前言:
logminer是Oracle 8i以后提供的一个日志分析工具,可以对在线日志,归档日志进行分析,该分析工具在安装Oracle时一般默认包含,由一组PL/SQL包和一些动态视图组成。
本文主要介绍通过使用logmine对日志的分析,获得用户操作的反向操作(undo_sql)或者正向操作(redo_sql)用来修复用户数据的丢失或者是错误。
正文:
实现条件
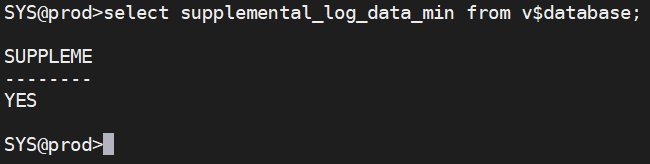
操作日志挖掘需要打开辅助日志功能(SUPPLEMENTAL_LOG_DATA_MIN),默认是关闭的,数据库启用了Supplemental Logging之后,对于修改操作,oracle就会同时附加一些能够唯一标识修改记录的列到redolog中。主要目的是为了使logminer具备识别由update命令导致的行迁移、行移动的能力。
查看方法:
select supplemental_log_data_min from v$database;
开启附加日志方法:
alter database add supplemental log data;
构建环境
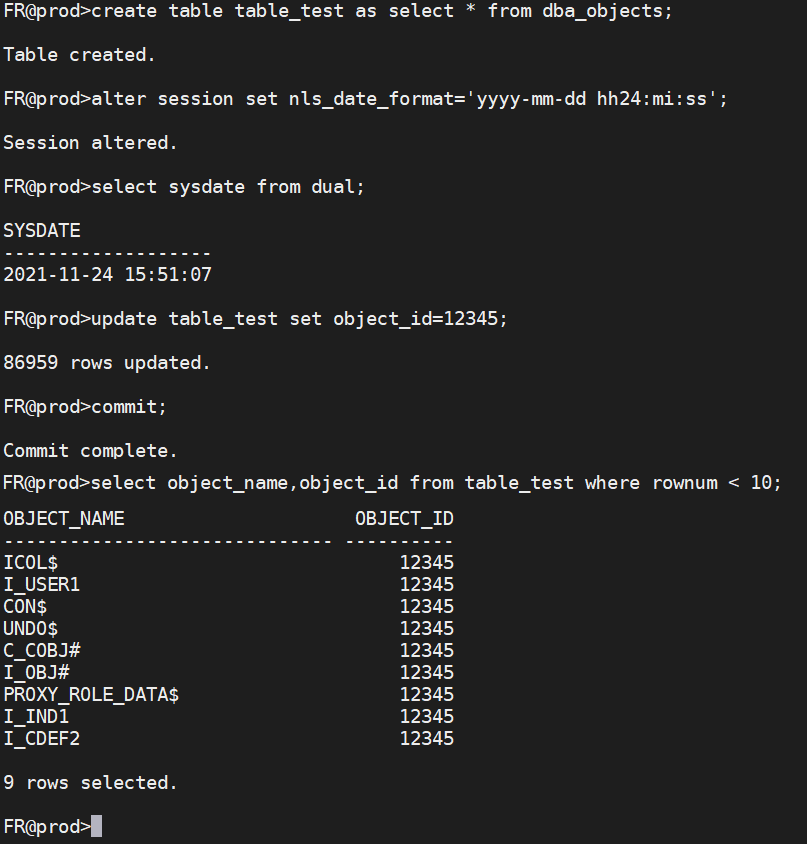
1.创建一个测试表
drop table table_test purge;
create table table_test as select * from dba_objects;(记录一下大概数据正常的时间)
2.模拟误操作
update table_test set object_id=12345;
commit;
由于该update没有添加谓词条件,所有行均被修改,并且已经commit;
