控制文件逻辑存放位置在global表空间下,物理存放在data/global目录下,大小为8k
修改kingbase.conf参数control_file_copy可以备份多个控制文件,当控制文件损坏或者被误删除时,可以通过该参数将设置路径下生成的控制文件copy到global下
control_file_copy = '/home/kingbase/sys_control1;/home/kingbase/ES/sys_control2'

#不支持sys_resetwal方式重建控制文件
wal日志
WAL日志的作用通俗的讲主要用来保证数据完整性,当用户向表中插入数据提交后会先将操作日志写入到日志文件,当数据还未保存到磁盘系统crash,可以通过wal日志中记录的事物进行恢复
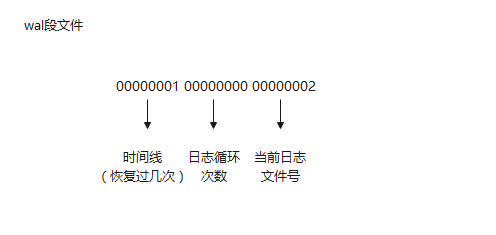
wal日志文件大小默认16MB, 00000001 00000000 00000002 文件是通过16进制的数字命名
- 00000001 //时间线ID
- 00000001 //LogId
- 000000C4 //logSeg
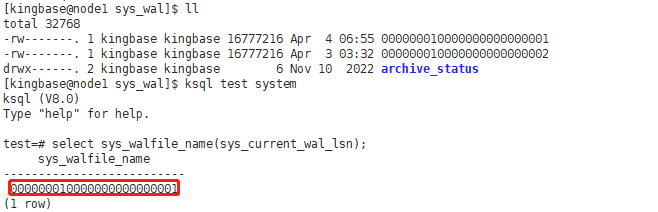
wal日志一次会生成多个文件,但最新的日志未必是当前使用的wal文件,可通过下列函数查询当前使用的wal文件
查看日志序列number号
select sys_walfile_name(sys_current_wal_lsn);
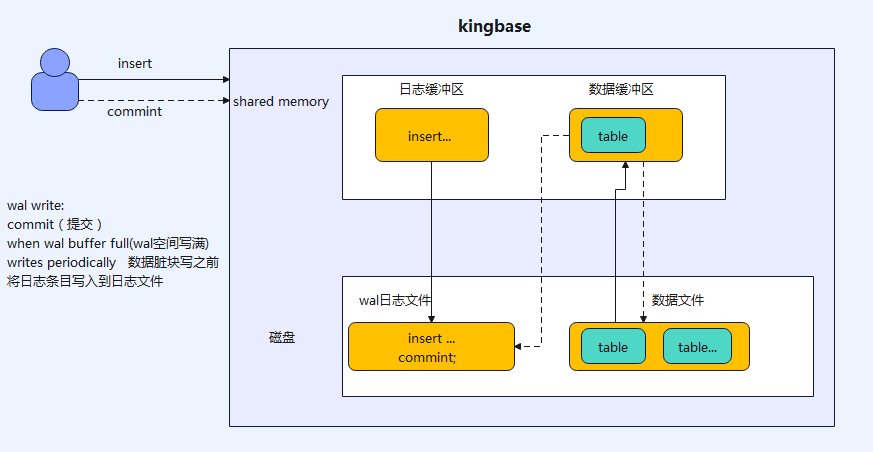
当用户向数据库发送请求,对表insert 数据库,首先将语句格式化成特性的日志条目放入wal buffer中,而后将数据块从磁盘读到buffer cache中进行insert操作。当用户commit时会将日志条目从wal buffer写入到日志文件中。而数据缓冲区此时并不会将脏数据时时写入到数据文件,当此时系统发生崩溃而脏数据还未写入到磁盘时,可通过wal日志条目来进行数据恢复
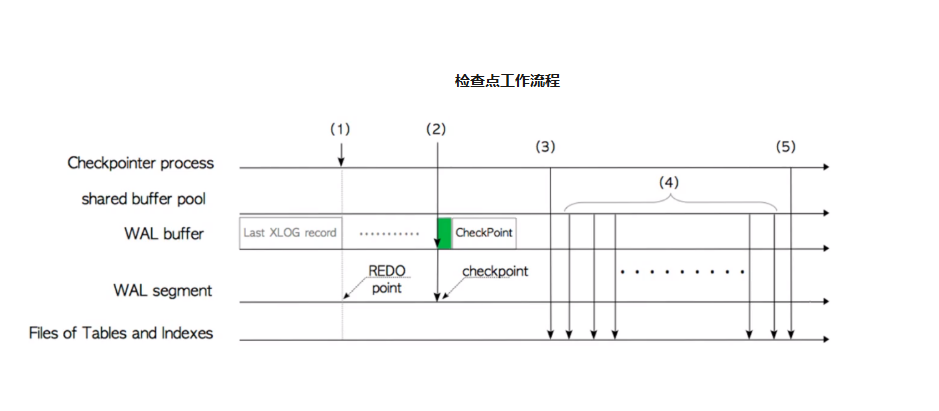
当检查点发生时,kes会收集检查点的相关信息,所以会标记一个redo起始位置,在记录checkpoint的位置,而后将检查点之前脏块写入到数据文件中(#检查点包含了redo的位置,当需要恢复时,通过checkpoint的位置查找redo的位置,从redo的位置往后进行数据恢复)
wal文件切换
select sys_switch_wal;
