




一、基础知识点介绍
CURRENT ROW --表示当前行
UNBOUNDED PRECEDING --表示第一行
UNBOUNDED FOLLOWING --表示最后一行
LAST_VALUE(SAL) --最后的行,跟排序的升降有关,升序则最后的值为最大值,降序最后的值则为最小值
如果窗口函数及sql语句末端都有order by,两个order by 的执行机制
分析函数是在整个SQL查询结束后(SQL语句中的 order by 的执行比较特殊)再进行的操作,也就是说SQL语句中的order by也会影响分析函数的执行结果:
1、两者一致:如果SQL语句中的order by 满足分析函数分析时要求的排序,那么SQL语句中的排序将先执行,分析函数在分析时就不必再排序。
2、两者不一致:如果SQL语句中的order by 不满足分析函数分析时要求的排序,那么SQL语句中的排序将最后在分析函数分析结束后执行排序。
当省略窗口子句时:
如果存在order by, 则默认的窗口是 unbounded preceding and current row --存在order by 时 从第一行到当前行
如果同时省略order by, 则默认的窗口是 unbounded preceding and unbounded following --省略存在order by 时 从第一行到最后一行
如果省略分组,则把全部记录当成一个组:
如果存在order by 则默认窗口是 unbounded preceding and current row --存在order by 时 从第一行到当前行
如果这时省略order by 则窗口默认为 unbounded preceding and unbounded following --省略存在order by 时 从第一行到最后一行
二、示例:
1、SQL无排序,over()排序子句省略:此处展示的就是 deptno分组后,从第一行到最后一行数据中选出最后一个值,其实就是分组后的最后一个值,该分组中分行都显示这个值
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno) from emp;
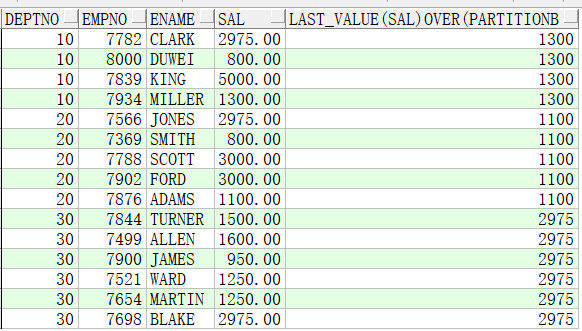
2、SQL无排序,over()排序子句有,窗口省略:此处展示的是,deptno分组后,按sal降序排序,从第一行到当前的数据中选出最后一个值,其实就是选择当前行的值
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal desc) from emp;
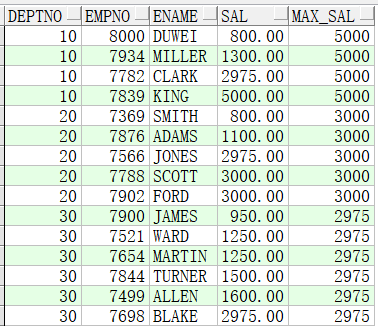
3、SQL无排序,over()排序子句有,窗口也有,窗口特意强调全组数据:
此处展示的是,eptno分组后,按sal升序排序,从第一个到分组中的最后一行中,选择最后一行,其实就是选择分组中的最大sql展示在分组内的每一行
select deptno,
empno,
ename,
sal,
last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal
from emp;
4、SQL有排序(正序),over() 排序子句无,先做SQL排序再进行分析函数运算
此处展示的是:先按where条件选择数据,再按sql中的字段排序升序排序,然后进行分析函数运算,从结果集中,先按deptno分组,分组后从各分组中的第一行到最后一行中
选择最后一行,所以各分组中展示的都是该分组中的最后一行
select deptno,
mgr,
ename,
sal,
hiredate,
last_value(sal) over(partition by deptno) last_value
from emp
where deptno = 30
order by deptno, mgr;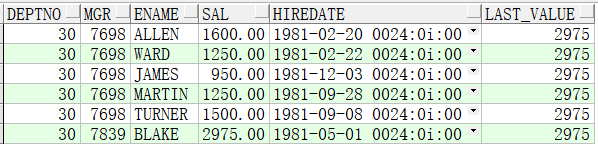
5、SQL有排序(倒序),over() 排序子句无,先做SQL排序再进行分析函数运算
此处展示的是:先按where条件过滤,再按eptno, mgr 降序排序,然后进行分析函数运算,从结果集中,先按deptno分组,分组后从各分组中的第一行到最后一行中
选择最后一行,所以各分组中展示的都是该分组中的最后一行
select deptno,
mgr,
ename,
sal,
hiredate,
last_value(sal) over(partition by deptno) last_value
from emp
where deptno = 30
order by deptno, mgr desc;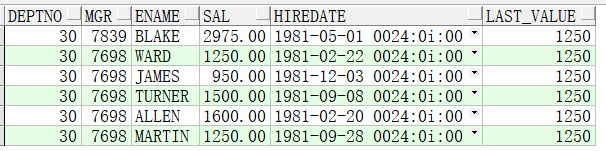
6、SQL有排序(倒序),over()排序子句有,窗口子句无
此时的运算是:SQL先选数据但是不排序,而后排序子句先排序并进行分析函数处理(窗口默认为第一行到当前行),最后再进行SQL排序
因为分析函数跟sql中的order by 不一样,先运行分析函数里的排序,顾先根据where条件筛选出结果集,然后根据分析函数中的deptno分组,
各分组中按order by sal进行排序,因为分析函数里是带order by的子句,那就意味真选择从第一行到当前行选择最小的,又因为最小的就是第一行
所以,last_value就一直是950了,分析函数跑完,再在sql中deptno, mgr desc进行排序
select deptno,
mgr,
ename,
