点击上方蓝字获取更多新鲜资讯
在过去几年中,我们在处理敏感数据的隐私安全方法方面取得了进展,例如:同时发现了对人类迁移的观察以及通过使用联合分析(如RAPPOR)。2019 年,Google 发布了一个开源库,使开发人员或组织能够使用提供差异化隐私的技术,一个被广泛接受的隐私数学概念。差分隐私数据分析是一种原则性方法,它使组织能够从大量数据中学习、理解数据,同时也提供数学保障,这些结果不会逆向推导出个人用户数据。
这篇文章中,我们考虑以下基础问题:给定一个包含多个用户属性的数据库,如何创建有意义的用户组并了解他们的特征?最重要的是,如果手头的数据库包含用户的敏感属性,如何在不损害个人用户隐私的情况下揭示这些群体特征?
聚类是无监督机器学习的基础。聚类方法将数据点划分为组,并提供一种将任何新数据点分配到与其最相似的组的方法。k-means 聚类算法是一个广泛的且相对通用的聚类方法。但是,在处理这些敏感数据集时,它可能会泄露有关单个数据点的隐私信息,从而危及对应用户的隐私。
为此我们的差分隐私库中添加了一种新的差分隐私聚类算法,该算法基于隐私生成新的具有代表性数据点。我们在多个数据集上评估其性能并与现有基线方法进行比较,寻找具有竞争力或更好的性能。
k-means 聚类
给定一组数据点,k-means 聚类的目标是识别(最多)k 个点,称为蔟中心。这将数据点集划分为 k 个组。此外,任何新数据点都可以根据其最近的蔟中心分配给一个组。然而,发布蔟中心集合有可能泄露有关特定用户的信息。例如:考虑一个特定数据点与其余点相距很远的场景,因此标准 k-means 聚类算法返回一个聚类以该单点为中心,从而揭示有关该单点的敏感信息。为了解决这个问题,我们设计了一种新算法,用于在差分隐私框架内使用 k-means 目标进行聚类。