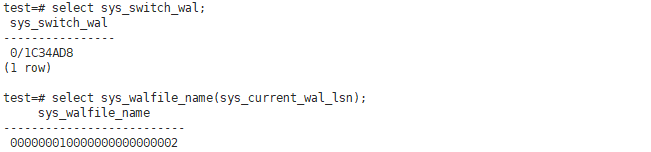
wal文件段的数据主要由以下2个参数控制
wal_keep_segments :用户主从复制、高可用时指定保留多少个wal文件
checkpoing_complation_target:内核将数据刷新到磁盘的时间,默认是 0.5。值越大意味着checkpointer进程休眠的机会越多,以控制脏块刷盘的进度。在checkpoint过程中当刷盘的脏数据超过一定值(checkpoint_flush_after )后,会调用fsync将数据从page cache中刷盘。
因此,休眠越多,fsync也就不那么频繁,刷盘的IO压力就会降一点。在checkpoint完成后,会调用一次fsync,将page cache都刷到磁盘
检查点的作用
定期保存修改过的数据块,将修改过的脏数据定期从缓冲区写入到磁盘中,防止服务器在发生断电、异常时内存的数据块就会丢失
实例恢复时的起始位置,如果发生实例崩溃,那么在下一次启动时需要进行实例恢复,数据库会找最近一次检查点的位置做为起始位置进行recovery
介质恢复时的起始位置,每次物理备份都会触发一个检查点,用来判断恢复时的起始位置。因为备份时数据文件有先后顺序且备份出的数据文件也不一致,后期恢复需要使用归档将其变成同步,起始的备份位置就是recovery位置
检查点的触发机制
- checkpoint_time:检查點的间隔时间,默认300s
- kes在smart或fast模式下关闭数据库
- wal文件总大小超过max_wal_size设定的值
- 手动执行checkpoint操作
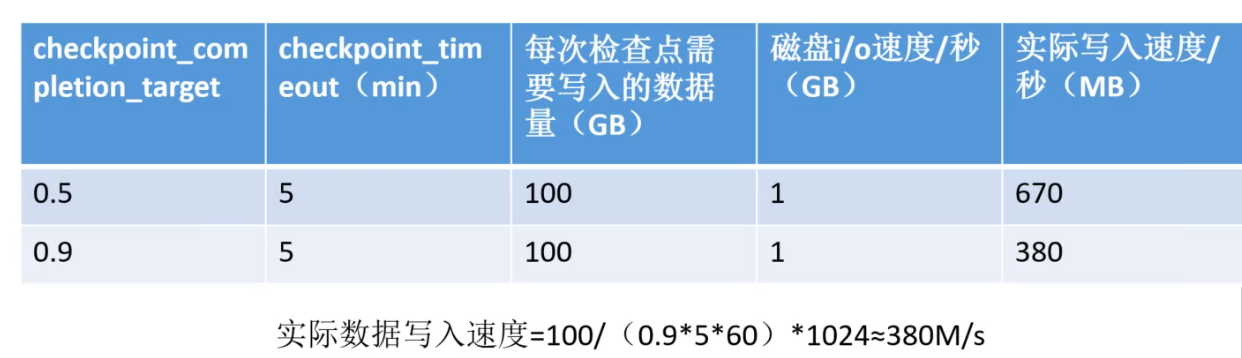
checkpoint_completion_target主要与checkpoint_timeout配合使用,值越小表示检查点要越快完成,要求写的越快i/o就越高
控制每次检查点发生时i/o的吞吐量,值越高i/o占用的资源越少,数据库性能就越高
checkpoint_flush_after:在执行检查点时,只要写入的字节数超过checkpoint_flush_after,则尝试强制OS将这些写入操作刷到存储中。这样做将限制内核页面缓存中的脏数据量,从而减少在检查点末尾发出fsync时停顿的可能性,参数默认0(禁用)
checkpoint_warning:如果产生的wal日志超过max_wal_size而导致的检查点发生的时间比这段时间更近,向服务器日志中写入消息,此时建议增加max_wal_size,参数默认30s