




低秩适应(Low-Rank Adaptation,LoRA)可以被认为是一项重大突破,它能够有效地训练大型语言模型以执行特定任务。如今,它在许多应用中被广泛使用,并且已经激发了研究如何改进其主要思想以实现更好性能或更快速地训练模型的工作。
在本文中,我将概述一些LoRA的变体,这些变体以不同的方式改进LoRA的能力。我将首先解释LoRA本身的基本概念,然后介绍LoRA+、VeRA、LoRA-FA、LoRA-drop、AdaLoRA、DoRA和Delta-LoRA。
Lora
LoRA: Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., … & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
Low-Rank Adaption (LoRA) 如今被广泛用于训练大型语言模型(LLMs)。大型语言模型具有预测自然语言输入的标记的能力。这是一项令人惊讶的能力,但对于解决许多问题来说,这还不够。
大多数情况下,希望将LLM训练用于给定的下游任务,例如对句子进行分类或生成对给定问题的答案。最直接的方法是微调,在微调中,您使用所需任务的数据训练LLM的一些层。但这意味着需要训练拥有数百万到数十亿参数的非常庞大的模型。
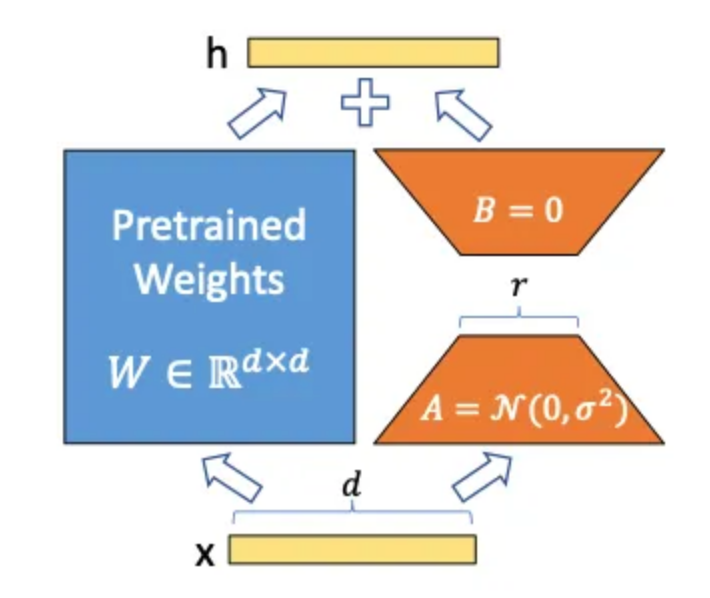
LoRA(低秩适应)提供了一种替代训练方式,由于参数数量大幅减少,因此训练速度更快,更容易进行。除了已经预先训练的LLM层的参数权重外,LoRA还引入了两个矩阵和,称为适配器,这两个矩阵要小得多。
如果原始参数矩阵的大小为,则矩阵和的大小为和,其中要小得多(通常低于100)。参数称为秩。也就是说,如果您使用秩为的LoRA,则这些矩阵的形状为。秩越高,训练的参数越多。这可能会在一方面带来更好的性能,但另一方面需要更多的计算时间。
现在我们有了这些新的矩阵和,它们会发生什么呢?将输入馈送给的同时也会提供给,并且的输出会加到原始矩阵W的输出上。也就是说在顶部训练了一些参数,并将它们的输出添加到原始预测中,从而可以影响模型的行为。此时不再对进行训练,这就是为什么我们有时会说被冻结了。重要的是,和的加法不仅仅在最后一层进行(这只会在顶部添加一层),而且可以应用于神经网络中深层的层次。
与微调相比,LoRA需要训练的参数更少,但仍然可以获得可比较的性能。我想在这里提及的另一个技术细节是:在开始时,矩阵被初始化为均值为零的随机值,但在该均值周围具有一定的方差。矩阵被初始化为完全为零的矩阵。这确保了LoRA矩阵不会从一开始就以随机方式改变原始W的输出。一旦调整了和的参数朝着期望的方向,它们对的输出的更新应该是对原始输出的添加。
LoRA+
LoRA+: Hayou, S., Ghosh, N., & Yu, B. (2024). LoRA+: Efficient Low Rank Adaptation of Large Models. arXiv preprint arXiv:2402.12354.
