




❝Enhancing Textbook Question Answering Task with Large Language Models and Retrieval Augmented Generation:
https://arxiv.org/pdf/2402.05128.pdf
摘要
教科书问题回答(TQA)是人工智能中的一个挑战性任务,因为其上下文的复杂性和多模态数据。尽管以前的研究已经显著改进了这项任务,但仍存在一些限制,包括模型的推理能力较弱以及无法捕捉长篇上下文中的上下文信息。大型语言模型(LLMs)的引入已经彻底改变了人工智能领域,然而,直接应用LLMs通常会导致不准确的答案。本文提出了一种方法,通过结合检索增强生成(RAG)技术和利用迁移学习来处理长上下文并增强推理能力,以应对TQA中的“领域外”场景,其中概念分布在不同的课程中。通过对LLM模型Llama-2进行有监督的微调和结合RAG,我们的架构优于基线,在验证集上实现了4.12%的准确率提升,在测试集上对于非图表多选题实现了9.84%的提升。
1 引言
自然语言处理(NLP)是人工智能(AI)中最复杂的应用之一。使用深度学习算法来增强计算机理解自然语言或生成自然语言的能力,为NLP领域带来了最新的进展。在NLP的众多任务中,问题回答(QA)尤为引人注目和广泛。作为AI和NLP的一部分,QA利用NLP技术来响应查询。这项任务要求深入理解语言,以便为人类用自然语言表达的问题提供准确答案。QA研究已经显示出显著的活动,根据输入模态或知识来源将QA系统分类为三类:上下文QA、视觉QA(VQA)和教科书QA(TQA)。上下文QA,也称为机器阅读理解(MRC),涉及模型通过理解文本上下文回答自然语言问题。VQA整合了NLP和计算机视觉(CV),要求模型从图像中推断答案。TQA要求模型通过理解多模态上下文回答多模态问题。2017年,Kembavi和其他研究人员提出了一个数据集,引入了TQA独有的挑战,这些挑战在MRC和VQA中不存在。TQA涉及复杂的推理和理解多模态上下文,包括科学图表和广泛信息,以便回答问题。被认为是AI的一个大挑战,TQA结合了MRC和VQA的挑战,需要大量的研究努力。它代表了多模态机器阅读理解(M3C)任务,涉及中学科学教育领域的文本和图表。TQA任务的挑战包括需要推理能力,这需要视觉理解和语言理解。TQA中的一个具体挑战是上下文的平均长度较长,答案必须从一个平均长度为1800字的上下文中推断出来。有效处理如此长文本上下文中的依赖关系是一个关键挑战。上下文的广泛性质,超过75%的课程中有50多个句子,加上有限的训练数据(15,153个样本),增加了表示现实世界数据多样性和复杂性的复杂性,这阻碍了模型有效泛化的能力。另一个挑战是TQA中的一些概念在不同的课程中解释,这被称为“领域外”问题。领域外问题带来了需要一些技术的需求,这些技术从所有可用课程中检索相关上下文,而不仅仅是问题所在的课程。TQA数据集(CK12-QA)展示了高水平的理解,如图1所示。左侧的问题需要从多个句子中提取答案。相比之下,右侧的问题旨在比较两种情况,以简化或更相关的方式解释复杂概念。它还需要处理定性和定量数据的能力,以及对否定、连接或常识等语言细微差别的深入理解。
