




开始之前
当我们把数据从socket中读出来的时候,往往需要对这些数据做前置处理,以便进行后续的业务逻辑,也需要把业务逻辑的返回值进行后置处理写回socket。前置处理包括:数据拆包->数据解码。后置处理包括:数据编码->分割数据。如果数据量大的话在最后可能还要加上 数据压缩,对应的需要 数据解压。所以一个完整的请求在服务端可能需要经过如下的处理:
socket | ->拆包->解压->解码->业务逻辑->编码->压缩 ->添加分隔符 -> | socket
如果以传统的方式去做的话,我们可能会把每个模块写成一个方法,然后耦合在一个类中,这样的坏处就是不能灵活的组合这些模块,比如说 不需要解压缩,但是需要 验权,日志输出等操作。
解决此问题的关键是可以灵活简便的方式删除,增加上述操作,其中每个操作完成特定的过滤动作。
Intercepting Filter
姑且称为 拦截过滤器,最常见的是在web容器的配置文件会为一些URL定义一组filter chain,这些filters会在URL请求资源之前做诸如 session检查,权限检查,日志输出等。我们可以在配置文件中修改这些filter,并不会影响核心业务逻辑。
有关Intercepting Filter的介绍可以阅读这篇文档
(https://www.oracle.com/technetwork/java/interceptingfilter-142169.html)
Netty中的实现