LoRA+ 引入了一种更有效的训练LoRA适配器的方法,通过为矩阵A和B引入不同的学习率。在训练神经网络时,通常只有一个学习率被应用于所有权重矩阵。然而,对于LoRA中使用的适配器矩阵,LoRA+的作者可以证明,拥有单一学习率是次优的。通过将矩阵B的学习率设置得比矩阵A的学习率高得多,训练变得更加高效。
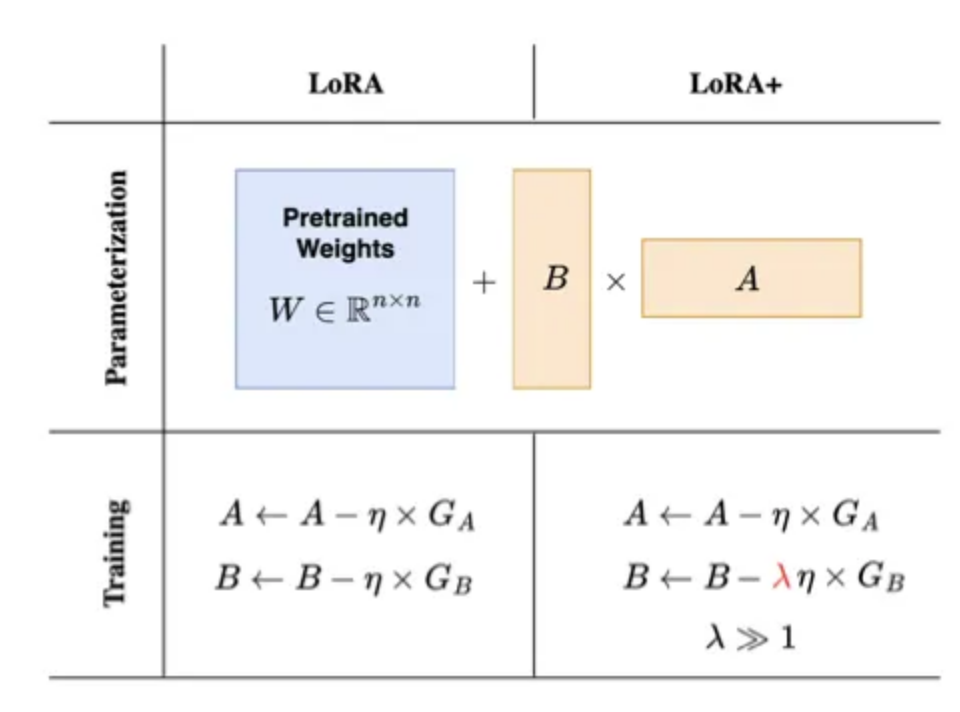
这种方法有一个理论上的论据来证明其有效性,主要基于神经网络初始化的数值注意事项,特别是当模型在其神经元数量上变得非常宽时。然而,证明这一点所需的数学相当复杂。直觉上用零初始化的矩阵B可以使用比随机初始化的矩阵A更大的更新步长。此外,还有经验性证据证明了这种方法的改进。通过将矩阵B的学习率设置为矩阵A的16倍,作者已经能够在模型准确性上取得小幅提升(约为2%),同时将RoBERTa或Llama-7b等模型的训练时间加快了两倍。
VeRA
VeRA: Kopiczko, D. J., Blankevoort, T., & Asano, Y. M. (2023). Vera: Vector-based random matrix adaptation. arXiv preprint arXiv:2310.11454.
