




一,简介
pgpool-II 4.2版本较以前发生了表多的变化特别是将在下面介绍的运行模式上的差异,有很大的差异。
官方文档:https://www.pgpool.net/docs/latest/en/html/index.html
pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件
·提供以下功能:
▼连接池
▼连接限制
▼缓存
▼复制
▼负载均衡
▼看门狗
·Pgpool对服务器和应用来说几乎是透明的,现有的数据库应用程序基本上可以不需要更改就可以使用pgpool
连接池
Pgpool-II维护已经连接到postgresql的数据库连接,并当新连接连接时,如果存在具有相同连接信息(即用户名,数据库,协议版本和其他连接参数)的连接则直接使用它们。
它减少了连接开销并改善了系统的整体吞吐量。
作用:
资源重用
更快的系统响应速度
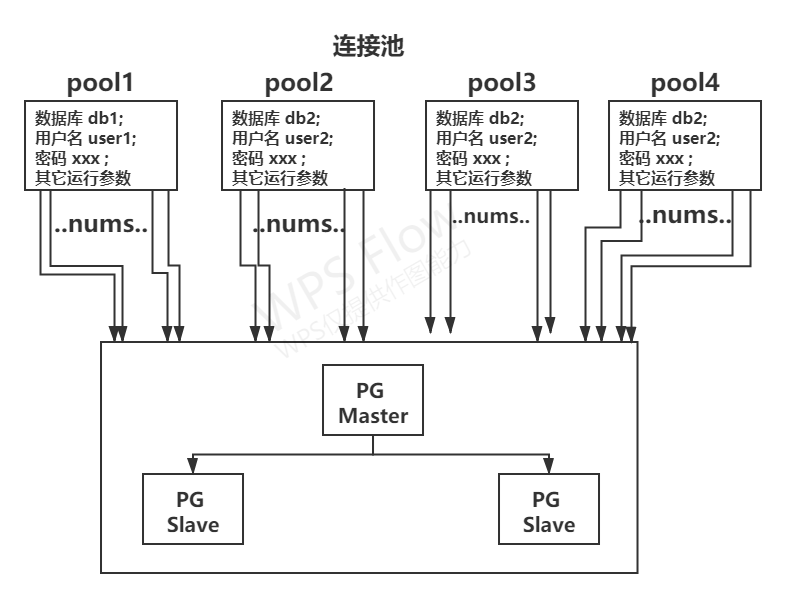
连接数的限制
PostgreSQL 会限制当前的最大连接数,当到达这个数量时,新的连接将被拒绝。 增加这个最大连接数会增加资源消耗并且对系统的全局性能有一定的负面影响。 pgpool-II 也支持限制最大连接数,但它的做法是将连接放入队列,而不是立即返回一个错误
相关的参数以及注意事项
max_pool
每个Pgpool-II子进程的最大缓存连接数。如果传入的连接连接到具有相同数据库、用户名和相同运行参数,Pgpool-II将重用缓存的连接。如果没有,Pgpool-II将创建一个到后端的新连接。如果缓存的连接数超过max_pool,最旧的连接将被丢弃,并将该槽用于新连接。
默认值为4。请注意,从Pgpool-II进程到后端的连接总数可能达到num_init_children * max_pool。这个也就是说,在同一批次的参数的链接这些归为一个pool。
比如上图所示的pool1 里面全是db1 user1 ;pool2 里面全是db2 user2…,max_pool为4,也就是说,pool最多有4个。
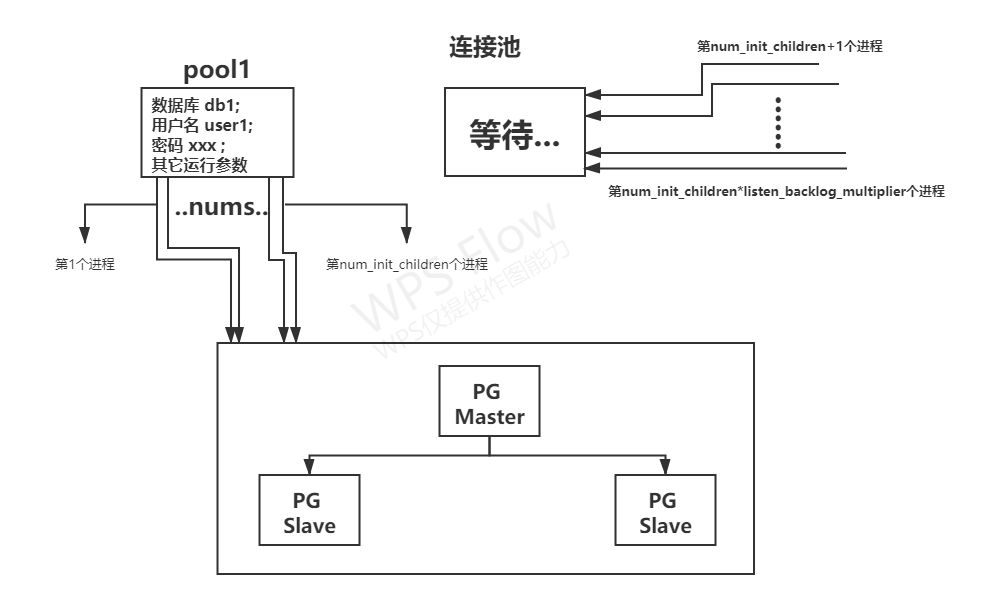
num_init_children
