




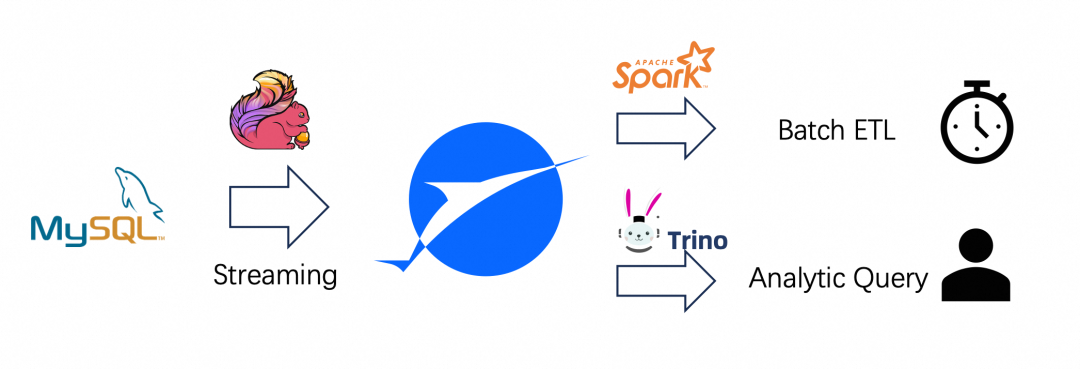
技术背景
业务用例
CREATE TABLE orders (order_id BIGINT,order_name STRING,order_user_id BIGINT,order_shop_id BIGINT,order_product_id BIGINT,order_fee DECIMAL(20, 2),order_create_time TIMESTAMP(3),order_update_time TIMESTAMP(3),order_state INT,PRIMARY KEY (order_id) NOT ENFORCED)
Paimon 主键表
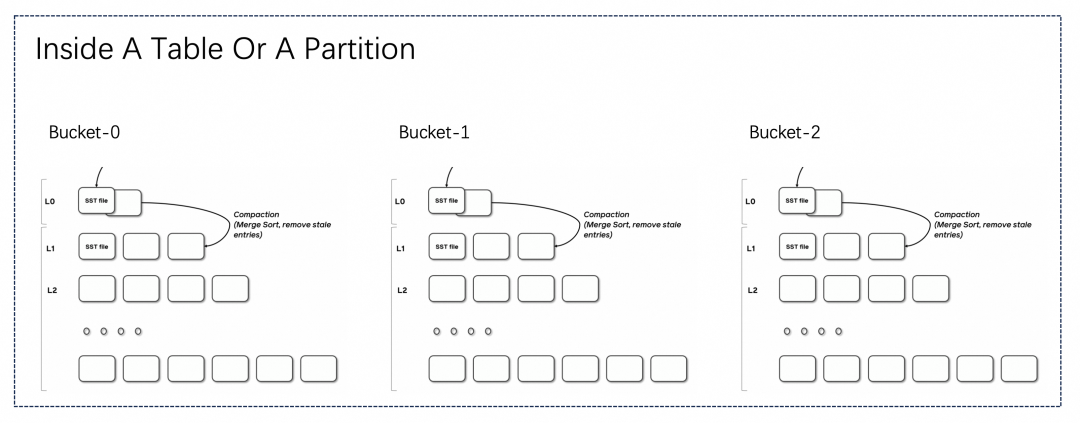
