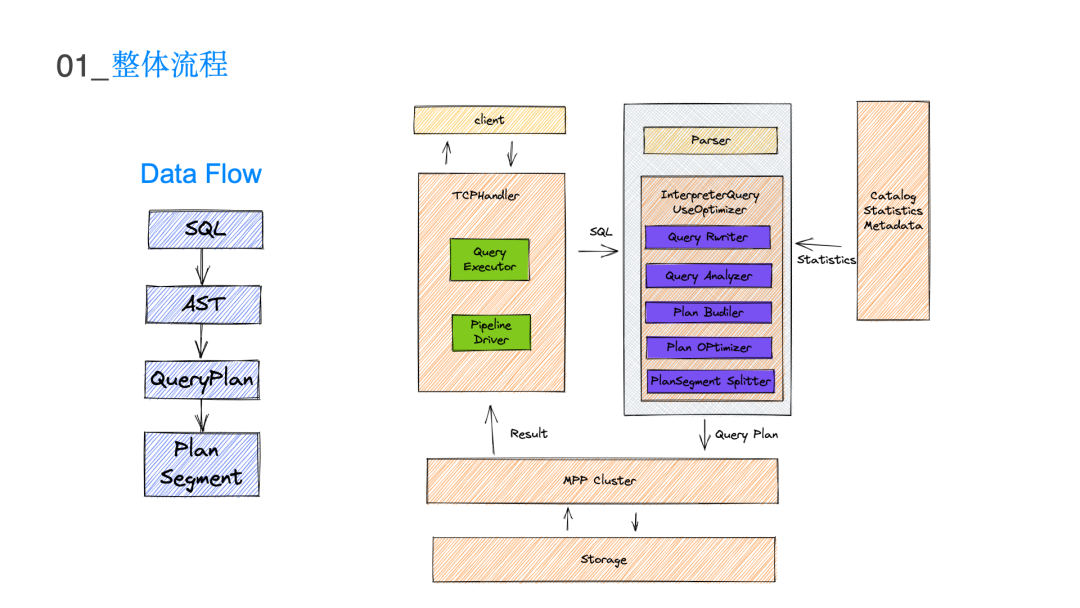
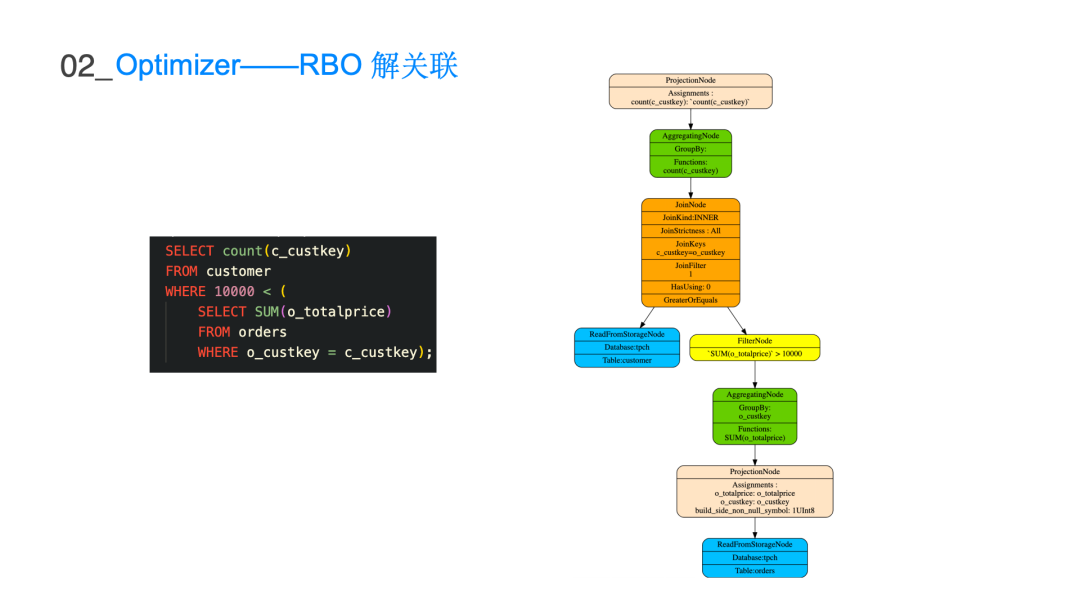
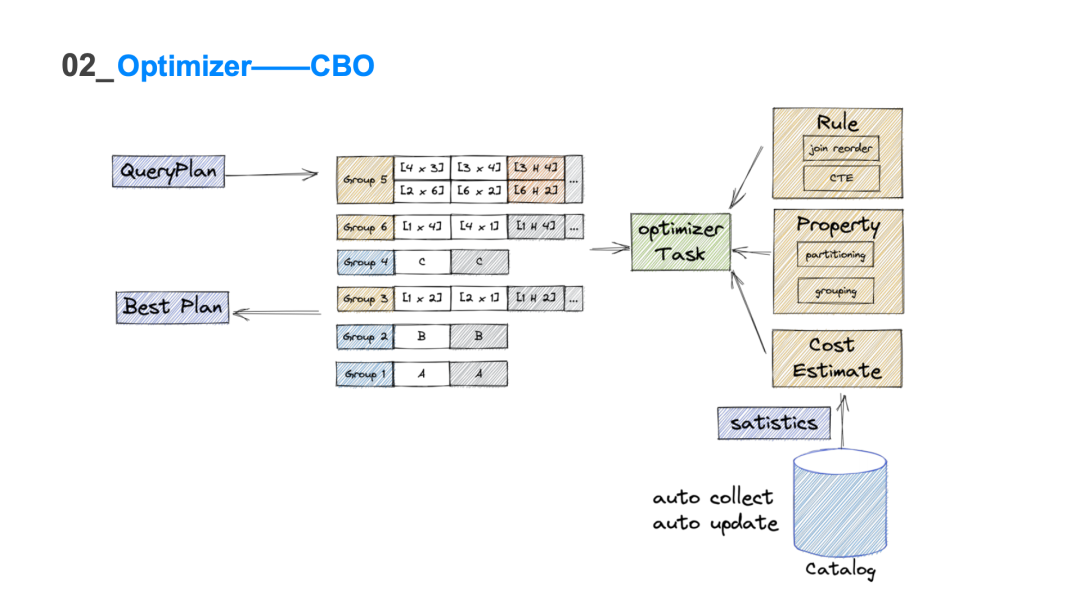
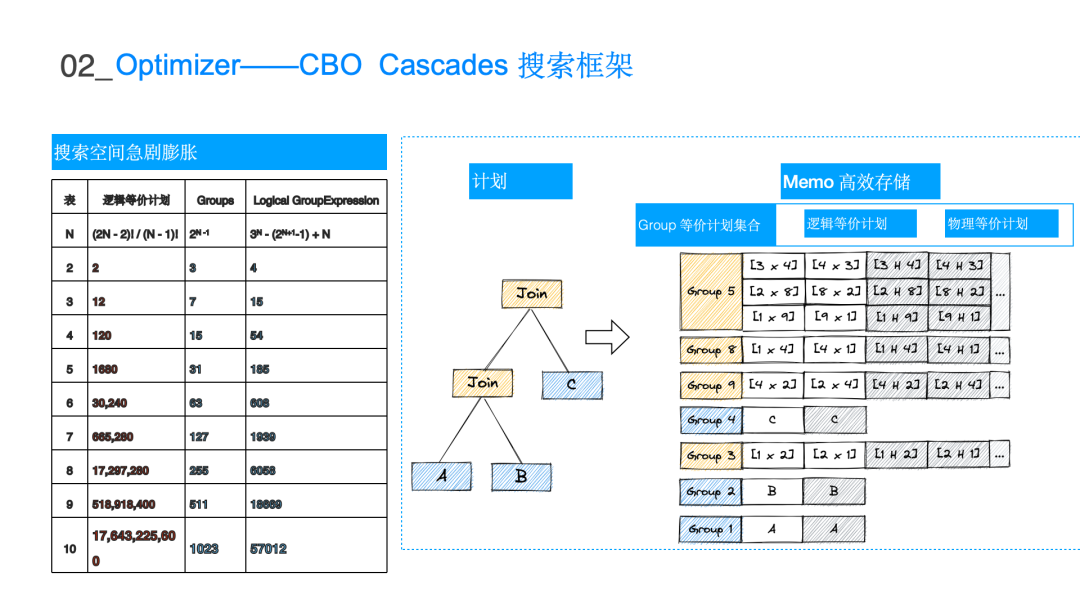
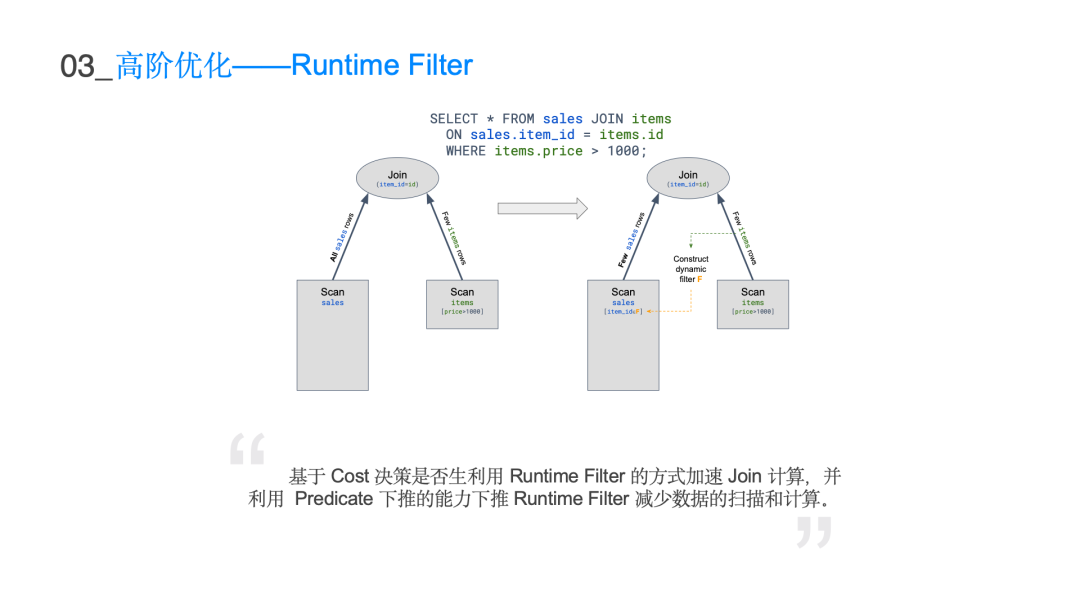
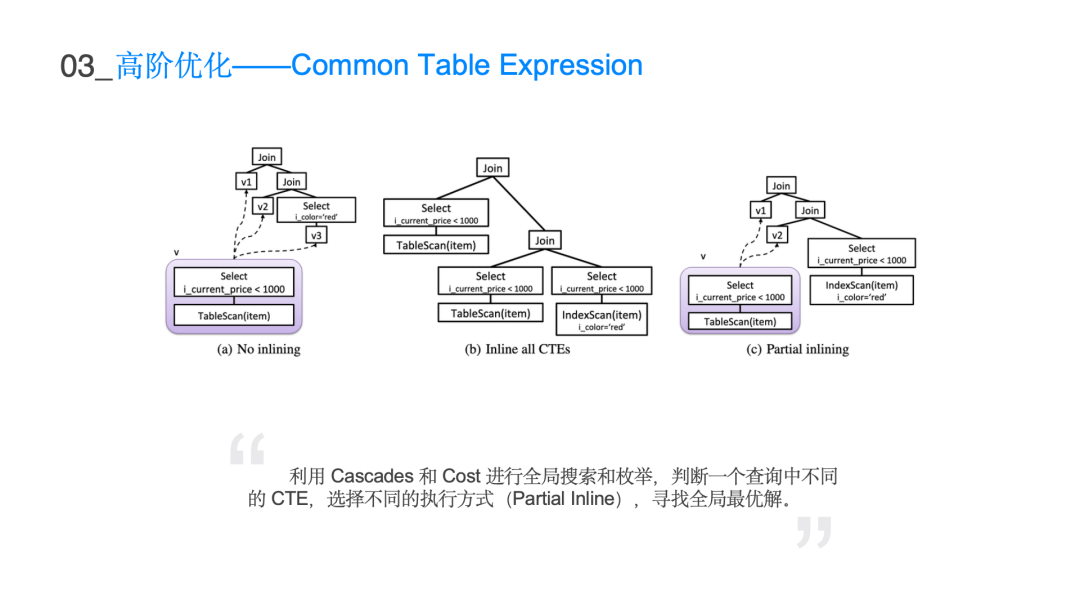
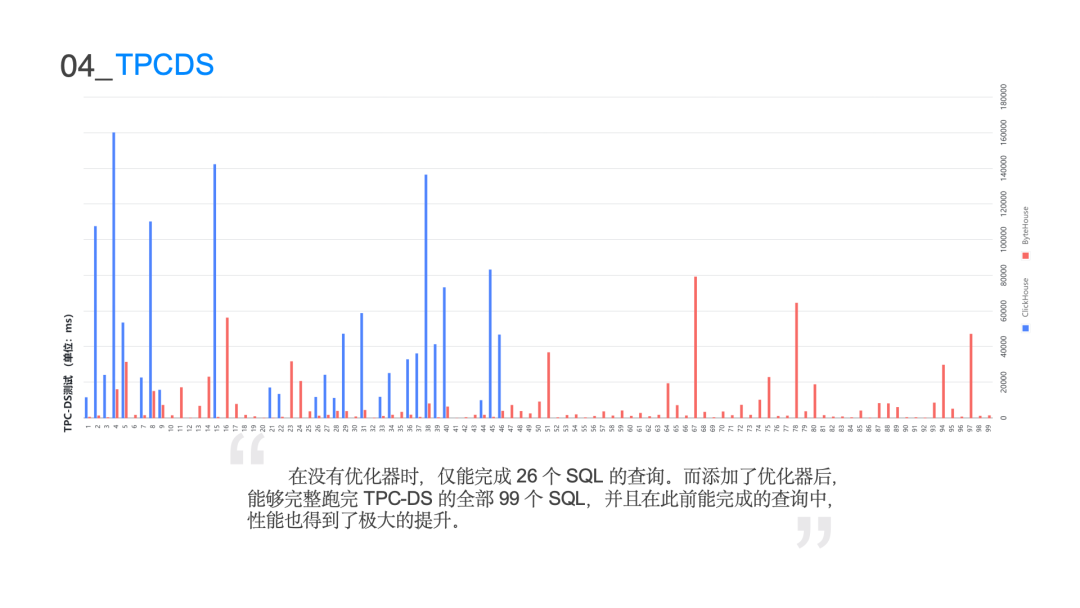
