




分布式数据库系统的运行中,DN和CN节点会定时上报业务执行数据到INSIGHT中,INSIGHT根据这些信息制定好各类图标后展示到页面中供用户分析系统业务运行情况。
● 摘要
查看各个计算节点的性能统计数据。
● 事务数统计趋势图直观展示计算节点不同指标的统计数据。
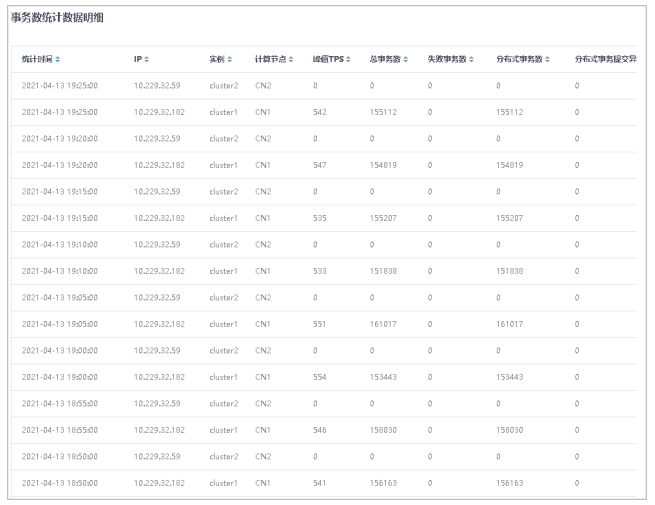
● 事务数统计数据明细通过表格详细展示了事务数统计数据。
● 步骤
1.选择菜单[统计监控→监控→事务数统计],进入事务数统计界面。
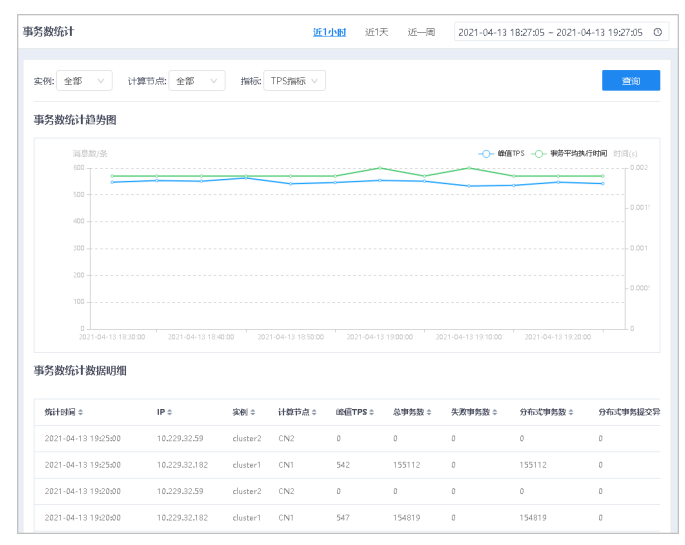
2.设置统计条件,单击查询按钮,查询符合条件的统计数据。
● 可以通过右上角的时间范围选择查询时间段,可查询不同时间范围内的数据。
● 可手动自定义一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
● 实例下拉框可以选择当前用户下所有的实例。选择实例后,可以选择对应计算节点,默认选择全部。
● 指标包括:TPS指标、异常指标、事务构成指标、分布式写事务构成指标、语句数指标。
3.在事务数统计趋势图中,鼠标悬停在图上的数据点,可查看该点的详细数据信息。
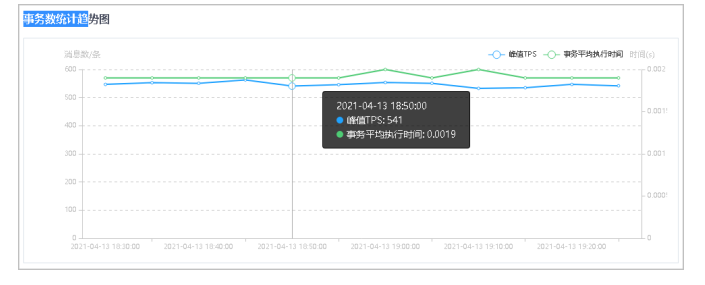
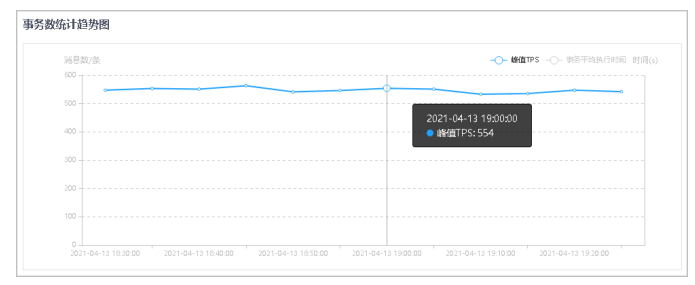
4.单击右上角筛选指标,可查看/隐藏对应折线图数据。
5.在事务数统计,单击表头各列的三角按钮,可对数据进行升序/降序排序。
● 摘要
事务响应统计展示各个计算节点的事务响应统计。
事务响应统计趋势图直观的展示了计算节点事务响应的统计数据。
注意,此项统计需要保证对应开关打开,可以手动进行配置,在对应计算节点的家目录下,在etc/proxy.ini中[SQLEXEC]段下添加配置“stat_conninstance_item=1”,动态生效(执行“dbtool -p -lc”)。
● 步骤
1.选择菜单[统计监控→监控→事务响应统计],进入事务响应统计界面。
2.设置统计条件,单击查询按钮,查询符合条件的统计数据。
● 可选择右上角的时间范围,查询到不同时间范围内的数据。
● 可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
● 实例下拉框可以选择当前用户下所有的实例,选择实例后,可以选择对应连接实例,然后可以选择对应计算节点,默认选择全部。
3.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
4.单击右上角筛选指标,可查看/隐藏对应折线图数据。
● 摘要
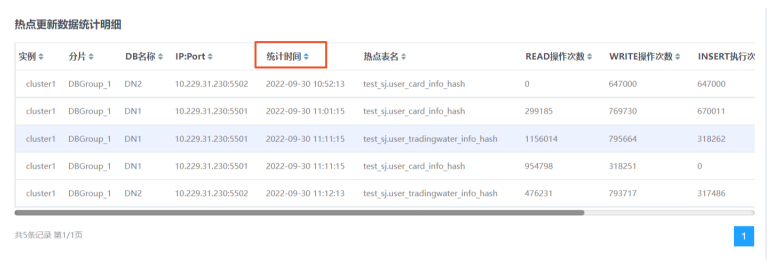
热点更新数据统计页面,可统计监控频繁访问的热点更新数据,并依此做出相应业务调整。
● 步骤
1.选择菜单[统计监控→监控→热点更新数据统计],进入热点更新数据统计界面。
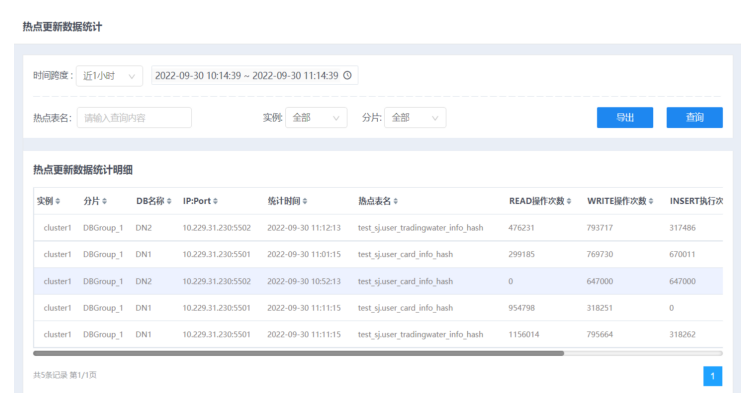
2.设置统计条件,单击查询按钮,查询符合条件的统计数据。
● 可选择右上角的时间范围,查询到不同时间范围内的数据。
● 可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
● 实例下拉框可以选择当前用户下所有的实例,选择实例后,可以选择对应连接实例,然后可以选择对应计算节点,默认选择全部。
3.在热点表名搜索框中输入想要查询的热点表名,点击查询按钮,可以根据热点表名信息更精确的定位数据。
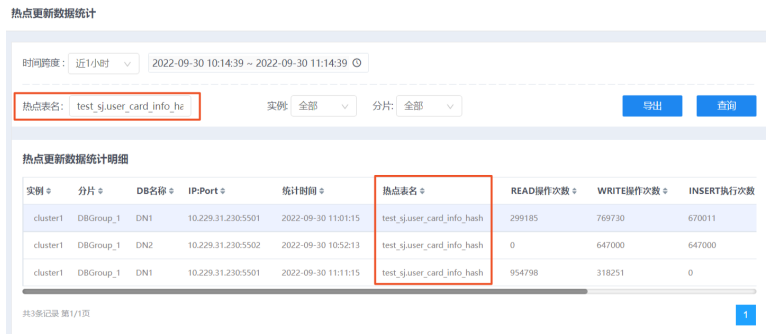
4.在统计明细中,单击表头各列的三角按钮,可对数据进行升序/降序排序。
● 摘要
SQL类型统计页面,可查看下实例层、分片层、数据节点层的总SQL语句数量。
实例层可以查看当前用户下所有实例的总SQL语句数量。
● 步骤
1.选择菜单[统计监控→监控→SQL类型统计],进入SQL类型统计界面。
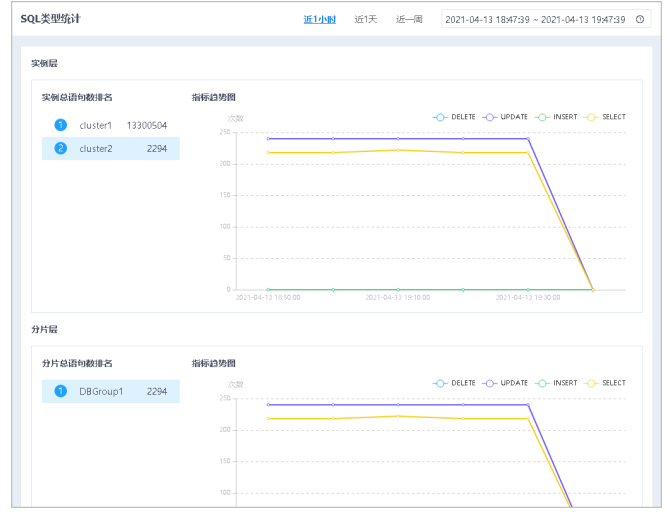
2.设置右上角的时间范围,可查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
3.在实例层区域,单击不同的实例,可直观的查看不同时间范围的指标趋势图。
4.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
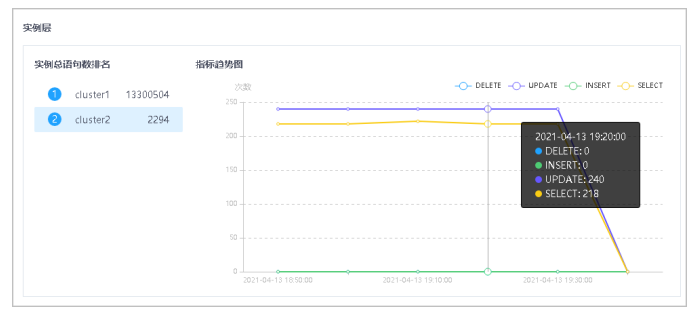
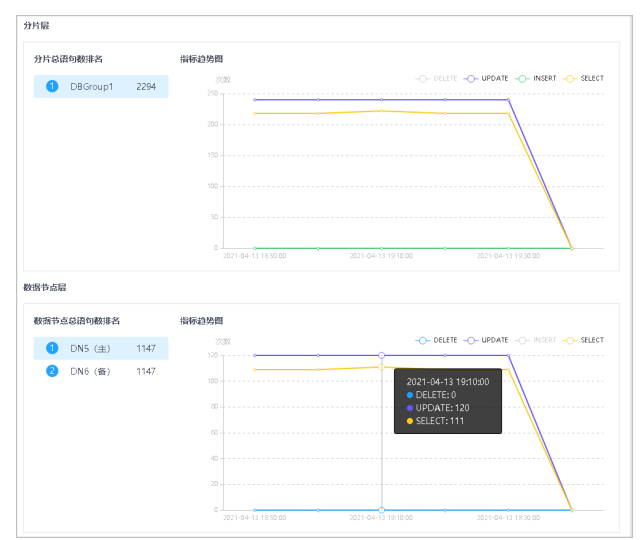
5.单击右上角筛选增、删、改、查筛选条件,可显示/隐藏SQL语句对应折线图数据。
6.分片层和数据节点层可参考实例层执行相应查看操作。
● 摘要
通过连接数统计,可查看客户端与计算节点的连接数统计,以及计算节点与各个数据节点之间的连接趋势。
注意:此项统计需要保证对应开关打开,可以手动进行配置,需要在对应GTM节点的家目录下,在etc/gtm.ini中配置“ReportSwitch=1”,动态生效(执行“dbtool -gtm -lc”)。
● 步骤
1.选择菜单[统计监控→监控→连接数统计],进入连接数统计界面。
2.设置右上角的时间范围,可查询到不同时间范围内的数据。
3.可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
4.选择不同的连接实例后可以选择相应的计算节点,从而直观的展示一定时间范围内客户端与不同计算节点的连接数,默认选择全部。
