




我们对 Claude 3 Sonnet 大模型在数据分析场景做了深入评测,结果发现:Claude 3 Sonnet 综合表现优异,尤其搭配指标平台情况下在指标计算方面可超越 GPT-4,实现“如虎添翼”的效果。
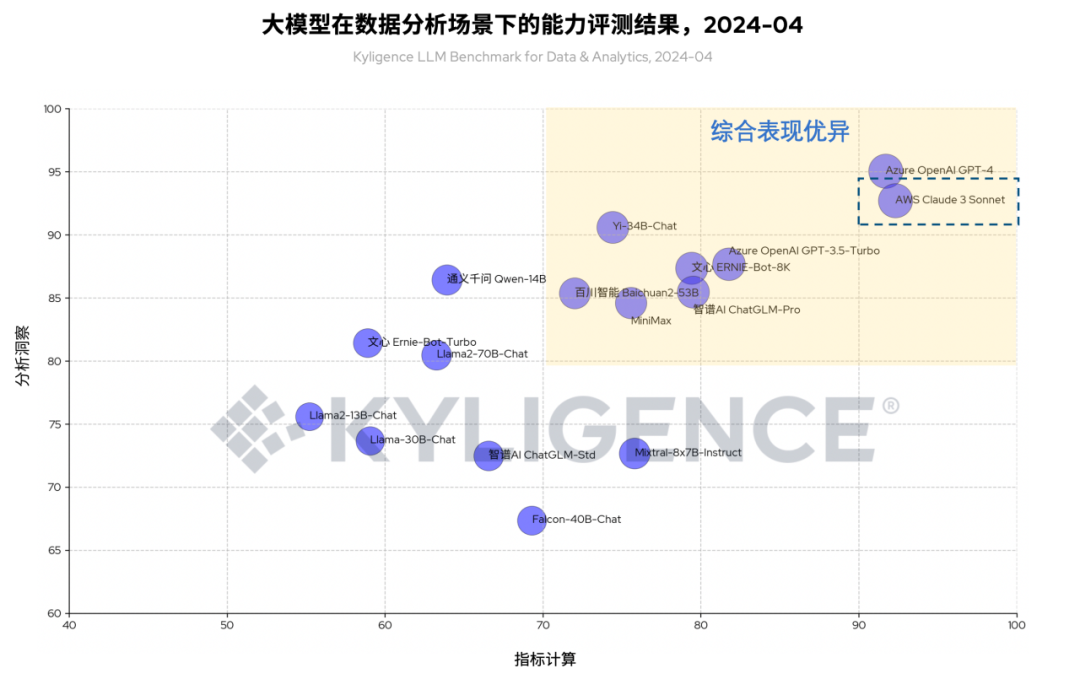
图 1 大模型在数据分析场景下的能力评测结果(虚线框为 Claude 3 Sonnet),2024-04
上图是我们以 Claude 3 Sonnet 和其他大模型在《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》框架下评测的统计结果。
今年 3 月,由 Anthropic 提供的 Claude 3 系列大模型正式登陆 AWS BedRock,该系列大模型包括 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku 三个版本,其中 Claude 3 Sonnet 的优势在于性能高、成本低,并且非常适合复杂推理、快速输出等任务。本文评测以 AWS BedRock 上的 Claude 3 Sonnet 进行评测。
#01
评测框架与方法

在《数据分析场景下的大模型能力评测框架(Kyligence LLM Benchmark for Data & Analytics)》中,我们结合来自金融、零售、制造、医药等行业应用场景的经验积累,共设置 8 个评分维度,分别是:意图识别、指标匹配、代码生成(SQL)、代码生成(指标)、洞察生成(SQL)、洞察生成(指标)、图表推荐、报告撰写。此外,根据不同维度所属阶段的不同,我们将这 8 个维度归类为指标计算、分析洞察等两个分类,以此对各个大模型进行实测评分。
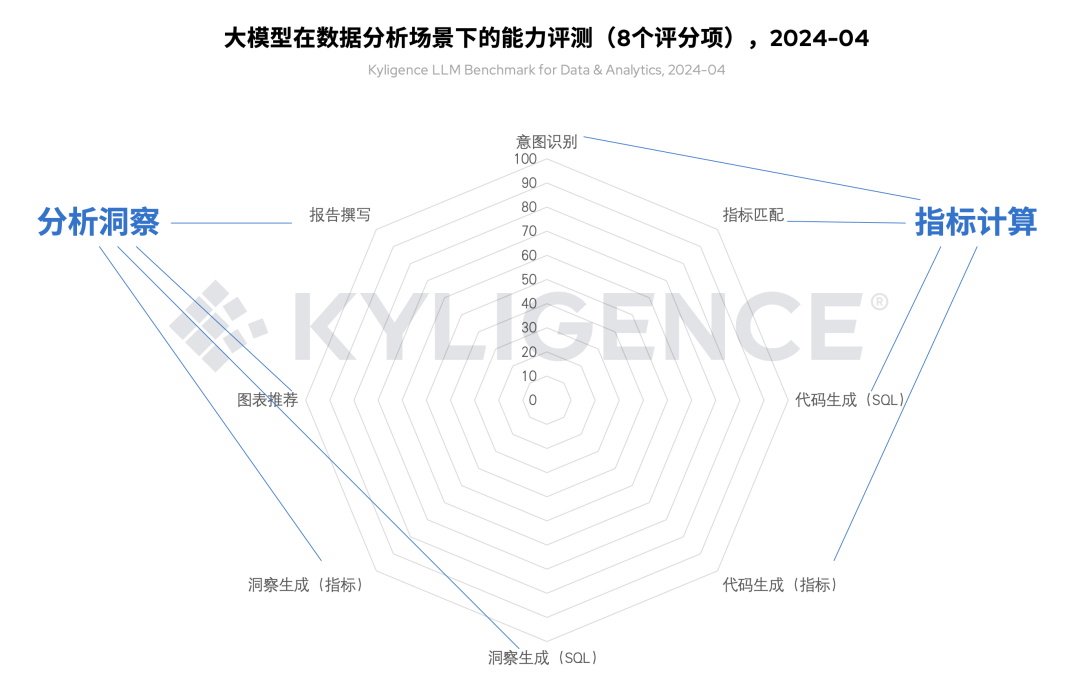
图 2 大模型在数据分析场景下的能力评测维度,2024-04
相比上一轮评测,我们基于 AWS Beckrock 着重评测了 Claude 3 Sonnet 大模型。另外,由于测试数据集更新迭代,我们也对上一轮评测的大模型进行重跑,包括 Azure OpenAI GPT-4、Azure OpenAI GPT-3.5-Turbo、智谱AI ChatGLM-Pro、Yi-34B-Chat、MiniMax、百川智能 Baichuan2-53B、通义千问 Qwen-14B、智谱AI ChatGLM-Std、Falcon-40B-Chat、文心 Ernie-Bot-Turbo、Llama-30B-Chat、Llama2-13B-Chat 等模型,最终各模型评测结果如表 1 所示:
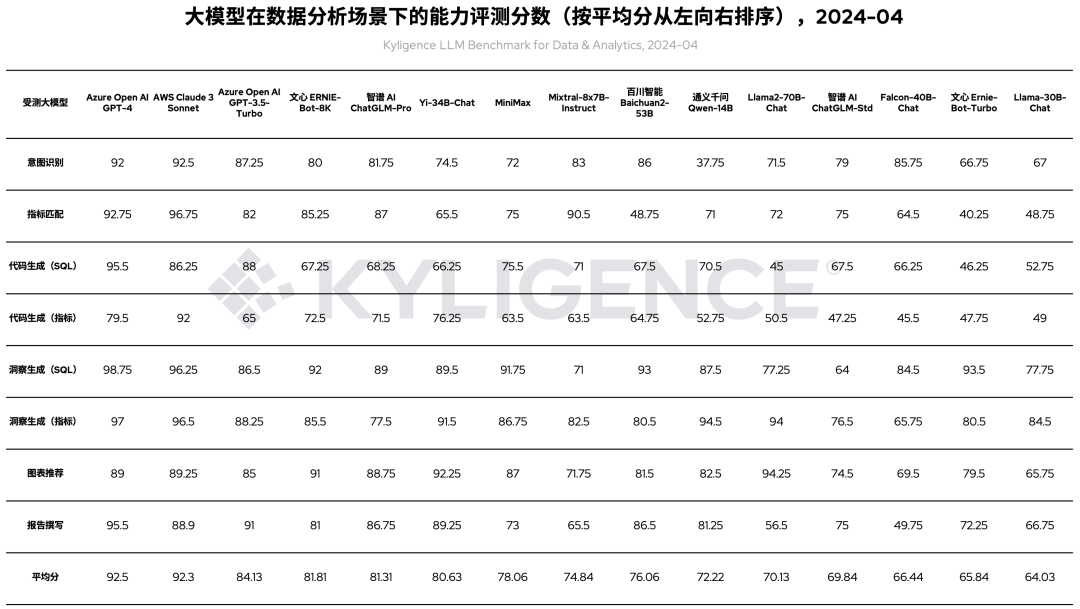
表 1 大模型在数据分析场景下的能力评测分数(按平均分从左向右排序),2024-04
评测过程中的已知限制和情况说明:
本次评测数据集基于 Kyligence Copilot 使用场景总结,可能不适用于企业所有数据分析场景
本次评测基于各大模型服务的默认配置,未进行任何调参;值得说明的一点是,对大模型服务进行调优可能进一步优化评测结果
本次评测中,Yi-34B Falcon-40B LLaMa-30B LLaMa2-13B 通义千问 Qwen-14B 是基于对应的开源模型在实验室私有化部署了本地服务,算力为 4 块 NVIDIA RTX 4090 24GB 显卡;其余大模型均基于厂商或云平台提供的 SaaS 服务,算力资源不详
#02
与 OpenAI GPT-4 对比
图 3 大模型在数据分析场景下的能力评测结果(虚线框为 Claude 3 Sonnet),2024-04
2.1 综合表现优异的大模型
根据图 3 可见,Claude 3 Sonnet 和 OpenAI GPT-4 同时位于图表右上角,说明两者在整体评分中均有较高表现,同属“综合表现优异”象限。这个象限表示大模型在数据分析场景下满足实际落地的基本要求,企业在为数据分析场景选型大模型时,可优先考虑该象限的大模型。
同时由图 3 可见,虽然 Claude 3 Sonnet 和 OpenAI GPT-4 分数领先,但国产大模型依然表现突出,且由表 2 可见,部分国产大模型在某些维度取得更高的分数。详情可见前期评测文章:
2.2 指标计算:超越 GPT-4
根据图 3 可见,Claude 3 Sonnet 相比 OpenAI GPT-4 在“指标计算”类别有更好的表现。“指标计算”类别主要体现大模型收到用户给出的自然语言指令后,通过意图识别、指标匹配、代码生成等过程,从原始数据中计算得出指标数值的过程。对于企业应用而言,数据准确性尤为重要,因为很细微的数值偏差有可能导致企业运营决策或绩效考评时出现纰漏。在本次评测中,Claude 3 Sonnet 评分更高,说明该模型可以在数据准确性方面比 GPT-4 有更好的保障。
#03
AI + 指标:怎么做到“如虎添翼”?
本章节,我们着重分析为什么 Claude 3 Sonnet 在“指标计算”方面能取得最好评分。一般而言,使用大模型做数据分析往往有两种技术实现方式:
Text-to-SQL:根据用户输入的自然语言指令,翻译成 SQL 以访问底层数据源获取数据和计算指标。在这种方式下,指标计算的准确度取决于生成 SQL 代码的准确度,如果大模型产生幻觉,极易产生指标计算错误的问题。
Text-to-Metrics:根据用户输入的自然语言指令,翻译成访问指标平台的访问请求,以直接从指标平台中获取指标结果。在这种方式下,指标计算的结果是直接从指标平台获取,而非大模型计算,因而可以避免由大模型幻觉引发的指标计算错误问题。
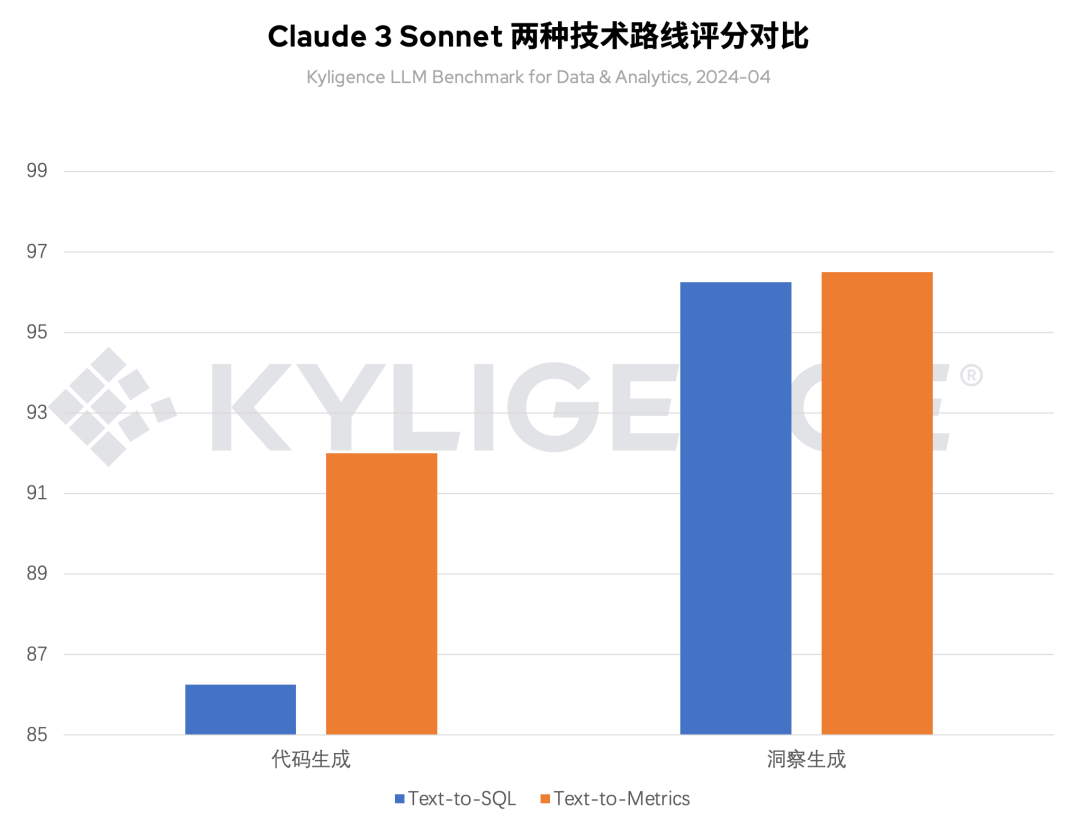
图 4 Claude 3 Sonnet 在两种技术路线下的评分对比,2024-04
如图 4 所示,在本次评测中,我们分别以两种方式测试了 Claude 3 Sonnet 在进行代码生成和洞察生成的表现:
代码生成:从评测结果可见,基于 Text-to-Metrics 的技术路线,Claude 3 Sonnet 能取得 11.6% 的分数提升,可见结合指标平台,Claude 3 Sonnet 的可靠性取得大幅提升
洞察生成:从评测结果可见,Text-to-Metrics 比 Text-to-SQL 表现略胜一筹,因为两者返回的结果均为结构化文本,而 Text-to-Metrics 因为包含更多指标语义信息,更容易被大模型理解,并以此生成更好的洞察结果
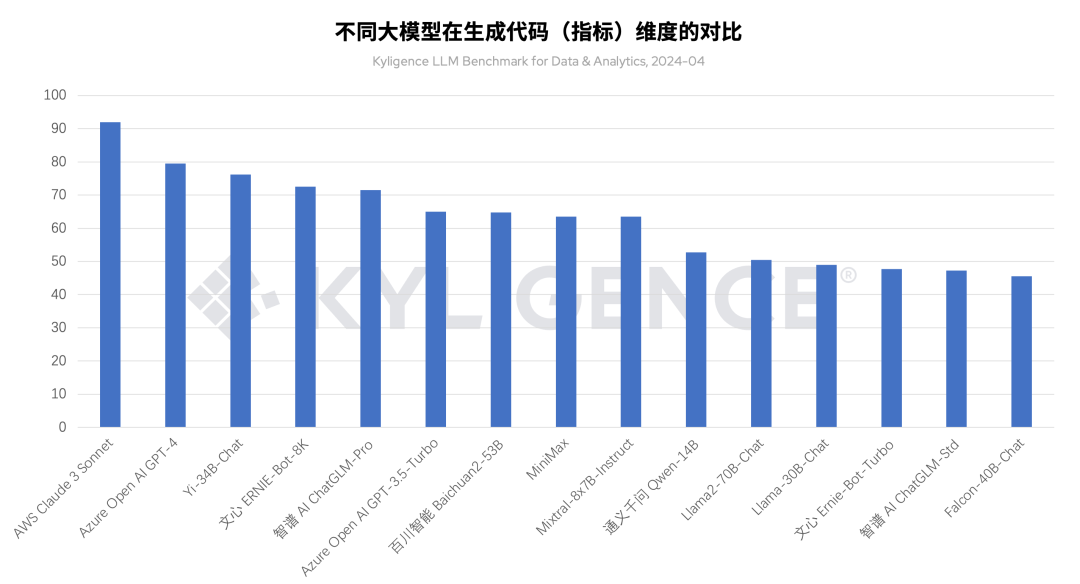
图 5 不同大模型在生成代码(指标)维度的对比,2024-04
如图 5 所示,横向对比不同大模型在 Text-to-Metrics 技术路线下,Claude 3 Sonnet 在生成代码维度上位列前茅,拥有最佳的落地表现。
#04
结语

如果您想了解“指标+AI”解决方案的更多详情,欢迎点击上图“即刻报名”参加 Kyligence 数智论坛暨春季发布会,将由 Kyligence、德勤、滔搏精彩分享这一方案的技术原理和实践案例。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售、医疗等行业客户,包括建设银行、平安银行、浦发银行、北京银行、宁波银行、太平洋保险、中国银联、上汽、长安汽车、星巴克、安踏、李宁、阿斯利康、UBS、MetLife 等全球知名企业,并和微软、亚马逊云科技、华为、安永、德勤等达成全球合作伙伴关系。Kyligence 获得来自红点、宽带资本、顺为资本、斯道资本、Coatue、浦银国际、中金资本、歌斐资产、国方资本等机构多次投资。

点击「阅读原文」即刻报名
