




Flink SQL 提升
源表自定义并行度
现在,在 Flink 1.19 中,您可以通过选 scan.parallelism 设置自定义并行度,以调整性能。第一个可用的连接器是 DataGen( Kafka 连接器即将推出)。下面是一个使用 SQL Client 的示例:
-- set parallelism within the ddlCREATE TABLE Orders (order_number BIGINT,price DECIMAL(32,2),buyer ROW<first_name STRING, last_name STRING>,order_time TIMESTAMP(3)) WITH ('connector' = 'datagen','scan.parallelism' = '4');-- or set parallelism via dynamic table optionSELECT * FROM Orders *+ OPTIONS('scan.parallelism'='4') */;
文档 https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/table/sourcessinks/#scan-table-source FLIP-367: Support Setting Parallelism for Table/SQL Sources https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=263429150
可配置的 SQL Gateway Java 选项
FLINK-33203 https://issues.apache.org/jira/browse/FLINK-33203
使用 SQL 提示配置不同的状态 TTL
-- set state ttl for joinSELECT *+ STATE_TTL('Orders'= '1d', 'Customers' = '20d') */ *FROM Orders LEFT OUTER JOIN CustomersON Orders.o_custkey = Customers.c_custkey;-- set state ttl for aggregationSELECT *+ STATE_TTL('o' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenueFROM Orders AS oGROUP BY o_orderkey;
文档 https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/table/sql/queries/hints/#state-ttl-hints FLIP-373: Support Configuring Different State TTLs using SQL Hint https://cwiki.apache.org/confluence/display/FLINK/FLIP-373%3A+Support+Configuring+Different+State+TTLs+using+SQL+Hint
函数和存储过程支持命名参数
现在,在调用函数或存储过程时可以使用命名参数。使用命名参数时,用户无需严格指定参数位置,只需指定参数名称及其相应值即可。同时,如果没有指定非必要参数,这些参数将默认为空值。
下面是一个使用命名参数定义带有一个必选参数和两个可选参数的函数的示例:
public static class NamedArgumentsTableFunction extends TableFunction<Object> {@FunctionHint(output = @DataTypeHint("STRING"),arguments = {@ArgumentHint(name = "in1", isOptional = false, type = @DataTypeHint("STRING")),@ArgumentHint(name = "in2", isOptional = true, type = @DataTypeHint("STRING")),@ArgumentHint(name = "in3", isOptional = true, type = @DataTypeHint("STRING"))})public void eval(String arg1, String arg2, String arg3) {collect(arg1 + ", " + arg2 + "," + arg3);}}
在 SQL 中调用函数时,可以通过名称指定参数,例如:
SELECT * FROM TABLE(myFunction(in1 => 'v1', in3 => 'v3', in2 => 'v2'))
可选参数也可以省略:
SELECT * FROM TABLE(myFunction(in1 => 'v1'))
更多信息
文档
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/table/functions/udfs/#named-parameters
FLIP-387: Support named parameters for functions and call procedures
https://cwiki.apache.org/confluence/display/FLINK/FLIP-387%3A+Support+named+parameters+for+functions+and+call+procedures
Window TVF 聚合功能
支持流模式下的 SESSION Window TVF
现在,用户可以在流模式下使用 SESSION Window TVF。下面是一个简单的示例:
-- session window with partition keysSELECT * FROM TABLE(SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES));-- apply aggregation on the session windowed table with partition keysSELECT window_start, window_end, item, SUM(price) AS total_priceFROM TABLE(SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES))GROUP BY item, window_start, window_end;
Window TVF 聚合支持处理更新流
窗口聚合运算符(基于窗口 TVF 函数生成)现在可以顺利处理更新流(如 CDC 数据源等)。建议用户从传统的 窗口聚合迁移到新语法,以获得更全面的功能支持。
更多信息
文档
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/table/sql/queries/window-tvf/#session
新的 UDF 类型:AsyncScalarFunction
更多信息
FLIP-400: AsyncScalarFunction for asynchronous scalar function support
https://cwiki.apache.org/confluence/display/FLINK/FLIP-400%3A+AsyncScalarFunction+for+asynchronous+scalar+function+support
Regular Join 支持 MiniBatch 优化
消息放大是 Flink 中执行级联连接时的一个痛点,现在在 Flink 1.19 中得到了解决,新的MiniBatch优化可用于Regular Join,以减少此类级联连接场景中的中间结果。
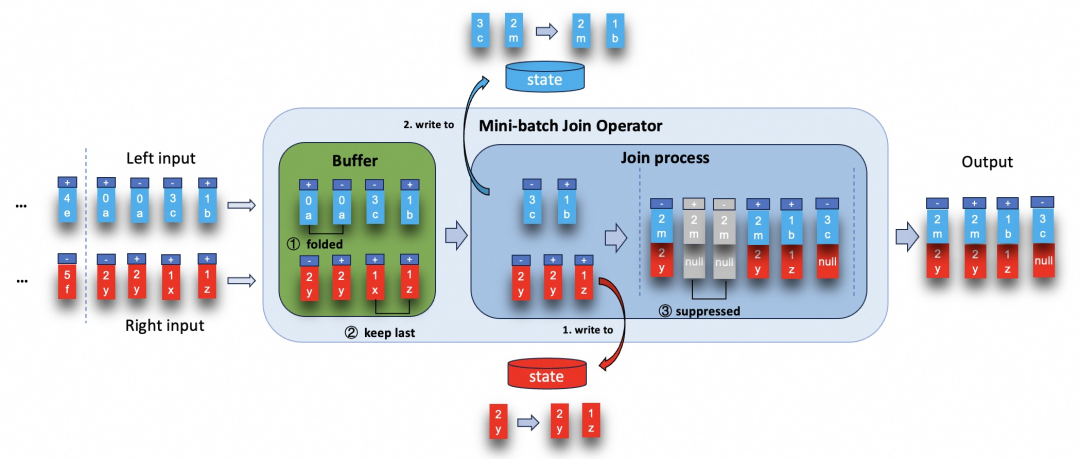
更多信息
minibatch-regular-joins 文档.
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/table/tuning/#minibatch-regular-joins
FLIP-415: Introduce a new join operator to support minibatch
https://cwiki.apache.org/confluence/display/FLINK/FLIP-415%3A+Introduce+a+new+join+operator+to+support+minibatch
Runtime & Coordination 提升
批作业支持源表动态并行度推导
在 Flink 1.19 中,我们支持批作业的源表动态并行度推导,允许源连接器根据实际消耗的数据量动态推断并行度。
与以前的版本相比,这一功能有了重大改进,以前的版本只能为源节点分配固定的默认并行度。
源连接器需要实现推理接口,以启用动态并行度推理。目前,FileSource 连接器已经开发出了这一功能。
此外,配置 execution.batch.adaptive.auto-parallelism.default-source-parallelism 将被用作源并行度推理的上限。现在,它不会默认为 1。取而代之的是,如果没有设置,将使用通过配置 execution.batch.adaptive.auto-parallelism.max-parallelism 设置的允许并行度上限。如果该配置也未设置,则将使用默认的并行度设置 parallelism.default 或 StreamExecutionEnvironment#setParallelism() 。
更多信息
文档.