2 相关工作
TQA研究始于主要论文MemN [4],他们应用了MRC模型如BiDAF [10]和VQA模型。这些模型在TQA数据集上的表现不佳,准确率比最低验证准确率低2.49%,比最高验证准确率低35.78%,因为数据集本身存在的固有挑战。
根据[11]的分类,TQA研究可以分为三类:基于图的、基于预训练的和基于可解释性的。
基于图的研究侧重于利用基于图的方法解决TQA问题,包括MoCA [12]、IGMN [6]和RAFR [13]的工作。MoCA试图通过引入预训练的语言模型来解决特定领域和一般领域之间的差距。他们将文本上下文和图表视为知识,并为问题选择一组最佳的支持句子和图节点(知识),然后比较不同知识表示的性能。他们应用外部知识来增强跨度级别的表示。MoCA中的文本使用多阶段预训练模块(RoBerta)进行编码,该模块在Wikipedia和BookCurpus数据集上预训练,用于随机掩码策略和CK12-QA用于跨度掩码策略。编码器在RACE和TQA数据集上进行了微调。为了获得MoCA中问题和指导图表的特征,他们使用了一个变换器编码器,并添加了一个线性投影层,将图像的文本和视觉部分对齐到一个共同的空间。为了增强模型,他们使用了一个前馈和层归一化来从多头引导注意力层中获取特征。IGMN试图找到文本上下文和候选答案之间的矛盾,以构建一个矛盾实体关系图(CERG)。他们利用手工编写的语义规则通过CERG理解长文章,其中他们使用Stanford Parser和自然语言工具包(NLTK)来构建它。他们利用空间分析规则通过矛盾实体关系图理解图表。他们使用了BiLSTM和VGG Net。RAFR试图学习有效的图表表示,并将问题、选项和最接近的段落输入到LSTM中以获取它们的表示。他们分析文本在图表中的相对位置和依赖关系,以构建关系图,然后应用双重注意力来预测答案。他们应用图注意力网络(GATs)来理解图表。RAFR只考虑图表上的文本,这导致其他重要视觉信息的丢失。
基于预训练的论文提出了一个多阶段预训练方法,然后使用TQA数据集进行微调,最后进行集成学习,如ISAAC [7]和WSTQ [14]的工作。ISAAC试图克服TQA数据集的复杂性和相对较小的规模以及大型图表数据集的稀缺性等关键挑战。ISAAC分别处理每种类型的问题,忽略了不同类型问题之间的关联,并依赖于大型预训练模型、集成学习和大型数据集。他们结合了一个预训练的变换器(RoBERTa)模型来编码文本和自下而上自上而下(BUTD)注意力,以及六个模型集成用于特征提取。他们使用了四种知识检索器:信息检索(IR)、下一句预测(NSP)、最近邻(NN)和图表检索。