VeRA(Vector-based Random Matrix Adaptation)介绍了一种极大减少LoRA适配器参数大小的方法。与LoRA的核心思想相反,他们不是训练矩阵和,而是将这些矩阵初始化为共享的随机权重(即所有层中的所有矩阵和具有相同的权重),并添加两个新向量和。接下来只训练这些向量和。
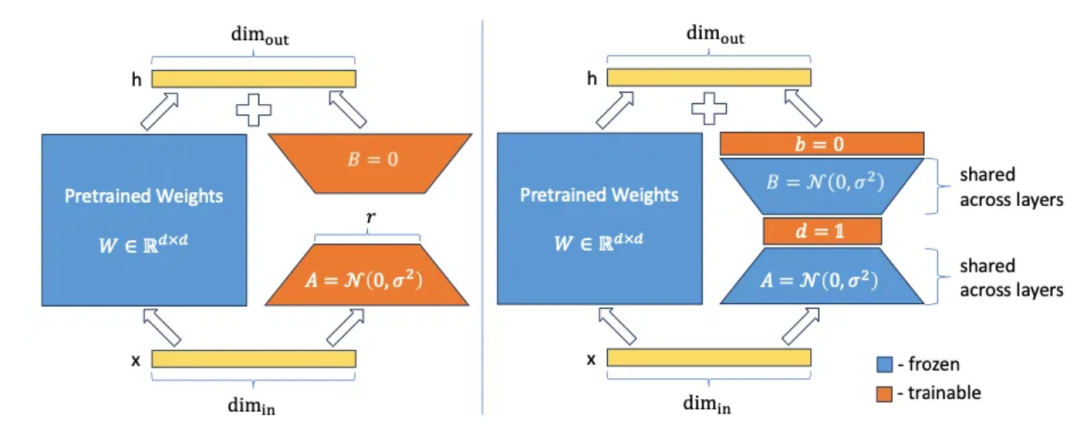
矩阵和是随机权重的矩阵。如果它们根本没有经过训练,它们如何对模型的性能做出贡献呢?这种方法基于一个有趣的研究领域,即所谓的随机投影。有相当多的研究表明,在一个大型神经网络中,只有一小部分权重被用来引导行为,并导致模型在训练时达到期望的性能。由于随机初始化,模型的某些部分(或子网络)从一开始就对期望的模型行为做出了更多的贡献。 在训练过程中,所有参数都会被训练,因为现在已知哪些是重要的子网络。这使得训练非常昂贵,因为大多数更新的参数对模型的预测没有任何价值。
基于这个想法,有一些方法只训练这些相关的子网络。通过在矩阵后添加投影向量,可以获得类似的行为。由于矩阵与向量的乘积,这可能会导致与调整矩阵中的一些稀疏参数相同的输出。这正是VeRA的作者通过引入向量和所提出的,这些向量是经过训练的,而矩阵和是冻结的。此外,与原始的LoRa方法相比,矩阵B不再被设置为零,而是像矩阵A一样随机初始化。
这种方法自然地导致了比完整的矩阵和小得多的参数数量。例如,如果将LoRA层的秩设置为16到GPT-3中,你将会有7550万个参数。而使用VeRA,您只有280万个参数(减少了97%)。但是,这样少量的参数如何影响性能呢?VeRA的作者对一些常见的基准测试进行了评估,例如GLUE或E2E,以及基于RoBERTa和GPT2 Medium的模型。他们的结果表明,VeRA模型的性能与完全微调的模型或使用原始LoRa技术的模型相比只略低。
LoRA-FA
LoRA-FA: Zhang, L., Zhang, L., Shi, S., Chu, X., & Li, B. (2023). Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning. arXiv preprint arXiv:2308.03303.
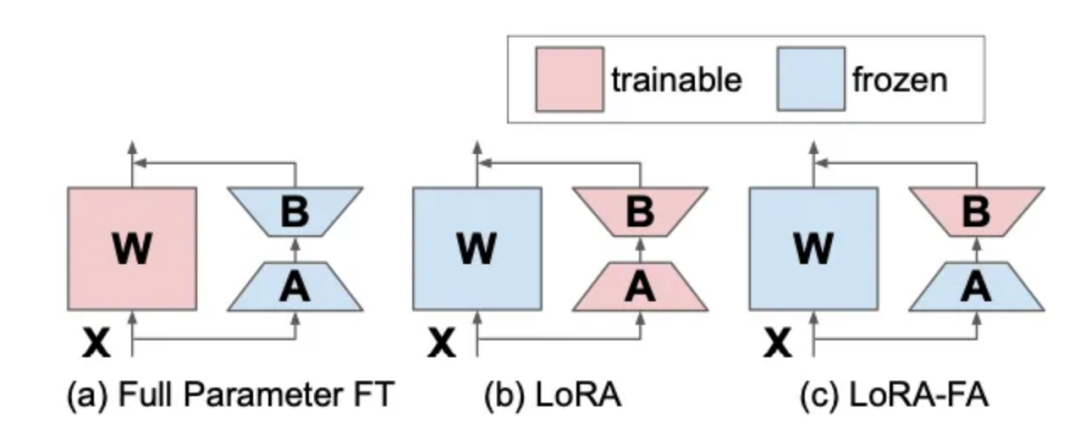
LoRA-FA代表的是带有Frozen-A的LoRA,它与VeRA的方向类似。在LoRA-FA中,矩阵A在初始化后被冻结,因此作为一个随机投影。不过,与添加新向量不同,矩阵B在初始化为零后进行训练(就像在原始的LoRA中一样)。这样可以减少一半的参数数量,同时性能与普通的LoRA相当。
LoRa-drop
LoRA-drop: Zhou, H., Lu, X., Xu, W., Zhu, C., & Zhao, T. (2024). LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation. arXiv preprint arXiv:2402.07721.