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/elastic_scaling/#enable-dynamic-parallelism-inference-support-for-sources
FLIP-379: Support dynamic source parallelism inference for batch jobs https://cwiki.apache.org/confluence/display/FLINK/FLIP-379%3A+Dynamic+source+parallelism+inference+for+batch+jobs
Flink Configuration 支持标准 YAML 格式
从 Flink 1.19 开始,Flink 正式全面支持标准 YAML 1.2 语法。默认配置文件已改为 config.yaml ,放置在 conf/directory 中。如果用户想使用传统的配置文件 flink-conf.yaml ,只需将该文件复制到 conf/directory 中即可。一旦检测到传统配置文件 flink-conf.yml ,Flink 就会优先使用它作为配置文件。而在即将推出的 Flink 2.0 中, flink-conf.yaml 配置文件将不再起作用。
更多信息
flink-configuration-file 文档
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/config/#flink-configuration-file
FLIP-366: Support standard YAML for Flink configuration
https://cwiki.apache.org/confluence/display/FLINK/FLIP-366%3A+Support+standard+YAML+for+FLINK+configuration?src=contextnavpagetreemode
在 Flink Web 上 Profiling JobManager/TaskManager
Profile 结果:

更多信息
文档
https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/ops/debugging/profiler/
FLIP-375: Built-in cross-platform powerful java profiler
https://cwiki.apache.org/confluence/x/64lEE
新增管理员 JVM 选项配置选项
文档 https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/config/#jvm-and-logging-options FLIP-397: Add config options for administrator JVM options https://cwiki.apache.org/confluence/display/FLINK/FLIP-397%3A+Add+config+options+for+administrator+JVM+options?src=jira
Checkpoints 提升
Source 反压时支持使用更大的 Checkpointing 间隔
引入 ProcessingBacklog 的目的是为了说明处理记录时应采用低延迟还是高吞吐量。ProcessingBacklog 可由Source算子设置,并可用于在运行时更改作业的检查点间隔。
更多信息
FLINK-32514
https://issues.apache.org/jira/browse/FLINK-32514
[FLIP-309: Support using larger checkpointing interval when source is processing backlog]
https://cwiki.apache.org/confluence/display/FLINK/FLIP-309%3A+Support+using+larger+checkpointing+interval+when+source+is+processing+backlog
CheckpointsCleaner 并行清理单个检查点状态
现在,在处置不再需要的检查点时,ioExecutor 会并行处置每个状态句柄/状态文件,从而大大提高了处置单个检查点的速度(对于大型检查点,处置时间可从 10 分钟缩短至 < 1 分钟)。可以通过设置为 false 恢复旧版本的行为。
更多信息
FLINK-33090
https://issues.apache.org/jira/browse/FLINK-33090
通过命令行客户端触发 Checkpoints
命令行界面支持手动触发检查点。
使用方法:
./bin/flink checkpoint $JOB_ID [-full]
如果指定"-full "选项,就会触发完全检查点。否则,如果作业配置为定期进行增量检查点,则会触发增量检查点。
更多信息
FLINK-6755
https://issues.apache.org/jira/browse/FLINK-6755
Connector API提升
与 Source API 一致的 SinkV2 新接口
在 Flink 1.19 中,SinkV2 API 做了一些修改,以便与 Source API 保持一致。以下接口已被弃用:TwoPhaseCommittingSink、StatefulSink 、WithPreWriteTopology、WithPreCommitTopology、WithPostCommitTopology 。引入了以下新接口 CommitterInitContext 、CommittingSinkWriter 、 WriterInitContext 、StatefulSinkWrite。更改了以下接口方法的参数:Sink#createWriter 。在 1.19 版本发布期间,原有接口仍将可用,但会在后续版本中移除。
更多信息
FLINK-33973
https://issues.apache.org/jira/browse/FLINK-33973
FLIP-372: Enhance and synchronize Sink API to match the Source API
https://cwiki.apache.org/confluence/display/FLINK/FLIP-372%3A+Enhance+and+synchronize+Sink+API+to+match+the+Source+API
用于跟踪Committables状态的新Committer指标
修改了 TwoPhaseCommittingSink#createCommitter 方法的参数化,新增了 CommitterInitContext 参数。原来的方法在 1.19 版本发布期间仍然可用,但会在后续版本中移除。
更多信息
FLINK-25857