MOR (Merge On Read): 合并数据默认是半异步的 (当 L0 文件太多会反压写),你也可以设置成完全异步 (不反压写)。 COW (Copy On Write):合并数据也可以设置为同步,也就是在写入时完成合并。
Merge-On-Read
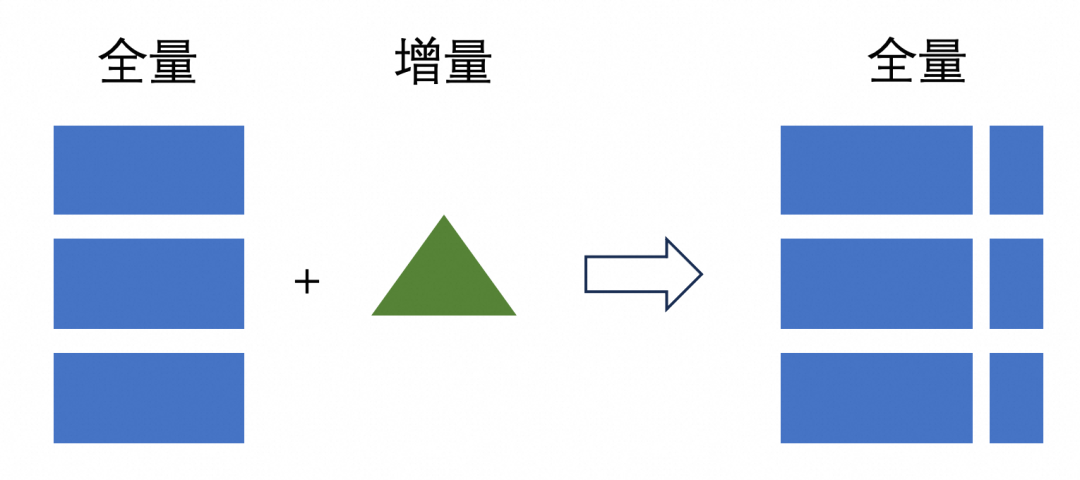
单 LSM 单线程,并发受限。 非主键的列不能做过滤下推。 多路归并需要一定性能消耗。
写入:100分,非常好 读取:10分,较差
Copy-On-Write
ALTER TABLE orders SET('full-compaction.delta-commits' = '1');
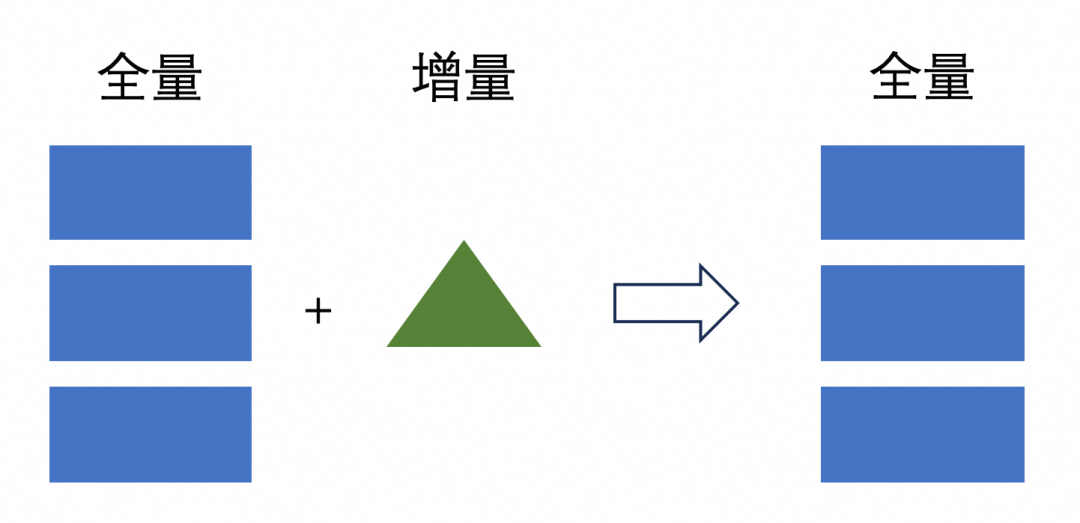
写入:10分,非常差 读取:100分,非常好
Deletion Vectors