LoRA-drop引入了一个算法来决定哪些层值得通过LoRA进行增强,以及哪些不值得这样做。即使训练LoRA适配器比微调整个模型要便宜得多,但你添加的LoRA适配器越多,训练的成本就越高。
LoRA-drop包括两个步骤。在第一步中,你对数据的一个子集进行抽样,并训练LoRA适配器几次迭代。然后,你计算每个LoRA适配器的重要性,计算方法是,其中和是LoRA矩阵,是输入。这简单地是LoRA适配器的输出,它被添加到每个冻结层的输出中。如果这个输出很大,它会更显著地改变冻结层的行为。如果它很小,这表明LoRA适配器对冻结层的影响很小,可以省略。
有了这个重要性,现在你选择最重要的LoRA层。有不同的做法。你可以将重要性值加总直到达到一个由超参数控制的阈值,或者你只选择具有固定个最高重要性的顶部个LoRA层。无论如何,在下一步中,你对整个数据集进行完整的训练(记住你在之前的步骤中使用了一个数据子集),但只在你刚刚选择的那些层上进行。其他层被固定到一组共享的参数上,在训练过程中不再更改。
因此LoRA-drop算法允许只对LoRA层的子集进行模型训练。作者提出的经验性证据表明,与训练所有LoRA层相比,准确度只有轻微的变化,但由于需要训练的参数数量减少,计算时间也相应减少。
AdaLoRA
AdaLoRA: Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y., Chen, W., & Zhao, T. (2023). Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512.
AdaLoRA 是自适应LoRa。这里的LoRA的哪一部分是自适应的?是LoRA矩阵的秩(即大小)。向每一层添加LoRA矩阵和可能没有价值,但对于某些层,LoRA训练可能比其他层更重要(即可能导致模型行为更改更多)。为了确定这种重要性,AdaLoRA的作者提出考虑LoRA矩阵的奇异值作为其重要性的指标。
这是什么意思?首先,我们必须理解,矩阵乘法也可以看作是将函数应用于向量。在处理神经网络时,这是很明显的:大多数时候,你使用神经网络作为函数,即你提供一个输入(比如说,一个像素值的矩阵),然后得到一个结果(比如说,对图像的分类)。在幕后,这个函数应用是由一系列矩阵乘法驱动的。现在,假设你想要减少这样一个矩阵中的参数数量。这将改变函数的行为,但你希望它改变得尽可能小。一个方法是计算矩阵的特征值,它告诉你矩阵的每行捕获了多少方差。
然后,你可以决定将一些只捕获了很小方差的行设置为零,因此对函数不会添加太多信息。这就是AdaLoRA的主要思想,因为前面提到的奇异值正好是特征值的平方根。也就是说,基于奇异值,AdaLoRA决定了LoRA矩阵的哪些行更重要,哪些可以省略。这有效地缩小了一些矩阵的秩,其中有许多行不贡献太多。然而,需要注意与上一节的LoRA-drop的一个重要区别:在LoRA-drop中,一个层的适配器被选择为完全训练,或者根本不进行训练。AdaLoRA还可以决定保留一些层的适配器,但秩较低。这意味着最终,不同的适配器可以具有不同的秩(而在原始的LoRA方法中,所有的适配器都具有相同的秩)。
AdaLoRA方法还有一些细节,由于篇幅原因我省略了。通过将AdaLoRA与具有相同秩预算的标准LoRA进行比较,可以得出该方法的实证证据。也就是说,两种方法总共具有相同数量的参数,但这些参数分布不同。在LoRA中,所有矩阵具有相同的秩,而在AdaLoRA中,一些矩阵具有更高的秩,一些矩阵具有较低的秩,最终导致相同数量的参数。在许多场景中,AdaLoRA比标准LoRA方法产生更好的分数,表明可训练参数在模型的特定重要部分上分布更好。下图是一个例子,展示了AdaLoRA为给定模型分配秩的方式。正如我们所见,它给了模型末尾的层更高的秩,表明调整这些层更为重要。
DoRA
DoRA: Liu, S. Y., Wang, C. Y., Yin, H., Molchanov, P., Wang, Y. C. F., Cheng, K. T., & Chen, M. H. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv preprint arXiv:2402.09353.