差分隐私算法
在ICML 2021 上发表的“ Locally Private k-Means in One Round ”中,我们提出了一种用于聚类数据点的差分隐私算法。该算法的优点是在本地模型中是安全的,即使在执行集群的服务器中,用户的隐私也得到保护。然而,与使用需要授信服务器的隐私模型的方法相比,其他此类方法精度会下降。
这里,我们提出一种类似的启发式聚类算法,该算法适用于差分隐私的核心模型,其中授信的服务器可以完全访问原始数据,我们的目标是计算过程不泄漏任何隐私信息的差分隐私簇中心的单个数据点。核心模型是差分隐私的标准模型,核心模型中的算法可以更容易地代替非隐私算法,因为它们不需要更改数据获取过程。该算法首先以不同的隐私方式生成一个核心集合,然后由它“代表”数据点集合。然后在这个隐私生成的核心集合上执行任何(非隐私)聚类算法(例如:k-means++)。
该算法首先以递归方式使用基于随机投射的局部敏感哈希(LSH) 将点划分为相似点的“桶”,然后替换每个桶,从而生成隐私核心集合通过单个加权点,即桶中点的平均值,权重等于同一桶中的点数。但是,正如到目前为止所说的,该算法不是隐私算法。我们通过向桶内点的计数和平均值添加噪声,以加密的方式执行每个操作来使其私密。
该算法满足差分隐私,因为每个点对桶计数和桶平均值的贡献被添加的噪声所掩盖,因此该算法的行为不会泄露有关任何单个点的信息。这种方法有一个权衡:如果桶中的点数太大,那么核心集中的点将不能很好地表示单个点,而如果桶中的点数太少,那么与实际值相比,增加的噪声(计数和平均值)将变得显着,导致核心集合的质量较差。这种权衡是通过用户在算法中提供的参数来实现的,这些参数控制可以在一个桶中的点数。
