

Question 1

为什么大模型开“卷”长文本能力?

Question 2
谁使用如此多的单点长文本输入?
Question 3
大模型如何获得更多单点长文本输入?
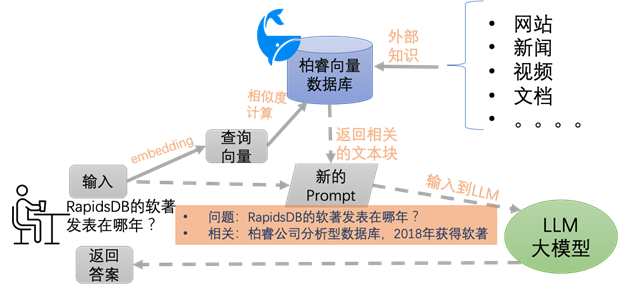
Question 4
为什么选择柏睿向量数据库?

推荐阅读



文章转载自柏睿数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





Question 1
为什么大模型开“卷”长文本能力?
Question 2
谁使用如此多的单点长文本输入?
Question 3
大模型如何获得更多单点长文本输入?
Question 4
为什么选择柏睿向量数据库?
推荐阅读
