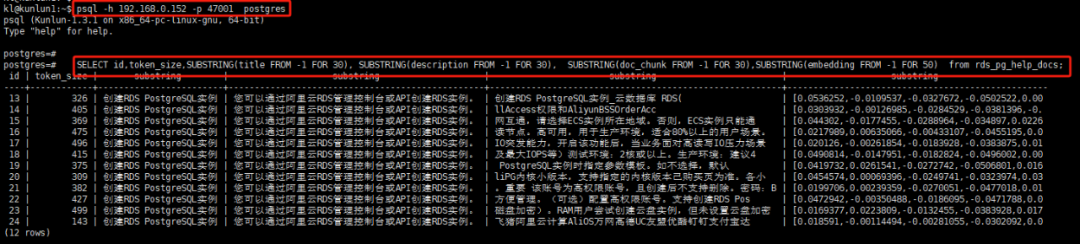
kl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgrespostgres=# SELECT id,token_size,SUBSTRING(title FROM -1 FOR 30), SUBSTRING(description FROM -1 FOR 30), SUBSTRING(doc_chunk FROM -1 FOR 30),SUBSTRING(embedding FROM -1 FOR 50) from rds_pg_help_docs;
chatbot.py------------------------------------------import openaiimport psycopg2from psycopg2.extras import DictCursorGPT_MODEL = "gpt-3.5-turbo"EMBEDDING_MODEL = "text-embedding-ada-002"GPT_COMPLETIONS_MODEL = "text-davinci-003"MAX_TOKENS = 1024# OpenAI的API Keyopenai.api_key = '<Secret API Key>'prompt = '如何创建一个RDS PostgreSQL实例'prompt_response = openai.Embedding.create(model=EMBEDDING_MODEL,input=prompt,)prompt_embedding = prompt_response['data'][0]['embedding']# 连接Klustron数据库conn = psycopg2.connect(database="postgres",host="192.168.0.152",user="abc",password="abc",port="47001")conn.autocommit = Truedef answer(prompt_doc, prompt):improved_prompt = f"""按下面提供的文档和步骤来回答接下来的问题:(1) 首先,分析文档中的内容,看是否与问题相关(2) 其次,只能用文档中的内容进行回复,越详细越好,并且以markdown格式输出(3) 最后,如果问题与RDS PostgreSQL不相关,请回复"我对RDS PostgreSQL以外的知识不是很了解"文档:\"\"\"{prompt_doc}\"\"\"问题: {prompt}"""response = openai.Completion.create(model=GPT_COMPLETIONS_MODEL,prompt=improved_prompt,temperature=0.2,max_tokens=MAX_TOKENS)print(f"{response['choices'][0]['text']}\n")similarity_threshold = 0.78max_matched_doc_counts = 8# 通过pgvector过滤出相似度大于一定阈值的文档块similarity_search_sql = f'''SELECT doc_chunk, token_size, 1 - (embedding <=> '{prompt_embedding}') AS similarityFROM rds_pg_help_docs WHERE 1 - (embedding <=> '{prompt_embedding}') > {similarity_threshold} ORDER BY id LIMIT {max_matched_doc_counts};'''cur = conn.cursor(cursor_factory=DictCursor)cur.execute(similarity_search_sql)matched_docs = cur.fetchall()total_tokens = 0prompt_doc = ''print('Answer: \n')for matched_doc in matched_docs:if total_tokens + matched_doc['token_size'] <= 1000:prompt_doc += f"\n---\n{matched_doc['doc_chunk']}"total_tokens += matched_doc['token_size']continueanswer(prompt_doc,prompt)total_tokens = 0prompt_doc = ''answer(prompt_doc,prompt)
替换 openai.api_key = '<Secret API Key>' 中的secret API key 为openai 的key; 替换 psycopg2.connect = …连接到你环境中的Klustron数据库。
kl@kunlun1:~$ python3 chatbot.py

源代码链接: https://github.com/zettadb/techtalk/blob/main/pgvector%E7%9A%84%E5%BA%94%E7%94%A8%E5%92%8C%E5%8E%9F%E7%90%86/clip.ipynb 关于这个demo的描述链接: https://doc.klustron.com/zh/Application_and_principle_of_pgvector.html#-1
文章转载自KunlunBase 昆仑数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