5.鼠标悬停在图上的数据点可查看该点的详细数据信息。
6.单击右上角筛选条件,可显示/隐藏对应折线图数据。
7.在计算节点与数据节点之间的连接趋势中,单击单个数据节点连接变化趋势页签。
8.选择不同的实例、相应的分片,可以直观的展示一定时间范围内计算节点与相应数据节点之间的连接趋势,默认选择全部。
9.通过切换只显示主、显示主备,可以选择是否只显示计算节点与主DN之间的连接趋势。
10.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
11.通过单击右上角筛选条件,可显示/隐藏对应折线图数据。
12.切换到数据节点连接数排行页签。
13.选择不同的实例,展示计算节点与相应数据节点之间的连接数排行,默认选择全部。
14.选择不同指标(包括最大连接数、最大活跃连接数、评价连接数、平均活跃连接数、新增连接数),以及Top数(可选5、10、20),可进行数据筛选展示。
● 摘要
统计GTID数据,可查看活跃GTID变化趋势,GTID申请、释放平均耗时变化趋势以及GTM服务器CPU、IO变化趋势。
注意:此项统计需要保证对应开关打开,可以手动进行配置,需要在对应GTM节点的家目录下,在etc/gtm.ini中配置“ReportSwitch=1”,动态生效(执行“dbtool -gtm -lc”)。
● 步骤
1.选择菜单[统计监控→监控→GTID统计],进入GTID统计界面。
2.设置右上角的时间范围,可查询到不同时间范围内的数据。
3.可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
4.选择不同的实例、相应的连接实例,从而直观的展示一定时间范围内活跃GTID变化趋势及GTID申请、释放平均耗时变化趋势。默认选择全部。
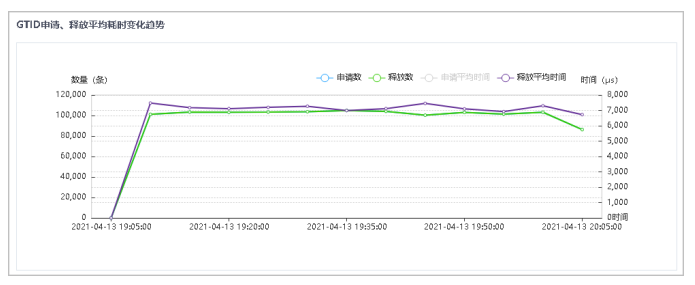
5.鼠标悬停在图上的数据点可查看该点的详细数据信息。
6.单击右上角筛选条件,可显示/隐藏对应折线图数据。
7.在GTM服务器CPU、IO变化趋势中,通过选择右上角不同的GTM服务器,可展示其CPI、IO变化趋势。
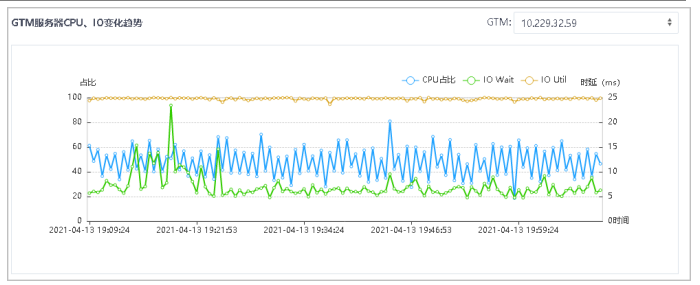
8.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
9.单击右上角筛选条件,可显示/隐藏对应折线图数据。
● 摘要
通过空间监控功能,可查看不同实例、分片所在空间的各项指标统计。
● 步骤
1.选择菜单[统计监控→监控→空间监控],进入空间监控界面。
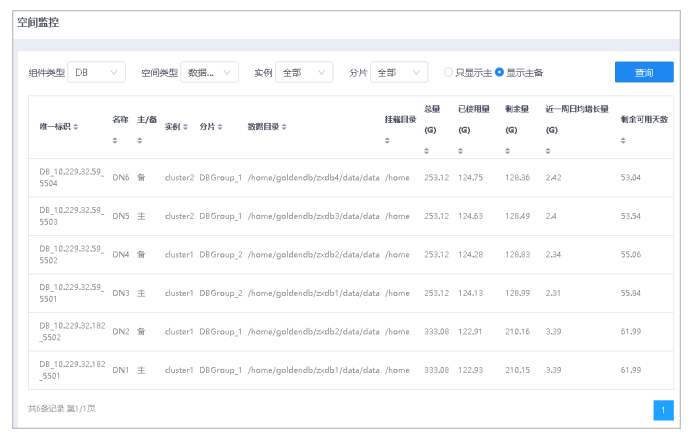
2.设置查询条件,单击查询按钮,查询相应组件类型所在空间的各项指标统计。
● 组件类型:可选DB和RDB。
● 空间类型:可选数据目录和备份目录。
● 选择不同的实例后可以选择相应的分片。
● 切换只显示主、显示主备,选择是否只显示主DN所在空间数据。
3.单击表头各列的三角按钮,可对数据进行升序/降序排序。
● 摘要
通过表空间监控功能,可查看表空间Top10及表空间列表。
● 步骤
1.选择菜单[统计监控→监控→表空间监控],进入表空间监控界面。
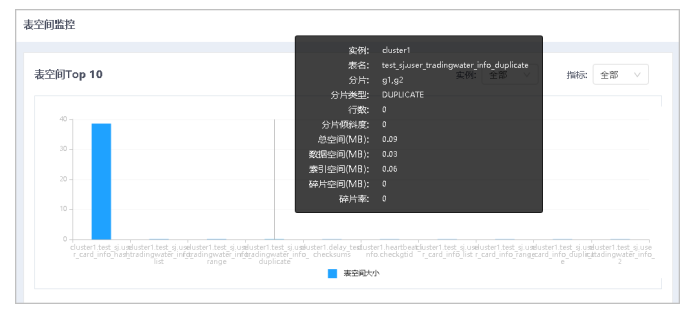
2.选择不同的实例,展示相应表空间大小Top10数据。
通过选择不同指标(包括总行数、碎片率、分片倾斜度),展示其表空间Top10。
3.鼠标悬停在图上的数据点可查看该点的详细数据信息。
4.在表空间列表区域,选择实例、相应的库名,展示该实例下对应库的表空间列表(支持表名模糊查询)。
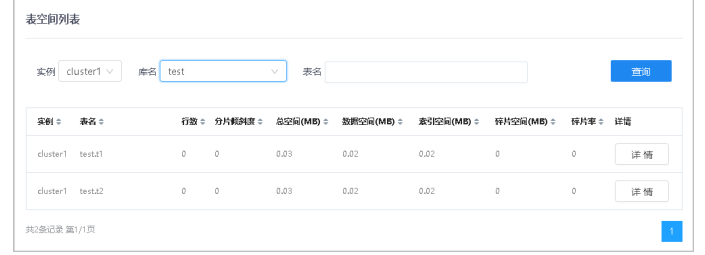
5.单击表头各列的三角按钮,可对数据进行升序/降序排序。
6.在待查看列表行,单击详情按钮,进入表空间诊断详情界面,查看所选表的分片规则及分片倾斜度。
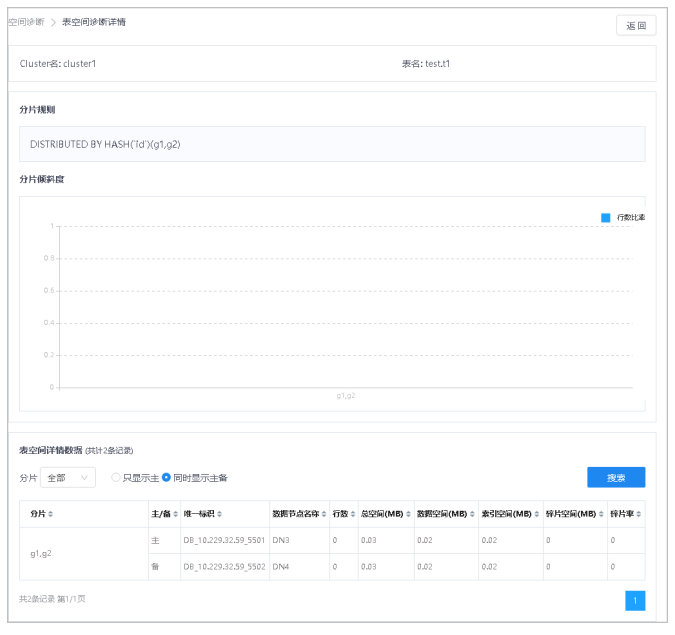
7.鼠标悬停在柱状图,可查看详细数据信息。
8.通过选择不同分片,查询表空间详情数据。
9.切换只显示主、同时显示主备,选择是否只显示主DN相关数据。
● 摘要
通过对SQL语句的统计,可查看不同实例、连接实例、分片根据不同指标的Top排行。
注意,此项统计需要保证对应开关打开,可以手动进行配置,在对应计算节点的家目录下,在etc/proxy.ini中[SQLEXEC]段下添加配置“stat_conninstance_item = 1”和“stat_report_interval (不要为0,可以为60)”,重启生效(执行“dbmoni -stop;dbmoni -start”)。
● 步骤
1.选择菜单[统计监控→监控→TOPN],进入TOPN界面。
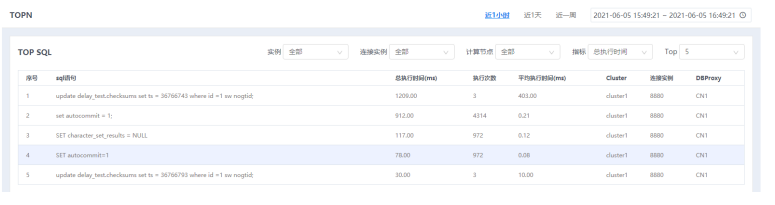
2.设置右上角的时间范围,可查询到不同时间范围内的数据。
3.可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
4.实例下拉框可以选择当前用户下所有的实例,选择实例后,可以选择对应连接实例,然后可以选择对应计算节点,默认选择全部。
5.选择不同指标(包括总执行时间、平均执行时间、执行次数),以及Top数(可选5、10、30),可进行数据筛选展示。
● 摘要
通过对SQL语句的统计,可查看不同实例、连接实例、分片根据不同指标的SQL语句执行时间并将其与历史比对。
注意:此项统计需要保证对应开关打开,可以手动进行配置,在对应计算节点的家目录下添加配置,重启生效。
● 步骤
1.选择菜单[统计监控→监控→SQL比对],进入SQL比对界面。