文本ISAAC在RACE、ARC-Challenge和OpenBookQA数据集上进行了预训练,并在CK12-QA上进行了微调。为了视觉理解,他们提取了图表组成部分的视觉特征,并应用BUTD注意力来回答图表问题。他们使用BUTD突出显示每个问题最相关的图表或视觉元素。多模态ISAAC在VQA抽象场景、VQA和AI2D数据集上进行了预训练,并在CK12-QA上进行了微调。WSTQ试图学习有效的图表表示。他们应用了一个文本匹配任务来理解文本,并应用了一个关系检测任务来学习图表语义。他们考虑了区域表示及其之间的关系,以学习更有效的图表表示。
第三类在回答问题的过程中使用跨度级别的证据,以提供问题的解释,这在一定程度上实现了足够的可解释性,如XTQA [14]的工作。XTQA将可解释性放在首位,通过提供准确的解释帮助学生更深入地理解他们所学的内容。他们将课程的全部文本上下文视为候选证据,然后应用细粒度算法提取跨度级别的解释来回答问题。他们应用了自监督学习方法SimCLR来学习TQA数据集的表示。
以前的研究依赖于循环和自注意力模型从问题和图表中提取文本特征,经常在处理长上下文时遇到计算限制和可扩展性问题。以前的研究中的检索器是传统QA系统的一个重要组成部分,用于检索可能包含正确答案的相关段落。
检索器可以是稀疏的,依赖于经典的信息检索(IR)方法如TF-IDF [15],密集的,结合DL检索方法如REALM [16]和ORQA [17],或者是迭代的,如MUPPET [18]。由于处理长上下文是TQA的主要挑战,需要努力增强检索与问题相关文本的过程。检索到的文档然后通过后处理或排名组件进行处理。
许多当前的工作使用了统计检索器(TF-IDF)如MemN [4]、IGMN [6]、EAMB [19]的工作。有些使用了搜索引擎,如MHTQA [20],而其他人则采用了基于变换器的模型(BERT、RoBERTa)如图2所示。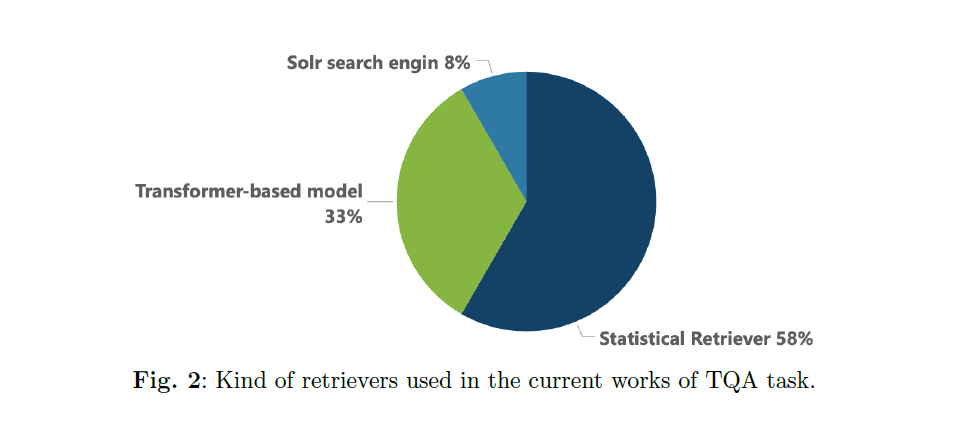
利用语义搜索,在检索与问题有关的信息以便理解方面取得了进展。这包括将整个上下文嵌入一个向量空间,计算距离以找到可衡量的关系,并检索与嵌入的问题或查询最接近(相关)的上下文。由于 TQA 检索器需要用更准确的方法来检索相关上下文,语义搜索通过将整个课程嵌入向量空间和计算距离来满足这一需求,从而提高了对相关上下文的理解能力。
尽管 TQA 系统取得了重大进展,但这些模型在推理能力、文本理解和长语境处理方面仍面临着根本性挑战,这一点从所达到的中等偏低的准确率中可以看出。这些模型可能会提供一个笼统的答案,而不会详细说明具体的回答或结果。这表明,在需要更深层次理解的情况下,模型的推理能力是有限的。
3 TQA数据集