在netty中使用ChannelPipeline,ChannelHandler,ChannelHandlerContext来实现对IO事件及操作的拦截过滤。他们的组合方式如下图:
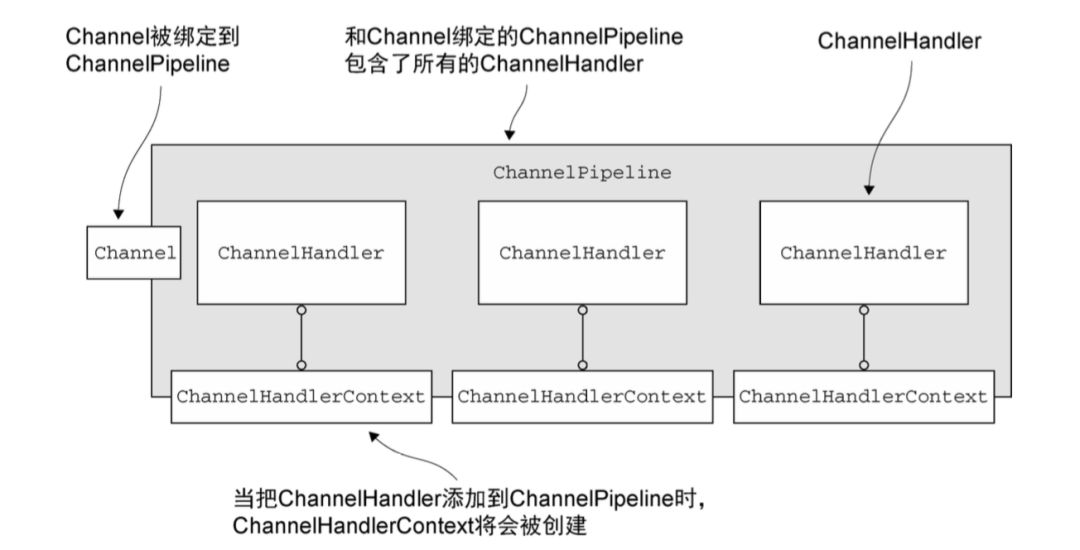
其中ChannelPipeline随着Channel的创建而创建,即每个Channel都对应着自己唯一的ChannelPipeline。
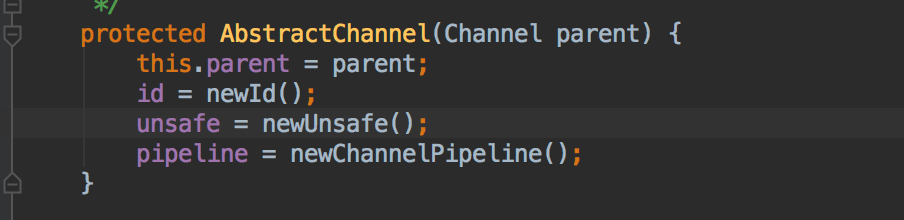
ChannelPipeline在初始化的会构建自己的链表为存放channelHandler作准备:
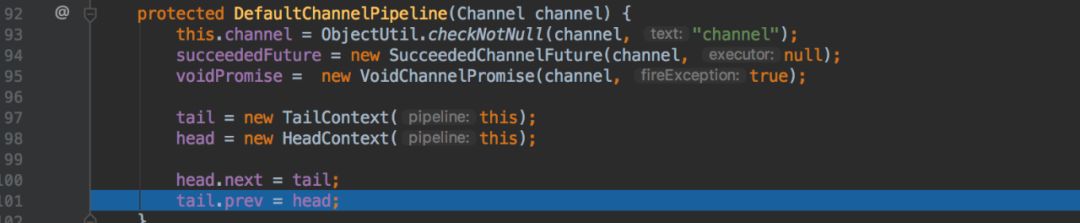
其中head代表链表头,tail代表链表尾,链表中的元素是ChannelHandlerContext。
当把ChannelHandler添加到ChannelPipeline时,ChannelHandlerContext将会被创建。被创建的context将会添加到pipeline的链表中,如下图:
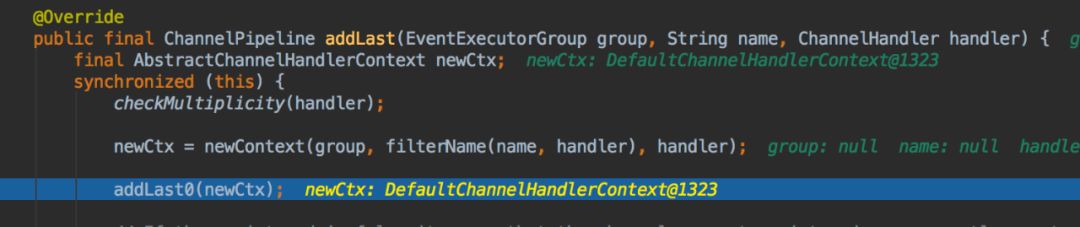
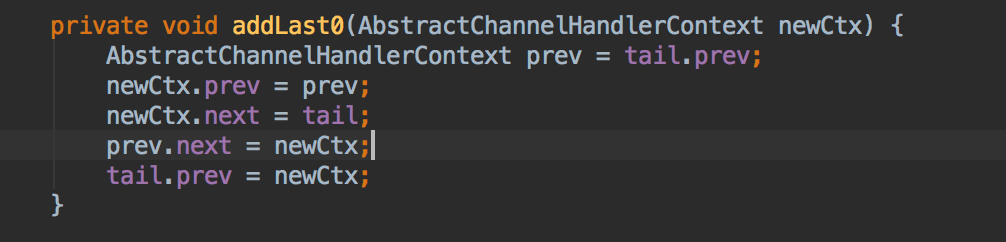
以上实现了在channel上对读写就像过滤拦截的基础,下面我们来看具体是怎么运行的。
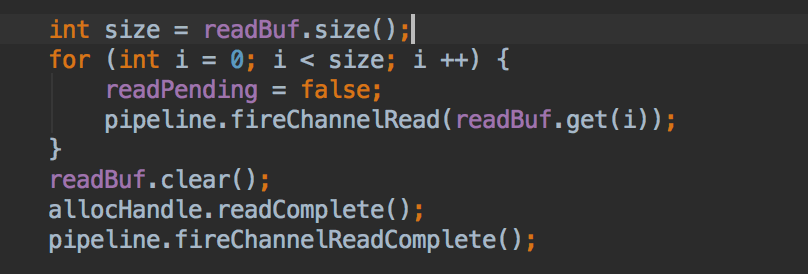
当channel中有数据被读出时,pipeline执行fireChannelRead方法从而使 该数据从pipeline的头部开始流动,handler准备进行拦截