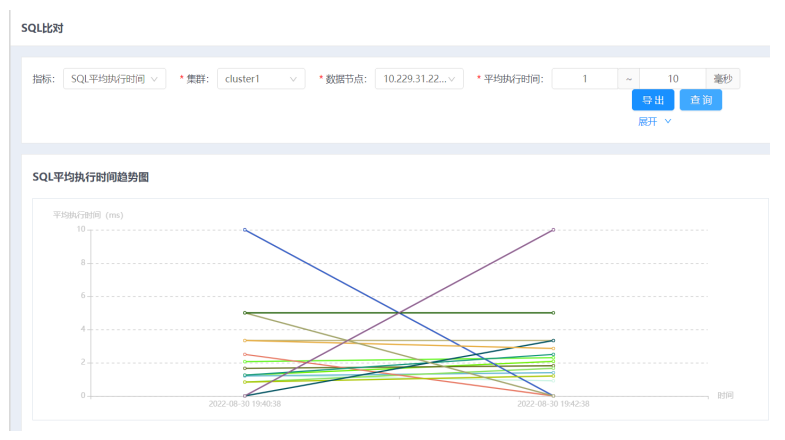
2. 设置不同的指标、集群、数据节点、平均执行时间来查询指定的SQL评价执行时间趋势图。
3. 可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
4. 在实例层区域,单击不同的实例,可直观的查看不同时间范围的指标趋势图。
5. 鼠标悬停在图上的数据点,可查看该点的详细数据信息。
6. 点击导出可以将数据导出。
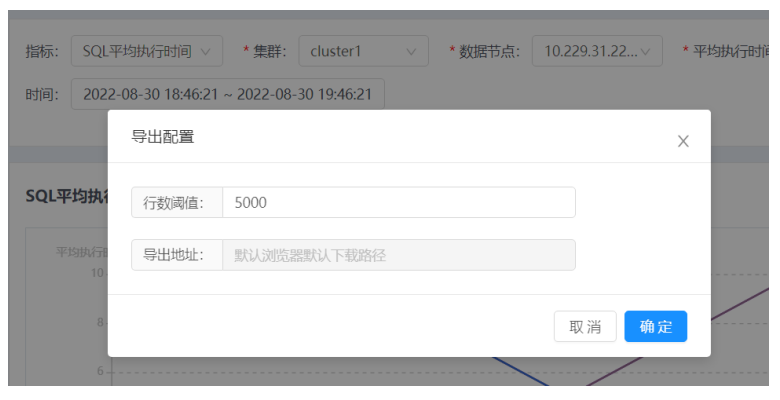
1. 下方可以查看SQL平均执行时间具体明细。
● 摘要
集成在通用报表中,通过对服务器CPU的实时监控统计,筛选出是哪些db的哪些sql语句导致的CPU的冲高。
注意:因为CPU记录具有时效性,此项统计并不是百分百抓住到引起CPU冲高的sql语句。
● 步骤
选择菜单[统计监控→监控→CPU冲高记录],进入CPU冲高记录界面。
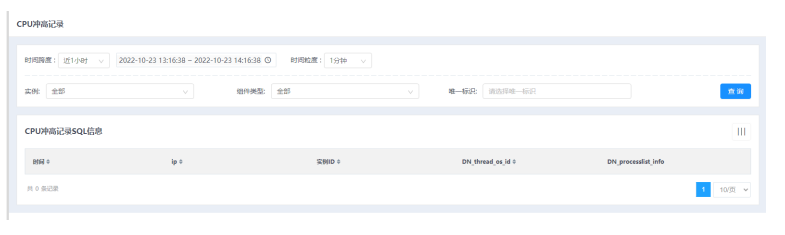
1.拥有通用报表的基础查询条件和查询结果默认字段
2.自动隐藏了部分字段,可通过点击表格右侧的竖条按钮选择展开字段
3.查询结果支持分页
● 摘要
慢日志分析包括慢SQL分析变化趋势和慢SQL数据明细。
注意:此项统计需要保证对应开关打开,可以手动进行配置,在对应计算节点的家目录下,在etc/proxy.ini中配置“slow_query_log=1”和“long_query_time=100”,动态生效(执行“dbtool -p -lc”)。还需要在所有主db家目录下的etc/my.cnf中配置“slow_query_log=1”和“long_query_time=0.1”,重启生效(执行“dbmoni -stop;dbmoni -start”)。
● 步骤
1.选择菜单[统计监控→诊断→慢日志分析],进入慢日志分析界面。
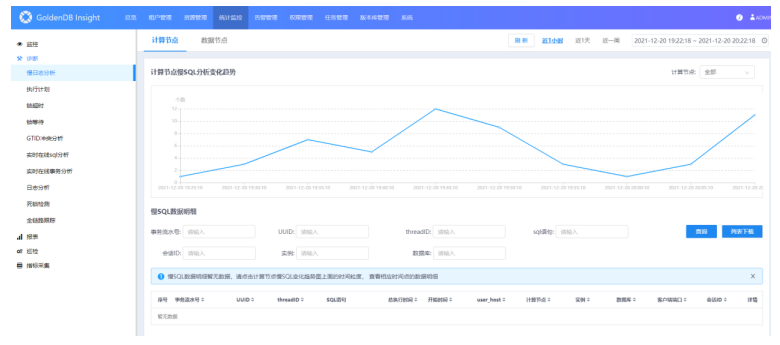
2.可选择右上角的时间范围,查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
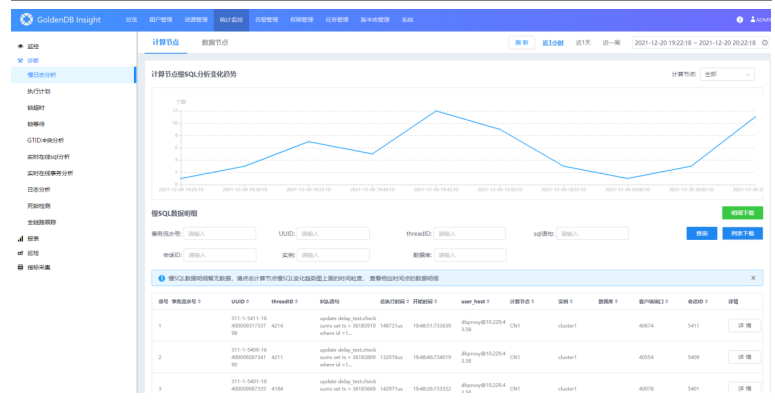
3.在计算节点页面,可执行相应操作。
| 参数 | 说明 |
|---|---|
查询相应慢SQL分析变化趋势 | 选择不同计算节点。 |
查看相应时刻的详细数据信息 | 鼠标悬停在图上,单击数据点可查看该时刻慢SQL数据明细。 |
下载明细 | 单击明细下载按钮。 |
4.慢SQL数据明细列表中,在待查看SQL语句行,单击详情按钮,进入详情界面,查看所选SQL语句及执行时间分解。
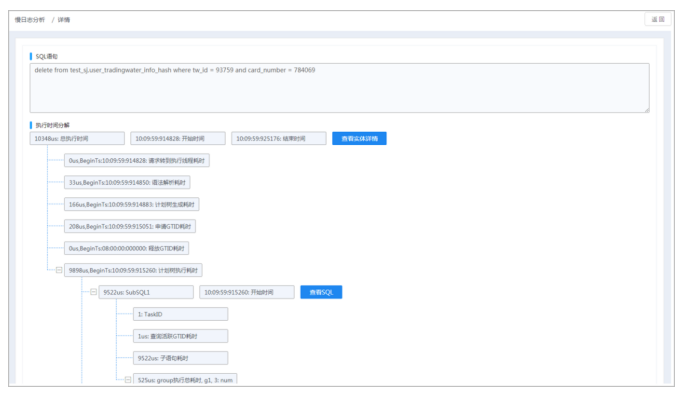
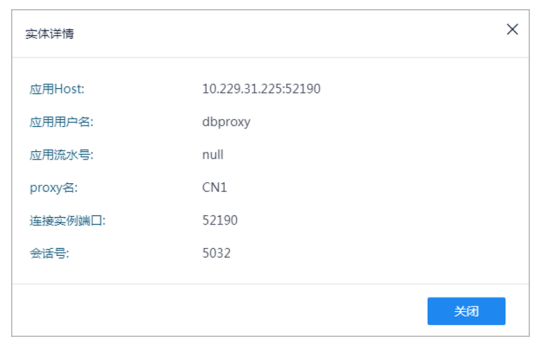
5.单击执行时间分解查看实体详情按钮,查看对应详情信息。
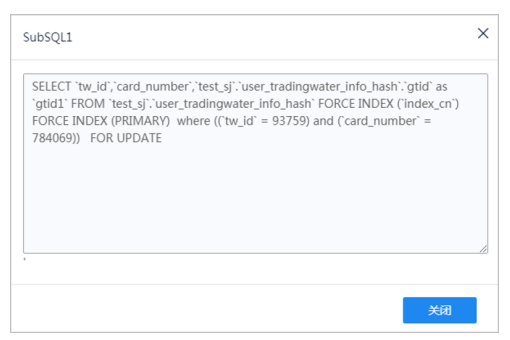
6.单击执行时间分解查看SQL按钮,查看对应详情信息。
7.当对应数据节点上有慢SQL记录时,单击执行时间分解查看DB慢SQL详情按钮,可查看对应详情信息,数据显示在下方慢SQL列表中。

8.切换到数据节点页签。
9.选择不同实例后可选择不同的分片查询相应慢SQL分析变化趋势。
说明
具体操作可参见计算节点相关查看步骤。
● 摘要
执行计划界面可查看不同实例下不同计算节点SQL语句的执行计划详情。
● 步骤
1.选择菜单[统计监控→诊断→执行计划],进入执行计划界面。
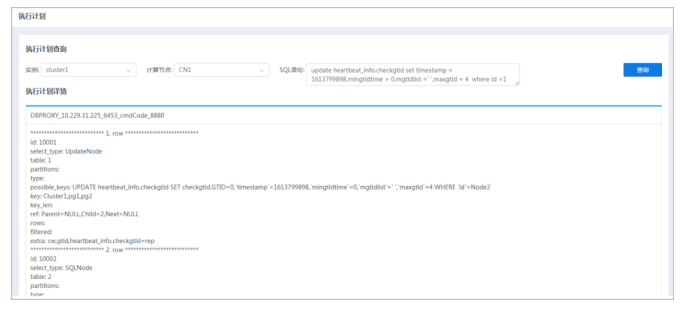
2.选择不同实例后可选择不同的计算节点,输入SQL语句,单击查询按钮,查询相应执行计划详情。
● 摘要
通过锁超时功能,查看DB锁超时次数排序结果。
注意,此项统计需要保证对应开关打开,可以手动进行配置,在对应计算节点的家目录下,在etc/proxy.ini中[SQLEXEC]段下添加配置“stat_conninstance_item=1”,动态生效(执行“dbtool -p -lc”)。
● 步骤
1.选择菜单[统计监控→诊断→锁超时],进入锁超时界面。
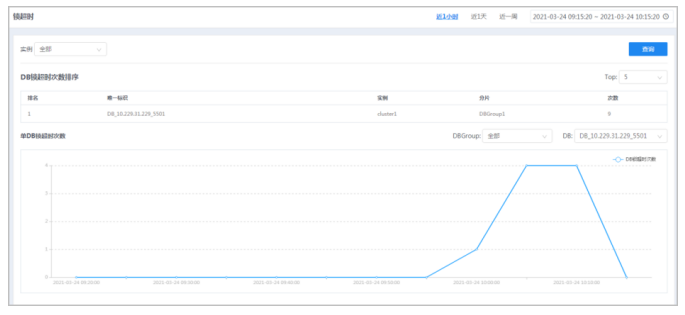
2.选择右上角的时间范围,查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
3.可以通过“TOP”下拉框选择前显示条数对DB锁超时次数排序,可选前5、10、20。
4.选择不同实例,可选择相应DBGroup及DB进行查询单DB锁超时次数。
5.鼠标悬停在图上,可查看相应时刻的详细数据信息。
● 摘要
通过锁等待功能,可查看不同实例下不同分片的锁等待统计数据。
注意,此项统计需要保证对应开关打开,可以手动进行配置,在对应管理节点的家目录下,在etc/clustermanager.ini中配置“check_deadlock_interval_time=5”,动态生效(执行“dbtool -cm -lc”)。还需要在所有主db家目录下的etc/my.cnf中配置“innodb_lock_wait_log = ON”、“innodb_lock_wait_timeout=200(值适当即可)”、“innodb_lock_wait_collect_time = 50”和“lock_wait_timeout=”,重启生效(执行“dbmoni -stop;dbmoni -start”)。
● 步骤
1.选择菜单[统计监控→诊断→锁等待],进入锁等待界面。