TQA数据集包含1076个课程,涵盖生命科学、地球科学和物理科学。TQA数据集中的每个课程都伴随着多项选择题,每个问题提供2-8个答案选项。这些问题被归类为非图表真/假(NDTF)问题,这些问题有一个真或假的可能答案,非图表多项选择(NDMC)问题,这些问题有4-7个答案选项,以及图表多项选择题,这些问题有四个候选答案。该数据集专注于事实性问题,这些问题可以通过简单的事实或命名实体来回答。答案将以多项选择的形式提供。答案以多项选择的形式提供。数据集被分为训练集、验证集和测试集,每个部分都包含课程和非图表及图表问题。表1显示了非图表问题的分布、课程数量和样本数量。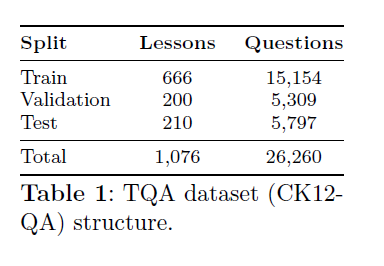
4 信息检索
TQA数据集中的问题性质要求直接从教科书本身包含上下文。然而,在LLM的预训练阶段,这种上下文的覆盖范围可能会有所不同。为了解决这个问题,我们的实验涉及将课程的部分或全部添加到LLM的上下文窗口中。这至关重要,因为仅依赖预训练模型已被证明是不够的,正如我们的实验4所示。这强调了RAG的重要性。RAG作为一个检索机制,集成到LLM的微调管道中,以增强模型的输入。通过使用RAG知识检索技术,模型通过利用检索到的上下文来提高生成文本的连贯性和相关性。为了在微调之前将TQA的知识整合到LLM中,并进一步提高生成文本的质量,我们利用了RAG,它代表了当前的最新技术。主要思想如图3所示,我们将数据集中的知识,由课程内的主题表示,引入到LLM在训练期间获得的现有知识中。检索系统是使用一个嵌入模型构建的,该模型负责将自然语言转换为向量。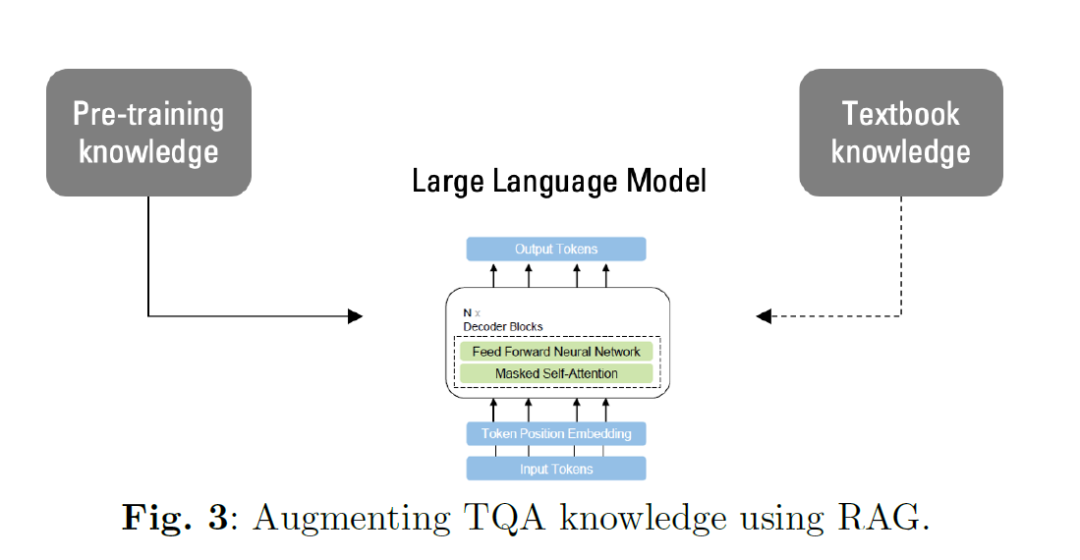
RAG提供了一个解决方案,以解决TQA中跨课程分散信息的问题,同时通过为LLM提供上下文基础,降低LLM响应中幻觉的风险。我们架构中的IR管道涉及使用向量嵌入进行搜索,如图4所示,以检索相关主题并将其纳入LLM的上下文窗口。这个管道包括一个向量数据库,用于存储处理和嵌入的上下文(在我们的案例中是教科书)。知识是基于嵌入查询的块检索的,使用OpenAI文本嵌入ada-002模型。检索到的知识然后添加到LLM的上下文窗口中,有可能通过重新排名模块进行增强,该模块评估检索答案的重要性。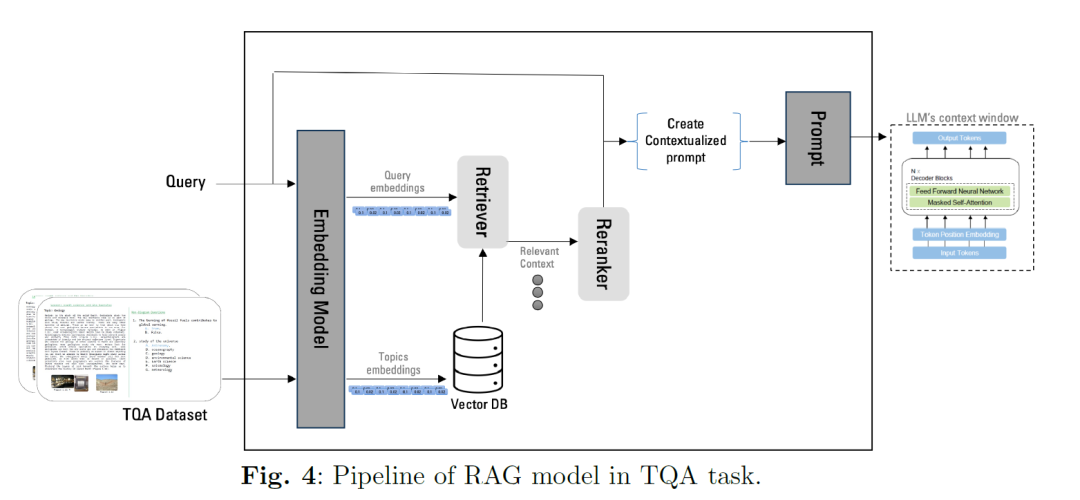
向量数据库的维度取决于嵌入模型的维度。用于计算相似性的相似性度量必须与嵌入模型对齐,无论是余弦还是点积。在架构中结合RAG的LLM被称为RAG模型,这些模型已被证明可以提高准确性。我们的方法集成了一个RAG框架,以准确可靠地回答科学问题,特别是解决“领域外”问题,其中一些问题需要从不同课程的句子中推断答案。为了制定问题,我们有几个问题,其中Qi代表课程中问题i的向量嵌入,以及几个可能得出答案的主题,Tj作为主题j的向量嵌入。由搜索工具创建的向量数据库通过向量搜索返回相关块。我们使用点积度量来计算相似性,通过乘以两个向量并测量它们在方向上的距离。方程1中的Qi和Tj分别代表查询向量和主题向量。
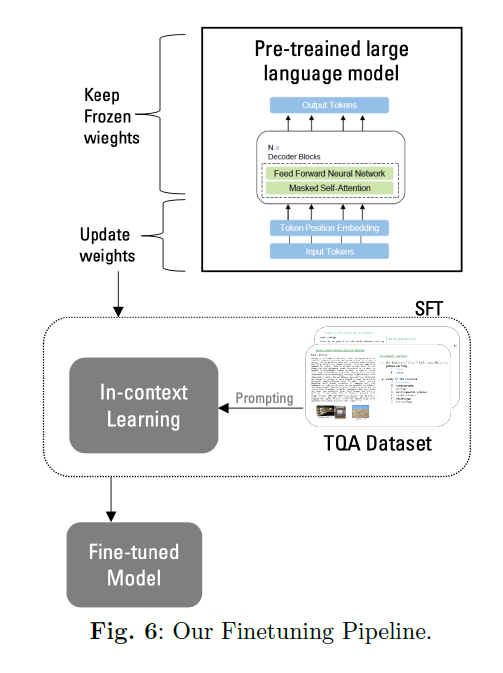
