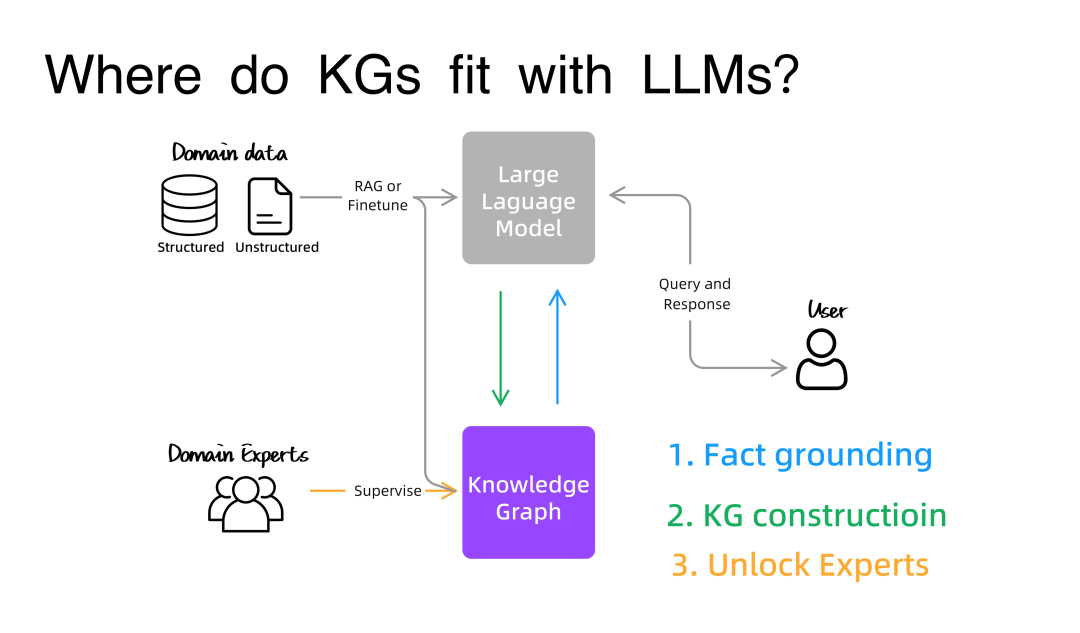
在三个月前的 AI 大会上,Anyscale 首席科学家 Dr. Waleed Kadous 在他的演讲 LLMs in Production 中,对这两种方式的抉择权衡提供了一些见解。他说:“微调是针对形式而非事实的。”、“而 RAG 是针对事实的。”。像是 OpenAccess-AI-Collective/axolotl、huggingface/trl 之类的开源库的存在,让微调变得更容易、更便宜。虽然难度和成本都降低了,但微调还是那个资源密集的工作,而且要以此为生的话,NLP 技术得更成熟才行。与此同时,另一边的 RAG 也变得更容易获取了。2 个月前,Hacker News 上有个咨询贴《2023 年 12 月了,有哪些方式来基于文档定制我的 LLM/ChatGPT?》,里面大多数的回复(从业者)都在用 RAG 而非微调。>>>>
Vector RAG vs Graph RAG
一说到 RAG,一般人们指代是基于向量数据库的检索系统,即 Vector RAG。但是在 NebulaGraph(一个开源的图数据库)的博客和教程中,介绍了一种称之为 Graph RAG 的替代方法,这是一种基于图数据库的检索系统。他们展示了不同的架构中 RAG 系统检索的事实是如何的不同。在 LlamaIndex 的 KnowledgeGraph vs VectorStoreIndex vs 混合 Index 结果对比中,提到与 Vector RAG 相比,Graph RAG 更简洁,在 token 开销方面更加便宜。>>>>
RAG 概览
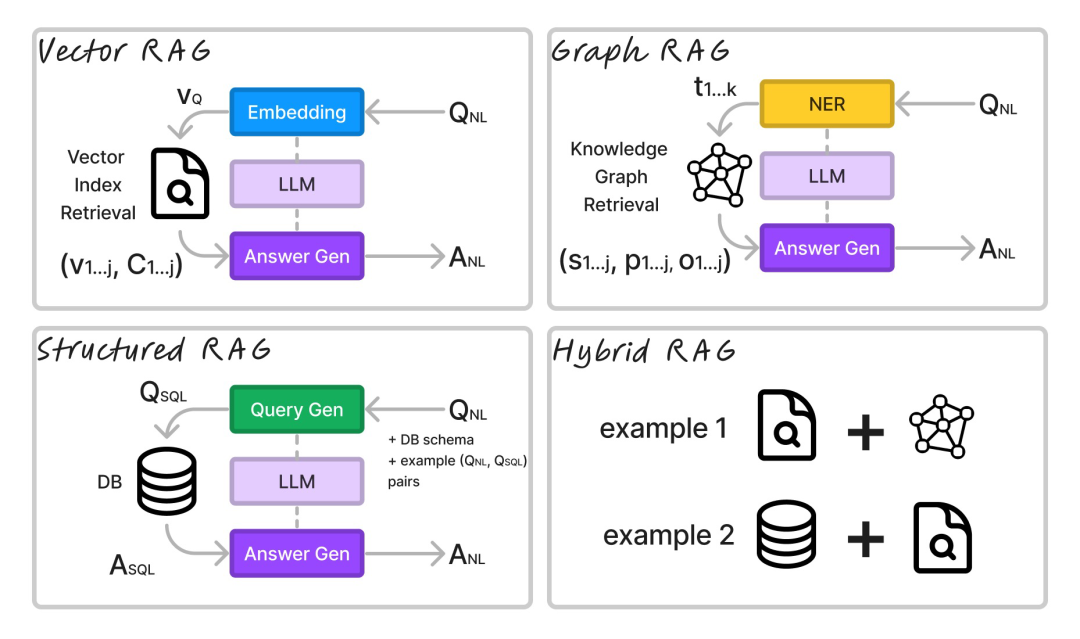
为了方便你理解不同的 RAG 架构,这里放出了我绘制的图表:
图注:Differences and similarities of the RAG architectures在绝大多数情况下,我们会以自然语言问问题,再得到一个自然语言的回复。而系统这边的处理流程就是,编码模型提取问题的结构后,同生成模型(答案生成器)一起生成对应的答案。Vector RAG 将查询嵌入到向量中,通常它会使用比 LLM 小的模型,像是 Flag Embedding 或者是 Huggingface 这些嵌入排行榜上主流的小型模型。然后,从向量数据库里检索出与最相近的 TOP K 个文档块,并将这些作为向量和块(,)返回。