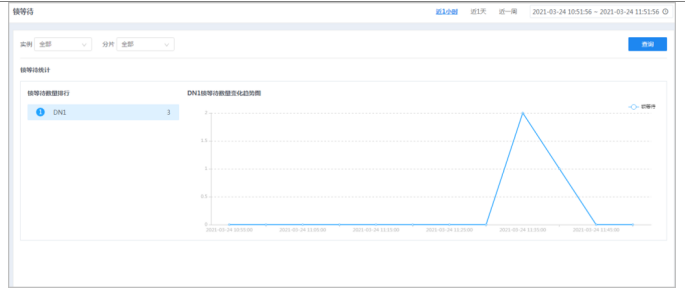
2.选择右上角的时间范围,查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
3.选择实例、相应分片,单击查询按钮,可查询对应锁等待统计数据。
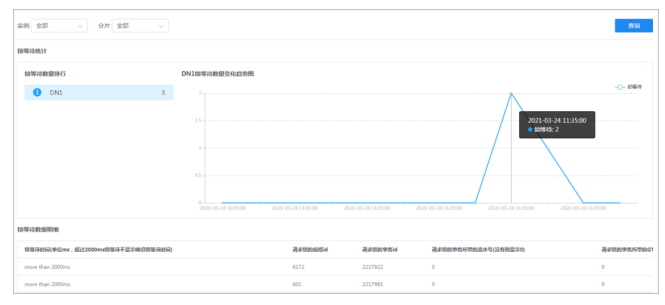
4.待机锁等待数量排行,可查看不同DN的锁等待数量变化趋势图。
5.鼠标悬停在图上,可查看相应时刻的详细数据信息。
单击数据点,可查看该时刻锁等待数据明细。
● 摘要
通过GTID冲突分析功能,可查看不同计算节点的GTID冲突数量。
注意,此项统计需要保证对应开关打开,可以手动进行配置,在对应GTM节点的家目录下,在etc/gtm.ini中配置“ReportSwitch=1”,动态生效(执行“dbtool -gtm -lc”)。还需要在计算节点家目录下的etc/proxy.ini中配置“gtid_conflict_stat_switch=”,动态生效(执行“dbtool -p -lc”)。
● 步骤
1.选择菜单[统计监控→诊断→GTID冲突分析],进入GTID冲突分析界面。
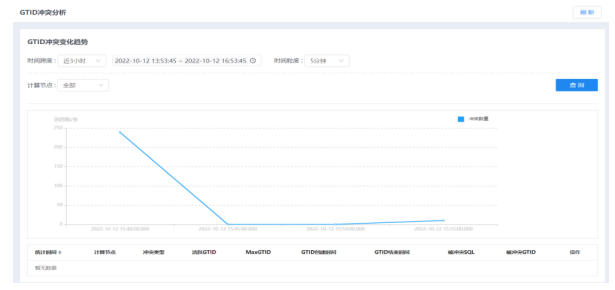
2.选择右上角的时间范围,查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
3.选择计算节点,单击搜索按钮,查询相应GTID冲突变化趋势。
4.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
单击图上某一数据节点,下方会出现该点的详细数据列表。
数据可根据统计时间进行排序。
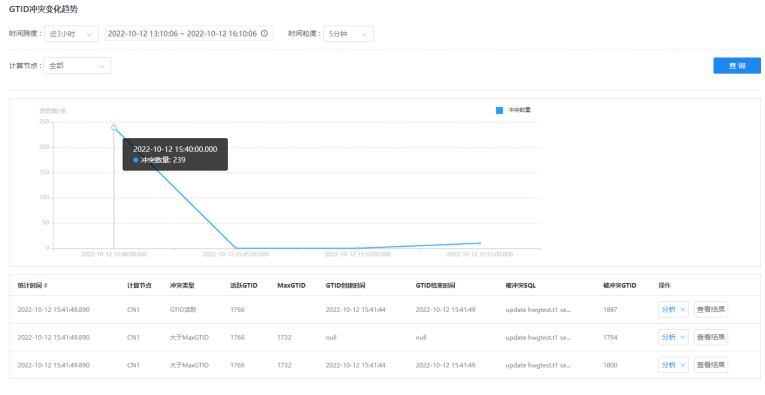
5.鼠标悬停在被冲突SQL上,可以查看发生GTID冲突时具体的被冲突SQL。
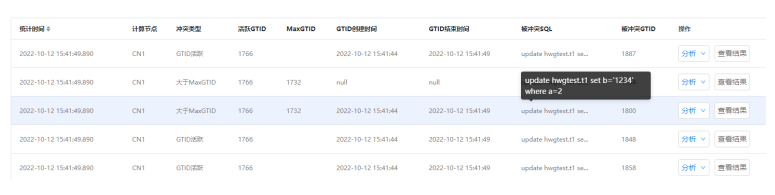
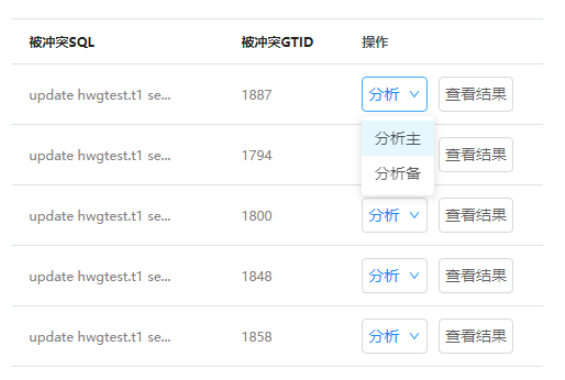
6.鼠标悬停在分析按钮上,可以选择分析主或者分析备,通过分析按钮,可以调用dbagent提供的脚本来获取阻塞SQL的信息。分析主是将分析SQL的工作交给各个分片的主节点来做,会略微影响主机性能;分析备是使用所有分片中的一个备机进行分析。选择之后需要一段时间分析才能查看结果,注意,不先进行分析无法直接查看结果。
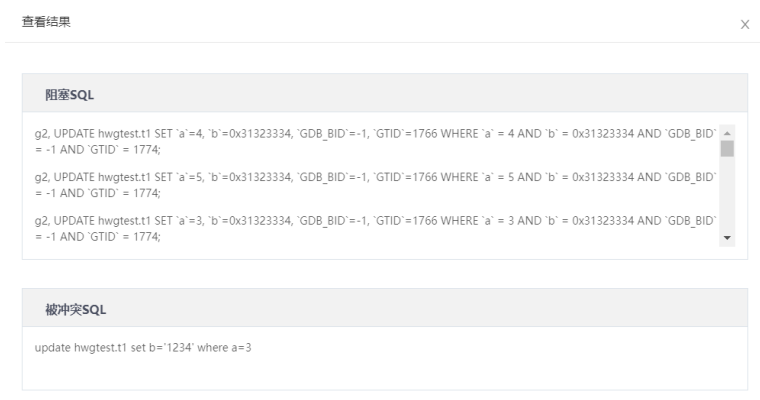
7.在分析完毕后点击查看结果可以查看具体阻塞SQL与被冲突SQL的信息,同时当阻塞SQL数据大于30条时也支持直接下载结果方便查看。
● 摘要
实时在线sql分析提供实时查询会话功能,用户可查询指定计算节点的会话信息,在此基础上,当发现异常会话时,提供kill指定事务功能。
需要先选择实例并选择相应计算节点,输入语句执行时长最小阈值进行查询。
● 步骤
1.选择菜单[统计监控→诊断→实时在线sql分析],进入实时在线sql分析界面。
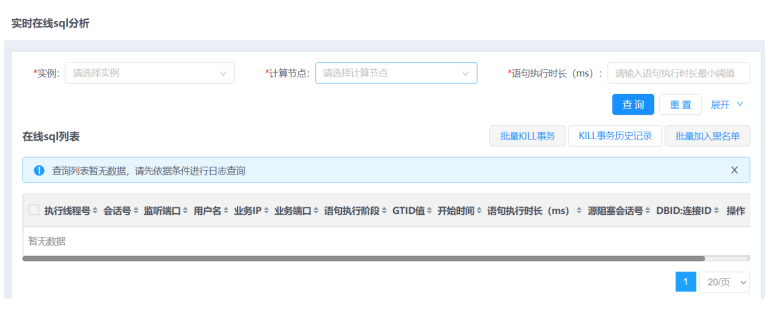
2.单击展开按钮,展开筛选条件(包括:会话号、监听端口、业务IP、业务端口、GTID、SQL语句,输入的内容满足各输入框的限制条件才可正常查询)。
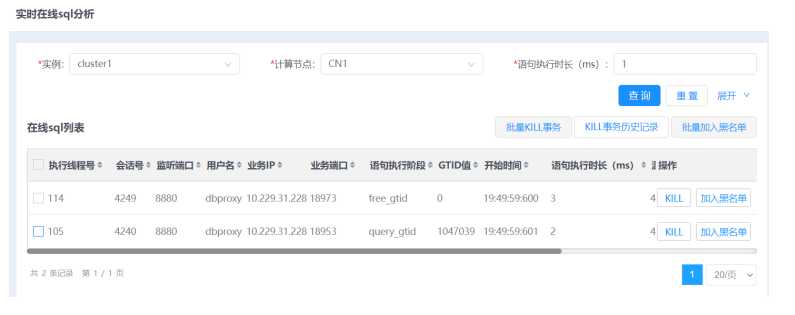
3.输入查询条件,单击查询按钮。
单击在线事务列表表头的三角按钮,可对各项数据进行排序。
4.(可选)当发现异常会话时,可执行如下操作kill指定事务。
1)单击操作列KILL按钮,弹出确认框。
2)在确认框中单击确定按钮。
5.对某条SQL语句可执行如下操作拉入黑名单。
1)单击操作列加入黑名单按钮,弹出确认框。
2)在确认框中单击确定按钮。
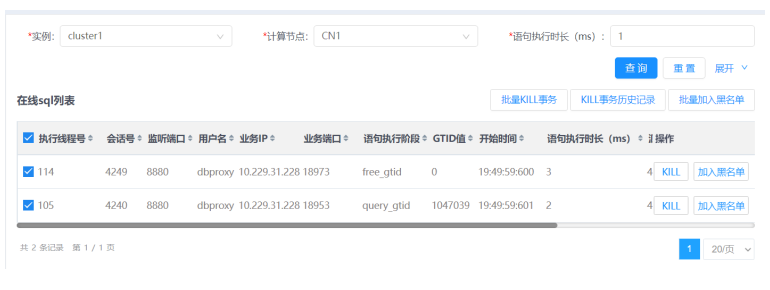
6.支持批量kill指定事务与批量加入黑名单的功能。勾选指定会话前的方框,点击批量KILL事务按钮或者批量加入黑名单,即可实现批量操作。
7.单击KILL事务历史记录按钮,进入KILL事务历史记录页面。
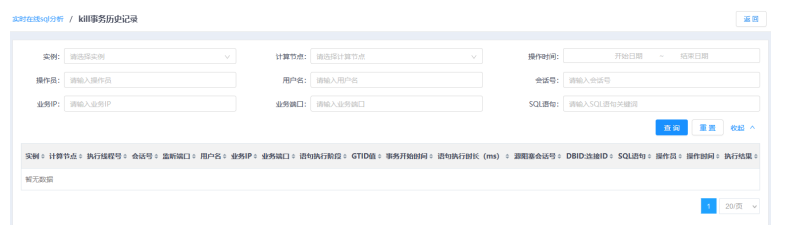
8.单击展开按钮,展开查询条件(包括:实例、计算节点、操作时间、操作员、用户名、会话号、业务IP、业务端口、SQL语句,输入的内容满足各输入框的限制条件才可正常查询)。
9.设置查条件,单击查询按钮,查看符合条件的记录。
单击表头的三角按钮,可对各项数据进行排序。
● 摘要
实时在线事务分析提供实时查询会话功能,用户可查询指定计算节点的会话信息,在此基础上,当发现异常会话时,提供kill指定事务功能。
需要先选择实例并选择相应计算节点,输入事务持续时长最小阈值进行查询。
● 步骤
1.选择菜单[统计监控→诊断→实时在线事务分析],进入实时在线事务分析界面。
2.单击展开按钮,展开筛选条件(包括:会话号、监听端口、业务IP、业务端口、GTID,输入的内容满足各输入框的限制条件才可正常查询)。
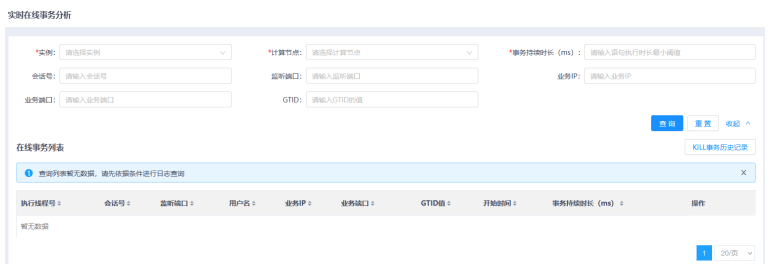
3.输入查询条件,单击查询按钮。
单击在线事务列表表头的三角按钮,可对各项数据进行排序。
4.(可选)当发现异常会话时,可执行如下操作kill指定事务。
1)单击操作列KILL按钮,弹出确认框。
2)在确认框中单击确定按钮。
5.单击KILL事务历史记录按钮,进入KILL事务历史记录页面。
6.单击展开按钮,展开查询条件(包括:实例、计算节点、操作时间、操作员、用户名、会话号、业务IP、业务端口、SQL语句,输入的内容满足各输入框的限制条件才可正常查询)。
