




随着OpenAI推出ChatGPT,生成式人工智能(AI)开始引起全球范围内的轰动。这一浪潮不仅吸引了普罗大众的目光,也成为投资界热议的焦点。据《日本经济新闻》报道,全球100多家大规模生成式AI企业的总市值已经达到480亿美元,远超过了2020年的水平,而这一趋势正是由OpenAI所引领的。
然而,在这个竞争激烈的领域中,OpenAI并非唯一的参与者。Jasper、DeepMind、Stability、以及Cohere等竞争者也在不断崛起。作为一家源自加拿大的初创企业,Cohere能够在激烈的竞争中脱颖而出,获得众多投资者的青睐,究竟是如何做到的呢?我们将深入了解该企业的发展历程,并分析其产品与ChatGPT的区别。
Cohere创始人:Aidan Gomez、Nick Frosst 和 Ivan Zhang
Cohere公司于2019年由三位创始人共同创立,分别是艾丹·戈麦斯(Aidan Gomez)、Nick Frosst和Ivan Zhang。他们联合创办了这家自然语言处理(NLP)公司,旨在利用大型NLP模型为外界提供API服务,以提高计算机对文本的理解和生成能力,从而推动NLP技术的发展和应用。

Aidan Gomez和Nick Frosst作为Cohere的联合创始人之一,都曾在谷歌担任研究员,积累了丰富的技术和行业经验。其中,Aidan Gomez是《Attention Is All You Need》论文的作者之一。该论文提出了一种新的网络架构——Transformer,被誉为“祖师爷”,这一架构为后来的ChatGPT等大规模语言模型奠定了基础。
Cohere商业模式
Cohere的商业模式主要围绕其自然语言处理(NLP)技术和相关产品展开,旨在为企业提供强大的语言理解和生成解决方案。
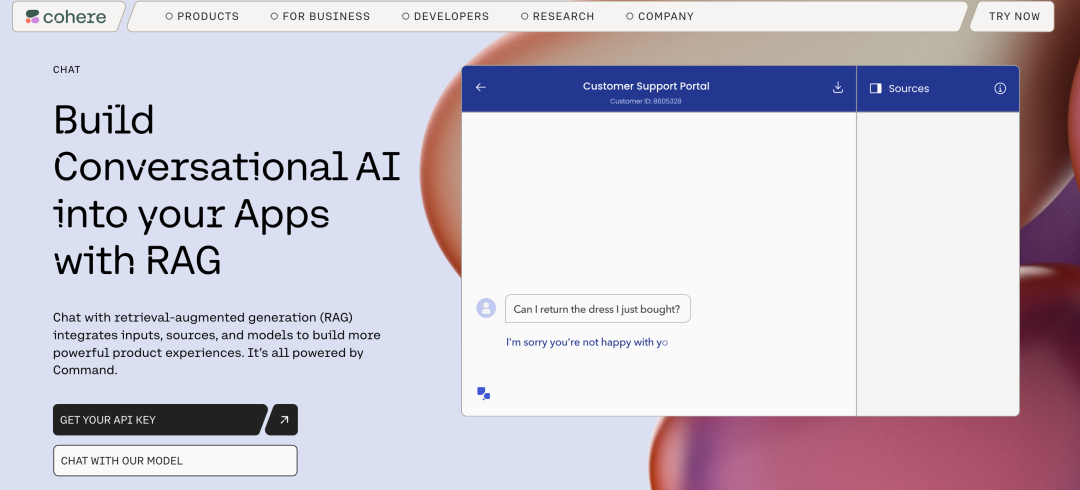
API服务销售:Cohere提供API服务,使企业可以轻松地集成其自然语言处理技术到他们的应用程序中。 企业定制化解决方案:除了通用的API服务外,Cohere还为企业提供定制化的解决方案。通过深度了解客户的需求和业务场景。 训练和咨询服务:Cohere还提供训练和咨询服务,帮助企业利用其技术进行模型的定制和优化。这些服务包括模型调优、数据标注、性能评估。
Cohere API功能
生成(Generate):使用可扩展且价格合理的生成式人工智能工具撰写产品描述、博客文章、新闻稿和营销文案。 摘要(Summarize):提取文章、电子邮件和文档的简明、准确摘要。 神经搜索(Neural Search):在英语或100多种语言中构建准确、高性能的语义文本搜索,适用于任何文档类型。 分类(Classify):用于客户支持路由、意图识别、情感分析等文本分类任务。 嵌入(Embed):访问一个性能超越开源软件的受管嵌入模型,可用于英语和100多种语言,以开发您自己的功能。
API 案例
Chat
Generates a text response to a user message.