表格描述了在不同 join 表数量的情况下它真正表达的搜索空间是多大即阶乘级别的复杂度。10 个表已经是亿级别的量级,由于枚举数量庞大的逻辑执行计划是不现实的,所以利用 Cascades 的搜索框架Group 和 GroupExpr 来表达数量庞大的搜索空间,可以将 n 的阶乘复杂度的搜索空间来降低到 3 的 n 次方级别。这样在有限的时间内搜索出 10 表以内的所有的 join 情况,可大大地降低整个搜索时间以及存储空间。
/ CBO计划枚举 /
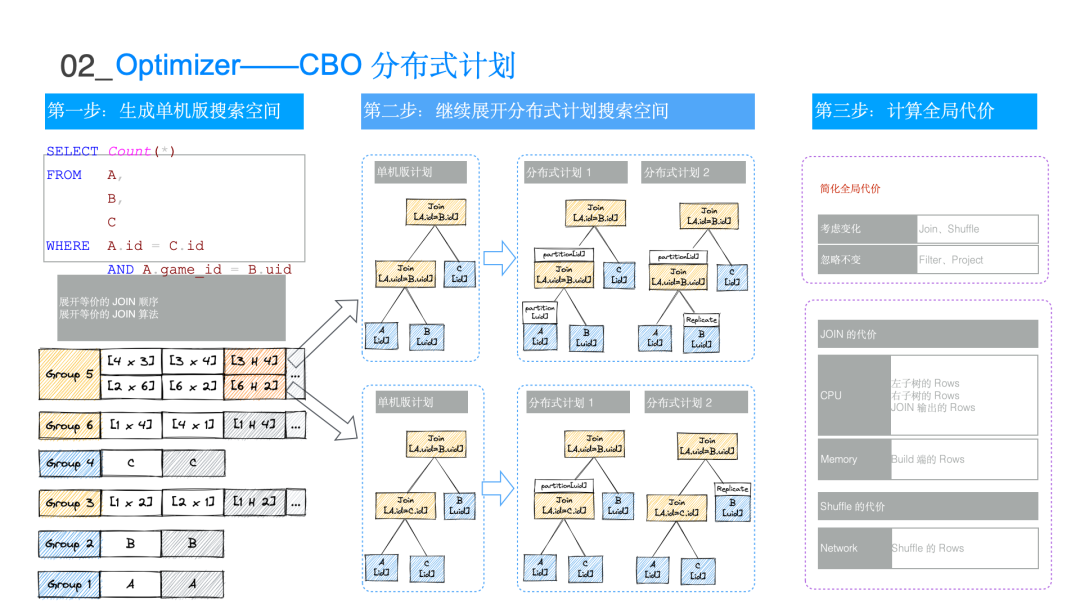