7.设置查条件,单击查询按钮,查看符合条件的记录。
单击表头的三角按钮,可对各项数据进行排序。
● 摘要
查看不同组件的日志,可通过组件、日志级别、时间范围、UUID、关键词、发起方交易流水号进行日志查询。
● 步骤
1.选择菜单[统计监控→诊断→日志分析],进入日志分析界面。
2.单击选择组件,弹出选择组件窗口。
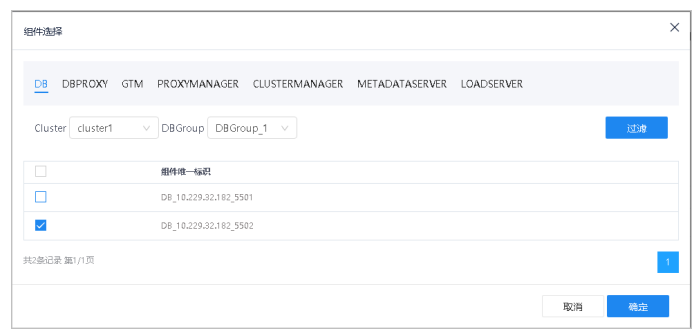
3.选择不同组件,单击确定按钮。
DB项可选择不同集群Cluster及相应分片DBGroup进行过滤。
4.日志级别为多选框,可选择ERROR、WARN、INFO、DEBUG。
5.时间范围可自定义选择时间,默认近1天。
6.单击关键词参考,弹出建议关键词窗口。
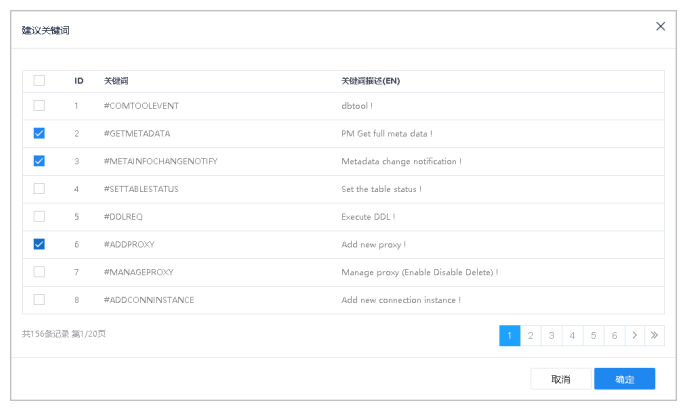
7.勾选关键词,单击确定按钮。
8.在日志分析界面,单击查询按钮,查询符合条件的日志。
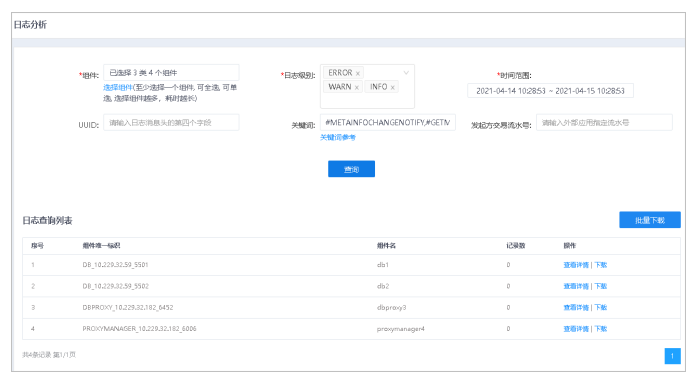
9.在待查看日志行,单击查询详情按钮,进入日志详情界面。
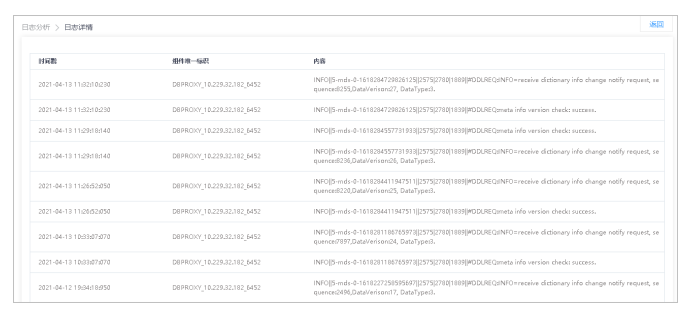
日志详情界面
10.单击返回按钮,可返回日志分析界面。
11.在日志分析界面,可根据需要单个下载或批量下载查询的日志。
| 参数 | 说明 |
|---|---|
下载单个日志 | 在待下载日志行,单击下载按钮。 |
下载全部日志 | 单击批量下载按钮。 |
DN死锁
● 摘要
当业务发生单点死锁时,在insight死锁监控界面可以看到死锁信息。
注意:需要在页面手动添加monitor采集任务,具体monitor任务采集操作可参考7.5采集指标,采集项选择monitor下的死锁日志。添加采集任务时对于每个集群只设置一个任务,采集任务重复会有重复数据产生。
死锁日志采集是在db表中采集,如需要采集死锁信息需要保证对应开关打开,可以手动进行配置,在对应db节点的家目录下,在etc/my.cnf中配置“innodb_deadlock_log_table=ON”和“innodb_deadlock_detect=ON”。还需要关注死锁日志表的清理参数innodb_deadlock_log_expire_seconds,默认31536000s,表示清理死锁日志表中31536000s之前出现的行锁死锁记录,配置为0表示不清理,均为动态生效。
● 步骤
1.选择菜单[统计监控→诊断→死锁检测→DN死锁],进入DN死锁检测界面。
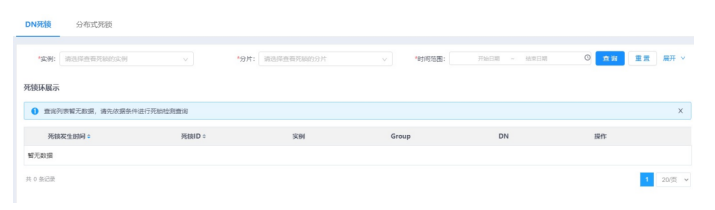
2.单机击展开按钮,展开查询条件(包括:实例、分片、时间范围、事务I、GTMGTID、SQL语句、DN线程ID、死锁ID)。
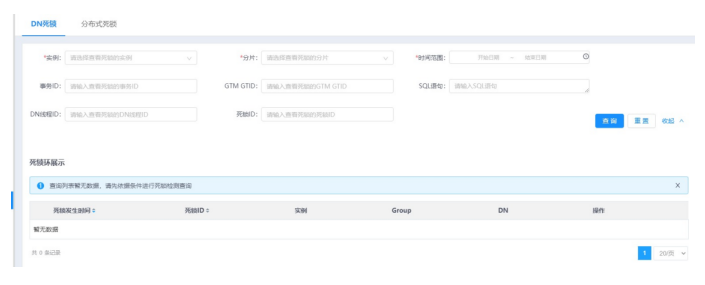
3.设置查询条件,单击查询按钮。
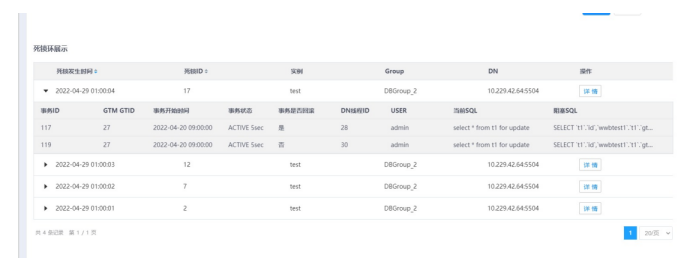
4.单击列表左侧三角按钮,可展开所选数据的死锁环信息。
5.单击死锁环展示表头的三角按钮(死锁发生时间、死锁ID),可对各项数据进行排序。
默认根据死锁发生时间倒序排序。
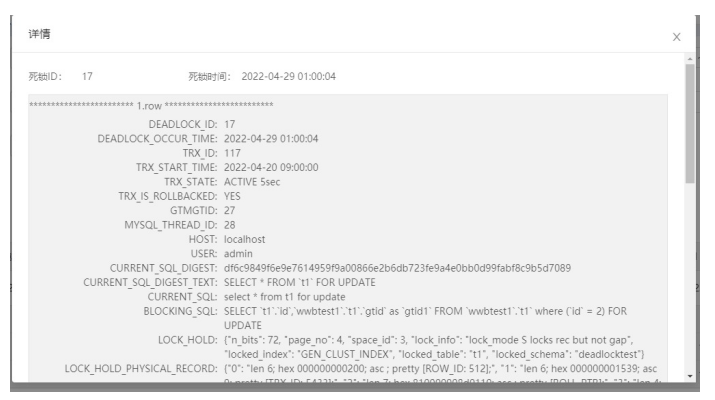
6.单击死锁环上的详情按钮。
分布式死锁
● 摘要
出现分布式死锁的时候,系统能够检测出全局分布式死锁。
● 步骤
1.选择菜单[统计监控→诊断→死锁检测→分布式死锁],进入分布式死锁检测界面。
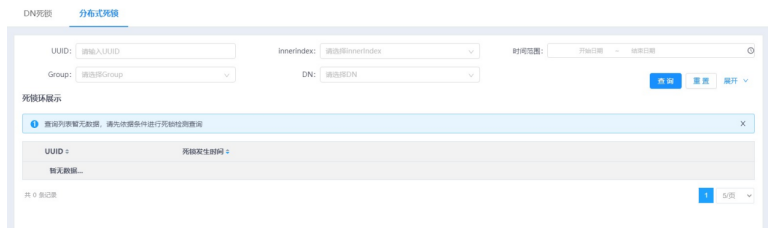
2.单击展开按钮,展开查询条件(包括:UUID、innerindex(死锁环顺序)、时间范围、Group、DN、阻塞表、等锁方gtid、持锁方gtid、等锁语句、持锁事务ID)。
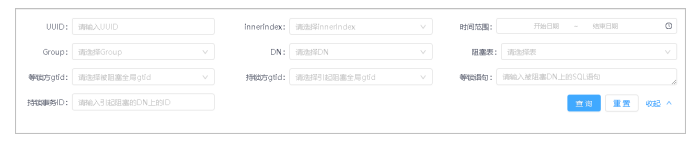
3.设置查询条件,单击查询按钮。
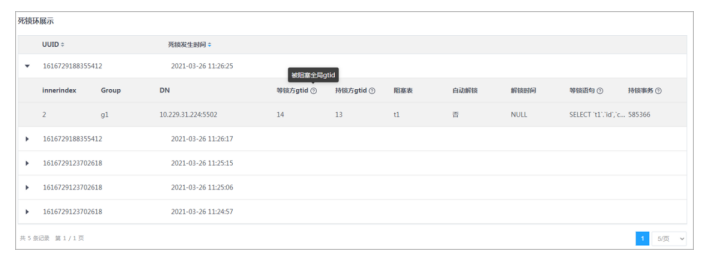
4.单击列表左侧三角按钮,可展开所选数据的详细信息。
5.鼠标移至?符号,可查看该项解释。
6.单击死锁环展示表头的三角按钮,可对各项数据进行排序。
默认根据死锁发生时间倒序排序。
● 摘要
追踪sql语句的从CN到DN执行情况。可以选择组件类型、cluster和事务流水号进行查询。
注意,此项统计需要保证对应开关打开,可以手动进行配置。单分片情况下,需要修改所有主db家目录下的etc/my.cnf和计算节点家目录下的etc/proxy.ini,在etc/my.cnf中可以配置“trx_query_log=1”和“trx_query_log_time=0”(方便统计),重启生效(执行“dbmoni -stop;dbmoni -start”)。在etc/proxy.ini中可以配置“trx_query_log=1”和“trx_query_log_time=0”(方便统计),动态生效(执行“dbtool -p -lc”),详细设置信息可见下面功能配置、日志格式说明内容。
多分片情况只修改所有计算节点家目录下的etc/proxy.ini即可,可以配置“trx_query_log=1”和“trx_query_log_time=0”(方便统计),详细设置信息可见下面功能配置、日志格式说明内容,动态生效(执行“dbtool -p -lc”)。
● 步骤
1.选择菜单[统计监控→诊断→全链路跟踪],进入全链路跟踪界面。
2.单击展开按钮,展开筛选条件(包括:原始SQL、事务开始时间、事务结束时间,输入的内容满足各输入框的限制条件才可正常查询)。点击查询按钮可以得到查询结果,点击CN性能使用情况可以跳转至租户管理/节点/性能页面。
