赛题名称:海上风电出力预测 赛题任务:预测出力 赛题类型:数据挖掘 赛题链接👇:
https://www.dcic-china.com/competitions/10098
赛题背景
2023年12月1日,我国首个国家级海上风电研究与试验检测基地在福建开工建设,海上风电是实现能源低碳转型的重要战略支撑,大规模海上风力发电已成为国家能源战略发展的重要方向。
赛题任务
本赛题要求选手基于风力海况气象数据、风机性能数据等,针对复杂多变气象和海况条件的深度耦合影响,提出海上风电出力预测模型,提升模型精度以及在工程应用中的可信度,为大规模风电接入下的能源安全可靠运行提供保障。
评价指标

赛题数据集
海上风电出力预测的用电数据分为训练组和测试组两大类,主要包括风电场基本信息、气象变量数据和实际功率数据三个部分。风电场基本信息主要是各风电场的装机容量等信息;气象变量数据是从2022年1月到2024年1月份,各风电场每间隔15分钟的气象数据;实际功率数据是各风电场每间隔15分钟的发电出力数据。
除赛题公布的数据集以外,其他分钟级的气象数据,各选手可参考如下网站资源:
http://www.nmc.cn/publish/satellite/FY4A-true-color.htm (中央气象台)
https://www.jma.go.jp/bosai/map.html#4/36.704/145.811/&elem=ir&contents=himawari (日本气象厅)
(1)基本信息基本信息存储的是五个风电场的位置和装机容量等信息,包括:
| 序号 | 字段名称 | 含义说明 |
|---|---|---|
| 1 | 站点名称 | 风电场名称,字母代码表示 |
| 2 | 装机容量(MW) | 风电装机容量,单位:MW |
(2)气象变量数据气象变量数据存储的是五个风电场从2022年1月到2024年1月份,每间隔15分钟的气象数据,包括:
| 序号 | 字段名称 | 含义说明 |
|---|---|---|
| 1 | 站点名称 | 风电场名称,字母代码表示 |
| 2 | 时间 | 时间,格式为:年-月-日 小时:分:秒 |
| 3 | 气压 | 气压,单位:Pa |
| 4 | 相对湿度 | 相对湿度,单位:% |
| 5 | 云量 | 云量 |
| 6 | 10米风速 | 10米风速,单位:10m/s |
| 7 | 10米风向 | 10米风向,单位:° |
| 8 | 温度 | 温度,单位:K |
| 9 | 辐照强度 | 辐照强度,单位:J/m2 |
| 10 | 降水 | 降水,单位:m |
| 11 | 100m风速 | 100m风速,单位:100m/s |
| 12 | 100m风向 | 100m风向,单位:° |
(3)实际功率数据实际功率数据存储的是五个各风电场从2022年1月到2024年1月份,每间隔15分钟的发电出力数据,包括:
| 序号 | 字段名称 | 含义说明 |
|---|---|---|
| 1 | 站点名称 | 风电场名称,字母代码表示 |
| 2 | 时间 | 时间,格式为:年-月-日 小时:分:秒 |
| 3 | 出力 | 出力,单位:MW |
解题方案
特征构建
# 差值
train_df['100mWindSpeed_10mWindSpeed'] = train_df['100mWindSpeed'] - train_df['10mWindSpeed']
test_df['100mWindSpeed_10mWindSpeed'] = test_df['100mWindSpeed'] - test_df['10mWindSpeed']
train_df['100mWindDirection_10mWindDirection'] = train_df['100mWindDirection'] - train_df['10mWindDirection']
test_df['100mWindDirection_10mWindDirection'] = test_df['100mWindDirection'] - test_df['10mWindDirection']
# 风切变指数
train_df['WindSpeed/WindDirectio'] = train_df['100mWindSpeed/10mWindSpeed'] / train_df['100mWindDirection/10mWindDirection']
test_df['WindSpeed/WindDirectio'] = test_df['100mWindSpeed/10mWindSpeed'] / test_df['100mWindDirection/10mWindDirection']
train_df['100mWindSpeed/10mWindSpeed_2'] = train_df['100mWindSpeed/10mWindSpeed'].apply(lambda x:np.log10(x)) / 10
test_df['100mWindSpeed/10mWindSpeed_2'] = test_df['100mWindSpeed/10mWindSpeed'].apply(lambda x:np.log10(x)) / 10
# 合并训练数据和测试数据
train_df['is_test'] = 0
test_df['is_test'] = 1
df = pd.concat([train_df, test_df], axis=0).reset_index(drop=True)
# 构建特征
num_cols = ['airPressure','relativeHumidity','cloudiness','10mWindSpeed','10mWindDirection',
'temperature','irradiation','precipitation','100mWindSpeed','100mWindDirection']
for col in tqdm.tqdm(num_cols):
# 历史平移/差分特征
for i in [1,2,3,4,5,6,7,15,30,50] + [1*96,2*96,3*96,4*96,5*96]:
df[f'{col}_shift{i}'] = df.groupby('stationId')[col].shift(i)
df[f'{col}_feture_shift{i}'] = df.groupby('stationId')[col].shift(-i)
df[f'{col}_diff{i}'] = df[f'{col}_shift{i}'] - df[col]
df[f'{col}_feture_diff{i}'] = df[f'{col}_feture_shift{i}'] - df[col]
df[f'{col}_2diff{i}'] = df.groupby('stationId')[f'{col}_diff{i}'].diff(1)
df[f'{col}_feture_2diff{i}'] = df.groupby('stationId')[f'{col}_feture_diff{i}'].diff(1)
# 均值相关
df[f'{col}_3mean'] = (df[f'{col}'] + df[f'{col}_feture_shift1'] + df[f'{col}_shift1'])/3
df[f'{col}_5mean'] = (df[f'{col}_3mean']*3 + df[f'{col}_feture_shift2'] + df[f'{col}_shift2'])/5
df[f'{col}_7mean'] = (df[f'{col}_5mean']*5 + df[f'{col}_feture_shift3'] + df[f'{col}_shift3'])/7
df[f'{col}_9mean'] = (df[f'{col}_7mean']*7 + df[f'{col}_feture_shift4'] + df[f'{col}_shift4'])/9
df[f'{col}_11mean'] = (df[f'{col}_9mean']*9 + df[f'{col}_feture_shift5'] + df[f'{col}_shift5'])/11
df[f'{col}_shift_3_96_mean'] = (df[f'{col}_shift{1*96}'] + df[f'{col}_shift{2*96}'] + df[f'{col}_shift{3*96}'])/3
df[f'{col}_shift_5_96_mean'] = (df[f'{col}_shift_3_96_mean']*3 + df[f'{col}_shift{4*96}'] + df[f'{col}_shift{5*96}'])/5
df[f'{col}_future_shift_3_96_mean'] = (df[f'{col}_feture_shift{1*96}'] + df[f'{col}_feture_shift{2*96}'] + df[f'{col}_feture_shift{3*96}'])/3
df[f'{col}_future_shift_5_96_mean'] = (df[f'{col}_future_shift_3_96_mean']*3 + df[f'{col}_feture_shift{4*96}'] + df[f'{col}_feture_shift{5*96}'])/3
# 窗口统计
for win in [3,5,7,14,28]:
df[f'{col}_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().values
df[f'{col}_win{win}_max'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').max().values
df[f'{col}_win{win}_min'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').min().values
df[f'{col}_win{win}_std'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').std().values
df[f'{col}_win{win}_skew'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').skew().values
df[f'{col}_win{win}_kurt'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').kurt().values
df[f'{col}_win{win}_median'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').median().values
# 逆序
df = df.sort_values(['stationId','time'], ascending=False)
df[f'{col}_future_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().values
df[f'{col}_future_win{win}_max'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').max().values
df[f'{col}_future_win{win}_min'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').min().values
df[f'{col}_future_win{win}_std'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').std().values
df[f'{col}_future_win{win}_skew'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').skew().values
