




点蓝字关注 设为星标 ☆ 优先赏阅
数据化审计:问题导向、应用至上、解决痛点
问题背景
“如何从公司公告中分析相关政策的影响?”
这个问题源自一位做公司财务方向研究的网友,也启发了一个看问题的视角:重大决策部署、重大政策最终都要落到每个经济实体头上,也必然会影响到每个经济实体的行为。
行为的结果自然也会在经营管理成果中有所映射,在上市的年度报告中,往往会披露各类政策对公司经营管理的影响。
此外,该问题对研究非结构化数据的应用也有借鉴意义。
本文重点是如何在多个文本文件中批量查找,关于如何在多个word文档中查找关键词,参见文章《如何批量在多个word文档中查找关键词? 》

图源:WW
实现思路
要分析这种影响,首先需要查找相关政策关键字在公告中的位置,然后读取关键字的上下文,再对这些文字进行分词、共词分析等处理、展现。
实现步骤如下:
文本内容获取,文本清洗,编码格式判断。这一步涉及从PDF文档中抽取文本的处理,还有文本内容的规范化处理。在python的PDF处理库pdfminer中,文字版本的PDF文件中的文本内容一般为位于LTTextBox中,可以使用get_text()函数提取。本文不赘述。公告PDF文件转为文本文件后,存放在代码所在目录的txt子目录下,每个公告一个文本文件(*.txt)。
循环读取文件,根据指定的关键词,查找关键词所在的上下文。本例中,查找“产业政策|货币政策|环保政策”三个关键词。为便后续溯源和分析,查找结果存入Excel文件,包括六个字段:文件名、行数、关键字、上下文、前一段、后一段。
对关键词所在的文本内容进行分词和词频统计,分析政策相关的共词。在使用jieba库进行分词过程中,需要根据文本的实际内容,增加自定义词组、停用词等处理。
代码运行环境
主环境为python 3.8 。Python 3.8.5 (default, Sep 3 2020, 21:29:08) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32。
核心外部库:
pandas==1.1.3 jieba==0.42.1
实现代码
"""
Python 3 环境
"""
import glob
import pandas as pd
import re # 内置的正则表达式处理库
import codecs
import jieba
# 建立一个空白的pandas数据框 df,用于存放查找的结果
# 并考虑提取关键字所在的前后段落作为参考
df = pd.DataFrame(columns=[u'文件名',u'行数',u'关键字',u'上下文',u'前一段',u'后一段'])
# 确定查询关键词 多个关键词间用英文的 | 隔开,并放在英文括弧中 ()
kw = u'(产业政策|货币政策|环保政策)'
# 建立一个正则表达式规则字符串,匹配关键词前后的所有中文
# 关键词前后各取30个字作为上下文摘要,可以调整数值
regstr = u'([\w\W\u4e00-\u9fff]{0,30}'+kw+u'[\w\W\u4e00-\u9fff]{0,30})'
pattern = re.compile(regstr)
# 循环读取指定目录下的文本文件 进行检索
for f in glob.glob('txt/*.txt'):
# 逐个读取文本文件 并将文本文件内容逐行存入list
with codecs.open(f,mode='r',encoding='utf-8') as fp:
fcontentlist = fp.readlines()
# 对每行文本进行循环查找
for index,p in enumerate(fcontentlist):
results = pattern.findall(p)
# 查找的结果是个list变量,可以理解为存储多个值的表
# 循环查找结果的list 提取每个查找结果
for result in results:
## 显示下查询结果
print(u'【{}】-第【{}】段包含关键字【{}】\r\n上下文内容【{}】'.format(f,index,result[1],result[0]))
# 创建一个空的list 用于存储6个字段的内容
# strip函数删除结尾的换行字符
row = []
row.extend([f,index+1,result[1],result[0].strip('\r\n'),fcontentlist[index-1].strip('\r\n'),fcontentlist[index+1].strip('\r\n')])
# 在数据框中添加一行记录,包括6个字段的数据
df.loc[len(df)] = row
## 将数据框中的查询结果保存为中文格式的Excel文件
df.to_excel(u'查询结果.xlsx',encoding='gbk')
保存后的数据如下图所示:

# 对检索结果进行分词梳理,找到检索关键词的关系词
# 增加一个自定义词汇
jieba.add_word('环保政策')
# 根据实际情况 增加一些停用词
stopwords = ['我国','如果','主要','相关','一是','二是','三是']
segments = []
for idx,row in df.iterrows():
ls = row['前一段'] + row['上下文'] + row['后一段']
segs = jieba.cut(ls.replace(' ',''))
#print(list(segs))
for seg in segs:
if len(seg)>1 and seg not in stopwords:
segments.append({'word':seg,'count':1});
# 转换为dataframe 后续好计算
df_seg = pd.DataFrame(segments)
# 统计词频
df_wordcount = df_seg.groupby('word')['count'].sum().reset_index()
# 按照词频倒序排列
df_wordcount.sort_values(["count"],ascending=False,inplace=True)
# 列出前20个词
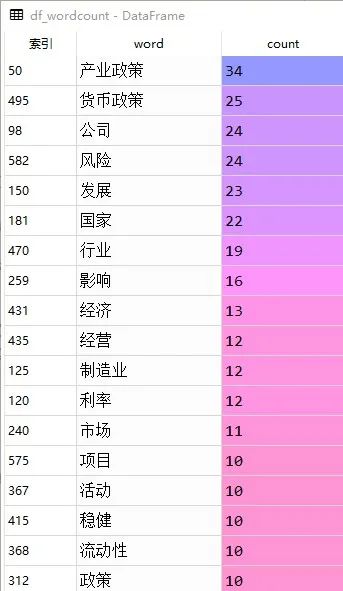
df_wordcount.head(20)
和“产业政策|货币政策|环保政策”相关高频出现的20个词语如下:
延伸应用
可以根据共词理论,对每个句子中的关键词进行抽取,建立共词矩阵,进行聚类等分析,找出这些文本聚焦的共同话题。
还可以将每个句子分词的结果当成一个“购物篮”数据,对相关词语出现的情况进行预测分析。
另外,由于微信公众号推送机制的调整,大家可以点下“赞”和“在看”,这样每次文章推送后,就会第一时间出现在您的订阅号列表中。