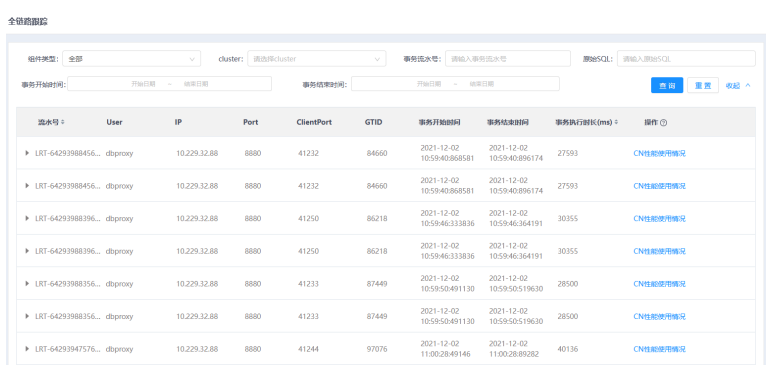
3.点击查询结果行首的三角按钮,展开查询结果详情。可以看到这次sql执行的全链路跟踪分析结果(SQL顺序、执行时间、SQL语句等相关信息)。
4.点击展开后查询结果下的三角按钮,可以看到更加详细的GroupID、DNID、子SQL顺序等内容。
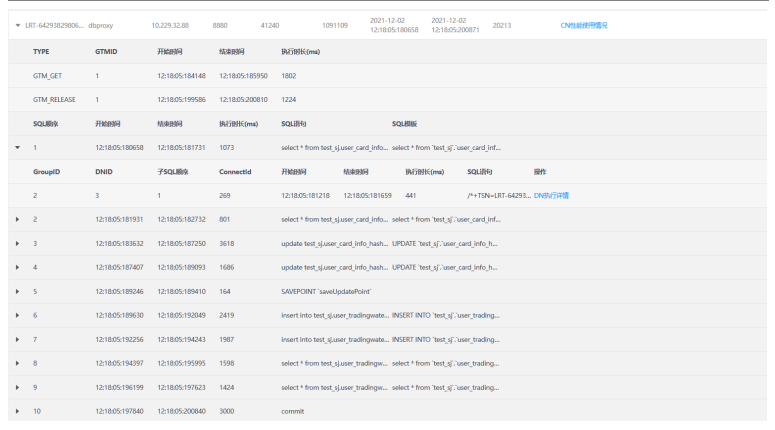
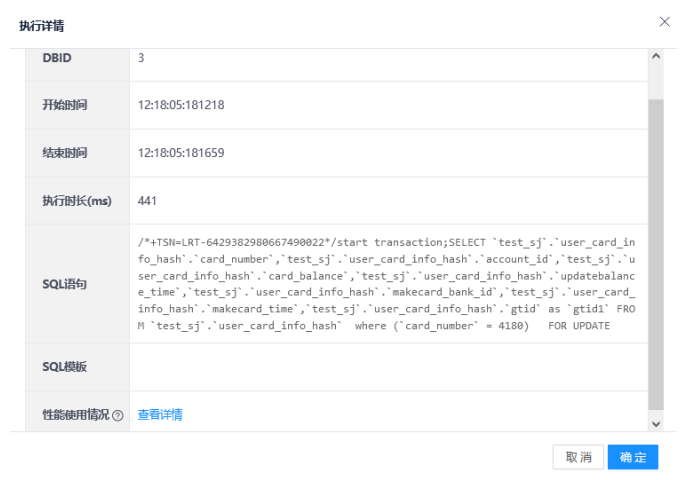
5.点击DN执行详情,展示DBID、执行时长、SQL语句等信息。
● 相关信息业务设置事务流水号
1)语法:set @transaction_serial_number = 流水号;
例如:
begin;
set @transaction_serial_number="...";
select ...
select ...
insert ...
commit;
2)说明:事务流水号一般是在事务中(比如start transaction之后,第一条语句之前)进行设置,主要目的用于跟踪从业务至数据库层的整个事务过程。业务可以根据实际需要在一个事务中设置多个事务流水号。
● 功能配置、日志格式说明
1.CN介绍
(1)配置说明:
CN的etc/proxy.ini中与该功能相关的配置项说明如下:
事务统计日志开关:trx_query_log,配置为1表示开启统计。
事务统计时间阀值:trx_query_log_time,事务执行时间大于该配置值时才会进行输出,单位ms。
事务统计日志输出路径:trx_query_log_file,此项暂不支持修改,所有日志均输出到~/log目录下,日志名:trx_query.log
事务统计日志级别:trx_query_log_level,配置为0表示输出所有事务及包含在该事务内的所有sql语句信息,配置为1表示只输出带有事务流水号的事务及包含在该事务内的所有sql语句信息,配置为2表示输出所有事务信息,不包含sql,配置为3表示只输出带有事务流水号的事务信息,不包含sql。
事务统计日志大小(最小值):trx_query_log_size,单位m,支持范围100-1024,用于控制日志切换,切换规则:在每次处理并输出日志之前(30s一个周期),如果当前日志大小大于该配置值,该日志便会切换并归档,本次的统计信息均输出至最新的日志文件中。
以上配置项除trx_query_log_file外,都支持动态生效(执行“dbtool -p -lc”)。
(2)日志格式说明:
CN处输出的日志样例如下:
以事务为单位进行统计输出,统计信息包括:客户端信息(ip,port),事务流水号,事务开始及结束时间,事务内各sql语句信息,以及每个sql语句对应的下到每个分片上的子sql语句信息等。
(3)其他说明
CN的日志是由单独线程周期性的输出,周期为30s,也就是每30s触发一次,输出在该30s内满足输出条件的事务统计信息。
CN在进行统计的时候,目前只针对开启事务的情况进行统计,也就是CN内部自行补发start transaction/begin或者业务手动start transaction/begin/set autocommit=0的情况,CN才会进行统计,其余情况暂不统计。
3.DN介绍
DN配置项
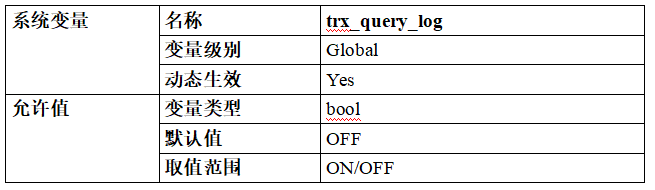
(1)trxquery_log
| 名称 | trx_query_log |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | bool |
默认值 | OFF |
取值范围 | ON/OFF |
说明:设置是否启用事务级日志,默认关闭。
(2)trx_query_log_file
| 名称 | trx_query_log_file |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | char * |
默认值 | $HOME/log/trx_query.log |
取值范围 | - |
说明:值为空时,在trx_query_log设置为on后,会默认使用localhost-trx.log。值配置为错误路径时,即使my.cnf配置文件trx_query_log配置为on,在mysql启动后trx_query_log仍会是off,在trx_query_log设置为on时,会有出错信息告警。
(3)trx_query_log_level
| 名称 | trx_query_log_level |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | uint |
默认值 | 1 |
取值范围 | 0-3 |
说明:0:打印所有事务及其sql语句,1:只打印有事务流水号的事务及其sql语句,2:只打印所有事务,不打印sql语句,3:只打印有事务流水号的事务,不打印sql语句。
(4)trx_query_log_time
| 名称 | trx_query_log_time |
|---|---|
变量级别 | Global/Session |
动态生效 | Yes |
变量类型 | double |
默认值 | 10 |
取值范围 | 0-31536000 |
说明:事务级日志的时间阈值,单位s。
(5)trx_query_log_effective_period
| 名称 | trx_query_log_effective_period |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | char * |