sal,
hiredate,
min(sal) over(partition by deptno order by sal) last_value
from emp
where deptno = 30
order by deptno, mgr desc;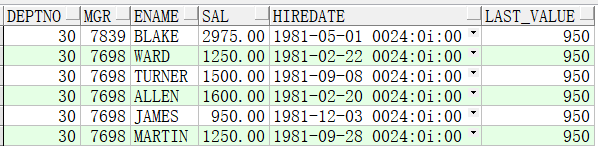
7、first_value()与last_value():求最值对应的其他属性,问题:取出每个月通话费最高和最低的两个地区
准备数据:
create table t(
BILL_MONTH VARCHAR2(12),
AREA_CODE NUMBER,
NET_TYPE VARCHAR(2),
LOCAL_FARE NUMBER
);
insert into t values('200405',5761,'G', 7393344.04);
insert into t values('200405',5761,'J', 5667089.85);
insert into t values('200405',5762,'G', 6315075.96);
insert into t values('200405',5762,'J', 6328716.15);
insert into t values('200405',5763,'G', 8861742.59);
insert into t values('200405',5763,'J', 7788036.32);
insert into t values('200405',5764,'G', 6028670.45);
insert into t values('200405',5764,'J', 6459121.49);
insert into t values('200405',5765,'G', 13156065.77);
insert into t values('200405',5765,'J', 11901671.70);
insert into t values('200406',5761,'G', 7614587.96);
insert into t values('200406',5761,'J', 5704343.05);
insert into t values('200406',5762,'G', 6556992.60);
insert into t values('200406',5762,'J', 6238068.05);
insert into t values('200406',5763,'G', 9130055.46);
insert into t values('200406',5763,'J', 7990460.25);
insert into t values('200406',5764,'G', 6387706.01);
insert into t values('200406',5764,'J', 6907481.66);
insert into t values('200406',5765,'G', 13562968.81);
insert into t values('200406',5765,'J', 12495492.50);
insert into t values('200407',5761,'G', 7987050.65);
insert into t values('200407',5761,'J', 5723215.28);
insert into t values('200407',5762,'G', 6833096.68);
insert into t values('200407',5762,'J', 6391201.44);
insert into t values('200407',5763,'G', 9410815.91);
insert into t values('200407',5763,'J', 8076677.41);
insert into t values('200407',5764,'G', 6456433.23);
insert into t values('200407',5764,'J', 6987660.53);
insert into t values('200407',5765,'G', 14000101.20);
insert into t values('200407',5765,'J', 12301780.20);
insert into t values('200408',5761,'G', 8085170.84);
insert into t values('200408',5761,'J', 6050611.37);
insert into t values('200408',5762,'G', 6854584.22);
insert into t values('200408',5762,'J', 6521884.50);
insert into t values('200408',5763,'G', 9468707.65);
insert into t values('200408',5763,'J', 8460049.43);
insert into t values('200408',5764,'G', 6587559.23);
insert into t values('200408',5764,'J', 7342135.86);
insert into t values('200408',5765,'G', 14450586.63);