https://issues.apache.org/jira/browse/FLINK-25857
FLIP-371: Provide initialization context for Committer creation in TwoPhaseCommittingSink
https://cwiki.apache.org/confluence/display/FLINK/FLIP-371%3A+Provide+initialization+context+for+Committer+creation+in+TwoPhaseCommittingSink
重要API弃用
Flink's org.apache.flink.api.common.time.Time[1] 现已被正式弃用,并将在 Flink 2.0 中删除。引入了支持 Duration 类的方法,以取代已废弃的基于 Time 的方法。 org.apache.flink.runtime.jobgraph.RestoreMode#LEGACY[2] 已被弃用。请使用 RestoreMode#CLAIM[3] 或 RestoreMode#NO_CLAIM[4] 模式,以在还原时获得清晰的状态文件所有权。 旧的解决模式兼容性的方法已被弃用,请参考迁移说明迁移至新方法:Migrating from deprecated TypeSerializerSnapshot#resolveSchemaCompatibility(TypeSerializer newSerializer) before Flink 1.19.[5] 通过硬代码配置序列化行为已被弃用,例如 ExecutionConfig#enableForceKryo[6] 。请使用选 pipeline.serialization-config 、pipeline.force-avr 、pipeline.force-kryo 和 pipeline.generic-types。实例级序列化器的注册已被弃用,请使用类级序列化器。 除了getString(String key, String defaultValue)[7] 和 setString(String key, String value)[8] ,我们已废弃所有 setXxx 和 getXxx 方法,如:setInteger 、setLong 、getInteger 和 getLong 等。建议用户和开发人员使用以 ConfigOption 代替字符串作为键的 get 和 set 方法。 StreamExecutionEnvironment 、CheckpointConfig 和 ExecutionConfig 中的非 ConfigOption 对象及其相应的 getter/setter 接口现已废弃。这些对象和方法计划在 Flink 2.0 中删除。已废弃的接口包括重启策略(RestartStrategy)、检查点存储(CheckpointStorage)和状态后端(StateBackend)的getter 和 setter 方法。 org.apache.flink.api.common.functions.RuntimeContext#getExecutionConfig [9] 现已被正式弃用,并将在 Flink 2.0 中删除。请使用 getGlobalJobParameters()[10] 或 isObjectReuseEnabled()[11] 。 org.apache.flink.api.common.functions.RichFunction#open(Configuration parameters)[12] 方法已被弃用,并将在未来版本中删除。我们鼓励用户迁移到新的 RichFunction#open(OpenContext openContext)[13] 。 org.apache.flink.configuration.AkkaOptions[14] 已被弃用,取而代之的是 RpcOptions[15] 。
[5] https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/datastream/fault-tolerance/serialization/custom_serialization/#migrating-from-deprecated-typeserializersnapshotresolveschemacompatibility
[6] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/ExecutionConfig.java#L643
[7] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/configuration/Configuration.java#L176
[8] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/configuration/Configuration.java#L220
[9] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/functions/RuntimeContext.java#L191
[10] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/functions/RuntimeContext.java#L208
[11] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/functions/RuntimeContext.java#L216
[12] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/functions/RichFunction.java#L76
[13] https://github.com/apache/flink/blob/release-1.19/flink-core/src/main/java/org/apache/flink/api/common/functions/RichFunction.java#L118
[14] https://github.com/apache/flink/blob/master/flink-core/src/main/java/org/apache/flink/configuration/AkkaOptions.java
[15] https://github.com/apache/flink/blob/master/flink-core/src/main/java/org/apache/flink/configuration/RpcOptions.java
升级说明
贡献者列表

本届 Flink Forward Asia 更多精彩内容,可点击「阅读原文」或扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!

▼扫码开启Flink学习之旅▼


 点击「阅读原文」,在线观看FFA 2023 会后资料~
点击「阅读原文」,在线观看FFA 2023 会后资料~