num_init_children 也是从客户端到 Pgpool-II 的并发连接限制。 如果超过 num_init_children 客户端尝试连接到 Pgpool-II,它们将被阻止,但是不会直接拒绝,直到与任何 Pgpool-II 进程的连接关闭,此处是假设reserved_connections设置为0。 最多可以排队 listen_backlog_multiplier* num_init_children。
该队列位于内核内部,称为“侦听队列”。 侦听队列的长度称为“积压”。 某些系统的backlog是有上限的,如果num_init_children*listen_backlog_multiplier超过这个数目,就需要把backlog设置的更高一些。 否则,重载系统可能会出现以下问题:
连接到 Pgpool-II 失败
由于内核中的重试,连接到 Pgpool-II 变得越来越慢
比如上图的,一个pool1 下面一共可以连接 num_init_children - reserved_connections个连接。
(reserved_connections参数: 默认为0,为0表示超过num_init_children并且没有超过num_init_children*listen_backlog_multiplier,会排队等待;
若为非0,假设为1,num_init_children为32,那么第32个链接将会被拒绝,没有等待)
下图为reserved_connections=0的示意图
系统中 可以使用netstat -s来观察目前系统的一个队列情况(过滤关键词:listen queue)
sysctl net.core.somaxconn 查看目前系统设置的最大队列数
用管理员用户可以通过命令sysctl -w net.core.somaxconn = 256 来进行修改和设置。
基于内存的查询缓存
你可以在任何模式中使用基于内存的查询缓存。它不同于以上的查询缓存,因为基于内存的查询缓存会快很多,因为缓存存储于内存中。 另外,如果缓存事小了,你不需要重启 pgpool-II 因为相关的表已经得到更新了。
基于内存的缓存保存 SELECT 语句(以及它绑定的参数,如果 SELECT 是一个扩展的查询)以及对应的数据。 如果是相同的 SELECT 语句,则直接返回缓存的值。因为不再有 SQL 分析或者到 PostgreSQL 的调用,实际上它会非常快。