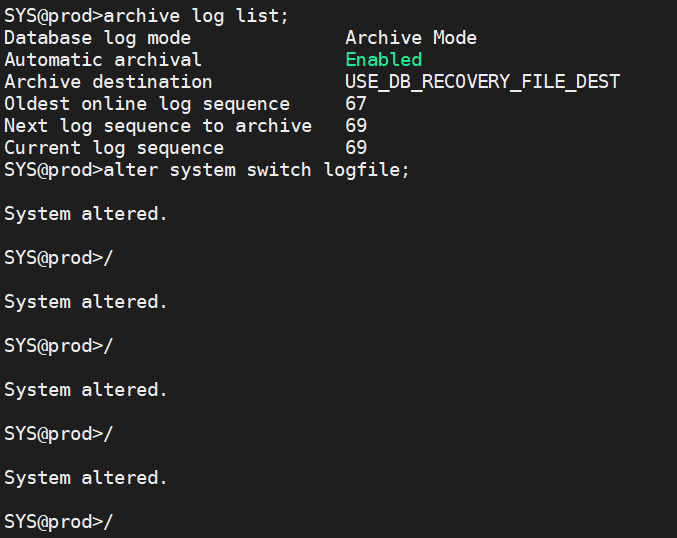
3.模拟已经过去一段时间
archive log list;
alter system switch logfile;(多次执行)
至此,环境已经构建完毕,接下来开始进行日志挖掘。
日志挖掘
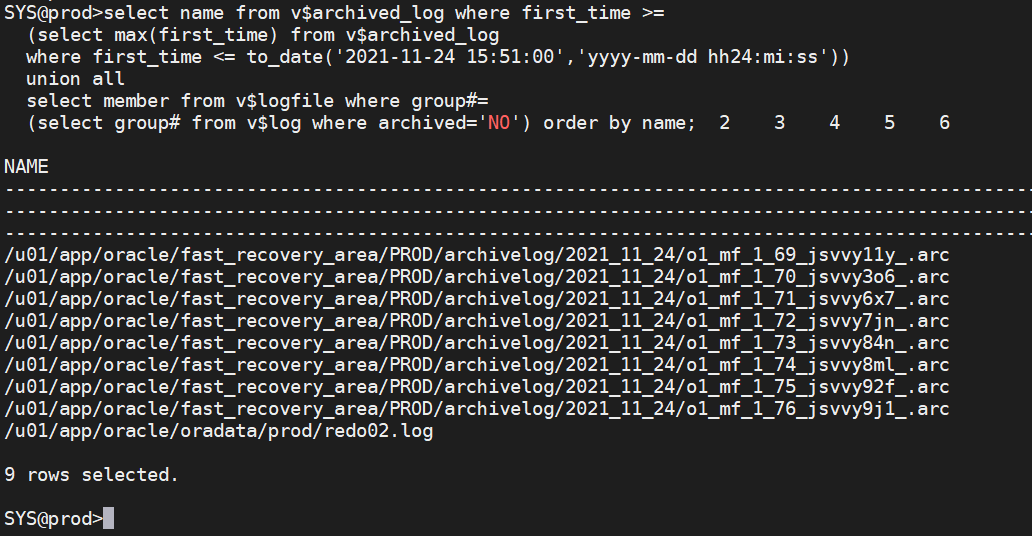
1.根据大致的用户错误时间,找到所需要的所有的日志(归档日志和在线重做日志)
select name from v$archived_log where first_time >=
(select max(first_time) from v$archived_log
where first_time <= to_date('2021-11-24 15:51:00','yyyy-mm-dd hh24:mi:ss'))
union all
select member from v$logfile where group#=
(select group# from v$log where archived='NO') order by name;
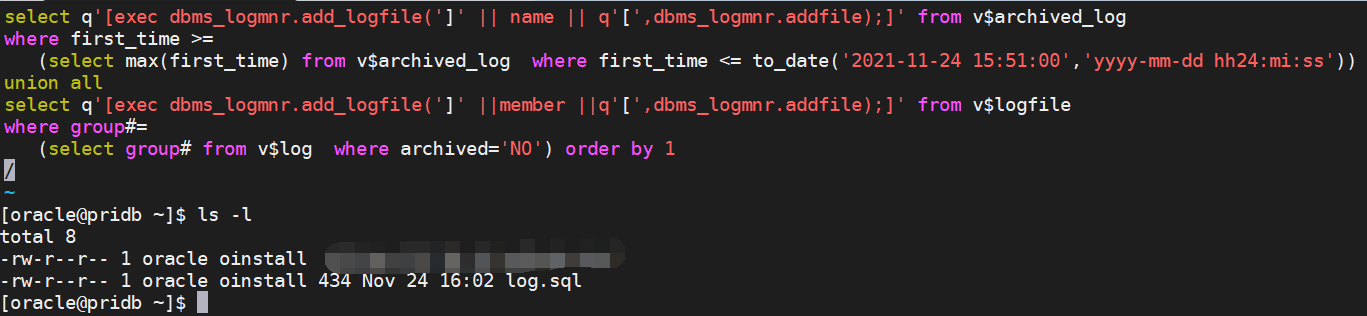
2.修改上一个sql语句,构建并执行挖掘队列所需的脚本
[oracle@pridb ~]$ vim log.sql
select q'[exec dbms_logmnr.add_logfile(']' || name || q'[',dbms_logmnr.addfile);]' from v$archived_log
where first_time >=