insert into t values('200408',5765,'J', 12680052.38);
commit;--分析函数中需要order by 但是这样的话就是从第一行到当前行,所以需要加上 rows between unbounded preceding and unbounded following 定义了从第一行到最后一行
select bill_month,
area_code,
sum(local_fare) local_fare,
first_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) firstval,
last_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) lastval
from t where bill_month=200405
group by bill_month, area_code;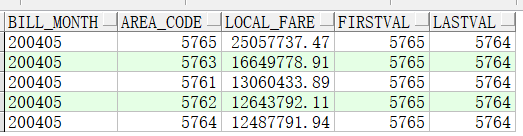
8、lag()与lead():求之前或之后的第N行
lag(arg1, arg2, arg3):
arg1:是从其他行返回的表达式
arg2:是希望检索的当前行分区的偏移量。是一个正的偏移量,是一个往回检索以前的行数目
arg3:是在arg2表示的数目超出了分组的范围时返回的值
而lead()与lag()相反
select bill_month,
area_code,
local_fare cur_local_fare ,--当前行
lag(local_fare, 1, 0) over(partition by area_code order by bill_month) last_local_fare, --上一行
lead(local_fare, 1, 0) over(partition by area_code order by bill_month) next_local_fare --下一行
from (select bill_month, area_code, sum(local_fare) local_fare
from t where bill_month=200405
group by bill_month, area_code);
9、max()、min()、sum()与avg():求移动的最值、总和与平均值
select area_code,
bill_month,
local_fare,
sum(local_fare) over(partition by area_code order by to_number(bill_month) range between 1 preceding and 1 following) month3_sum,
avg(local_fare) over(partition by area_code order by to_number(bill_month) range between 1 preceding and 1 following) month3_avg,
max(local_fare) over(partition by area_code order by to_number(bill_month) range between 1 preceding and 1 following) month3_max,
min(local_fare) over(partition by area_code order by to_number(bill_month) range between 1 preceding and 1 following) month3_min
from (select bill_month, area_code, sum(local_fare) local_fare
from t where bill_month=200405
group by area_code, bill_month);
10、求各地区按月份累加的通话费
select area_code,
bill_month,
local_fare,
sum(local_fare) over(partition by area_code order by bill_month asc) last_sum_value
from (select area_code, bill_month, sum(local_fare) local_fare
from t where bill_month=200405
group by area_code, bill_month)
order by area_code, bill_month;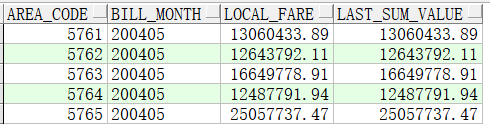
11、ratio_to_report():求百分比,求各地区花费占各月花费的比例
select bill_month,
area_code,
sum(local_fare) local_fare,
RATIO_TO_REPORT(sum(local_fare)) OVER(partition by bill_month) AS area_pct
from t where bill_month=200405
group by bill_month, area_code;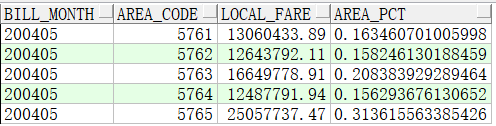
根据以上示例理解分析函数,真正了解分析函数的妙用!
参考:http://www.tuohang.net/article/267713.html