1. 规则 需要靠CBO的规则不停地扩充搜索空间,然后基于cost选出其中的最优解。扩充得越多,选出最优解可能性就更高。常见的CBO rule得到实现。例如:Inner Join Reorder,Left Join to Right Join,Pull Left through Inner以及CTE和Magic Set这样高级优化。 2.分布式计划 作为分布式数据库,ByteHouse会利用分布式的属性,将分布式计划的生成和搜索融合在同一个Cascades搜索框架内,最终基于代价来选择最优的分布式计划。利用三种property来优化和生成分布式计划: ●partitioning是指数据如何分区的,每个数据分区内的数据是不相交的。例如第一个分区内的数据是AB,那第二个分区内数据是CD,所有 A 或者 B 都会在第一个分区内,所有 C 和 D 都会在第二个分区内。 ●grouping 和 sorting描述的是数据行与行之间的关系。grouping 是相同值的数据都要连续地排布在一起,例如 BBA。sorting 被认为是对 grouping 的加强,它不但要连续的数据,而且是有序的,例如 AABB。 将分布式计划和 CBO 框架结合在一起。很多数据库的做法是用 CBO 生成一个计划,在这个计划上推导如何插入 exchange 的节点,这样有可能会丢失最优解,很多情况下可能是次优的 join order ,但加上生成的分布式计划,反而是全局最优的。 以a、b, c 三个表为例子,这两个橙色计划分别对应两个不同的单机计划(对于每一个单地计划,其实都可以扩容出多个分布式计划)。比如先进行 a join b,再 join c,这样的情况 a 表按 uid 进行repatition,这样 a b 都按 uid 进行分区之后,可以直接进行 join ,然后对 join 的结果再按 id 进行repatition,然后去和 c 进行join,这样的结果才是正确的。也可以不对a做repatition,对b做replicated。对于另一个单机计划来说,同样可以生成两种不同的数据分布方式。对四个计划评估代价是多少并基于 cost 选择最终的最优解。