其他方面,它会比较慢,因为它增加了一些负载用于缓存。另外,当一个表被更新,pgpool 自动删除相关的表的缓存。 因此,在有很多更新的系统中,性能会降低。如果 cache_hit_ratio 低于 70%,建议你关闭基于内存的缓存。
限制
基于内存的查询缓存通过监视 UPDATE,INSERT,ALTER TABLE一类的查询语句来自动删除缓存的数据。 但pgpool-II 无法发现通过触发器、外键和 DROP TABLE CASCADE 产生的非显式的更新。 你可以通过配置 memqcache_expire 让 pgpool 在固定时间周期内自动删除缓存来避免这个问题, 你也可以通过配置 black_memqcache_table_list 来让 pgpool 的基于内存的缓存忽略指定的表。
如果你使用 pgpool-II 的多个实例来使用共享内存进行缓存,可能出现一个 pgpool 发现表被更新了因而删除了缓存,但另一个依旧使用旧的缓存。 对于这种情况,使用 memcached 是一个更好的策略。
pgpool复制
pgpool-II 可以管理多个 PostgreSQL 服务器。 激活复制功能并使在2台或者更多 PostgreSQL 节点中建立一个实时备份成为可能, 这样,如果其中一台节点失效,服务可以不被中断继续运行。
这个呢我们也是一般配置pg自己的流复制然后上面一次pgpool 这样也是同样来实现,其实pgpool的复制,他也是通过pg自身的pg_basebackup来做的复制
负载均衡
如果数据库进行了复制(可能运行在复制模式或者主备模式下), 则在任何一台服务器中执行一个 SELECT 查询将返回相同的结果。 pgpool-II 利用了复制的功能以降低每台 PostgreSQL 服务器的负载。 它通过分发 SELECT 查询到所有可用的服务器中,增强了系统的整体吞吐量。 在理想的情况下,读性能应该和 PostgreSQL 服务器的数量成正比。 负载均衡功能在有大量用户同时执行很多只读查询的场景中工作的效果最好。
负载均衡的条件
需要对一个查询使用负载均衡,需要满足一些条件:
PostgreSQL 7.4 或更高版本
在复制模式(流复制、逻辑复制、slony复制)或本机复制模式下
查询必须不是在一个显式的事务中(例如,不在 BEGIN ~ END 块中)
事务隔离级别不是 SERIALIZABLE
不能是 SELECT INTO
事务尚未发出写查询
不能是 SELECT FOR UPDATE 或者 FOR SHARE