df[f'{col}_future_win{win}_kurt'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').kurt().values
df[f'{col}_future_win{win}_median'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').median().values
# 恢复正序
df = df.sort_values(['stationId','time'], ascending=True)
# 二阶特征
df[f'{col}_win{win}_mean_loc_diff'] = df[col] - df[f'{col}_win{win}_mean']
df[f'{col}_win{win}_max_loc_diff'] = df[col] - df[f'{col}_win{win}_max']
df[f'{col}_win{win}_min_loc_diff'] = df[col] - df[f'{col}_win{win}_min']
df[f'{col}_win{win}_median_loc_diff'] = df[col] - df[f'{col}_win{win}_median']
df[f'{col}_future_win{win}_mean_loc_diff'] = df[col] - df[f'{col}_future_win{win}_mean']
df[f'{col}_future_win{win}_max_loc_diff'] = df[col] - df[f'{col}_future_win{win}_max']
df[f'{col}_future_win{win}_min_loc_diff'] = df[col] - df[f'{col}_future_win{win}_min']
df[f'{col}_future_win{win}_median_loc_diff'] = df[col] - df[f'{col}_future_win{win}_median']
for col in ['is_precipitation']:
for win in [4,8,12,20,48,96]:
df[f'{col}_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().values
df[f'{col}_win{win}_sum'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').sum().values
目标转化
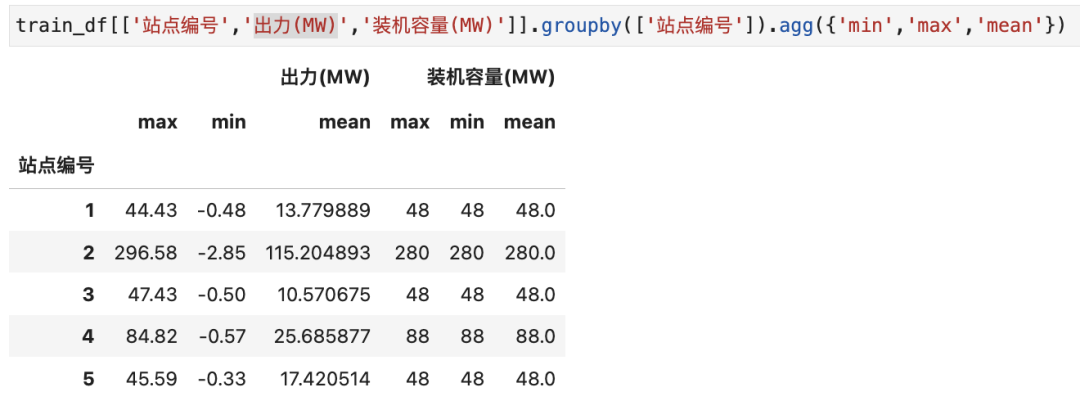
不同站点的出力分布存在差异,将多个站点数据放一起进行训练,相互之间存在干扰,常规做法可以分站点进行训练预测。但装机容量(MW)与出力存在一定关联,具体如下:
模型选择
def cv_model(clf, train_x, train_y, test_x, capacity, seed=2024):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
# 转化目标,进行站点目标归一化
trn_y = trn_y / capacity[train_index]
val_y = val_y / capacity[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse',
'min_child_weight': 5,
'num_leaves': 2 ** 8,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 3000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=500, early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = 1/(1+np.sqrt(mean_squared_error(val_pred * capacity[valid_index], val_y * capacity[valid_index])))
cv_scores.append(score)
print(cv_scores)
if i == 0:
imp_df = pd.DataFrame()
imp_df["feature"] = cols
imp_df["importance_gain"] = model.feature_importance(importance_type='gain')
imp_df["importance_split"] = model.feature_importance(importance_type='split')
imp_df["mul"] = imp_df["importance_gain"]*imp_df["importance_split"]
imp_df = imp_df.sort_values(by='mul',ascending=False)
imp_df.to_csv('feature_importance.csv', index=False)
print(imp_df[:30])
return oof, test_predict
lgb_oof, lgb_test = cv_model(lgb, train_df[cols], train_df['power'], test_df[cols], train_df['capacity']
获取完整代码:
https://github.com/datawhalechina/competition-baseline/tree/master
想要一起参赛?
可以在下面论坛中一起讨论:http://discussion.coggle.club/t/topic/18
或添加下面微信如竞赛群: