




各位看官请耐心的看完,后面会介绍工业知识图谱建设的几个主要内容。

自从进入了大数据时代,人们一直在说有了数据才有了智能,这句话说得一点也没错,但很多人可能理解为数据=智能。这就是为什么很多客户建设了大数据平台,有了大数据采集和治理的能力后,发现有数据也没什么用处!
此部分详见文章《没用的大数据平台》
于是产生了新时代的垃圾--数据垃圾,抛弃觉得可惜,全量保存又浪费资源。那么为什么我们还要全量去保存呢?就是由于我们深知智慧化发展的道路上是需要这些数据的,比如搞算法需要训练数据、搞决策需要分析数据。但我们真正需要的是这些数据里蕴含的价值,而不是数据本身。其中较为重要的价值,就是今天我们要谈论的--------数据中蕴含的知识。
可以说知识一直在数据中存在,我们人可以通过大量的阅读数据(比如:读书)来获取其中的知识。那知识是什么?就是知道了识别世间万物规律的方法。比如:
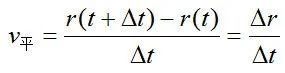
我们抽象知识的过程就是建立知识图谱的过程,只不过在软件层面我们的知识来源于数据。所以,我们需要建立一套可以在多个数据源中抽取知识的系统,然后按照一定的规则加入到知识图谱中,这个过程就是信息抽取。
信息抽取的来源就是数据源,目前主要是两个类别,就是结构化数据和非结构化数据。我们要抽象的知识,在数据层面的表示是两个事物的关系,比如:A是B的父亲,B是C的父亲,那么知识点来了,A是C的爷爷,这些都是从关系中提取的知识。有了关系就有了数学层面的知识。于是从数据中抽取关系是知识图谱建设的第一步。
结构化的数据在存储前已经进行了梳理,所以直接查询处理就可以了,结构化数据如下:
| 姓名 | 生日 | 职业 | 出生地 |
| 阿尔伯特·爱因斯坦 | 1879年3月14日 | 现代物理学家 | 德国乌尔姆市 |
知识图谱表达如下:
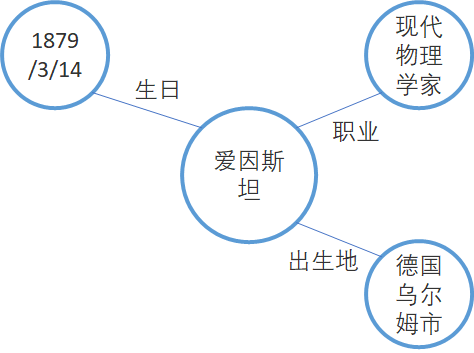
这种知识提取和表达看上去还是比较简单,可是一旦关系层级较多,关系较为复杂,就会出现查询困难等问题,这个后面会介绍。
所以,在知识提取的阶段主要的难点在于非结构化的数据如何提取关系。举个例子,非结构化数据如下:
爱因斯坦出生于德国乌尔姆市的一个犹太人家庭(父母均为犹太人)。1900年毕业于瑞士苏黎世联邦理工学院,入瑞士国籍 [1-4] 。1905年,爱因斯坦获苏黎世大学物理学博士学位,并提出光子假设、成功解释了光电效应(因此获得1921年诺贝尔物理学奖) [1-4] ;同年创立狭义相对论,1915年创立广义相对论,1933年移居美国、在普林斯顿高等研究院任职,1940年加入美国国籍同时保留瑞士国籍 [1-4] 。1955年4月18日,爱因斯坦于美国新泽西州普林斯顿逝世,享年76岁 [1-4] 。 百度百科
知识图谱表达如下:
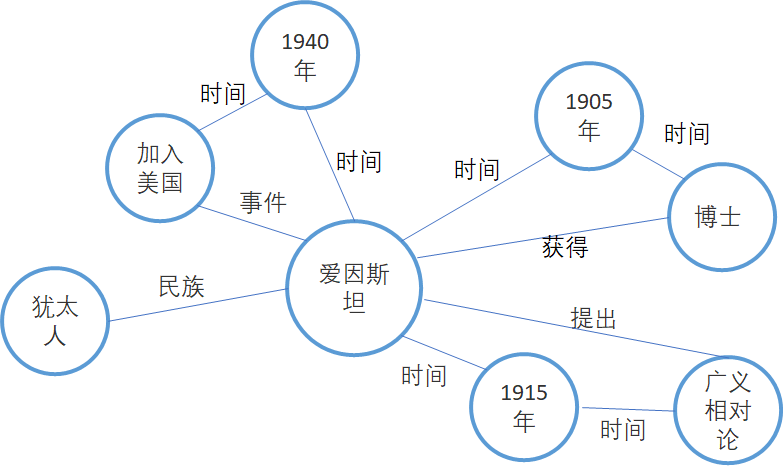
不难看出,想要从非结构化数据中提取关系或者知识,一定需要一系列的处理才能形成知识图谱。
那这一系列的处理包含什么内容呢,我们进一步介绍。
1:关键词库与标签化
首先我们要识别关系中的“实体”,相当于在上述的段落中找到关键词,如:爱因斯坦,并且知道这个关键词是个“姓名”。这就需要我们建立一个实体词列表,并为每个实体词打上标签。例如:【1904年:年份】【博士:学历】【广义相对论:著作】等等。在我们工业行业,关键词举例如下:“主机设备、电机、机床”等等。
2:关系抽取

