“尽管我已经掌握了许多图查询命令,但当开始对图进行建模时,我仍然感觉自己像个新手。”
这是我们一位客户的话,反映了图数据库初学者从熟悉的关系型数据库过渡到图数据库世界时的共同感受。
前言
虽然我们经常在新手指南中强调查询语言的重要性,但大多数用户在实际应用中面临的主要挑战不是编写查询语句,而是将数据无缝迁移到图数据库——尤其是从传统关系数据库过渡时,这一挑战尤为突出。
· 节点和边的不当区分
数据表的命名法通常将所有表呈现为现实世界中的不同实体。当用户尝试辨别哪些表表示真实实体,哪些表描述这些实体之间的关系时,这可能会导致混淆。
· 架构中徘徊的冗余字段过多
“冗余字段”的概念,旨在解决 SQL 表 JOIN 查询的低效率问题,在用户的脑海中挥之不去。这使得删除或替换这些字段具有挑战性,尤其是在处理图数据的设计时。
· 表结构调整不足
在对表结构进行多次修改后,最终的图模型有时可能会明显偏离原始表结构。进行如此重大的转变是很少有初学者愿意承担的任务。
真相是 无论用户的数据是否是表结构,往往都无法直接转换为图数据。图数据遵循特定的要求:节点必须拥有唯一的ID作为其身份证,而边必须指定FROM和TO,两者都引用图中的节点 ID。只有这样,我们才能真正体会到边缘之美,“一座连接节点的宏伟桥梁”!
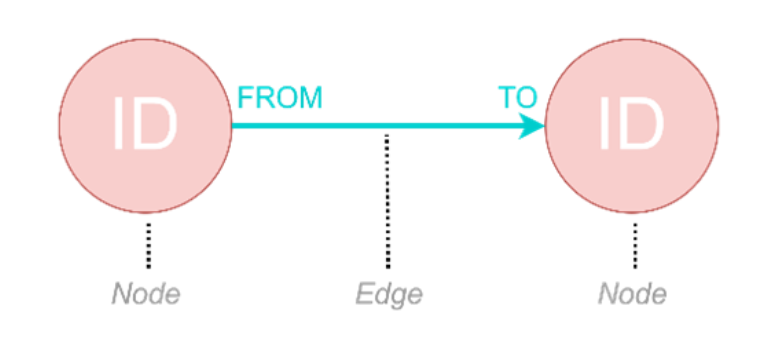
图1:节点的 ID 和边的 FROM、TO 的图示
这种艰巨的数据迁移过程通常涉及多轮微调数据模式[1] 。如果说在这场数据转换中有什么黄金法则的话,那就是:一丝不苟地关注原始表中的主键和外键。这些键将成为节点的 ID 以及边缘的 FROM 和 TO,使其成为成功获取图数据的关键元素。