以 “SELECT” 开始或者为 COPY TO STDOUT, EXPLAIN, EXPLAIN ANALYZE SELECT… 其中一个,ignore_leading_white_space = true 将忽略开头的空格。
在本机复制模式下,除上述条件外,还必须满足以下条件:
不使用临时表
不使用unlogged的表
不使用系统目录
注意你可以通过在 SELECT 语句之前插入任意的注释来禁止负载均衡:
/REPLICATION/ SELECT …
通常,如果满足某些条件,读查询是负载平衡的。但是,写查询可能会影响负载平衡。此处“写查询”指除以下查询外的所有查询:
SELECT/WITH 不写函数。 Volatile 函数被视为写入函数。
SELECT/WITH without FOR UPDATE/SHARE
WITH without DML statements
COPY TO STDOUT
EXPLAIN
EXPLAIN ANALYZE and the query is SELECT not including writing functions
SHOW
(附:
关于Volatile函数:
每一个函数都有一个易变性分类,可能是 VOLATILE、STABLE或者IMMUTABLE。 如果CREATE FUNCTION命令没有指定一个分类,则默认是 VOLATILE。易变性分类是给优化器的关于该函数行为的一种承诺:
一个VOLATILE函数可以做任何事情,包括修改数据库。在使用相同的参数连续调用时,它能返回不同的结果。
一个STABLE函数不能修改数据库并且被确保对一个语句中的所有行用给定的相同参数返回相同的结果。
一个IMMUTABLE函数不能修改数据库并且被确保用相同的参数 永远返回相同的结果。。例如,一个 SELECT … WHERE x =1 + 2这样的查询可以被简化为 SELECT … WHERE x = 3,因为整数加法操作符底层的函数被 标记为IMMUTABLE。
我们在创建函数索引的时候某一些函数是不能建立函数索引的,只能用IMMUTABLE函数来创建函数索引)
流复制模式下负载均衡条件
流复制模式是官方最推荐的方式,也是最流行的使用方式,所以这里给大家罗列了一些关于这个流复制的一些情况只会发送到主节点。一些,DML、DDL、锁、事务、游标、序列器、vacuum操作,这里就不一一列举了。
看门狗