(select max(first_time) from v$archived_log where first_time <= to_date('2021-11-24 15:51:00','yyyy-mm-dd hh24:mi:ss'))
union all
select q'[exec dbms_logmnr.add_logfile(']' ||member ||q'[',dbms_logmnr.addfile);]' from v$logfile
where group#=
(select group# from v$log where archived='NO') order by 1
/
SYS@prod>set trim on
SYS@prod>set trims on
SYS@prod>set term off
SYS@prod>set heading off
SYS@prod>set feedback off
SYS@prod>set echo off
SYS@prod>set linesize 500
SYS@prod>set pagesize 0
SYS@prod>spool /home/oracle/logmnr.sql
SYS@prod>@log.sql
SYS@prod>spool off
[oracle@pridb ~]$ vim logmnr.sql

仅保留挖掘队列的命令(保留带有dbms_logmnr.add_logfile字样的行)

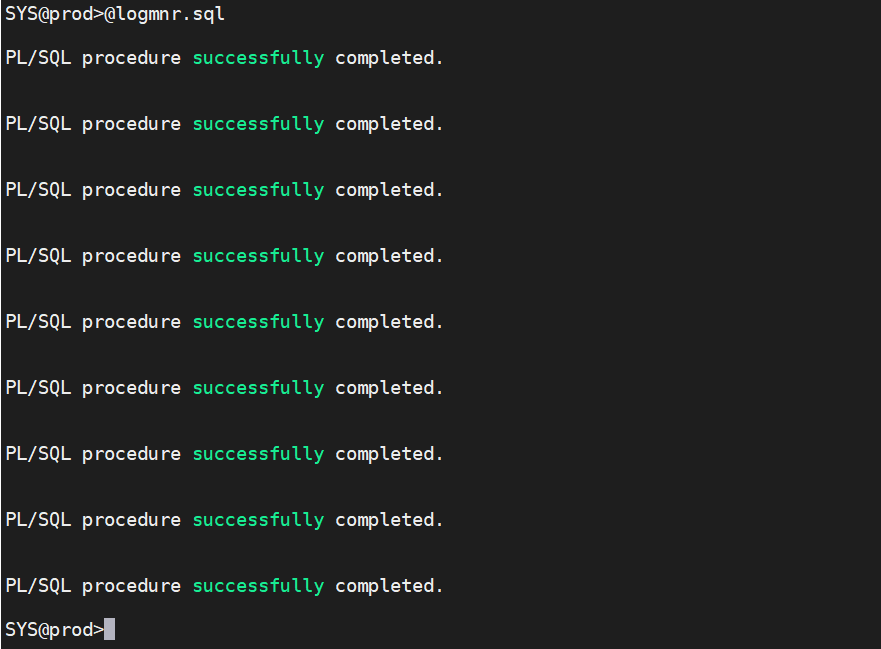
3.执行挖掘队列脚本
@logmnr.sql
为logminer挖掘会话手动注册可挖掘的重做日志(不要退出会话)
4.开始挖掘
exec dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);