这些块连同一起作为上下文传给 LLM 生成答案。Graph RAG 从查询中提取关键词,并检索与关键词匹配的图中的三元组。然后,它将这些三元组(, , )连同一起传递给 LLM 生成答案。Structured RAG 使用生成模型(LLM 或更小的经过微调的模型)来生成数据库查询语言中的查询。它可以为关系型数据库生成一个 SQL 查询,或者为图数据库生成一个 Cypher 查询。例如,我们想查询一个关系数据库:模型将生成 ,再传给数据库来检索答案。如果留意的话,都是从数据库运行得到的数据记录。答案以及都会传给 LLM 来生成。在混合 RAG 情况下,系统会结合了上述所有方法。因为混合技术不在本文的讨论范畴,总之记住有很多种混合技术。当中最简单的是,传递更多上下文给 LLM 用于答案生成,并让它利用摘要能力强化生成的答案。>>>>
LlamaIndex 中的 Graph RAG 实现
现在,来看下使用当前的框架,10 行 Python 代码构建出来的 Graph RAG 系统。
from llama_index.llms import Ollama from llama_index import ServiceContext, KnowledgeGraphIndex from llama_index.retrievers import KGTableRetriever from llama_index.graph_stores import NebulaGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.query_engine import RetrieverQueryEngine from llama_index.data_structs.data_structs import KG from IPython.display import Markdown, display
# 创建图空间 CREATE SPACE wikipedia(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1); # 使用图空间 USE wikipedia; # 创建实体 CREATE TAG entity(name string); # 创建关系边 CREATE EDGE relationship(relationship string); # 创建实体类型对应的索引 CREATE TAG INDEX entity_index ON entity(name(256));
知识图谱的搭建 >>>>