让我们深入研究一个实际示例,演示如何将使用 SQL Server 构建的医院信息管理系统的表结构转换为图模型,然后将生成的图数据导入嬴图系统中。

1、表结构
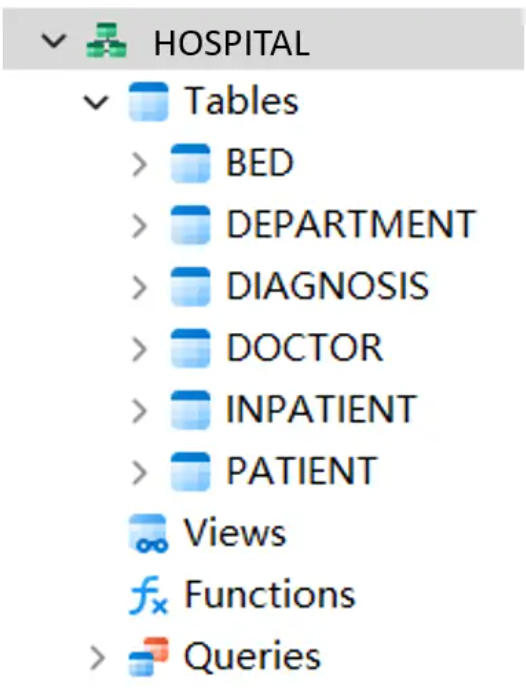
图2:在 SQL Server 中为医院信息管理系统创建的表
让我们创建一个关系图来直观地描述这些表之间的关系:
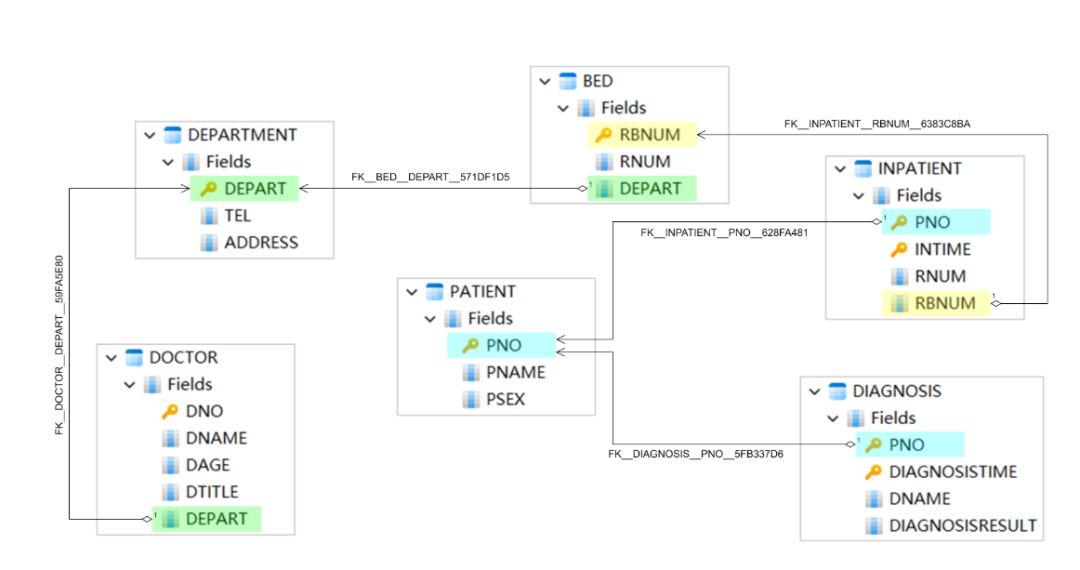
图3:表关系的可视化,突出显示了从外键到主键的链接
在图中,从外键开始到主键结束的箭头指示表的互连方式以及 SQL 联接查询的执行方式。例如,要收集特定医生在特定时间范围内看到的有关患者的信息,包括他们的姓名、性别和诊断,必须关注字段 PNO,将 DIAGNOSIS 表与 PATIENT 表链接起来。对于精通SQL的读者来说,这种表连接查询无疑是熟悉的景象。
这种初始的结构设计也有其缺陷。例如,在 DIAGNOSIS 表中,将记录医生的姓名 DNAME,而不是其唯一标识符 DNO。此设计缺陷会导致缺少外键,从而阻止 DIAGNOSIS 表与 DOCTOR 表建立连接以获取详细的 doctor 信息。尽管可以通过在 DIAGNOSIS 表中添加一些有关医生的常见信息(例如部门名称 DEPART)来避免联接查询的复杂性,但不能低估冗余存储带来的挑战,例如磁盘空间消耗和数据一致性检查。
在图数据库模型的后续设计中,这些困境将不再构成障碍!
2、表中的数据
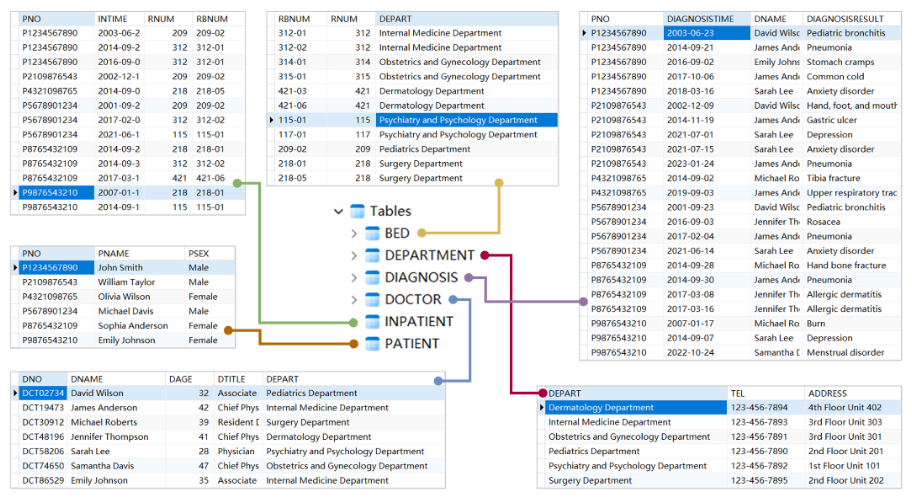
图4:医院信息管理系统中6个表格数据的全面概述
虽然表格表示是系统的,它提供了单个数据字段的详细和透明的概述,但它缺乏阐明数据记录之间高维交互的能力。诸如“哪个科室的医生照顾了哪个病人”或“哪个病人被分配到特定科室的哪个病房”这样的问题很难仅从表格中推断出来。与我们即将构建的图模型相比,这种直观的理解变得非常具有挑战性。
1、区分节点和边
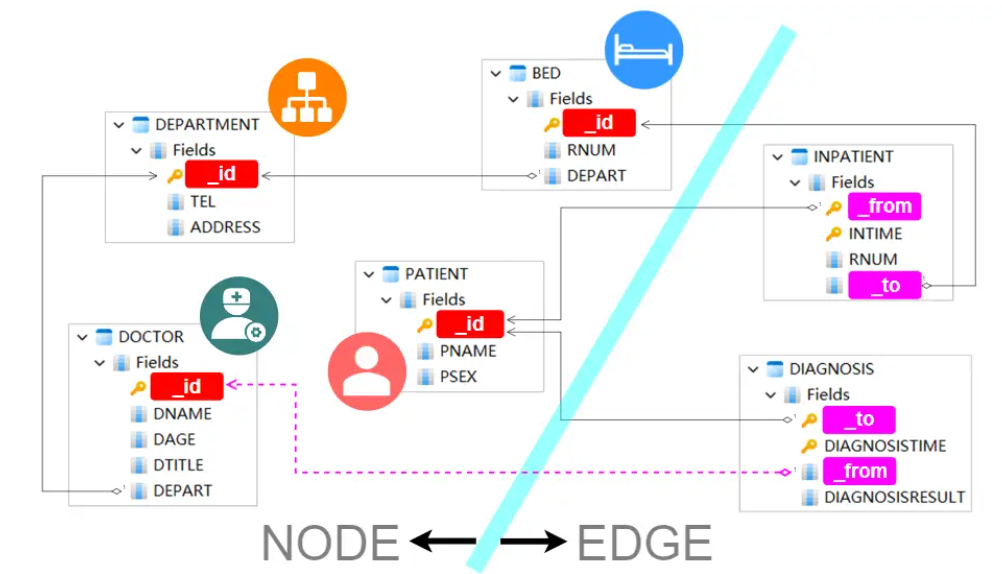
图5:节点和边的区分
不应将 INPATIENT 误解为 PATIENT 的子集,因为它捕获了 PATIENT 和 BED 之间的关系,如其两个外键所示。将 INPATIENT 定义为边,并将其两个外键指定为边的 FROM 和 TO(用 _from 和 _to 表示)。
(随意交换边缘的 FROM 和 TO,只要边缘的含义保持连贯即可。例如,将 PATIENT's _id设置为 FROM,将 BED 的 _id 设置为 TO 表示“患者签到床位”,而反之则表示“床位接收患者”。
应用类似的原理,将 DIAGNOSIS 指定为封装 DOCTOR 和 PATIENT 之间联系的边缘。在确定其 FROM 和 TO 时,通过将 DNAME 替换为 DNO 来填充链接到 DOCTOR 的缺失外键。这个缺失的链接问题之前在解释表结构时已经解决,现在已在边缘设计阶段得到纠正。
节点 ID 是从原始表的主键中提取的,而边的 FROM 和 TO 是从原始表的外键派生的,并在必要时进行补充。
好奇的人可能会想,“边有 ID 吗?答案是肯定的。事实上,我们通常使用指定为边的表的主键作为它们各自的 ID。此逻辑反映了节点 ID 的方法。但是,重点并未放在边 ID 上,因为对于边缘,FROM 和 TO 的指定具有更大的意义。
2、调整架构
如下图所示,通过引入两个新的边缘模式 WORKAT 和 BELONGTO 来解决这两个外键,这相当于在原始结构中添加两个新表:
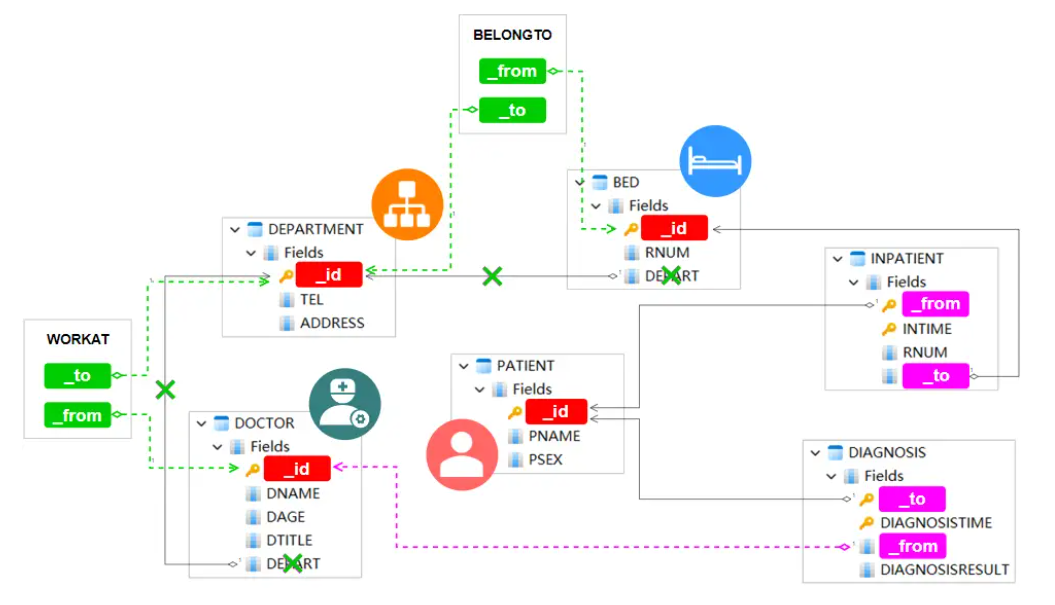
图6:引入新的边模式 WORKAT 和 BELONGTO
WORKAT 和 BELONGTO 的引入使得 DEPART 从 DOCTOR 和 BED 中删除。由于这些新模式仅使用 FROM 和 TO 进行了最小化,因此可以按需合并其他属性以适应现实场景。
到此为止,表中的所有主键和外键都已被寻址。最后一项改进是将表示房间号的 RNUM 字段从 BED 表中隔离到节点模式 ROOM 中,因为许多医院需要计算房间占用率或管理房间内的设施:
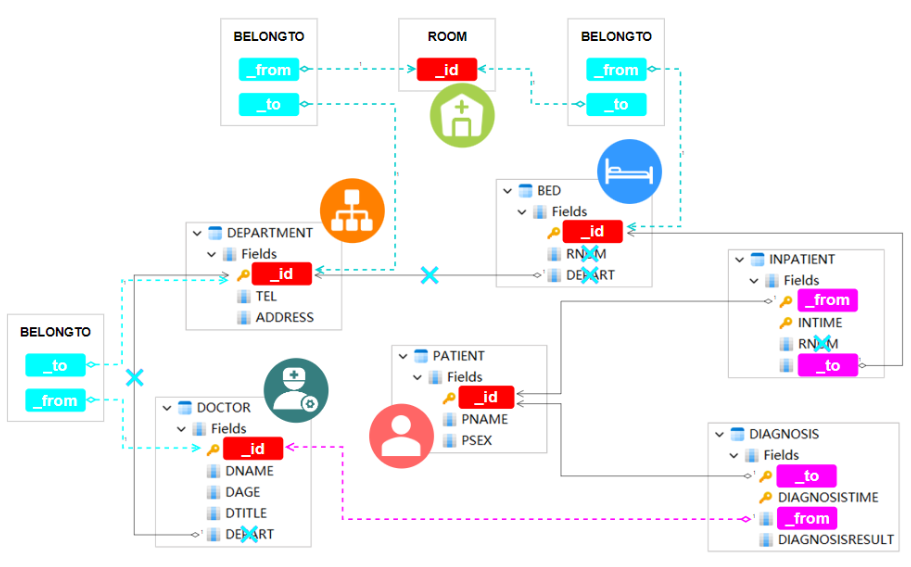
图7:抽象节点模式 ROOM 和共享边模式 BELONGTO
一些剩余步骤是:从 BED 和 INPATIENT 中删除冗余 RNUM,在 BED-ROOM、ROOM-DEPARTMENT 和 DOCTOR-DEPARTMENT 之间共享 BELONGTO,因为所有这些关系只需要属性 FROM 和 TO。
现在,根据上述建立的图模型,清理表数据并将其转换为图数据。假设每个表的数据存储为单独的 CSV 文件(例如,DOCTOR 的数据保存为 DOCTOR.csv),字段名称用作文件中的标题,则转换过程需要标题修改、列内容替换以及创建新的 CSV文件。详细步骤如下:
在 DEPARTMENT.csv、PATIENT.csv、DOCTOR.csv 和 BED.csv 中,将包含主键的列标题重命名为“_id”。
在 IMPATIENT.csv 中,将标题“PNO”重命名为“_from”,将标题“RBNUM”重命名为“_to”,并删除整个列“RNUM”。
在 DIAGNOSIS.csv 中,将标题“PNO”重命名为“_to”,将标题“DNAME”重命名为“_from”,并将“DNAME”下的数据替换为 DOCTOR.csv 中“_id”列中的相应数据。
创建带有标题“_from”和“_to”的 BELONGTO.csv。
将DOCTOR.csv中'_id'和'DEPART'下的数据复制到BELONGTO.csv中的'_from'和'_to'下,保证同一行数据的对应关系。然后,删除 DOCTOR.csv 中的整个“DEPART”列。
创建带有标题“_id.”的 ROOM.csv。将 BED.csv 中“RNUM”下的唯一值复制到 ROOM.csv 中的“_id”列。
将BED.csv中的“_id”和“RNUM”下的数据复制到BELONGTO.csv中的“_from”和“_to”中,保证同一行数据的对应关系。
将BED.csv中'RNUM'和'DEPART'下的唯一组合值复制到BELONGTO.csv中的'_from'和'_to',确保同一行数据的对应关系保持不变。然后删除 BED.csv 中的整个“RNUM”和“DEPART”列。
提醒一下,可能需要处理主键以确保其关联的 ID在整个图中是唯一的[2] 。虽然这不适用于本文中提供的数据,但这是许多用户遇到的常见挑战。
有多种方法可将图数据导入嬴图系统内的指定图集中。例如通过嬴图Manager(一种用于让用户更好管理嬴图系统的高可视化工具· 更多了解可详阅走进嬴图Manager之高可视化或搜索嬴图官网)单独上传 CSV 文件,或者通过命令行实用程序 嬴图Importer一次性批量导入所有文件。
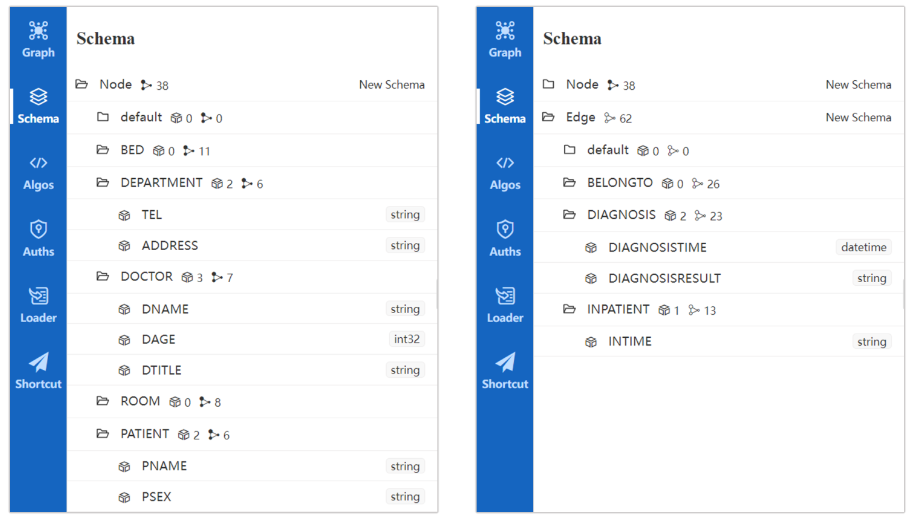
图8:图模型在嬴图Manager 中以架构和属性的形式说明
在嬴图Manager 中,ID、FROM 和 TO 在模式列表中不可见。这些是系统生成的属性,无法修改或删除。
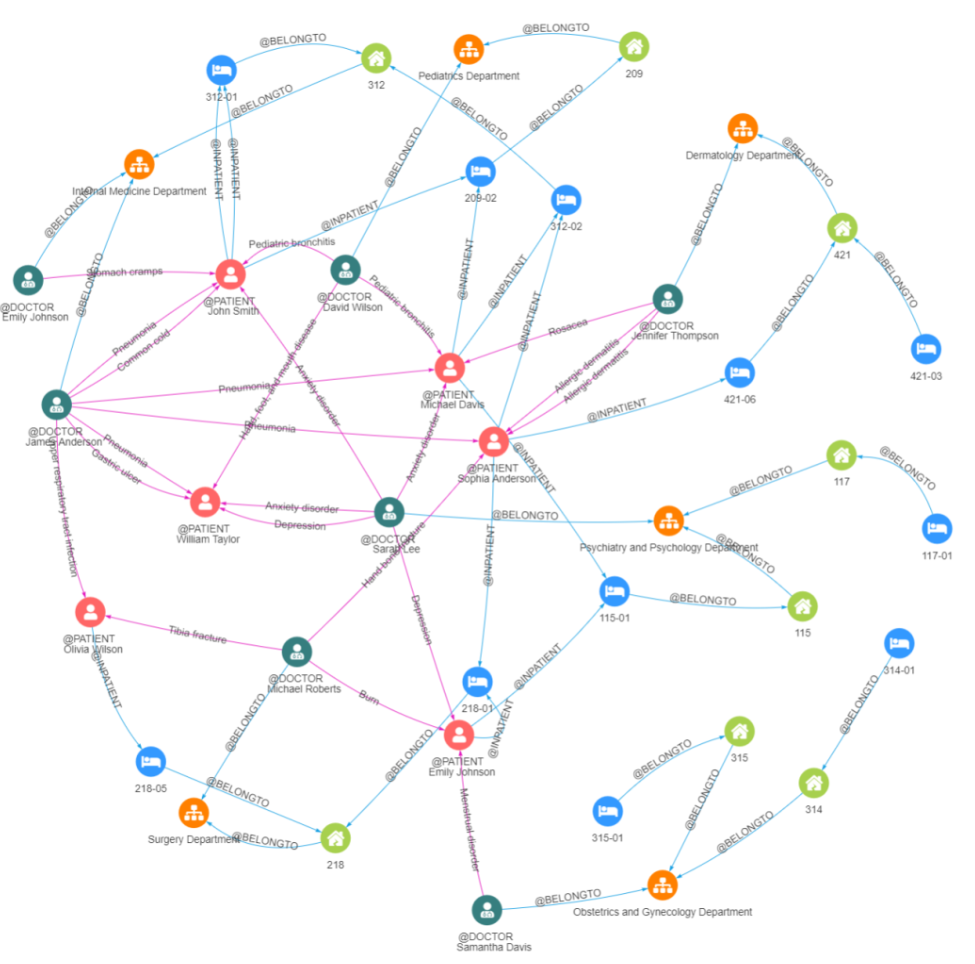
图9:嬴图Manager 中图数据的 2D 可视化
嬴图Manager 的 2D 渲染功能利用鲜艳的颜色和图标,确保不同实体之间的关系清晰可见。快速浏览可以轻松识别图中互连的节点。这种直观、方便的可视化使图数据库脱颖而出,超越了传统关系数据库的功能。它极大地增强了数据分析和探索的轻松性和乐趣。
我们相信这篇文章为图建模提供了宝贵的见解,特别是对于涉足图数据库世界的新手来说。在实际场景中,构建图模型涉及到更复杂的情况。另一方面,图模型本身并不是固定的,需要进行适应性修改以满足不断变化的业务需求。【文 wanyi】
【注释】

技术分享 | 如何使用Ultipa Graph构建网站后台数据库?
更多阅读:《图数据库原理、架构与应用》; 孙宇熙,嬴图团队;