import cohere
co = cohere.Client('<<apiKey>>')
response = co.chat(
chat_history=[
{"role": "USER", "message": "Who discovered gravity?"},
{"role": "CHATBOT", "message": "The man who is widely credited with discovering gravity is Sir Isaac Newton"}
],
message="What year was he born?",
# perform web search before answering the question. You can also use your own custom connector.
connectors=[{"id": "web-search"}]
)
Embed
Embeddings can be used to create text classifiers as well as empower semantic search.
在使用模型时,请根据您的具体用例和要求,确保指定适当的输入类型和所需的嵌入类型。
可用模型:
embed-english-v3.0:嵌入维度为1024。 embed-multilingual-v3.0:嵌入维度为1024。 input_type:指定传递给模型的输入类型。对于嵌入模型v3及更高版本,此项为必填。
"search_document":用于嵌入存储在向量数据库中的搜索用例文档。 "search_query":用于运行针对向量数据库的搜索查询的嵌入,以找到相关文档。 "classification":用于通过文本分类器传递的嵌入。 "clustering":用于通过聚类算法运行的嵌入。 embedding_types:指定您希望获得的嵌入类型。
import cohere
co = cohere.Client('<<apiKey>>')
response = co.embed(
texts=['hello', 'goodbye'],
model='embed-english-v3.0',
input_type='classification'
)
print(response)
Rerank
Takes in a query and a list of texts and produces an ordered array with each text assigned a relevance score.
import cohere
co = cohere.Client('<<apiKey>>')
docs = ['Carson City is the capital city of the American state of Nevada.',
'The Commonwealth of the Northern Mariana Islands is a group of islands in the Pacific Ocean. Its capital is Saipan.',
'Washington, D.C. (also known as simply Washington or D.C., and officially as the District of Columbia) is the capital of the United States. It is a federal district.',
'Capital punishment (the death penalty) has existed in the United States since beforethe United States was a country. As of 2017, capital punishment is legal in 30 of the 50 states.']
response = co.rerank(
model = 'rerank-english-v2.0',
query = 'What is the capital of the United States?',
Classify
Prediction about which label fits the specified text inputs best. To make a prediction.
import cohere
from cohere import ClassifyExample
co = cohere.Client('<<apiKey>>')
examples=[
ClassifyExample(text="Dermatologists don't like her!", label="Spam"),
ClassifyExample(text="'Hello, open to this?'", label="Spam"),
ClassifyExample(text="I need help please wire me $1000 right now", label="Spam"),
ClassifyExample(text="Nice to know you ;)", label="Spam"),
ClassifyExample(text="Please help me?", label="Spam"),
ClassifyExample(text="Your parcel will be delivered today", label="Not spam"),
ClassifyExample(text="Review changes to our Terms and Conditions", label="Not spam"),
ClassifyExample(text="Weekly sync notes", label="Not spam"),
ClassifyExample(text="'Re: Follow up from today's meeting'", label="Not spam"),
ClassifyExample(text="Pre-read for tomorrow", label="Not spam"),
]
inputs=[
"Confirm your email address",
"hey i need u to send some $",
]
response = co.classify(
inputs=inputs,
examples=examples,
)
print(response)
Tokenize
Splits input text into smaller units called tokens using byte-pair encoding (BPE).
import cohere
co = cohere.Client('<<apiKey>>')
response = co.tokenize(
text='tokenize me! :D',
model='command' # optional
)
print(response)
# 学习大模型 & 讨论Kaggle #
每天大模型、算法竞赛、干货资讯