5 微调大型语言模型,Llama-2 在TQA任务中引入的最新语言模型包括预训练的变换器[7] [26],旨在提高TQA系统在准确性方面的性能。随着LLMs在AI领域的影响日益增长,将这些模型整合到TQA任务中对于提高准确性至关重要。自回归模型,或仅解码器模型,代表了一类通过自监督方式广泛训练的变换器模型。虽然最初设计用于预测序列中的下一个标记,但它们通过技术如监督微调(SFT)和从人类反馈中学习的强化学习适应于QA。Llama-2,一个自回归LLM [8],代表了Llama-1的增强,具有增加的训练数据和更大的上下文窗口(4096个标记)。在2万亿个标记的数据上训练,并扩展到700亿个参数,Llama-2作为表现最佳的开源LLM之一脱颖而出。它在推理和阅读理解方面的研究可用性和能力使其成为宝贵的资产。将Llama2的知识与RAG的结果整合,为其现有的训练增加了进一步的深度。微调和提示工程被用来增强LLMs的推理能力。提示工程通过提示实现上下文中的学习。在SFT中,模型使用输入示例和相应的输出进行训练。提示引导模型以对下游任务最优的方式行为。我们的工作利用Llama-2模型作为微调的基础,因为它在语言理解和生成方面具有显著的能力。图5说明了我们处理TQA数据集以供Llama-2提示的一般格式,确保与CK12-QA数据集和模型架构兼容。
 Llama-2通过在CK12-QA数据集上的迁移学习进行了微调。这个阶段涉及通过专门设计用于教科书QA领域的额外训练周期更新模型的权重。微调Llama2的目标是提高其性能和安全性,从而为更负责任的LLM创建铺平道路。微调步骤对于适应特定任务的LLM至关重要。然而,与微调大规模预训练语言模型相关的风险之一是灾难性遗忘,即模型在微调过程中更新参数时可能会忘记一些先前的知识。为了解决这个问题,采用了SFT。SFT专门用于使用比LLM初始预训练使用的更小数据集进行监督学习任务,以增强预训练模型。它通过技术如参数高效微调(PEFT)[33]提供内存高效训练,以减少训练内存使用并使模型量化。量化涉及将激活和参数从浮点值转换为低精度数据类型,如8位整数甚至更低。PEFT涉及冻结LLM的参数,引入一个可训练层(适配器层),并仅在新添加的层上使用来自我们的CK12-QA数据集的示例进行学习,如图6所示。冻结LLM的参数并在添加的层(适配器层)上仅更新新参数,带来了多个好处,包括减少存储要求,最小化微调时间,并防止在微调过程中更新所有模型参数可能导致的LLM知识的丢失。
Llama-2通过在CK12-QA数据集上的迁移学习进行了微调。这个阶段涉及通过专门设计用于教科书QA领域的额外训练周期更新模型的权重。微调Llama2的目标是提高其性能和安全性,从而为更负责任的LLM创建铺平道路。微调步骤对于适应特定任务的LLM至关重要。然而,与微调大规模预训练语言模型相关的风险之一是灾难性遗忘,即模型在微调过程中更新参数时可能会忘记一些先前的知识。为了解决这个问题,采用了SFT。SFT专门用于使用比LLM初始预训练使用的更小数据集进行监督学习任务,以增强预训练模型。