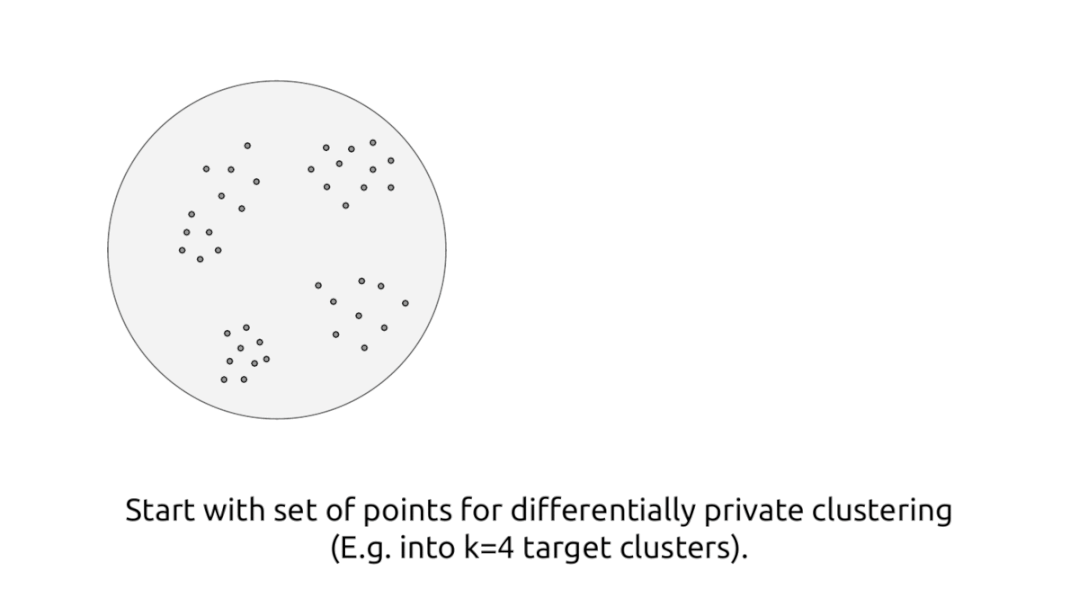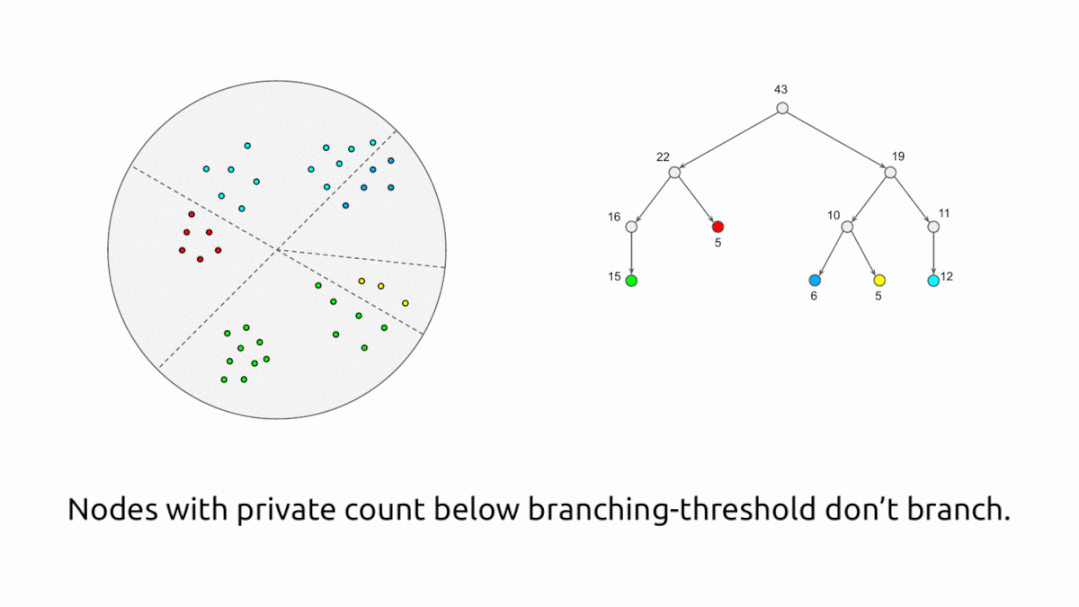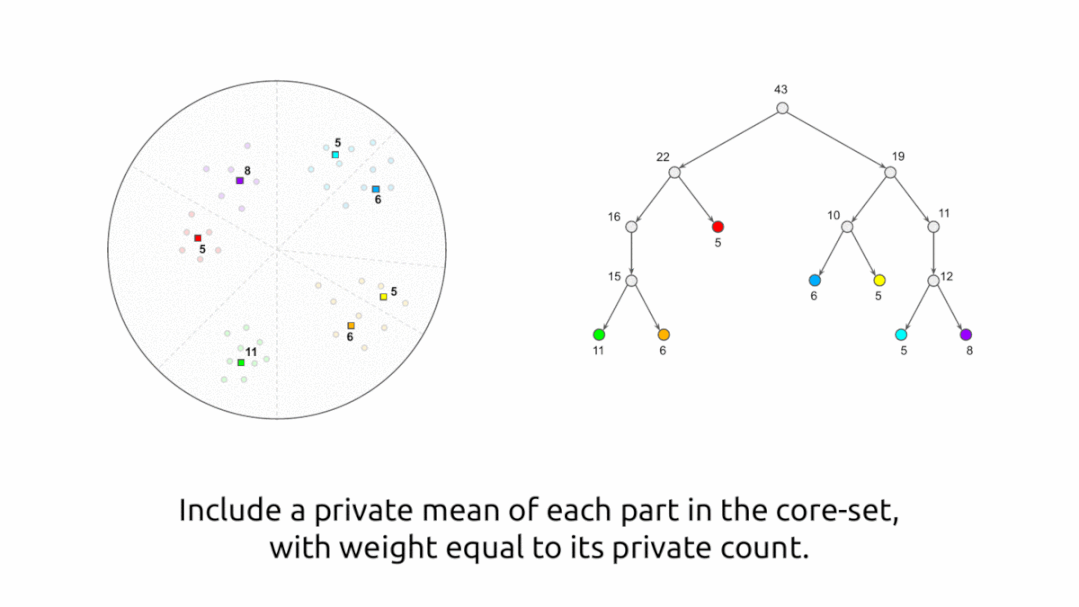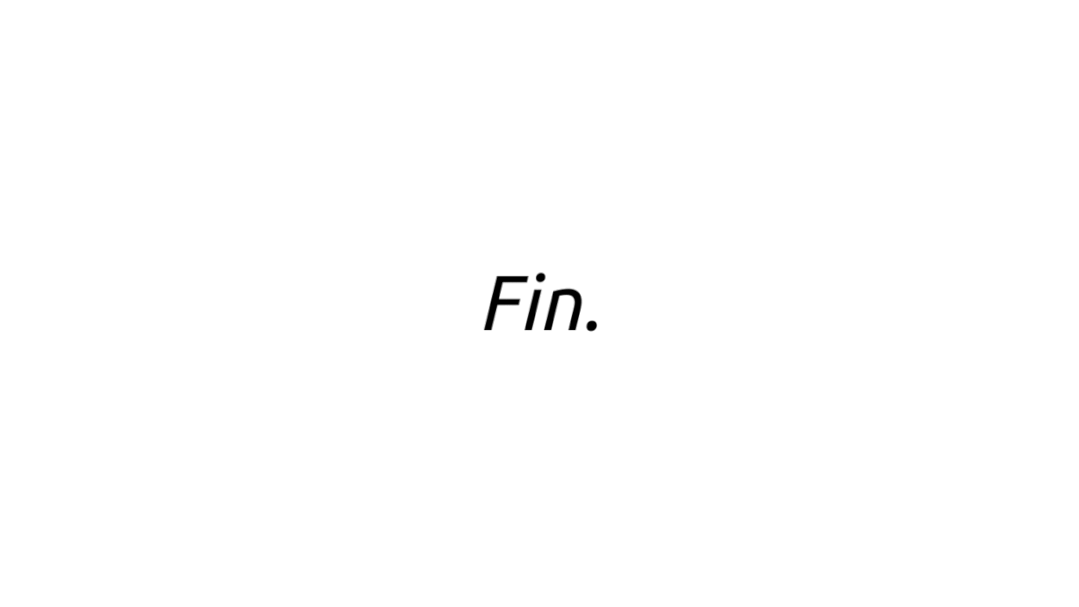
算法的可视化说明。
验证评估
我们在一些基准数据集上评估了该算法,将其性能与(非隐私)k-means++ 算法以及其他一些具有可用实现的算法,即diffprivlib和dp-clustering-icml17 的性能进行了比较。我们使用以下基准数据集:
由 100 个维度的 100,000 个数据点组成的合成数据集,这些数据点是从 64 个高斯混合样本中采样的;
通过训练LeNet 模型获得的手写数字 MNIST 数据集的神经表示;(iii)加州大学欧文分校关于字母识别的数据集;
加州大学欧文分校关于燃气轮机 CO 和 NOx 排放的数据集。
我们分析了归一化的 k-means loss(从数据点到最近中心的均方距离),同时改变了这些基准数据集的目标中心 (k) 的数量。在我们考虑的四个数据集中的三个数据集中,所描述的算法比其他隐私算法的 loss更低。
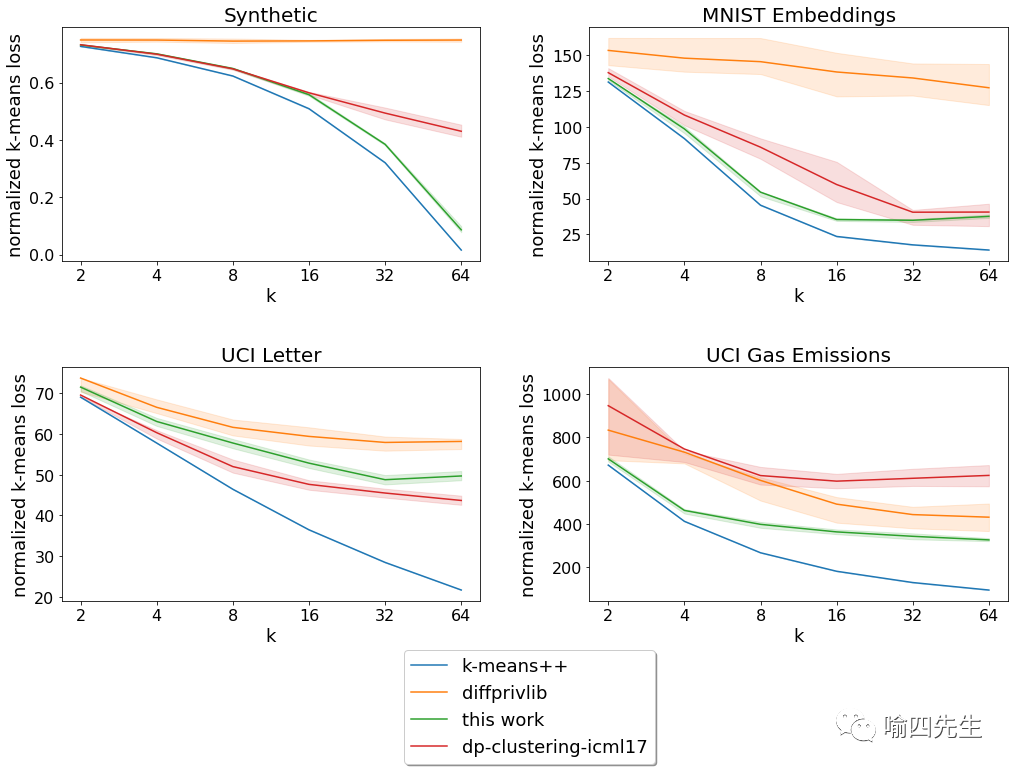
不同 k 的归一化loss = 目标集群的数量(越低越好)。实线表示 20 次运行的平均值,阴影区域表示第 25-75个百分位范围。
此外,对于具有指定ground-truth标签(即已知分组)的数据集,我们分析了聚类标签准确率,它是通过将聚类算法找到的每个聚类中最频繁出现的ground-truth标签分配给该集群中的所有点。在这里,对于我们考虑的具有预先指定的真实标签的所有数据集,所描述的算法的性能优于其他隐私算法。

