







提升复杂查询并发执行性能
金篆GoldenDB AP引擎引入MPP组件,可以有效提升复杂规模计算效率,MPP充分利用集群中多台服务器的CPU以及内存资源,对海量数据进行快速查询分析。计算节点判断业务请求是OLAP类SQL时,转发给分析型计算节点,由其承担复杂查询、复杂分析的OLAP任务,并根据调度策略分发给相应的数据节点。
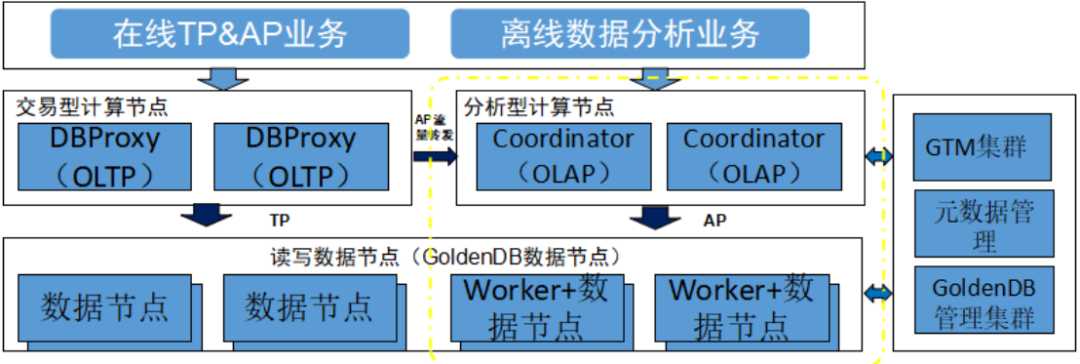
图1 MPP组件提升复杂SQL执行效率
可以通过如下配置启用MPP组件功能:


01 分页设计
Limit方式下的分页,建议排序字段和where条件字段、select_list字段列表一起建立联合索引,避免大数据量遍历时会有全表扫描或者直接读聚簇索引页,避免计算节点二次排序有大量的IO、内存、网络开销。推荐的优化方式:
1)数据按照分页方式进行顺序遍历。每次分页查询记录当前页的最大id,下一页的查询根据当前的最大id作为偏移位置向后取一页数据。该场景有局限性,分页必须是连续的。
2)将待查询出的目标页的主键先查出来,将主键再带回语句中进行二次查询。这样可以避免在计算节点做二次排序时内存开销太大,减少参与排序的数据行大小也是加快排序速度。如针对如下SQL:

3)LIMIT分页与缓存结合,先一次性查询多页记录数据或者全部ID|主键缓存到内存,业务程序实现或通过缓存二次访问数据库来实现分页功能。
02 利用分布式隔离级别提升性能
金篆GoldenDB UR(非一致性读)级别下无需判活(判断GTID是否在活跃事务列表),可以减少和GTM组件的交互以及减少由于活跃GTID冲突带来的GTID查询等待时间,提升读取性能。使用场景:
1)对于业务相关的所有表都会集中在某一个分片,与之相关的分布式事务也会集中在该分片。
2)业务场景涉及查询历史数据,即查询主要涉及历史数据的查询,此部分数据基本不涉及变更。
3)某些可接受脏读的业务场景,即部分分片读取到的是全局未提交的数据。示例SQL:

提升批处理性能
金篆GoldenDB和传统集中式数据在跑批场景下相比可以充分利用分片的优势,分片间并行执行跑批任务,依托数据均衡分布在各分片,可以把跑批应用程序按功能拆分,拆成多个作业(多个程序)并发处理。分后的几个程序之间没有前后依赖关系,可以并行执行。
01 按分片进行批处理
为充分利用分布式数据库的特性,请按分片进行批处理,通过SHOW DISTRIBUTION FROM【table_name】table获取表分片信息后,再通过多个线程使用STORAGEDB语法针对多个分片并发处理。
02 如何处理大数据量查询
批处理涉及大数据量查询,请通过游标方式先把数据的主键查询到本地,在本地确定数据分块的上下边界后,通过使用主键范围作为WHERE条件分批次查询数据。
参考示例,跑批主体查询SQL如下:

为充分发挥分布式模式分片并行处理能力,优化如下:
1)cif_client和mb_acct使用CLIENT_NO做分片键(使得两表JOIN能下压执行)。
2)进一步分析mb_acct表和cif_client哪张表是主表,以主表的主键作为分片键,将主表的主键字段作为冗余增加到从表,并以增加的冗余字段作为从表的分片键。
3)优化索引,CLIENT_NO,ACCT_STATUS,INTERNAL_KEY,main_bal_flag,int_ind,source_module根据情况创建本地索引。
应用侧优化如下:
1)查询表涉及的分片数:SHOW DISTRIBUTION FROM cif_client;返回g1,g2,g3三个分片。
2)每个分片(g1,g2,g3)对应启动一个Pod(共3个)。
3)Pod内主控进程查询该分片mb_acct表的主键范围:select pk from mb_acct;按主键范围分成64段(每段12万CLIENT记录)。
4)启动64个work进程,每个work进程处理一段记录:select ... from CIF_CLIENT iaa,MB_ACCT ia where client_no between分段i。
5)开启流式处理,数据库扫描2000行就返回结果给批量应用(PREPAREdStatement.setFetchSize(2000);)。
6)work进程查询出2000行记录时,再做进一步计算、更新数据库操作,commit事务并记录批量进度(断点重试位置),直到结束。
通过读写分离提升查询性能
读写分离提供了一种将特定的读语句按照预配置的分发规则发送到数据节点分片中的主机或者备机,主要是备机,以此减少对主机的访问,同时提升备机的资源使用率。
针对部分实时性要求不高的查询,可以通过读写分离分发到备机查询,如:历史明细、参数查询。支持实例级和语句级:
1)在连接实例上配置,可选择的配置类型有:不开启读写分离(默认)、本地同城策略、异地策略,其中本地同城策略需要配置权重;
2)语句级别的读写分离策略,通过在sql语句中携带hint实现。hint包括READMASTER、READBALANCE、READSLAVE。
注意:主备DB时延超过阈值时不进行读写分离。
金篆GoldenDB读写分离支持灵活配置读写分离的权重,可以按照本地同城/异地开启权重配置。
通过Insight平台配置读写分离,主要步骤如下:
1)租户管理页面->租户->服务端口->点“编辑”弹出服务端口页面
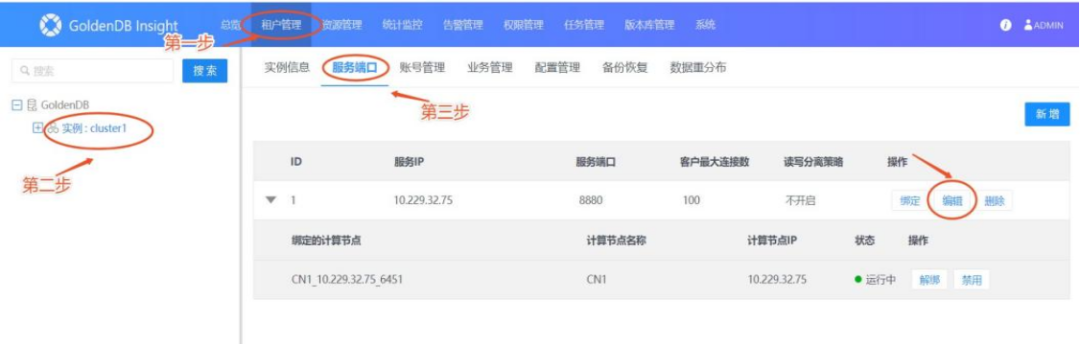
图2 设置服务端口参数
2)设置读写分离策略,编辑服务端口页面并点“确定”使之生效。
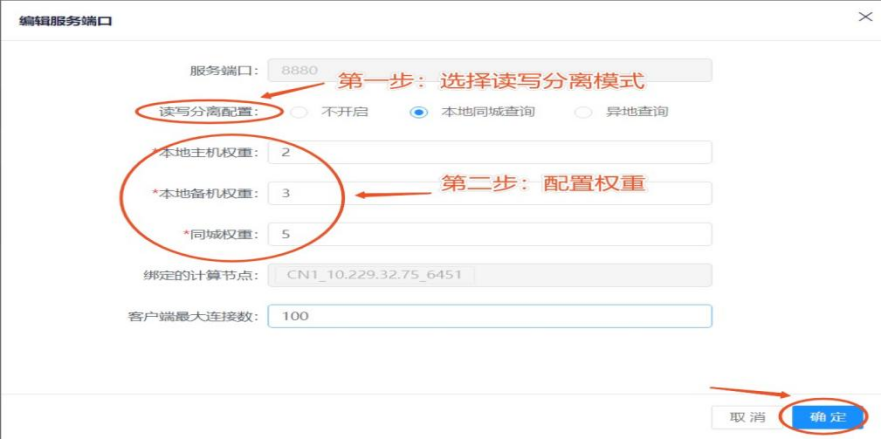
图3 设置服务端口的读写分离策略
数据导入导出
01 使用数据导入导出工具
金篆GoldenDB支持分布式数据库批量数据导入,实现异构数据库之间的数据迁移。如将oracle数据库数据导出为数据文件,可使用金篆GoldenDB工具(LoadServer)导入到金篆GoldenDB数据库中。LoadServer用户也支持批量导入应用端生成的数据等。LoadServer还作为金篆GoldenDB数据逻辑备份,下游用户应用进行数据分析、统计、处理等场景。
导入支持导入全部字段、部分字段、set子句、when子句,同时支持空列以及数据切片提升分片数据并行导入能力,如下为数据导入带when子句示例:
相应导出功能支持导出全部、部分字段、where条件,支持导出按行数和文件数进行切割以及指定分片导出,如下为带有where条件的导出示例:

02 向下游数据库同步数据
SLOTH2.0是金篆GoldenDB自研的数据库迁移工具集,包含迁移评估、数据同步和采集回放3大工具,其中数据同步工具可以提供同构/异构数据同步、支持全量和增量的同步模式以及实时数据一致性校验,目前已支持的同构和异构数据库包括:ORACLE、MySQL、TDSQL、金篆GoldenDB、DB2、KAFKA。