“看门狗”是一个 pgpool-II 的子进程,用于添加高可用性功能。 这通过多个 pgpool-II 的合作解决了单点故障的问题。
pgpool-II 4.1或更早版本,因为需要指定自己的pgpool节点信息和目的pgpool节点信息,每个pgpool节点的设置都不一样。 从 Pgpool-II 4.2 开始,所有主机上的所有配置参数都相同。 如果启用了看门狗功能,要区分哪个主机是哪个,需要一个 pgpool_node_id 文件。 您需要创建一个 pgpool_node_id 文件并指定 pgpool(看门狗)节点号(例如 0、1、2 …)来识别 pgpool(看门狗)主机。
看门狗提供以下功能。
pgpool-II 服务的生命检测
看门狗的存活检测是看门狗用于监控用于提供高可用的看门狗集群中的 pgpool-II 节点的健康状况的子组件。 “heartbeat(心跳)”和“query(查询)”模式。pgpool-II V3.5 - 中的看门狗添加新的“external(外部)” 健康检测方法,启用了让 pgpool-II 的看门狗关联一个外部的第三方健康检测系统的能力。 参考在看门狗中集成外部存活检测功能获取关于让看门狗关联第三方系统的细节。 除了远程健康检测,看门狗存存活检测还可以通过监控到上游服务的连接来检测安装的节点的健康状况。
在心跳模式中,看门狗使用心跳信号监控其他 pgpool-II 进程。看门狗接收其他 pgpool-II 定期发送的心跳信号。 如果时间周期到了还没收到信号,则看门狗认为 pgpool-II 已经失效。 为了冗余,你可以使用多个网络接口设备来在 pgpool-II 之间实现心跳交换。这是默认的模式,且推荐使用。
在查询模式中,看门狗监控 pgpool-II 提供的服务,而不是进程。看门狗向其他 pgpool-II 发送查询并检查反馈。 注意这种模式需要连接到其他 pgpool-II,所以如果 num_init_children 不够大则可能监控失败。 本模式不赞成使用,保留的原因是为了向下兼容。
"external(外部)"V3.5 -模式禁用了 pgpool-II 看门狗的内置存活检测, 期望外部系统通知看门狗关于本看门狗集群中本地和远程节点的健康状况。
看门狗还监控到从 pgpool-II 到前端服务器的连接(例如应用服务器),并检查 pgpool-II 能否为这些服务提供服务。如果监控到失败,则认为 pgpool-II 宕机了。