–通过载入数据字典开始挖掘,这些字典是用于挖掘器将重做记录中的oracle内部对象翻译成可读的信息的转换字典

5.获取挖掘结果
SYS@prod>set trim on
SYS@prod>set trims on
SYS@prod>set term off
SYS@prod>set heading off
SYS@prod>set feedback off
SYS@prod>set echo off
SYS@prod>set linesize 500
SYS@prod>set pagesize 0
SYS@prod>spool /home/oracle/undo_logmnr.sql
SYS@prod>select sql_undo from v$logmnr_contents
where table_name='TABLE_TEST'
and lower(sql_redo) like 'update%123456%';
---这里会输出所有undo_sql---
SYS@prod>spool off
另外再开一个终端,编辑/home/oracle/undo_logmnr.sql脚本
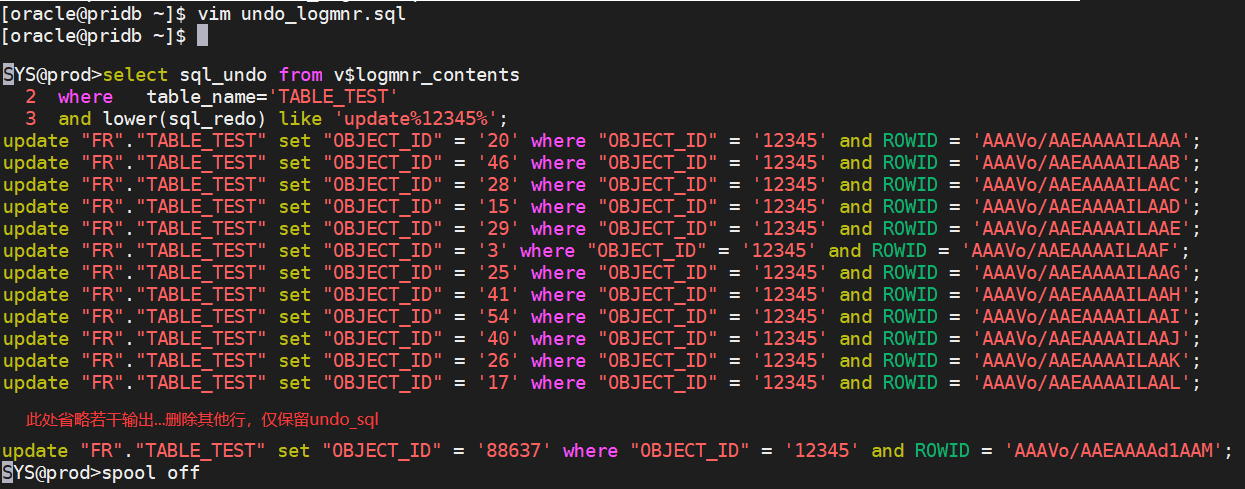
如之前步骤所示,去掉无关输出,只保留undo_sql
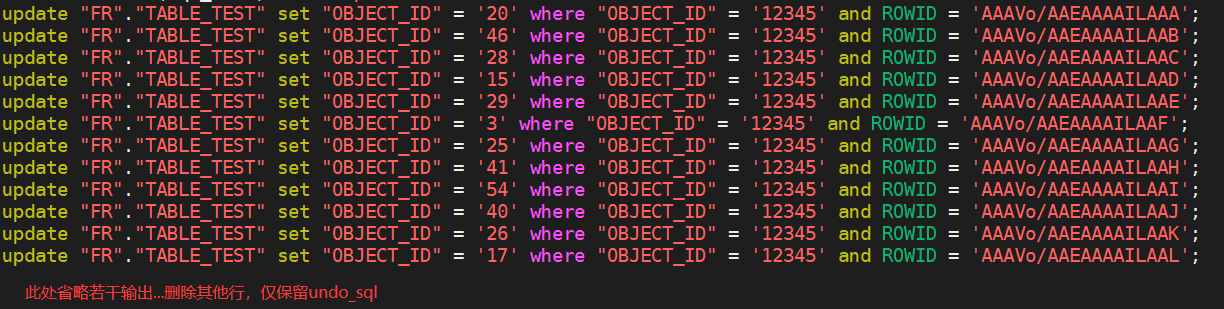
6.执行undo脚本
SYS@prod>@undo_logmnr.sql
7.结束挖掘
SYS@prod>exec dbms_logmnr.end_logmnr;
执行完此步骤,会回收logminer占用的内存,如果不关闭会导致内存被额外占用。

至此logminer过程结束,可以验证数据已恢复。