默认值 | 00:00:00~00:00:00 |
取值范围 | 符合格式要求的字符串 |
说明:配置为00:00:00~00:00:00格式的字符串,事务的开始和结束时间都在该时间范围内才记录事务级日志。此配置项会影响事务级日志是否记录的判断,配置项中如果结束时间比开始时间大,则认为是一天中的时间段,如果结束时间比起始时间小,则认为跨天的情况,如果起始时间和结束时间一样表示全天。
(6)max_trxlog_size
| 名称 | max_trxlog_size |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | ulong |
默认值 | 104857600 |
取值范围 | 4096-18446744073709551615(64 bit平台)。4096-4294967295(32 bit平台) |
说明:事务级日志文件的切换阈值,调整的最小步长:4096。
(7)trxlog_expire_logs_seconds
| 名称 | trxlog_expire_logs_seconds |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | ulong |
默认值 | 604800 |
取值范围 | 0-4294967295 |
说明:事务级日志过期的时间阈值。
(8)trx_log_cache_size
| 名称 | trx_log_cache_size |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | uint |
默认值 | 16384 |
取值范围 | 16384-10485760 |
说明:单个会话可以保留事务级日志缓存的大小阈值,调整的最小步长:1024。超过缓存限制大小将不记录后续的SQL信息,并将没有记录的结果写入到事务级日志中。
(9)trx_log_cache_total_size
| 名称 | trx_log_cache_total_size |
|---|---|
变量级别 | Global |
动态生效 | Yes |
变量类型 | ulonglong |
默认值 | 16777216 |
取值范围 | 16777216-107374182400 |
说明:可以保留事务级日志缓存的总大小阈值,调整的最小步长:1024。超过缓存限制大小将不记录事务级日志并在错误日志中发出告警。
DN配置项修改后重启生效(执行“dbmoni -stop;dbmoni -start”)。
DB日志格式说明
为了更好的控制事务日志的打印,我们通过trx_query_log_level配置来控制日志的打印详细程度。不同 trx_query_log_level下的日志格式:
(1)trx_query_log_level = 0
打印所有事务的全量信息,其中$trx_query_log为每个事务的日志,在不同trx_query_log_level下有所区别,全量信息格式示例如下:
User@Host: root[root]@ localhost[]|Port:8888|ID: 1234|Module:DB|TSN: ABCDEFG1234567|Trx_begin_time: 2021-07-21T10:16:58.625101|Trx_end_time: 2021-07-21T10:17:58.625101|Trx_time: 60.000000
SQLIndex: 1|ExecTime: 0.000412|BeginTime: 15:50:14.913434|EndTime:15:50:14.913846|PatternSql: select * ?|ExecSql: begin ;
SQLIndex:2|ExecTime: 2.748005|BeginTime: 15:50:14.941537|EndTime:15:50:17.689542|PatternSql: select * ?|ExecSql: select * from yxx.t1 for update;
SQLIndex: 3|ExecTime: 0.713094|BeginTime: 15:50:17.986452|EndTime: 15:50:18.699546|PatternSql: select * ?|ExecSql: select * from yxx.t1 for update;
SQLIndex: 4|ExecTime: 0.494901|BeginTime: 15:50:18.765234|EndTime: 15:50:19.260135|PatternSql: select * ?|ExecSql: commit;
(2)trx_query_log_level = 1
只会打印带有事务流水号的事务全量信息。
(3)trx_query_log_level = 2
打印所有事务的事务信息,不打印sql信息。例如:
User@Host: root[root]@ localhost[]|Port:8888|ID: 1234|Module:DB|TSN: ABCDEFG1234567|Trx_begin_time: 2021-07-21T10:16:58.625101|Trx_end_time: 2021-07-21T10:17:58.625101|Trx_time: 60.000000
(4)trx_query_log_level = 3
只打印带有事务流水号(TSN)事务的事务信息,不打印sql信息。