它通过技术如参数高效微调(PEFT)[33]提供内存高效训练,以减少训练内存使用并使模型量化。量化涉及将激活和参数从浮点值转换为低精度数据类型,如8位整数甚至更低。PEFT涉及冻结LLM的参数,引入一个可训练层(适配器层),并仅在新添加的层上使用来自我们的CK12-QA数据集的示例进行学习,如图6所示。冻结LLM的参数并在添加的层(适配器层)上仅更新新参数,带来了多个好处,包括减少存储要求,最小化微调时间,并防止在微调过程中更新所有模型参数可能导致的LLM知识的丢失。
6 实验和结果
在本节中,我们将探索我们所提出方法的经验评估,提供实验设置的详细描述,进行的测试以及获得的结果。
6.1 实验设置
所有训练和评估都是在配备A100 GPU的单台服务器上进行的。在SFT技术期间,我们使用了SFTTrainer [32]。我们通过RAG增强了参数化记忆生成模型Llama-2的非参数化记忆。在微调步骤中,我们采用了一种称为低秩适应(LORA)[35]的PEFT技术。PEFT,特别是LORA的目标是通过在微调期间最小化更新参数的数量,降低具有数十亿参数的大型语言模型(LLMs)的训练成本。LORA在变换器架构的每层引入可训练的秩分解矩阵。它仅适应自注意力模块中的权重矩阵以用于下游任务,并使用Adam进行模型优化。所有权重张量都使用bitsandbytes库[34]进行量化,使用一种称为量化LORA(QLORA)[37]的方法,旨在减小模型的大小并加速推理。量化的主要目标是在减少模型的内存占用和处理需求的同时,最小化对模型性能的影响。
在SFT阶段,我们使用了处理过的CK12-QA数据,余弦学习率调度(学习率:2 × 10^-4),权重衰减为0.001,批量大小为4,序列长度为512个标记。在微调过程中,每个样本由提示和答案组成。为确保模型序列长度正确填充,我们使用特殊标记连接了训练集中的所有提示和答案。我们采用了自回归目标,对用户提示中的标记进行零损失,仅在答案标记上进行反向传播。最后,我们对模型进行了2个时代的微调。关于LORA配置,我们将Alpha参数设置为16,使用了0.1的dropout参数,用于LORA的更新矩阵的秩为64。
6.2 主要结果
在CK12-QA数据集上进行了微调语言模型和RAG技术的评估。Llama-2的微调是在训练集上进行的,遵循SFT方法。受到[38]的启发,我们在两个类别的非图表问题上同时对Llama-2进行了微调:多项选择和真/假问题。模型被训练以完成给定的提示,并且损失基于模型提供的答案进行了优化。我们没有惩罚模型预测给定提示中的下一个标记,而是向整理器传递了一个响应模板。这种调整允许模型的权重根据它为问题提供的答案进行调整。在这种方法中,模型提示中的上下文是它所属问题的完整课程。这种Llama-2的上下文改进在测试集性能上得到了提升。在验证集上准确率下降了1.41%,达到了82.40%的准确率。然而,在测试集上,所有文本问题的准确率提高了0.525%,达到了84.24%的准确率。这表明为LLM提供整个课程作为上下文是有效的。
