




更轻、更快的Dmeta-Embedding-zh-small来啦!
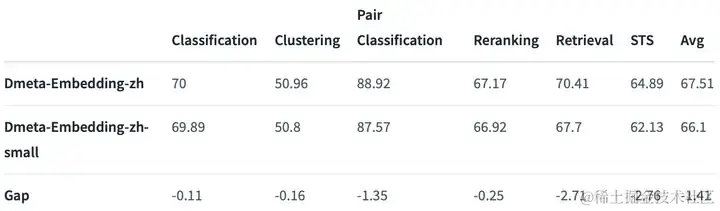
自Dmeta-Embedding-zh发布以来,我们的模型受到了众多用户使用与支持,我们深感荣幸!现在,更轻、更快、更便捷的Dmeta-Embedding-zh轻量化版本Dmeta-Embedding-zh-small已上线!相较于原始版本的Dmeta-Embedding-zh,轻量化的small版本推理速度提升约30% ,模型大小减小约三分之一,总体精度约下降1.4%(参考自MTEB榜单)。
- 高效性能:经过深度优化,新模型在基本保持原有精度的同时,显著降低了资源消耗,提升了运行效率。
- 易于集成:轻量化模型设计使得它更容易集成到各种规模的项目中,无论是初创企业还是大型企业,都能轻松应用。
- 成本效益:降低的资源消耗意味着更低的运行成本,让先进的 AI 技术更加亲民,助力开发者降低门槛,快速实现技术落地。

如何体验轻量化 Dmeta-Embedding 模型?
为了让大家能够第一时间体验到轻量化 Dmeta-Embedding 模型的强大功能,我们准备了详尽的教程和指南。您可以通过以下步骤快速开始:
- 访问模型主页(huggingface.co/DmetaSoul/D…) ,了解轻量化 Dmeta-Embedding 模型的详细信息。
- 查看教程文档,我们将提供包括但不限于 Langchain、Sentence-Transformers 等工具结合 Dmeta-Embedding 模型的使用教程,助您快速上手。
- 参与内测活动,通过提交申请(详见《现在!就请您使用 Dmeta Embedding 轻松开启 RAG 之旅吧!》),我们将为您开通 API Key,让您能够免费体验轻量化模型带来的便利。
如何在 Chroma 中使用Dmeta-Embedding系列模型?
为了方便大家在向量数据库 Chroma 中使用 Dmeta-Embedding 系列模型,在此我们提供了模型本地推理和HTTP API 两种方式的使用示例,简单快速集成到 Chroma 生态中。
0)首先,导入必要的依赖库
python复制代码import chromadb from chromadb import Documents, EmbeddingFunction, Embeddings from sentence_transformers import SentenceTransformer from langchain.embeddings import HuggingFaceEmbeddings import torch # 获取client client = chromadb.PersistentClient(path="your_path")
1.1)如果采用 HTTP API 方式,可以利用我们推出的 Dmeta-Embedding API,申请内测即可免费获得 4 亿 tokens 使用额度(内测申请)
ini复制代码# 通过Dmeta-Embedding API推理 import chromadb.utils.embedding_functions as embedding_functions dmeta_api_ef = embedding_functions.OpenAIEmbeddingFunction( api_key="your_key", api_base="https://api.dmetasoul.com/v1", model_name="DMetaSoul/Dmeta-embedding" ) DE = dmeta_api_ef
1.2)如果采用模型本地推理方式,可以通过 sentence-transformers、langchain 等方式加载推理:
ini复制代码# 通过sentence-transformers加载推理 class Dmeta_embedding(EmbeddingFunction): def __call__(self, input: Documents) -> Embeddings: embeddings = [] model = SentenceTransformer('DMetaSoul/Dmeta-embedding-zh') embeddings = model.encode(input, normalize_embeddings=True).tolist() return embeddings DE = Dmeta_embedding() # 或者通过通过 LLM 工具框架 langchain加载推理,二选一即可 class Dmeta_embedding(EmbeddingFunction): def __call__(self, input: Documents) -> Embeddings: model_name = "DMetaSoul/Dmeta-embedding-zh" model_kwargs = {'device': 'cuda' if torch.cuda.is_available() else 'cpu'} encode_kwargs = {'normalize_embeddings': True} model = HuggingFaceEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, ) embeddings = model.embed_documents(input) return embeddings DE = Dmeta_embedding()
2)创建 collection 索引
sql复制代码# 创建collection collection = client.get_or_create_collection("my_collection", embedding_function=DE) collection.add( documents=["胡子长得快怎么办?", "怎样使胡子不浓密!", "香港买手表哪里好", "在杭州手机到哪里买"], metadatas=[{"source": "my_source"}, {"source": "my_source"}, {"source": "my_source"}, {"source": "my_source"}], ids=["id1", "id2", "id3", "id4"] ) collection.get() #{'ids': ['id1', 'id2', 'id3', 'id4'], # 'embeddings': None, # 'metadatas': [{'source': 'my_source'}, # {'source': 'my_source'}, # {'source': 'my_source'}, # {'source': 'my_source'}], # 'documents': ['胡子长得快怎么办?', '怎样使胡子不浓密!', '香港买手表哪里好', '在杭州手机到哪里买'], # 'uris': None, # 'data': None}
3)进行检索查询
lua复制代码query_result = collection.query( query_texts =["胡子长得太快怎么办?"], n_results=2, ) print(query_result) # {'ids': [['id1', 'id2']], 'distances': [[0.09293291344747456, 0.6447157910392011]], # 'metadatas': [[{'source': 'my_source'}, {'source': 'my_source'}]], # 'embeddings': None, 'documents': [['胡子长得快怎么办?', '怎样使胡子不浓密!']], # 'uris': None, 'data': None}
完整代码示例请参考:github.com/meta-soul/d…
后续支持与服务:
我们将持续提供技术支持和产品更新,同时,我们也期待您通过Github、HuggingFace等多种渠道给予我们宝贵反馈,以便我们不断优化产品,为您提供更加完善的服务。
立即行动,加入 Dmeta-Embedding 的行列,共同探索 AI 技术的无限可能!
[关于我们]
数元灵科技成立于2021年,专注于一站式的大数据智能平台新基建,在研项目包括云原生湖仓一体框架LakeSoul,一站式机器学习框架MetaSpore, 以及云原生一站式AI开发生产平台AlphaIDE。公司力争打造以数据驱动为中心的标准化pipeline,推动国家数字化经济发展,致力于为帮助企业充分释放业务价值,服务新基建,让更多的行业和技术从业者享受到更普惠的大数据人工智能红利。
- 数元灵科技是国家高新技术企业、中关村高新技术企业
- 数元灵获国家信创认证、ISO27001信息安全管理、CMMI等资质认证、海光等生态认证
- 数元灵产品拥有软件著作12项,授权核心专利多项
- 入选最具潜力创业企业TOP10榜单、大数据产业国产化优秀代表厂商
GitHub:
github.com/lakesoul-io
AlphaIDE:
registry-alphaide.dmetasoul.com/#/login
官网:
官方交流群:
微信群:关注公众号“元灵数智”,点击“了解我们-用户交流”