协调多个 pgpool-II 共同工作
看门狗通过互相交换信息来协调多个 pgpool-II 共同工作。
在后端节点例如由于故障切换而发生状态变化后,看门狗通知其他 pgpool-II 节点并同步信息。 在发生在线恢复时,看门狗限制客户端连接到其他 pgpool-II 节点,以避免后端节点的不一致。
故障切换或者故障恢复的命令 (failover_command, failback_command, follow_master_command) 通过内部锁机制只被一个 pgpool-II 节点执行。
V3.5 -校验所有节点重要配置参数的一致性
启动的时候,看门狗会校验 pgpool-II 本地节点的配置与主看门狗节点配置的一致性。 这排除了由于不同 pgpool-II 节点的配置可能导致的非预期行为。
在检测到某些故障时交换活跃/备用状态
当一个 pg数据库的故障被检测到,看门狗通知其他的看门狗这个消息。 如果是活跃的 pg数据库发生故障,看门狗通过投票确定新的活跃 pg并更新活跃/备用状态。
在服务器切换的时候实现自动虚拟 IP 地址分配
当一个备用 pgpool 服务器提升为活跃的,新的活跃服务器启动虚拟 IP 接口。 也就是,之前的活跃服务器停用虚拟 IP 接口。 这确保活动的 pgpool 使用相同的 IP 地址,即使在发生服务器切换的时候。
在恢复的时候自动注册服务器为备用服务器
当失效的服务器恢复或者新的服务器连接上来,看门狗进程通知其他的看门狗进程关于新服务器的信息, 看门狗进程在活跃服务器和其他服务器上接收这些信息。 然后,新连接上的服务器注册为备用节点
启动/停止看门狗
看门狗进程由 pgpool-II 自动启动/停止,也就是说,没有单独的命令来启动/停止它。 但是,pgpool-II 启动时必须拥有管理员权限(root), 因为看门狗进程需要控制虚拟 IP 接口。
在等待到所有的 pgpool 启动后,生命监测将启动。
所以在启动pgpool时使用root用户启动
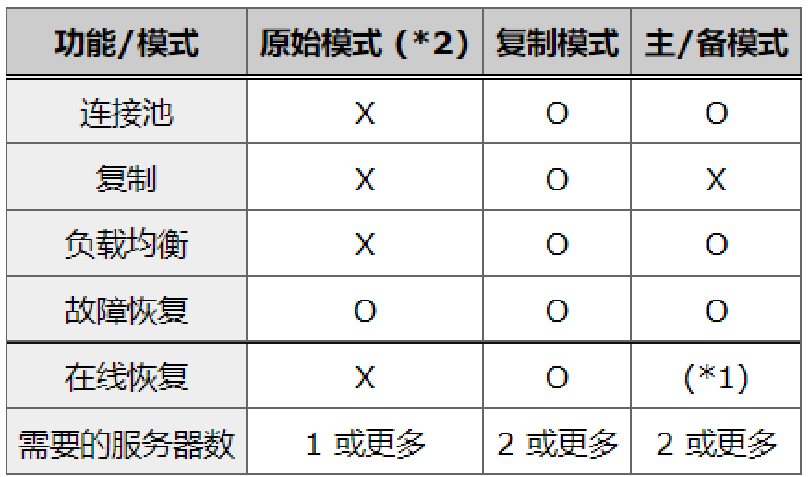
二,服务模式
pgpool 4.2版本较以前发生了表多的变化特别是将在下面介绍的运行模式上的差异,有很大的差异。
4.1-版本
4.2版本:

模式的控制参数是backend_clustering_mode 值可能是这些streaming_replication、logical_replication、slony、native_replication、snapshot_isolation、raw分别对应的是流复制模式、逻辑复制模式、Slony 模式、本机复制模式、快照隔离模式、原始模式 ;
可以使用负载均衡的包括流复制模式、逻辑复制模式、Slony 模式、本机复制模式 ,其中最流行并且官方最推荐的是流复制模式;
Pg负责复制的有:流复制模式、逻辑复制模式
Slony模式是中间件Slony-I负责复制,slony-I是以前我们pg还没有逻辑复制的时候出来的一款基于触发器的一个复制的中间件,有兴趣的小伙伴可以下来了解一下;
本机复制模式是pgpool-II负责复制;
模式类似于原生复制模式,只是增加了节点之间的可见性一致性。(基于一篇论文而做出来的一个东西,大概说的是复制中间件保证快照隔离而不需要修改数据库服务器,有兴趣的小伙伴可以下来研究一下这篇论文)
本机复制 Pgpool-II 不关心数据库同步问题,完全交给用户去处理
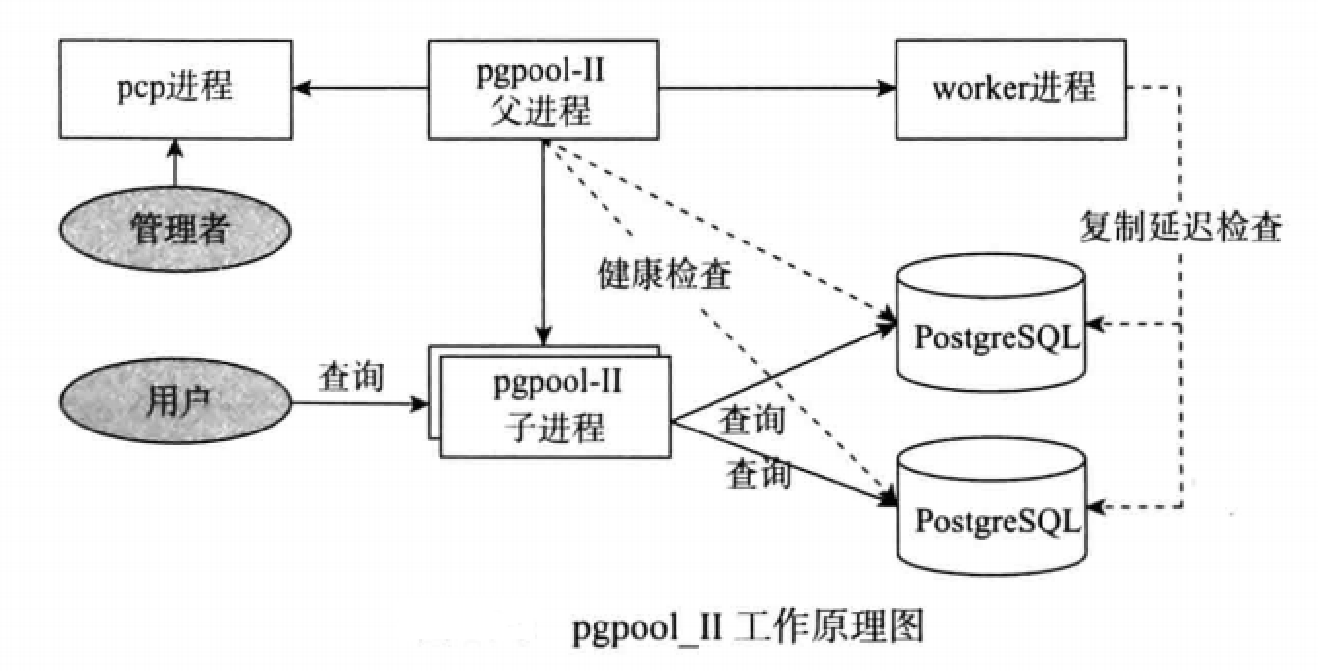
PGPOOL概念图
Pgpool子进程:接受 发送sql
Work进程:检查延迟情况。
Health Check:检查pg存活状态进程
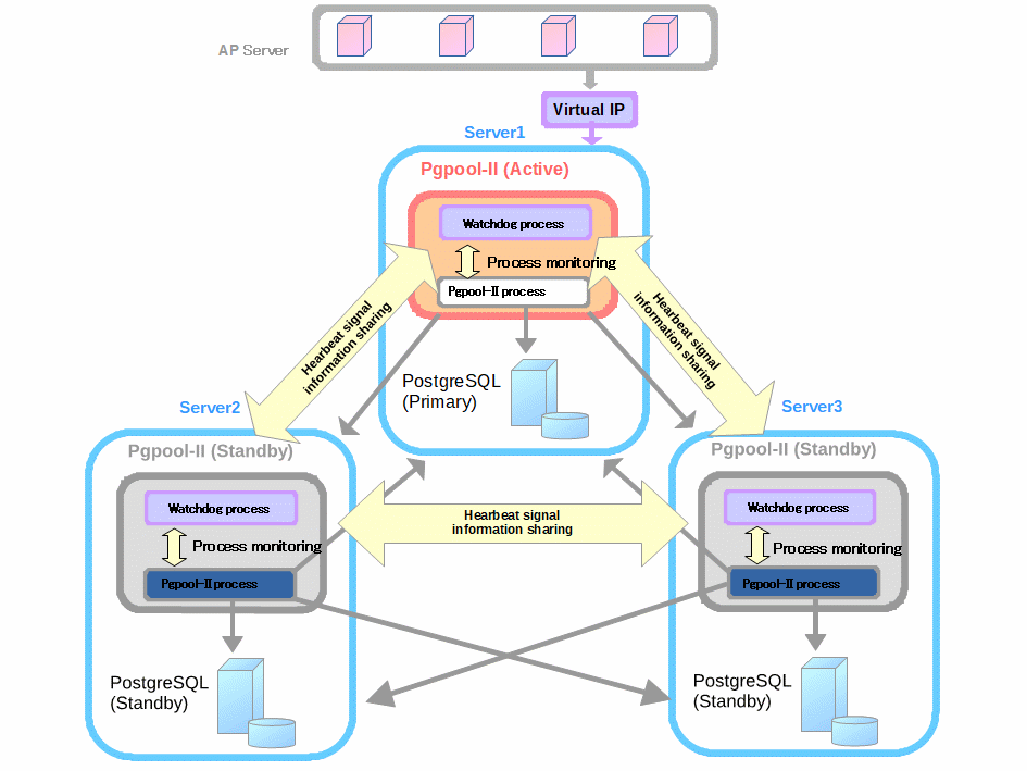
三,pgpool工作进程
Pgpool的服务进程。
Pcp进程:向pgpool发送管理命令的
父进程:负责检查数据库健康
Pgpool子进程:接受 发送sql
Work进程:检查延迟情况。
Pgpool logger:记录日志
Health Check:检查pg存活状态进程
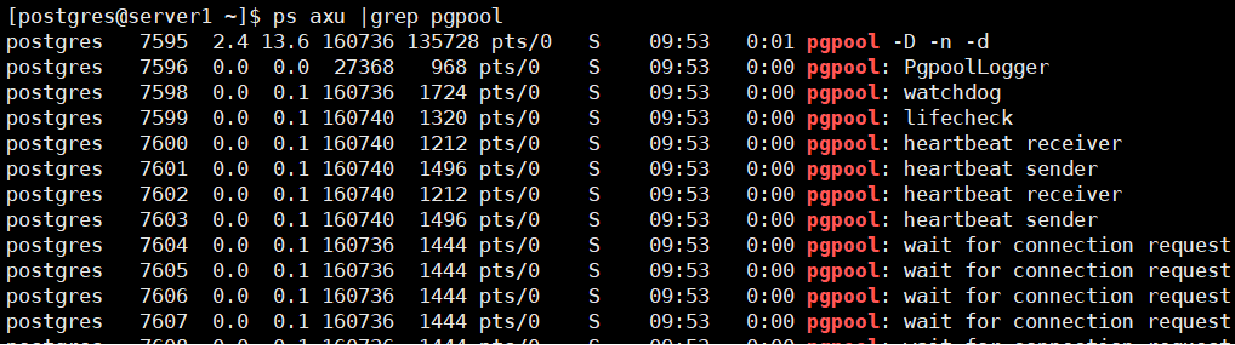
下面是我虚拟机上面的一些进程切图:

四,总结
pgpool自身带的负载均衡很不错,相对于pacemaker、patroni这些,负载均衡在pgpool上都是做的不错的。
配置了recovery更方便,可以使用脚本来实现自己恢复方式
但是节点之间需要互信,这对一些安全要求高的环境可能不太适用,这个呢就是有些环境可能会对这方面要求比较高。
基于中间件,截取/分发 性能损耗。
下一篇:PGPOOL部署安装,高可用切换测试:https://www.modb.pro/db/176886