DoRA的起点是每个矩阵都可以分解为幅度和方向的乘积的想法。对于二维空间中的向量,你可以很容易地将其可视化:一个向量就是从零点开始并在向量空间中的某一点结束的箭头。通过向量的分量,你指定了该点,例如,通过说和,如果你的空间有两个维度和。或者,你可以通过指定一个幅度和一个角度(即方向)来用不同的方式描述完全相同的点,例如m=√2和a=45°。这意味着你从零点开始,在45°的方向上移动,箭头长度为√2。这将带你到相同的点(x=1,y=1)。
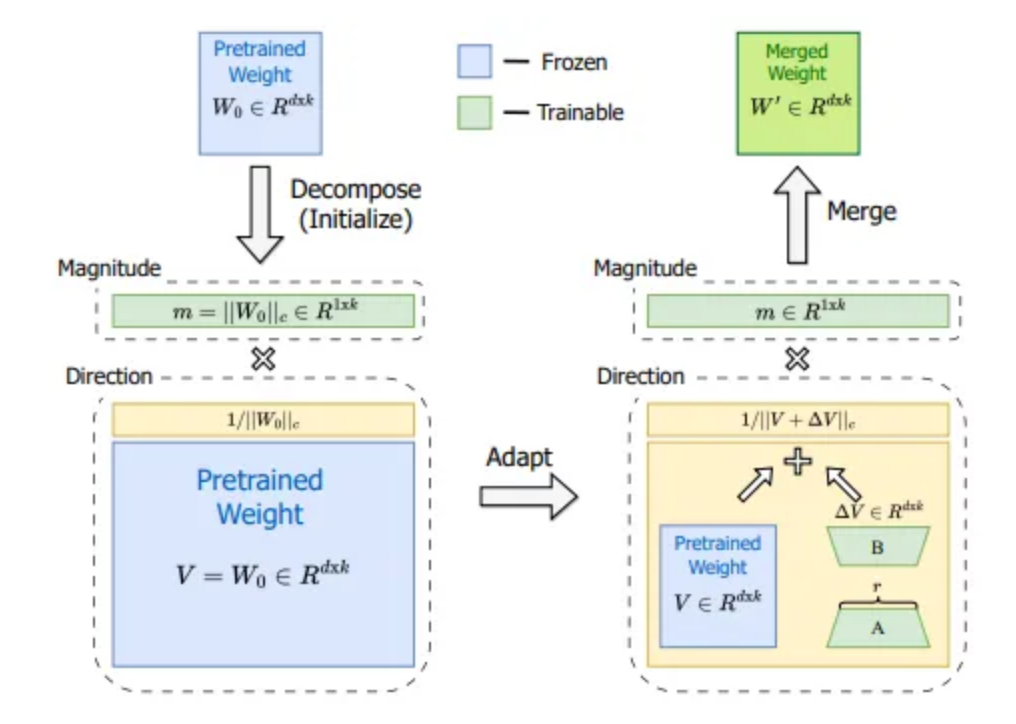
DoRA的作者将此应用于描述训练步骤中的更新的权重矩阵,用于使用普通微调和使用LoRA适配器进行训练的模型。我们看到两个图,一个用于经过微调的模型(左图),一个用于使用LoRA适配器进行训练的模型(右图)。在x轴上,我们看到方向的变化,在轴上,我们看到幅度的变化,图中的每个散点都属于模型的一个层。在两种训练方式之间有一个重要的区别。
在左图中,方向的更新与幅度的更新之间存在微弱的负相关,而在右图中,存在更强的正相关关系。你可能会想知道哪种方式更好,或者这是否有任何意义。请记住,LoRA的主要思想是实现与微调相同的性能,但参数更少。也就是说,理想情况下,我们希望LoRA的训练与微调共享尽可能多的属性,只要这不增加成本。如果在微调中,方向和幅度之间的相关性稍微为负,那么如果可能的话,这也可能是LoRA所希望的属性。换句话说,如果LoRA中方向和幅度之间的关系与完全微调不同,这可能是LoRA有时表现不佳的原因之一。
DoRA的作者介绍了一种方法,通过将预训练矩阵分解为大小为的幅度向量m和方向矩阵来独立地训练幅度和方向。然后,方向矩阵V像标准LoRA方法中一样被增强,而则直接进行训练,因为它只有一个维度。虽然LoRA倾向于同时改变幅度和方向,但DoRA可以更容易地调整其中之一,或通过对其中一个的负变化来抵消另一个的变化。
Delta-LoRA
Delta-LoRA: Zi, B., Qi, X., Wang, L., Wang, J., Wong, K. F., & Zhang, L. (2023). Delta-lora: Fine-tuning high-rank parameters with the delta of low-rank matrices. arXiv preprint arXiv:2309.02411.