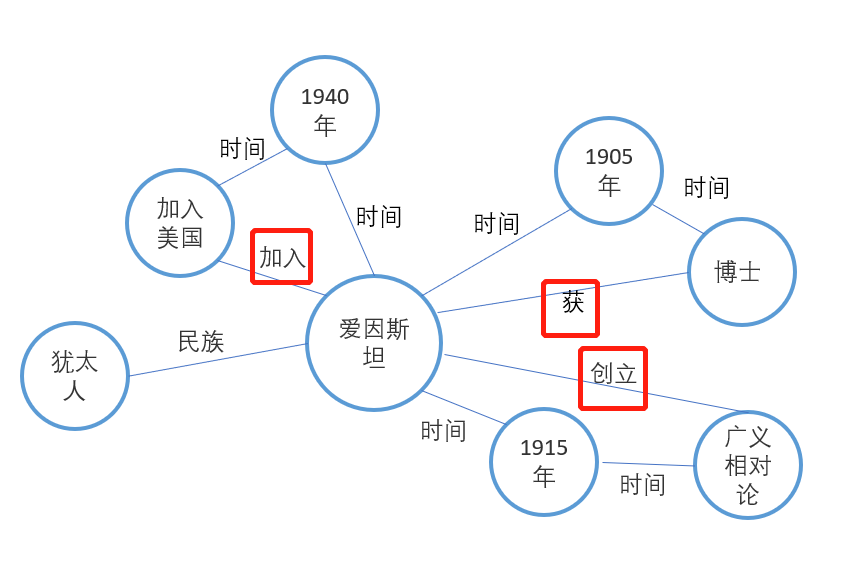
关系抽取是把实体之间的关系抽取出来的一项技术,其中主要是根据文本中的一些关键词,如“创立”、“获得”、“加入”等。这些关键词也需要行业知识来进行创建。比如我们工业中常用的词汇:“下发、采集、驱动、增温增湿”等。
3:实体统一处理
对于一个实体我们的名词可能是不同的,比如:李工和老李可能指的是同一个人,空压机和空气压缩机是同一个设备等等。实体统一处理就是解决这个问题的一项技术。
4:指代归属
如:“控制工艺空调的回风温度主要可以对它的能耗进行控制。”这里的【它】指的是【工艺空调】这些指代类的词语,算法要能够准确的识别。
以上这四步是对数据进行关系提取的主要环节,当我们将实体与关系提取出来后,就涉及到知识图谱的存储问题,上面说了结构化数据一般都存储在关系型数据库中,但是很尴尬的是,关系型数据库不适合存储数据间的关系。于是图数据库应运而生,专门为存储数据间关系而存在,图数据库的特点如下:
关系和节点都可以附加属性
图的遍历效率极高
有完善的事物管理机制
适合工业场景
此部分详见文章《为什么需要用“图数据库”》
有了图数据库,我们存储数据间的关系,特别是复杂层级嵌套关系,有了方法。于是,知识图谱就有了栖身之所。
5:知识推理
我们存储下实体与实体的关系后,通过关系的推理,便可以获取到新的知识,这就是知识推理的过程。举例如下:
例子1:男人和女人是不存在关系的交集的,于是知识推理出,一个人不可能既是男人又同时是女人。
例子2:妈妈和女人是存在关系交集的,于是知识推理得出,妈妈一定是女人。所以,知识推理在知识图谱中是个非常重要的知识创新过程,可以由算法通过关系找到更多的知识点,这比人脑去学习更加快速、准确、和稳定。
以上内容也可以参考之前的文章《自然语言处理的技术难点与解决方案》
通过上面的介绍,我们在工业场景中建设知识图谱至少需要以下步骤:
第一步:构建工业行业词库,并为词库中的词进行标签化。
第二步:搭建图数据库,用于存储关系数据。
第三步:搭建支持自然语言算法的系统,识别和抽取数据并进行关系化。
第四步:搭建知识推理学习系统,用于自学习,创建新的知识。
第五步:构建知识图谱,将知识可视化出来用于分析和展示
当然,创建一个行业的知识图谱也并非只有这一个方法,我们也可以提供一个系统,由行业专家进行知识图谱的构建,由人去输入各种参数之间的关系,但这显然不是这个时代要谈论的话题。但笔者也认为,这两种是可以结合建设的,一些固定下来的知识或关系,由人去录入,更多数据中的知识由系统智能的去识别。这样配合起来建设效果可能会更好。
通过今天的介绍,是否对知识图谱有个基础的了解了呢!欢迎各位留言一起探索智能制造相关的技术。另外关于知识图谱建设后,最显著的应用场景是什么?或者知识图谱有什么用处?我们会单独写一篇文章跟大家探讨。
