




作者简介
Laurenz Albe
cybertec公司工程师
译者简介
王志斌
PostgreSQL爱好者
校对者简介
崔鹏
PostgreSQL爱好者

最近我调查了一下DBeaver数据库客户端与PostgreSQL并行查询相关的一个令人惊讶的行为,我想与大家分享一下。对于所有使用JDBC驱动程序访问PostgreSQL的人来说,这可能会很有趣。
关于PostgreSQL并行查询的一些基础知识
并行查询概念
并行查询是在PostgreSQL 9.6中引入的,并在后续版本中进行了改进。它打破了“传统”的PostgreSQL架构,即每个数据库连接使用单个后端进程来处理SQL语句。如果优化器认为并行处理可以减少执行时间,它将计划额外的并行工作进程。这些进程由查询执行器创建,并且仅在单个SQL语句的持续时间内存在。并行工作进程计算中间结果,最终这些结果会被收集到原始的后端进程中。这个收集过程发生在执行计划的“ Gather ”节点中:PostgreSQL在Gather节点下面的所有步骤都是并行执行的,而Gather 节点上面的所有步骤都是单线程执行的。
并行查询限制
虽然并行查询可以加速查询执行,但它也会产生一些开销:
启动并行工作进程是一项昂贵的操作
在工作进程和后端之间交换数据需要通过动态共享内存段(DSM)进行进程间通信
PostgreSQL优化器通过针对计划处理的大表或索引的高代价语句来综合考虑这些开销的计算。为了防止并行查询消耗过多资源,还有一些额外的限制:
max_parallel_workers限制了整个数据库集群中并行工作进程的数量
max_parallel_workers_per_gather限制了单个语句可以使用的并行工作进程的数量
如果由max_parallel_workers定义的工作进程数量已经用尽,则查询执行器无法启动优化器计划的所有并行进程。
这个简要介绍远远不够详尽。有关更多信息,请阅读PostgreSQL文档以及我们关于并行查询优化、并行DDL、并行聚合或并行查询与SERIALIZABLE隔离级别的交互的文章。
DBeaver中并行查询的令人惊讶的问题
我将使用一个简单的查询来演示问题,该查询计算一个包含 500万行的表中的行数。PostgreSQL计划在表上进行并行顺序扫描:

使用DBeaver,我可以使用 EXPLAIN (ANALYZE) 来验证执行器是否实际启动了并行工作进程:
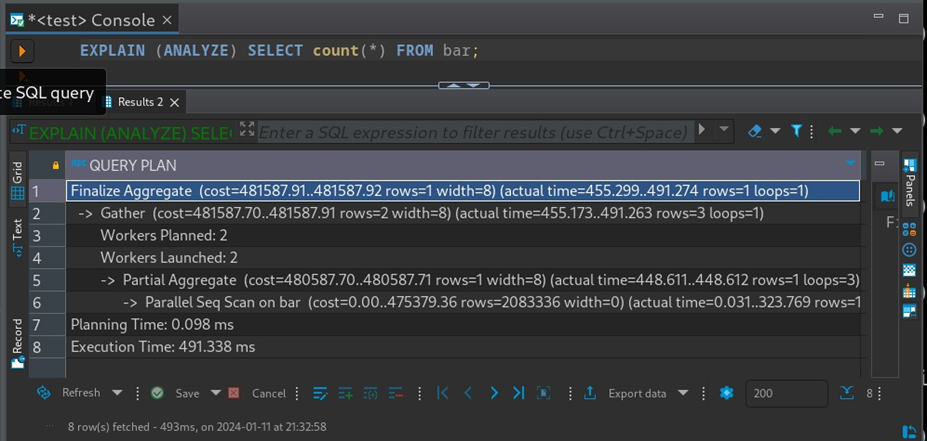
但是,在DBeaver中运行查询实际上花费的时间要比 491 毫秒长得多。这很奇怪,因为 EXPLAIN(ANALYZE) 会给语句的执行增加显着的开销!为了找出实际在服务器上发生了什么,我使用auto_explain 扩展来在 PostgreSQL 服务器日志中收集实际的执行计划:
LOG: duration: 712.369 ms plan:Query Text: SELECT count(*) FROM barFinalize Aggregate (...) (actual time=712.361..712.363 rows=1 loops=1)-> Gather (...) (actual time=712.355..712.356 rows=1 loops=1)Workers Planned: 2Workers Launched: 0-> Partial Aggregate (...) (actual time=712.354..712.354 rows=1loops=1)-> Parallel Seq Scan on bar (...) (actual time=0.006..499.970rows=5000000 loops=1)
PostgreSQL没有启动任何并行工作进程,因此查询必须以单线程方式执行。这解释了较长的持续时间。但是是什么阻止了PostgreSQL启动并行工作进程呢?第一个怀疑会是 max_parallel_workers 池已经耗尽了。但是在这个服务器上没有运行其他查询!是时候深入挖掘了。
并行查询的限制
PostgreSQL文档中有一章关于并行查询的限制。例如,大多数修改数据的语句不支持并行查询。此外,使用 PARALLEL UNSAFE 函数或在游标中执行的查询也不能使用并行查询。但是这些限制都不会影响我们在这里,否则优化器根本不会计划并行工作进程。问题一定发生在查询的执行过程中。
在页面的最后,我们发现了以下限制:
即使为特定查询生成了并行查询计划,也有几种情况在执行时无法并行执行该计划。
客户端使用非零提取计数发送Execute消息。请参阅扩展查询协议的讨论。由于libpq目前没有提供发送此类消息的方法,因此只有在使用不依赖于libpq的客户端时才会发生这种情况。
哈!看起来我们找到了关键。DBeaver使用JDBC驱动程序访问PostgreSQL,而该驱动程序不使用libpq访问PostgreSQL。
使用JDBC重现这个问题
您可以在PostgreSQL文档中看到上述“execute”消息的描述。最后一个参数是提取计数。PostgreSQL JDBC驱动程序使用该功能来实现方法setMaxRows(int),该方法在java.sql.Statement (并且由java.sql.PreparedStatement 和 java.sql.CallableStatement 继承)中可用。
以下是一个简单的Java程序,可以重现这个问题:
public class Parallel {public static void main(String[] args) throws ClassNotFoundException,java.sql.SQLException {Class.forName("org.postgresql.Driver");java.sql.Connection conn=java.sql.DriverManager.getConnection("jdbc:postgresql://127.0.0.1:5432/test?user=xxx&password=xxx");java.sql.Statement stmt = conn.createStatement();stmt.setMaxRows(200);java.sql.ResultSet rs = stmt.executeQuery(``"SELECT count(*) FROMbar"``);rs.next();System.out.println(rs.getString(1));rs.close();stmt.close();conn.close();}}
如果将行限制设置为0(默认值),问题就会消失。
使DBeaver能够使用并行查询
谜题的最后一部分是找出如何在DBeaver中配置行数限制。在文档中进行了一些调查后,我发现答案就在我查看“数据编辑器”窗格时就在眼前:
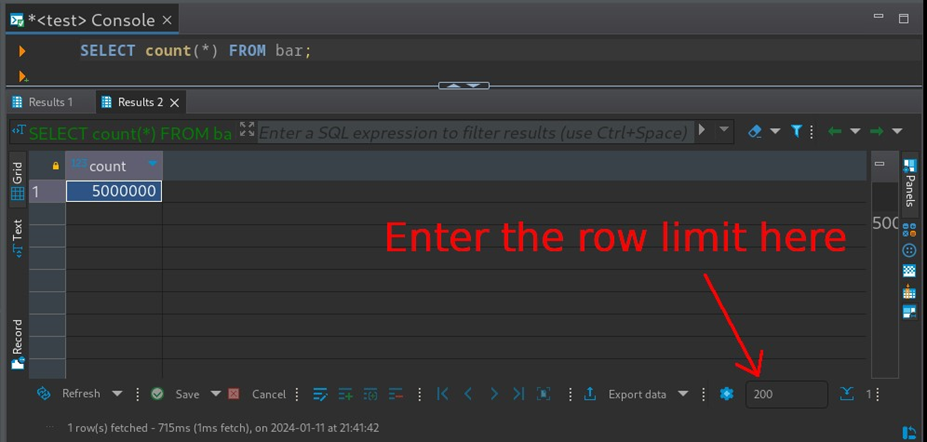
您只需要将限制更改为0!或者,您可以单击行限制左侧的“蓝色花朵”以弹出“属性”对话框。在那里,您可以在“数据编辑器”属性中更改“结果集提取大小”。如果您想永久更改设置,请切换到右上角的“全局设置”。
一旦您更改了设置,PostgreSQL将按预期启动并行工作进程。
那么我不能在结果集限制的情况下进行并行处理吗?
当然可以:使用 LIMIT 子句而不是 setMaxRows() 。这个查询可以使用并行工作进程:
EXPLAIN (COSTS OFF) SELECT count(*) FROM bar LIMIT 200;QUERY PLAN══════════════════════════════════════════════════Limit-> Finalize Aggregate-> GatherWorkers Planned: 2-> Partial Aggregate-> Parallel Seq Scan on bar
LIMIT 和 setMaxRows() 的区别在于前者在查询计划时已知,而后者仅在查询执行时才知道。在上面的查询中,优化器知道 LIMIT 应用在 Gather 节点之后,此时并行处理已经结束。执行器不知道这一点,因此为了安全起见,它禁用了并行处理。使用 LIMIT 的另一个原因是更好的是:如果优化器知道您只需要前几行结果,它可以选择一个快速产生这些行的计划,而不是针对整个结果集进行优化。
结论
DBeaver的默认配置使用 java.sql.Statement.setMaxRows(int) 来限制结果集的大小为200。这触发了PostgreSQL中一个很少被注意到的限制,阻止它启动并行工作进程。一旦您了解了发生了什么,通过将限制设置为0,问题就很容易避免。
如果想要并行处理,请在查询计划时使用 LIMIT 而不是在执行时使用行计数。
请点击文章底部“阅读原文”查看原文内容!