Delta-LoRA引入了另一个改进LoRA的想法。Delta-LoRA的作者提出通过的梯度来更新矩阵,其中是两个连续时间步骤中之间的差异。这个梯度与一些超参数λ相乘,它控制了新训练对预训练权重影响的大小,并添加到中(其中和(秩)是原始LoRA设置的超参数)。
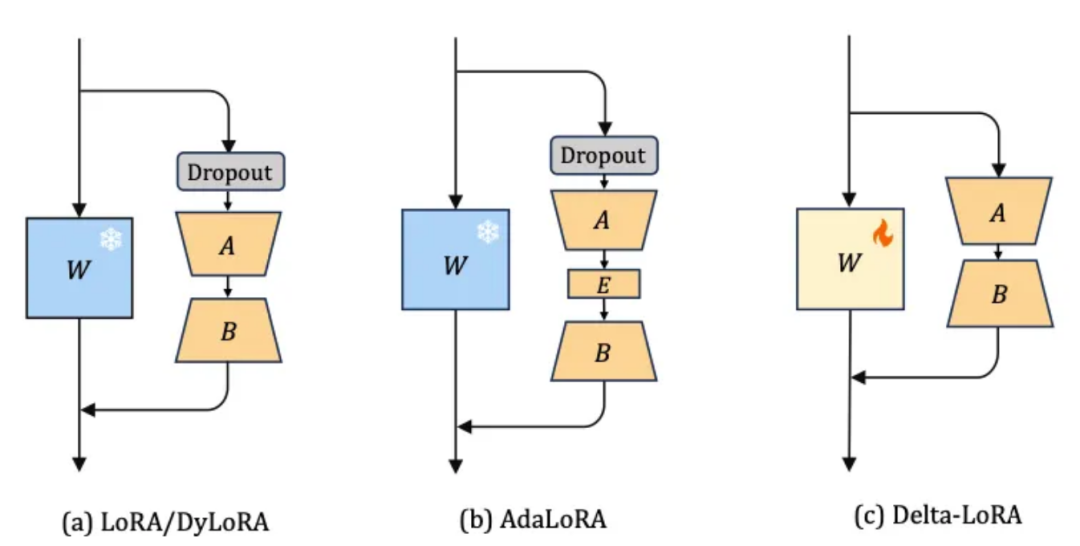
这引入了更多参数,几乎没有计算开销。我们不必像在微调中那样计算整个矩阵W的梯度,而是用我们已经在LoRA训练中得到的梯度来更新它。作者在一些基准测试中比较了这种方法,使用了RoBERTA和GPT-2等模型,并发现与标准LoRA方法相比,性能有所提升。
方法总结
我们刚刚看到了一些方法,这些方法改变了LoRA的核心思想,以减少计算时间或提高性能(或两者兼而有之)。最后,我将对不同方法进行简要总结:
LoRA引入了低秩矩阵A和B,这些矩阵在训练过程中进行训练,而预训练的权重矩阵W被冻结。 LoRA+建议对B的学习率比A的学习率高得多。 VeRA不训练A和B,而是随机初始化它们,并在其上训练新的向量d和b。 LoRA-FA只训练矩阵B。 LoRA-drop使用B*A的输出来确定哪些层值得训练。 AdaLoRA动态地调整A和B在不同层中的秩,允许在这些层中更高的秩,从而更多地为模型的性能做出贡献。 DoRA将LoRA适配器拆分为幅度和方向两个组件,并允许更独立地训练它们。 Delta-LoRA通过A*B的梯度改变W的权重。
LoRA和相关方法的研究领域非常丰富和活跃,每天都有新的贡献。在这篇文章中,我想解释一些方法的核心思想。当然,这只是一个选择,远远不足以构成完整的综述。
原文链接:https://towardsdatascience.com/an-overview-of-the-lora-family-515d81134725
# 学习大模型 & 讨论Kaggle #
每天大模型、算法竞赛、干货资讯