注:格式为key: value,冒号后带一个空格,sql内容作为行记录中最后一个值输出。后续新增内容加在sql前。
● 摘要
查看不同实例下不同计算节点的SQL统计数据。
● 步骤
1.选择菜单[统计监控→报表→SQL统计报表],进入SQL统计报表界面。
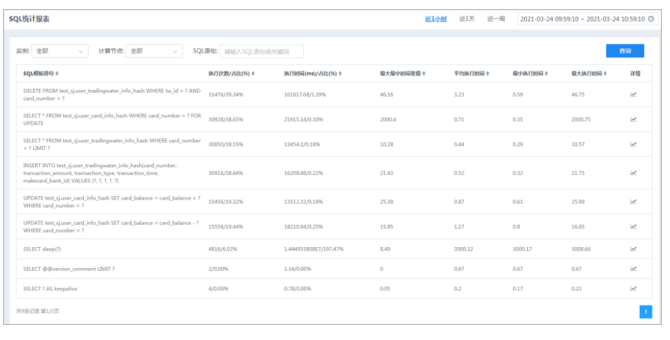
2.选择右上角的时间范围,查询到不同时间范围内的数据。
可手动自定义选择一段时间,也可快速选择近1小时/天/周,默认选择近1小时。
3.选择实例、相应计算节点,单击查询按钮,查询SQL统计。
SQL语句支持模糊查询。
4.单击表头的三角按钮,可对各项数据进行排序。
5.单击列表中右侧按钮,可查看所选SQL语句执行统计趋势图。
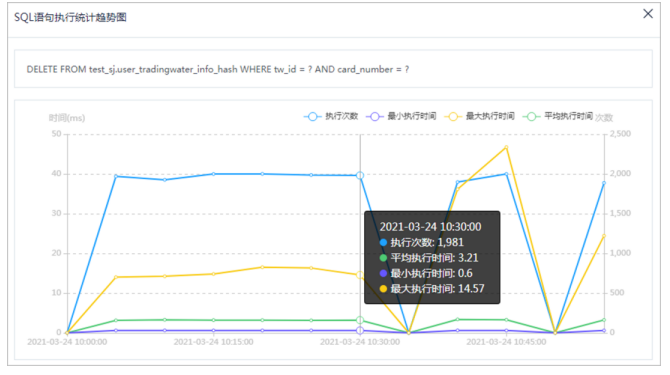
6.鼠标悬停在图上的数据点,可查看该点的详细数据信息。
7.单击右上角筛选指标,查看对应折线图数据。
● 摘要
新增巡检任务,包括定时巡检任务和实时巡检任务;查看巡检任务执行结果。
说明
巡检任务对性能有一定影响,建议在业务闲时执行。
● 步骤
1.选择菜单[统计监控→巡检→任务管理],进入任务管理界面。
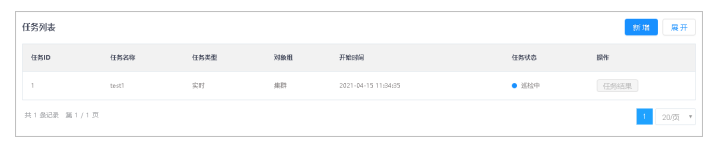
2.单击新增按钮,弹出新增巡检任务窗口,可以选择不同的对象组新增对应的巡检任务。
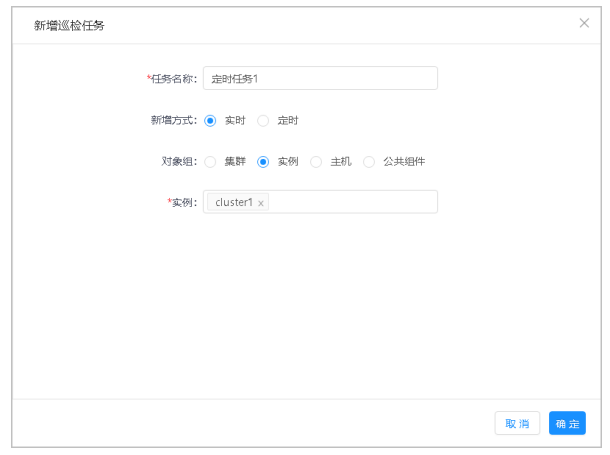
3.设置巡检任务参数,单击确定按钮。
新增方式包括:定时、实时。
对象组可选集群、实例、主机、公共组件,新增不同对象的巡检任务。
4.任务完成,单击任务结果按钮,进入任务结果界面。
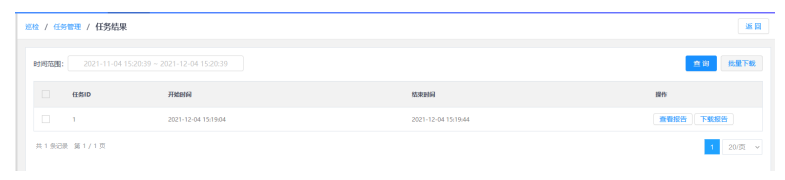
5.设置时间范围,单击查询按钮,查询指定时间范围内的任务结果。
6.点击查看报告按钮,可以在线查看报告的相关分析。
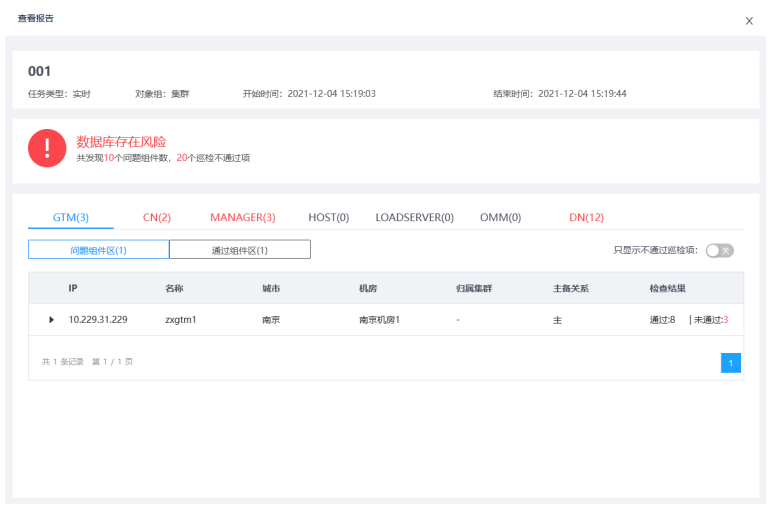
7.单击下载报告按钮,可将巡检结果下载到本地。
可选择多个任务报告,单击批量下载按钮,下载所选任务报告。
8.在任务管理界面,单击展开按钮,可展开查询条件(包括:任务类型、任务状态、时间范围。其中,任务类型包括实时和定时,当任务类型选择实时,任务状态可选成功、失败、巡检中;当任务类型选择定时,任务状态可选生效和失效)。
9.设置查询条件,单击查询按钮,可查找指定条件的任务。
● 摘要
查看各个模块巡检项和对应的阈值参数。
● 步骤
1.选择菜单[统计监控→巡检→巡检项管理],进入巡检项管理界面。
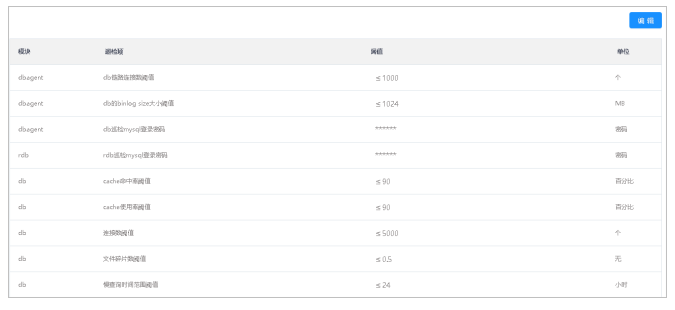
2.单击编辑按钮,各个模块巡检项的阈值参数进入编辑模式。
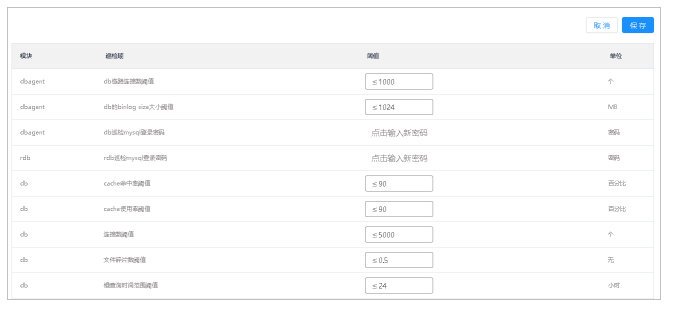
3.修改参数,单击保存按钮。
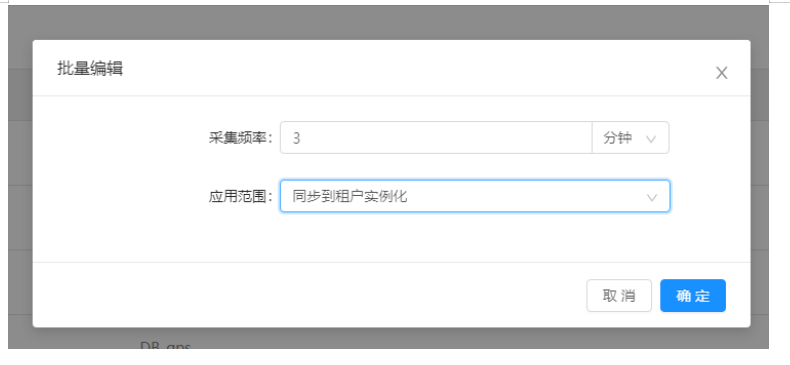
1)打开“统计监控—>通用采集—>公共采集配置”界面:
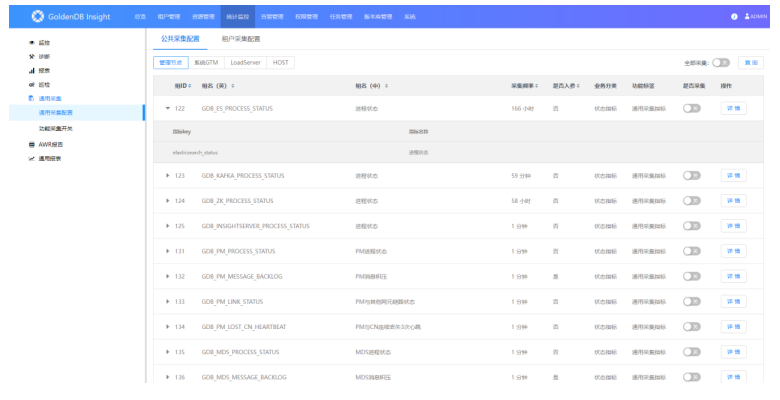
该页面展示的管理节点,系统GTM,loadServer,和HOST下的各个指标信息,同时可对指标的采集进行开关和配置采集频率。
2)采集指标查询
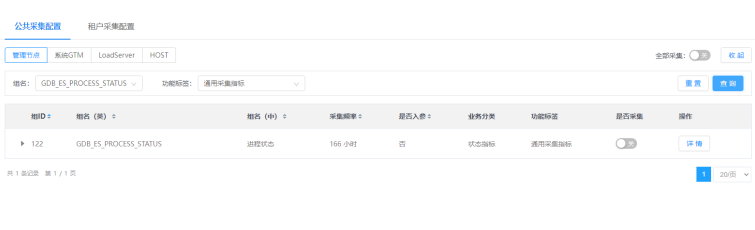
点击查询按钮,可以根据组名和功能标签对列表进行过滤查询。
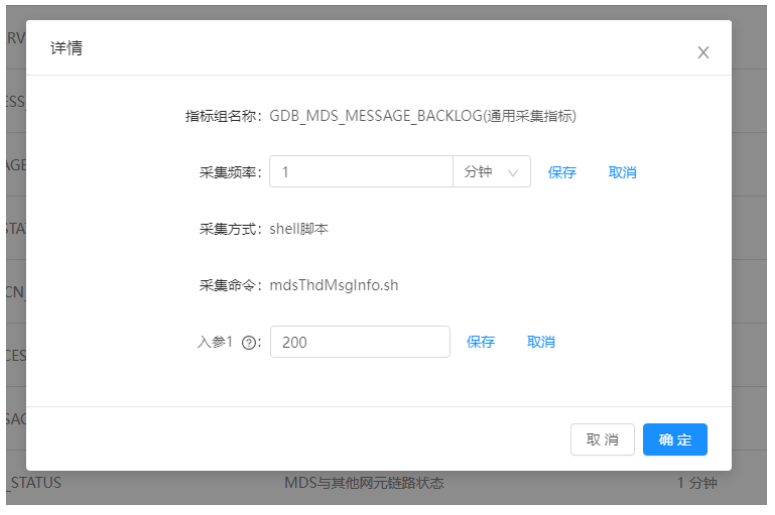
3)采集指标详情
4)打开“统计监控—>通用采集—>租户采集配置”界面:
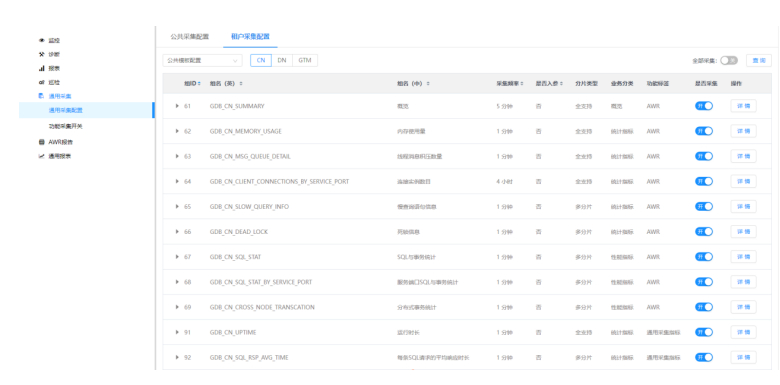
该页面展示的公共采集模板和每个租户下的各个指标信息,同时可对指标的采集进行开关和配置采集频率。
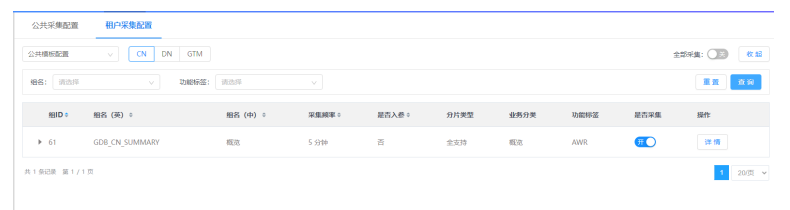
5) 租户采集配置的查询功能
6)租户采集配置的采集频率可以修改
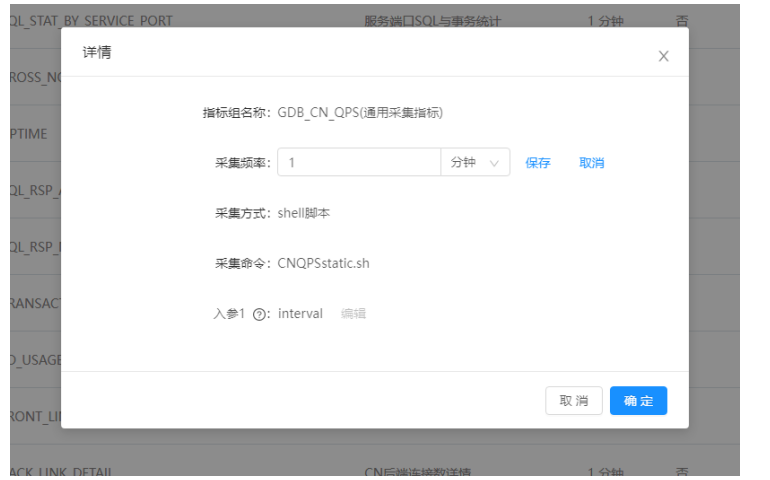
1)打开“统计监控—>通用采集—>功能采集开关”界面:
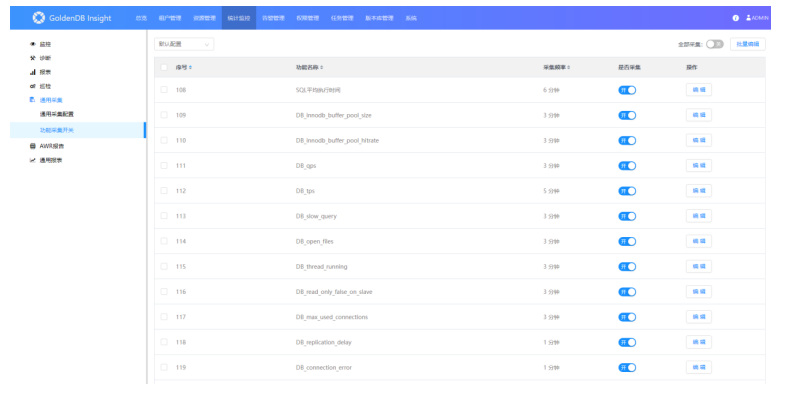
2)编辑
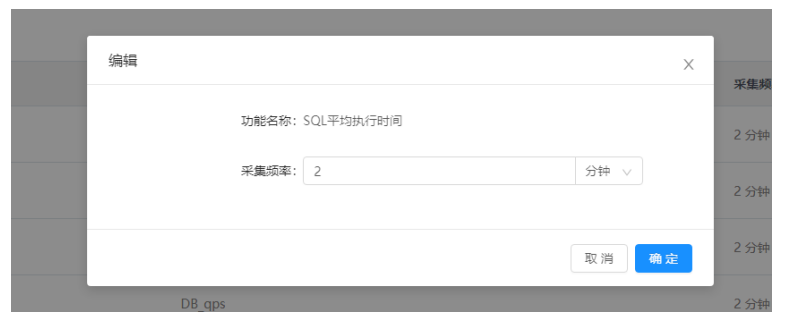
3)批量编辑
1)打开“统计监控—>AWR报告”界面:
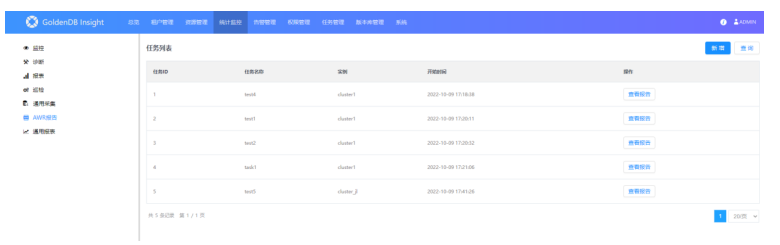
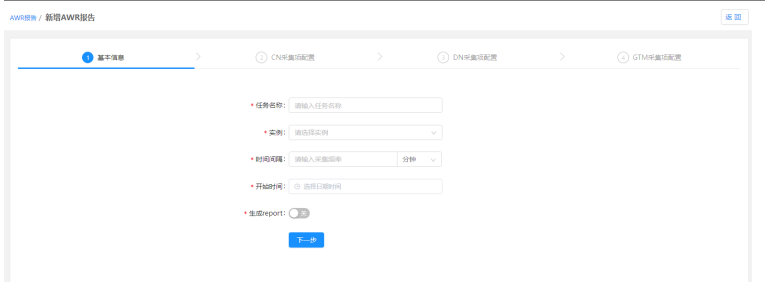
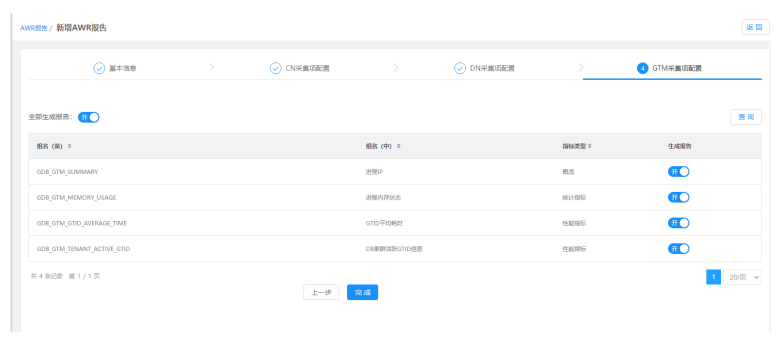
2)AWR报告新增
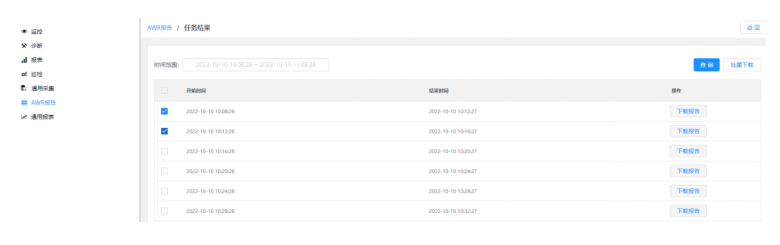
3)点击查看报告:AWR报告单个或者批量下载
1)打开“统计监控—>通用报表”界面:
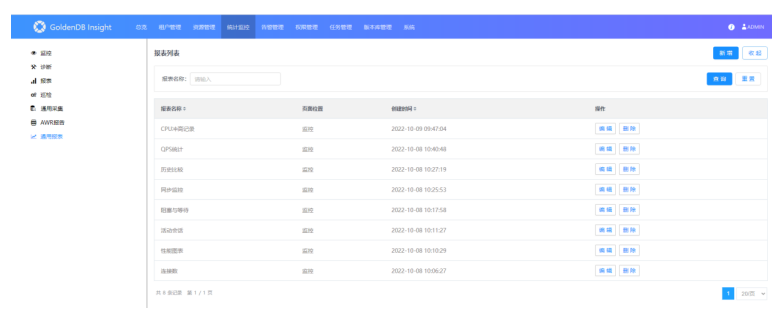
此页面可以管理报表列表,可以新增、筛选查询、编辑、删除,其中有一些内置报表不允许编辑、删除
2)新增:
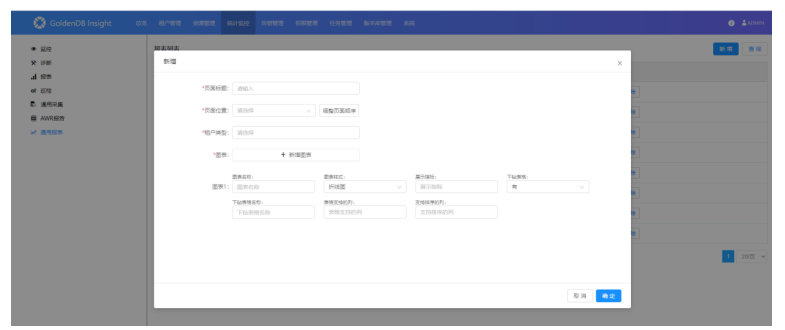
此页面可以新增报表,在页面标题和页面位置都有值后,可以点击调整页面顺序去更改报表菜单顺序。最多支持三个图标,可以根据实际需求自定义选择不同的图标样式等。
1)打开某一个新建的报表界面:
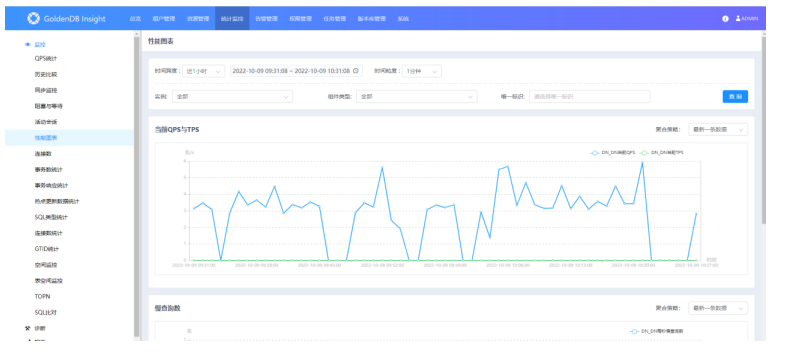
此页面可以根据创建报表的配置相应的展示出来。顶部有时间等条件过滤数据,每个图表根据不同的图标样式有相应的操作框。
