





前言
在大学和研究生阶段,矩阵的各种操作是绝对绕不开的,其中一个最基本的操作就是矩阵的转置。我们知道矩阵论在计算机行业有着非常重要的作用,那么我们在日常工作中是否能够把一些对象抽象为矩阵,把一些场景抽象为对矩阵的操作,从而简化业务场景呢?要想解决这个问题,我们下面先看下什么是矩阵的转置。
矩阵的转置
矩阵的转置,即将矩阵的行和列互换,但又保证矩阵的行列式不变。比如下面这个矩阵A,属于m × n矩阵,即该矩阵有m行n列。

将A矩阵进行转置,即是将A中的每一个元素位置由原来的(x, y)转换为(y, x),其中1 ≤ x ≤ m,1 ≤ y ≤ n。将转置后的矩阵取名为AT,其结构如下图。

了解了矩阵转置的基本操作,我们又有了新的疑问:该操作又与数据库有什么关系呢?
矩阵与关系型数据库
在软件开发中,关系型数据库中的表可以看作是一个矩阵,数据表的字段对应矩阵的列,数据表的每一条数据对应矩阵的行,如下客户信息表(customer_info)数据。
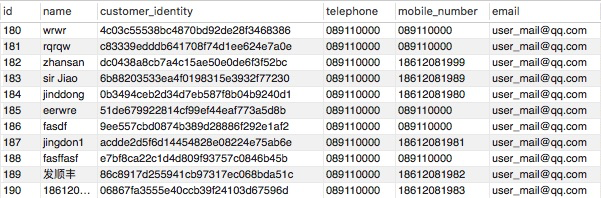
图中有11条数据,且表中定义了6个字段,那么该数据表可以看作一个11 × 6的矩阵。
既然矩阵与关系型数据库有对应关系,那什么场景下需要用到数据表的转置操作呢?
行列转置的应用场景
我们知道,在关系型数据库中,表字段是提前定义好的,并且表的结构定义与表的使用是分离开的,即在程序开发之前先定义好表的结构,程序的运行过程仅仅针对表的行数据进行增删改查操作。这么做是为了保证数据的稳定与安全性。但如果碰到一些特殊的业务场景,可能这种先建表再操作数据的开发模式就不太适用了。
在SaaS化场景中,同样的业务对象需要根据不同的业务身份进行定制,如客户信息,不同的使用者关注的客户属性不同,这种情况下,就需要定义一种特殊的数据结构,来满足不同使用者对同一属性表的定制化字段需求。
传统数据结构存储
定义数据表A,其建表语句为:
CREATE TABLE `A` (`id` BIGINT AUTO_INCREMENT,`col_1` varchar(50),`col_2` varchar(50),`col_3` varchar(50),`col_4` varchar(50),PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
执行以下语句,在表中插入4条数据:
INSERT INTO `A` (`col_1`, `col_2`, `col_3`, `col_4`)VALUES('val11', 'val12', 'val13', 'val14'),('val21', 'val22', 'val23', 'val24'),('val31', 'val32', 'val33', 'val34'),('val41', 'val42', 'val43', 'val44');
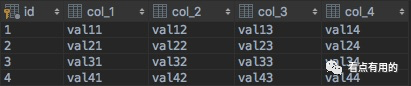
这样在表A中就构建了一个4 × 4的矩阵(去除id主键):
转置数据结构存储
定义数据表AT,其建表语句为:
CREATE TABLE `AT` (`id` BIGINT AUTO_INCREMENT,`batch_id` BIGINT,`col_name` varchar(50),`col_value` varchar(50),PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
执行以下语句,在表中插入数据:
INSERT INTO `AT` (`batch_id`, `col_name`, `col_value`)VALUES(1, 'col_1', 'val11'),(1, 'col_2', 'val12'),(1, 'col_3', 'val13'),(1, 'col_4', 'val14'),(2, 'col_1', 'val21'),(2, 'col_2', 'val22'),(2, 'col_3', 'val23'),(2, 'col_4', 'val24'),(3, 'col_1', 'val31'),(3, 'col_2', 'val32'),(3, 'col_3', 'val33'),(3, 'col_4', 'val34'),(4, 'col_1', 'val41'),(4, 'col_2', 'val42'),(4, 'col_3', 'val43'),(4, 'col_4', 'val44');
这样在表AT中就构建了一个字段名与字段值映射的数据结构:
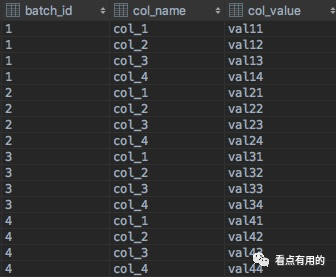
通过比对上述两种数据结构,可以发现在需要动态变更表结构的业务场景下,转置数据结构的存储方式更方便,只需要维持同一个batch_id的情况下,多插入一条key-value值即可。
关系型数据库的行列转置
在上文中我们知道,在需要动态变更表结构的应用场景下,转置数据结构存储比传统数据结构存储更有优势,但上层应用其实想要获取到的仍然是结构明确的一条条数据,即在查询时仍然需要构建传统数据结构视图。那又怎么进行处理呢?
pivot函数
pivot函数是Sql Server的内置函数,其标准用法如下:
SELECT <非透视的列>,[第一个透视的列] AS <列名称>,[第二个透视的列] AS <列名称>,...[最后一个透视的列] AS <列名称>,FROM(<生成数据的 SELECT 查询>)AS <源查询的别名>PIVOT(<聚合函数>(<要聚合的列>)FOR[<包含要成为列标题的值的列>]IN ( [第一个透视的列], [第二个透视的列],... [最后一个透视的列])) AS <透视表的别名><可选的 ORDER BY 子句>;
该函数并不是所有数据库都支持,此处不再详述,具体用法可自行验证。
聚合函数方案
聚合函数在任何版本的数据库中都是支持的,所以该方案可以作为一种通用解决方法,其具体语句如下:
SELECTbatch_id AS id,MAX(CASE col_name WHEN 'col_1' THEN col_value ELSE NULL END) 'col_1',MAX(CASE col_name WHEN 'col_2' THEN col_value ELSE NULL END) 'col_2',MAX(CASE col_name WHEN 'col_3' THEN col_value ELSE NULL END) 'col_3',MAX(CASE col_name WHEN 'col_4' THEN col_value ELSE NULL END) 'col_4'FROM `AT`GROUP BY batch_id;
该方案的执行原理是,将AT表中的数据按batch_id进行聚合,然后通过case…when函数将多条数据合并成一条数据,其执行结果如下图所示。
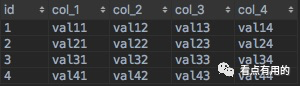
通过比对可以发现,该执行结果与“传统数据结构存储”中的查询结果是一致的。
结语
本文通过一个示例说明了数据库中的行列转置,其转置本质与矩阵的转置是一致的。其实矩阵或高数中的很多特性在软件开发中都能找到对应的应用场景,对数学的熟练程度间接地影响了自己软件开发的水平。数学与软件的关联性有待于我们进一步的发掘。
