背景:
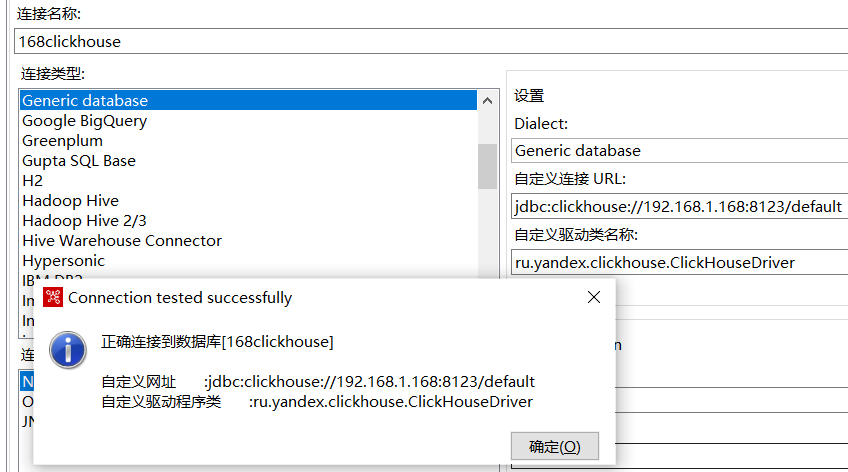
某次工作业务需要追求极致的性能优化,基表数据量大概在800W+。统计类SQL,统计的字段大概有10+个,但是还好是单表统计。在PG中从索引到分表再到分区最后到二级分区。从资源层能力评估到业务层并发量预估。从答疑到说服,从数据表结构设计到数据落地。从SQL语句写法技巧,到隐含参数微调最后到执行计划优化。 花了九牛二虎之力, 最终把SQL大概摁到 900ms左右的样子。 当时在想如果把数据拉到 列式数据库性能是否有改善? 咱毕竟不能只在空中, 需要手动落地。首先就要把数据从pg 抽取到 clickhouse。 数据抽取的话,之前在项目中做过。 当时使用文件作为数据载体。 当时感觉还可以,但是估计不能成为标准化流程。 所以干脆咱就使用数据抽取工具kattle把数据从PG抽取到clickhouse。 重要的第一步:kattle中配置clickhouse连接参数众所周知kattle是不能直接连接clickhouse的,需要单独配置。 配置方式:参考:https://github.com/biwed/PDI-clickhouse
其他的步骤没什么好说的,正常的抽取
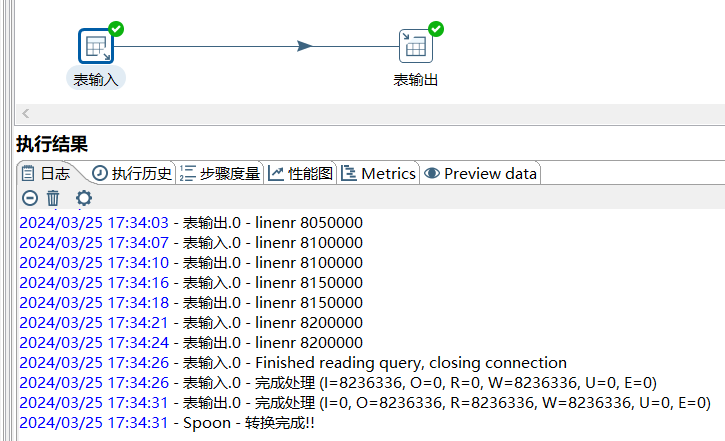
PG中823W条数据,5.5G数据,抽取到clickhouse中耗时:

clickhouse中823W条数据,713M
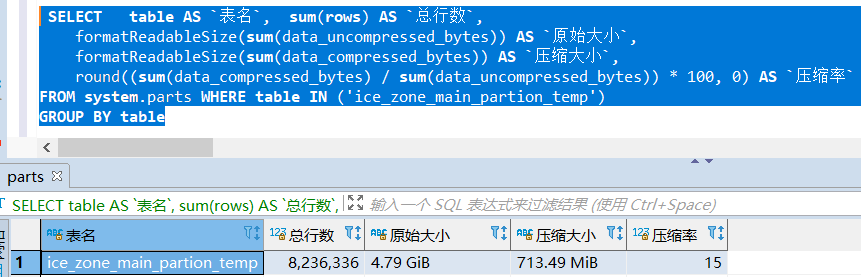
数据压缩比率还是不错的。 先尝鲜下看看是否如真的“速度较快”
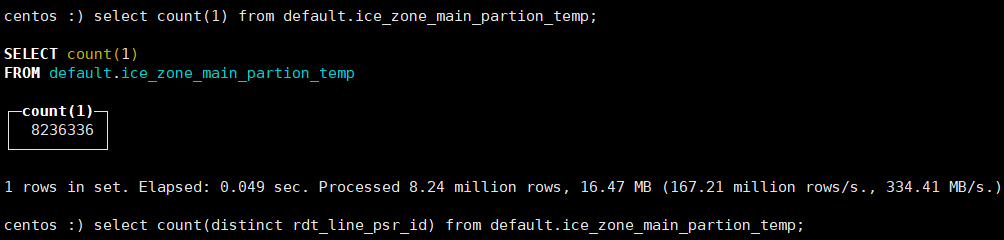

后面测试下并和PG对比下。统计类查询速度对比。数据基表823W, 统计的数据量77W。聚合计算17个字段,过滤7个字段,分组2个字段的SQL的效率。