HeadContext执行invokeChannelRead方法
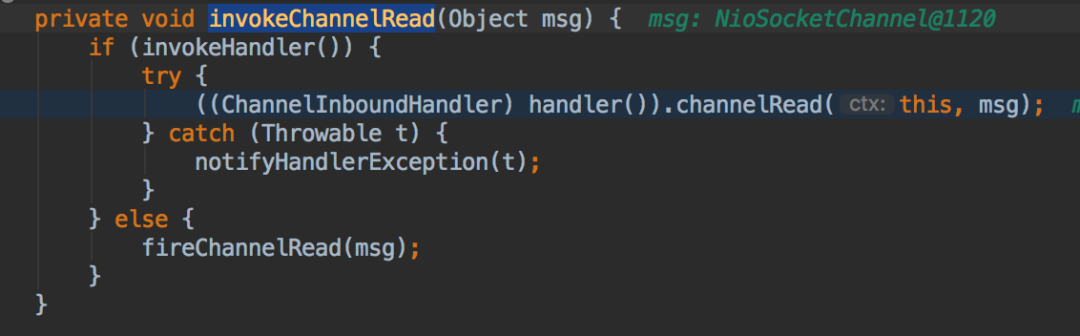
其中handler()方法返回context对应的handler,然后执行对应的channelRead方法。
每次一个handler执行完便会找到下一个合适的context:

下面这张图很好的表达出了事件在pipeline中流动的过程:
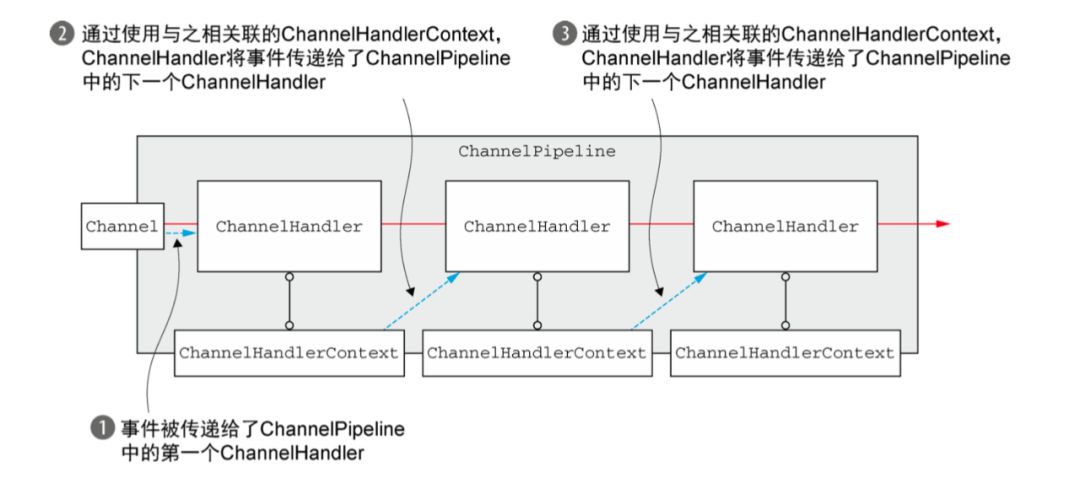
需要注意
pipeline的尾端,是用addLast最后一个添加到链表中的channelOutboudHandler
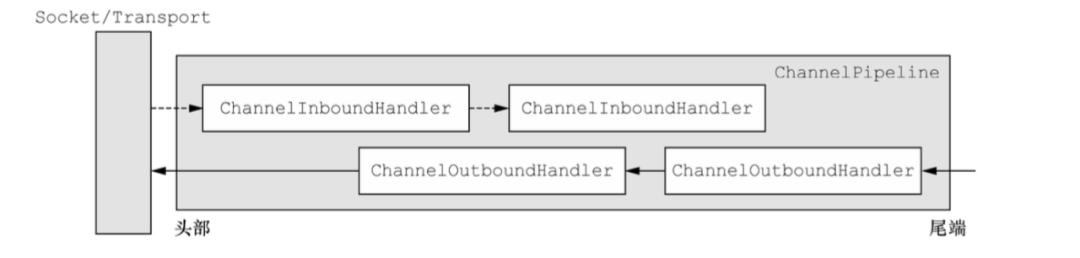
在channel或者pipeline上直接调用读写方法都会导致事件从pipeline的首尾开始流动。
在context上调用读写只会使事件从当前流转到下一个context。
所以在编程的时候需要注意不要在自己编写的ChannelOutboundHandler中调用channel或者pipeline的读写,因为这样会导致你的数据用于些不带socket中,只会在链表中循环。
结束语
本文简单介绍了Netty如何运用ChannelPipeline, ChannelHandlerContext与ChannelHandler实现对网络事件的拦截过滤,大家可以通过代码调试来加深自己的理解。