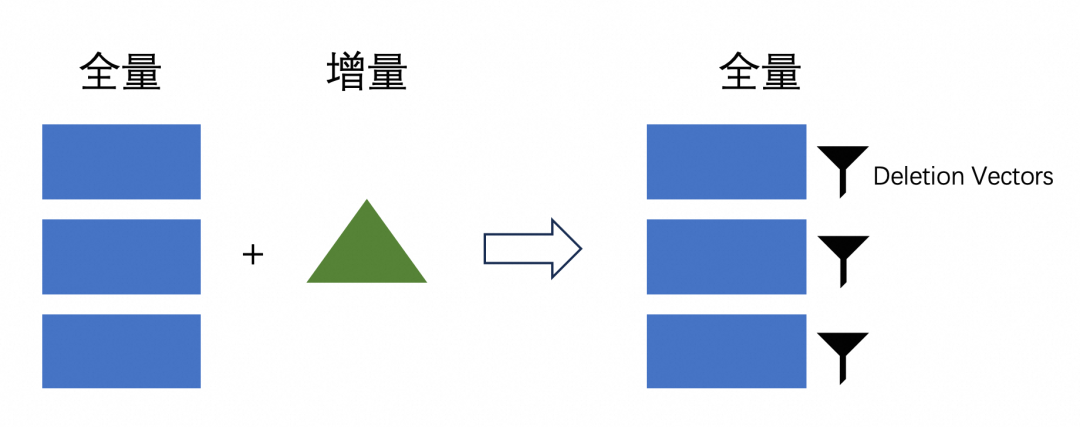
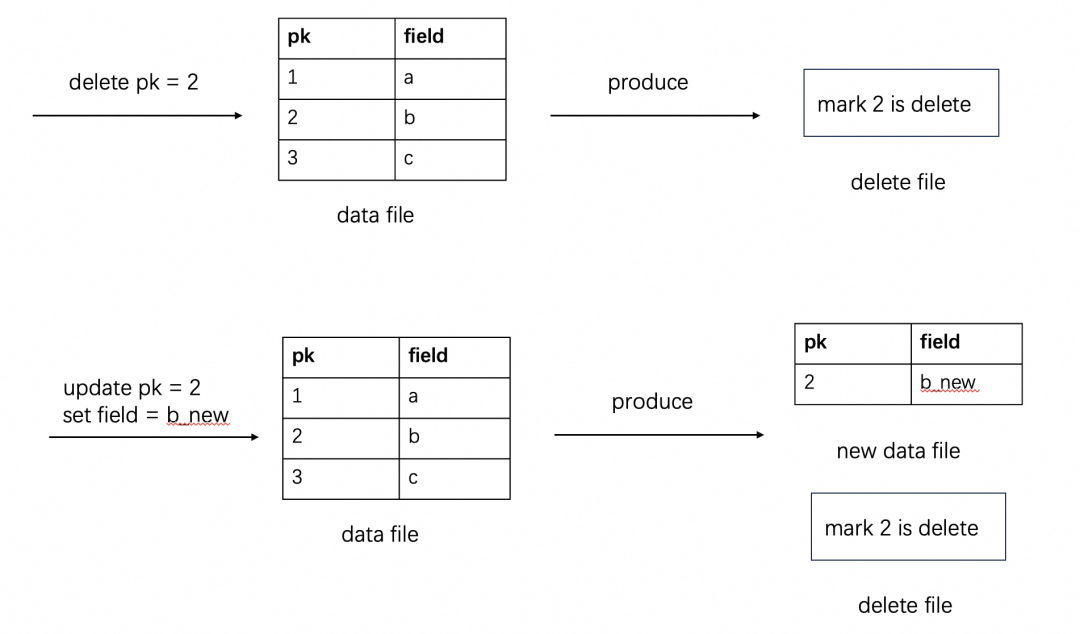
读取性能好:并发随意、可过滤下推、不需要合并,只是多了 Deletion Vectors 的过滤,代价小。 写入性能中:写入时,需要去查询并标记对应同主键的数据,修改历史文件的 Deletion Vectors。
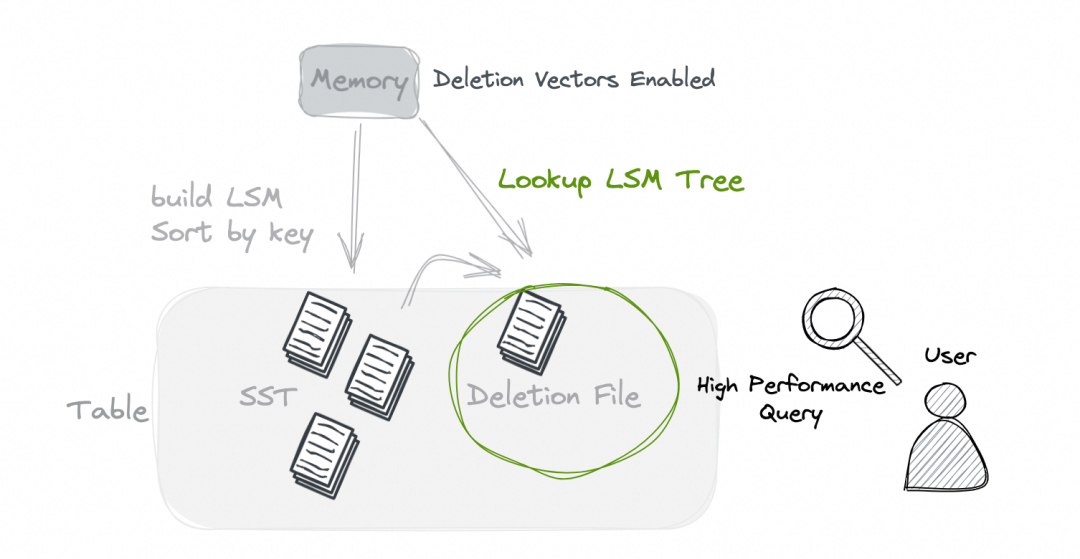
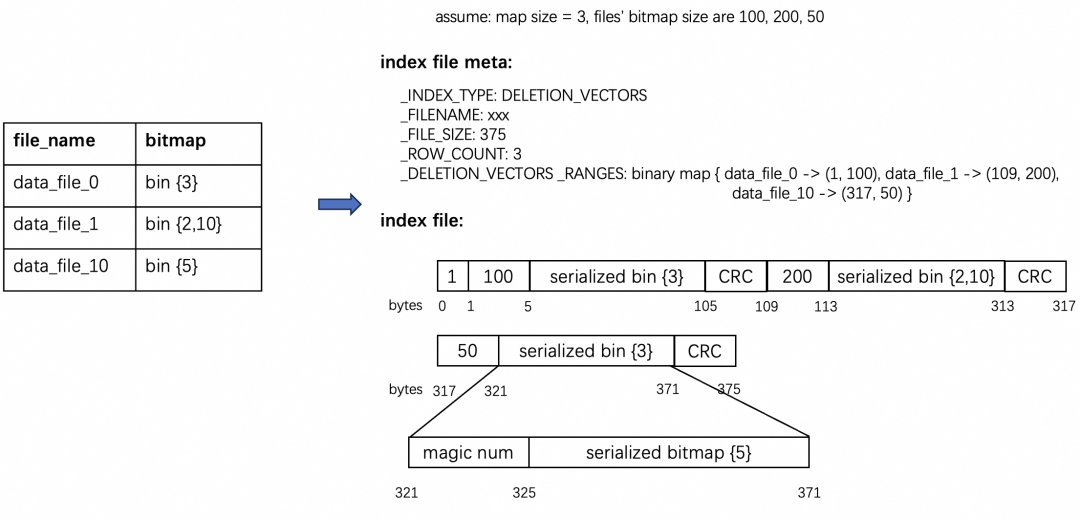
RoaringBitmap 是一种压缩的位图,可以大幅减少存储空间。 RoaringBitmap 有多语言支持,C++ 引擎也可以方便的读取它。
写入:60分,还可以 读取:90分,非常好
性能测试
测试环境
集群 EMR 5.16.0:工作节点: 4台,24 CPU,96 GiB Flink 1.15 & Spark 3.3.1 Trino 422:最新 Paimon-Trino 版本已经特殊优化过 ORC 的读取 Paimon 0.8:deletion-vectors.enabled 此配置可以开启 Deletion Vectors (简称 DV) 模式,默认关闭
数据规模
写入性能
不开启 DV:455 秒,单并发每秒写入 13 万条 开启 DV: 937 秒,单并发每秒写入 6.6 万条
查询性能
总结
关注 Apache Paimon 微信公众号,了解更多咨询。 点赞项目:https://github.com/apache/incubator-paimon/ 加入钉钉 Paimon 用户交流群。
文章转载自锋哥聊DORIS数仓,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