不同 k 的集群标签准确率 = 目标集群的数量(越高越好)。实线表示 20 次运行的平均值,阴影区域表示第 25-75个百分位范围。
在使用这个或任何其他库进行隐私聚类时,需要考虑几个限制。
在使用隐私聚类算法之前完成的任何预处理(例如,将数据点居中或重新缩放不同坐标)中单独考虑隐私loss是很重要的。因此,我们希望在未来为常用预处理方法的差分隐私版本提供支持,并观察其变化,以便算法在处理不一定预处理的数据时表现得更好。
所描述的算法需要用户提供的半径,以便所有数据点都位于该半径的球体内。这用于确定添加到存储桶平均值的噪声量。请注意,这与diffprivlib和dp-clustering-icml17 不同它采用数据集边界的不同概念(例如,每个坐标的最小值和最大值)。为了我们的实验评估,我们非私下计算了每个数据集的相关界限。然而,在实践中运行算法时,这些边界通常应该在不了解数据集的情况下私下计算或提供(例如,使用数据的基础范围)。但是,请注意,在所描述的算法的情况下,提供的半径不必完全正确;所提供半径之外的任何数据点都将替换为该半径范围内最近的点。
结论
这项工作提出了一种在差分隐私框架内计算代表点(簇中心)的新算法。随着全球获取的数据集数量不断增加,我们希望我们的开源工具能够帮助相关组织获取、分享有关其数据集的有意义的方案,并提供差分隐私的数学保障。
论文相关: dl.acm.org/doi/10.5555/3381089.3381122
文章来源:喻四先生
编辑:苏醒
往期内容:

欢迎投稿
邮箱:kedakeyin@163.com
参与更多讨论,请添加小编微信加入交流群