构建一个知识图谱
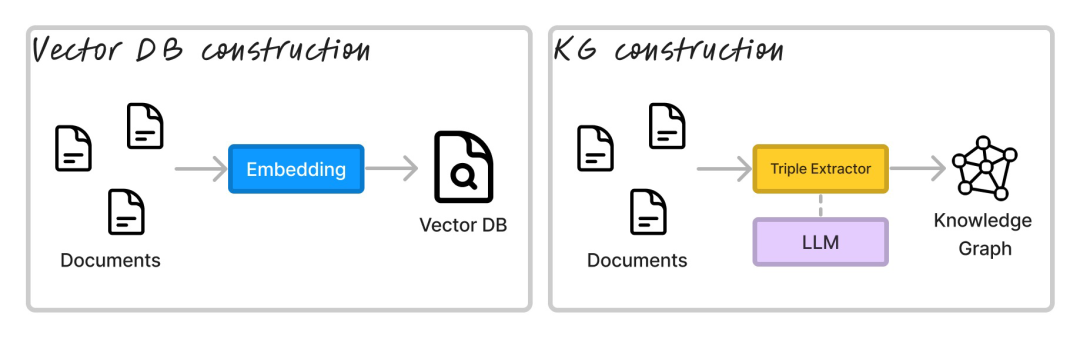
在进行推理之前,你需要在向量数据库或图数据库中对数据进行索引构建。
图注:Indexing architectures for RAG对于 Graph RAG 来说,与 Vector RAG 的文档分块、嵌入等操作对等的是,提取三元组。三元组的形式一般是(s, p, o),其中 s 是主体,p 是谓词,o 是客体。主体和客体是实体,谓词是关系。从文本中提取三元组有多种方式,但最常见的方法是使用命名实体识别器(NER)和关系提取器(RE)的组合。NER 提取像“Peter Quill”和“银河护卫队第 3 卷”这样的实体,RE 提取像“在...中扮演角色”和“由...导演”这样的关系。虽然市面上有专门用于 RE 的微调模型,比如:REBEL,但人们开始使用 LLM 来提取三元组了。下面是 LlamaIndex 的 RE 默认提示词:
Some text is provided below. Given the text, extract up to {max_knowledge_triplets} knowledge triplets in the form of (subject, predicate, object). Avoid stopwords. --------------------- Example: Text: Alice is Bob's mother. Triplets: (Alice, is mother of, Bob) Text: Philz is a coffee shop founded in Berkeley in 1982. Triplets: (Philz, is, coffee shop) (Philz, founded in, Berkeley) (Philz, founded in, 1982) --------------------- Text: {text} Triplets:
from llama_index.llms import Ollama from llama_index import ServiceContext, KnowledgeGraphIndex from llama_index.graph_stores import NebulaGraphStore from llama_index.storage.storage_context import StorageContext from llama_index import download_loader
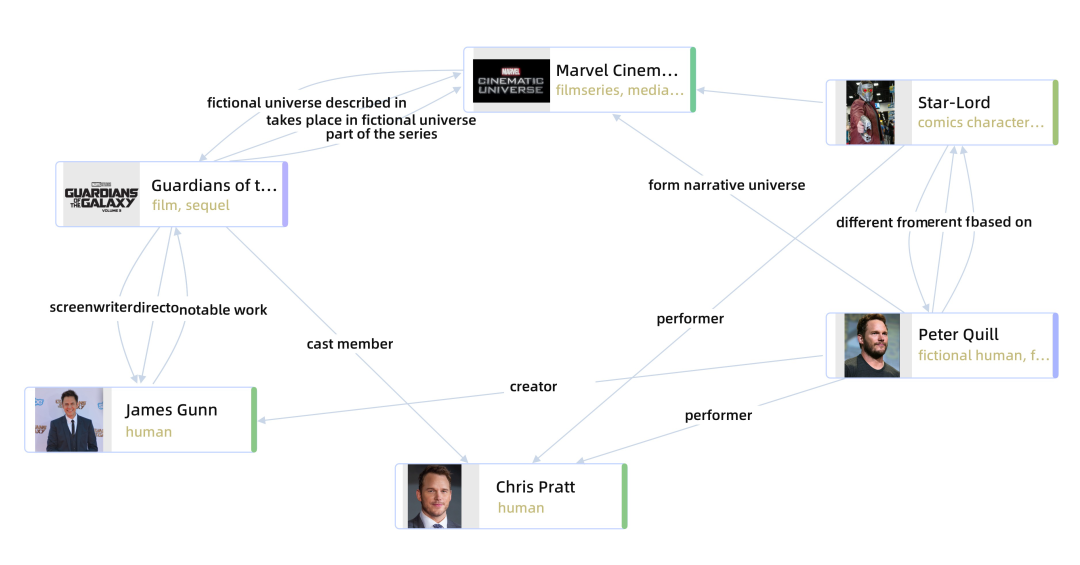
如果我们查看电影“银河护卫队第 3 卷”所生成的知识图谱,我们可能会发现一些问题:这里有个问题的汇总表:图注:问题汇总表格将它同与手工标记的 Wikidata 图谱对比是这样的:图注:Human-labelled KG in Wikidata generated with metaphacts>>>>
为了更好地构建知识图谱
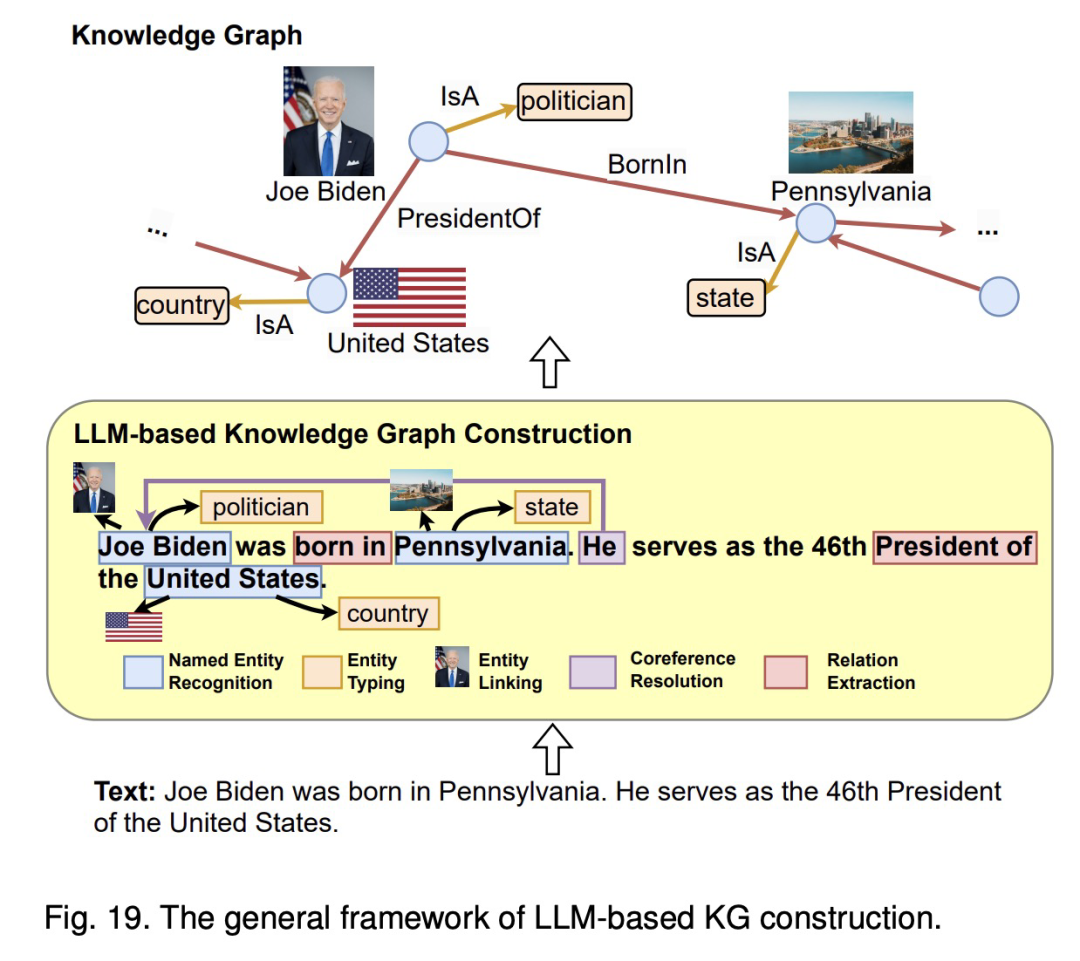
所以,我们的前进方向在哪里呢?本质上,知识图谱的构建优化要自然演进的话,其实目前有一些技术挑战需要解决:构建知识图谱的方法需要新的事实和表示未见过的知识。论文《统一大语言模型和知识图谱:路线图(Unifying Large Language Models and Knowledge Graphs: A Roadmap)》 很好地概述了当前的技术现状以及未来的挑战。构建知识图谱涉及在特定领域内创建知识的结构化表示,包括识别实体及其之间的关系。知识图谱构建过程通常包括多个阶段,包括:1) 实体发现;2) 共指消解;3) 关系提取。论文的 Fig.19 展示了在知识图谱构建的每个阶段应用大型语言模型(LLM)的一般框架。最近,还探索了 4) 端到端的知识图谱构建,涉及一步构建完整的知识图谱,或者直接从大型语言模型(LLM)中提炼知识图谱。
这篇论文可以用下图总结下:
图注:Fig.19 The general framework of LLM-based KG construction
图注:Human vs AI我建议阅读本文的你读一读 AI Snake Oil 报道中的这个回答。他们提出了一个好观点,即:像 ChatGPT 这样的模型只是记住了解决方案而不是推理它们,这让考试成为比较人类和机器的一个糟糕方式。超越存储记忆,还有一个围绕所谓的泛化、推理、计划、表示学习的研究领域,图能帮上忙。>>>>