微调模型的性能使用准确率进行评估,并与相关工作进行比较,如表3所示。使用全面的上下文大大提高了准确率,而在整个课程中使用RAG导致了验证集和测试集准确率之间的不同权衡。我们最好的模型,如表2所示,在验证集上实现了4.12%的提升,在测试集上实现了9.84%的提升,与TQA任务上最先进的工作相比。
6.3 消融研究 在本节中,我们旨在进一步了解RAG组件对我们微调模型的影响。在将RAG纳入我们的模型之前,我们首先分析了训练数据中需要来自它们所属课程以外的课程的上下文的问题数量。我们通过计算存储在向量数据库中的基于向量的主题与问题的向量之间的点积来衡量问题与课程内主题之间的相似性。在非图表问题的8,653个训练数据样本中,我们发现只有44%的问题从它们所属的课程中获得了检索到的主题,其余的则来自其他课程的主题。当加入重新排名机制时,从它们所属课程中获得答案的问题的百分比上升到52.43%。这个分析向我们展示了使用解决“领域外”问题的技术的重要性,例如通过将整个课程作为上下文纳入模型的RAG。在CK12-QA示例上未进行微调的Llama-2模型的性能评估显示,在所有文本问题的验证集和测试集上,准确率得分分别为38.09%和38.54%。“所有文本问题”包括NDTF和NDMC问题。这强调了在特定领域数据集上微调LLMs的必要性,并表明模型在准确回答CK12-QA问题方面的有限能力。
通过省略RAG,模型提示中的上下文将是它所属问题的完整课程。这种改进在测试集结果中得到了体现,如图2所示。在表6中,当整个课程和检索到的主题都作为上下文纳入我们的模型时,使用RAG,验证集上达到了83.78%的准确率。然而,在测试集上观察到了略低的81.73%的得分。这表明在增加上下文窗口大小时,可能会达到或超过4096(Llama-2的最大窗口大小)的限制,从而对生成性能产生轻微的权衡。在模型的整个课程作为上下文中,使用RAG重新排名相关主题,降低了验证集和测试集的准确率。如表7所示,验证集达到了80.74%的准确率,而测试集在所有文本问题上获得了79.22%的准确率。这可能是因为向模型提供无关主题,分散了模型的注意力,恶化了模型的推理过程。
7 结论
教科书问题回答(TQA)由于其复杂性,在人工智能(AI)领域提出了重大挑战。随着新的大型语言模型(LLMs)的引入,该领域正在迅速发展,从根本上改变了游戏的动态。本文仅关注TQA任务的文本部分,将视觉部分的整合留作未来工作。我们依赖于迁移学习的最新趋势,旨在增强TQA系统的推理能力,从而提高 整体准确性。利用LLMs的巨大潜力,我们特别通过SFT将LLM模型Llama-2适配到TQA任务。此外,我们结合了RAG技术来提高LLM生成文本的质量,并解决“领域外”问题。我们提出的架构在TQA的文本方面超越了基线性能,对于包括真/假和非图表多项选择题在内的整体文本多项选择题,在验证集上展示了4.12%的准确率提升,在测试集上展示了9.84%的准确率提升。
