




定期数据更新,如周期性数据导入和 ETL 操作,减少人工干预,提高数据处理的效率和准确性。 结合 Catalog 实现外部数据源数据定期同步,确保多源数据高效、准确的整合到目标系统中,满足复杂的业务分析需求。 定期清理过期/无效数据,释放存储空间,避免过多过期/无效数据对系统性能产生影响。
引入 Job Scheduler
为解决上述问题,Apache Doris 在 2.1 版本中引入了 Job Scheduler 功能,实现了自主任务调度能力,调度的精准度可达到秒级。该功能的推出不仅保障了数据导入的完整性和一致性,更让用户能够灵活、便捷调整调度策略。同时,因减少了对外部系统的依赖,也降低了系统故障的风险和运维成本,为社区用户带来更加统一、可靠的使用体验。
高效调度:Job Scheduler 可以在指定的时间间隔内安排任务和事件,确保数据处理的高效性。采用时间轮算法保证事件能够精准做到秒级触发。 灵活调度:Job Scheduler 提供了多种调度选项,如按 分、小时、天或周的间隔进行调度,同时支持一次性调度以及循环(周期)事件调度,并且周期调度也可以指定开始时间、结束时间。 事件池和高性能处理队列:Job Scheduler 采用 Disruptor 实现高性能的生产消费者模型,最大可能的避免任务执行过载。 调度记录可追溯:Job Scheduler 会存储最新的 Task 执行记录(可配置),通过简单的命令即可查看任务执行记录,确保过程可追溯。 高可用:依托于 Doris 自身的高可用机制,Job Schedule 可以很轻松的做到自恢复、高可用。
语法及示例
01 语法说明
关键字 CREATE JOB 需加作业名称,它在数据库中标识唯一事件。 ON SCHEDULE 子句用于指定 Job 作业的类型、触发时间和频率。 AT timestamp用于一次性事件。它指定 JOB 仅在给定的日期和时间执行一次,AT CURRENT_TIMESTAMP指定当前日期和时间。因 JOB 一旦创建则会立即运行,也可用于异步任务创建。EVERY:用于周期性作业,可指定作业的执行频率,关键字后需指定时间间隔(周、天、小时、分钟)。 Interval:用于指定作业执行频率。 1 DAY表示每天执行一次,1 HOUR表示每小时执行一次,1 MINUTE表示每分钟执行一次,1 WEEK表示每周执行一次。子句 EVERY包含可选STARTS子句。STARTS后面为timestamp值,该值用于定义开始重复的时间,CURRENT_TIMESTAMP用于指定当前日期和时间。JOB 一旦创建则会立即运行。子句 EVERY包含可选ENDS子句。ENDS关键字后面为timestamp值,该值定义 JOB 事件停止运行的时间。DO 子句用于指定 Job 作业触发时所需执行的操作,目前仅支持 Insert 语句。
CREATE
JOB
job_name
ON SCHEDULE schedule
[COMMENT 'string']
DO execute_sql;
schedule: {
AT timestamp
| EVERY interval
[STARTS timestamp ]
[ENDS timestamp ]
}
interval:
quantity { WEEK |DAY | HOUR | MINUTE
}
CREATE JOB my_job ON SCHEDULE EVERY 1 MINUTE DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2; 该语句表示创建一个名为 my_job 的作业,每分钟执行一次,执行的操作是将 db2.tbl2 中的数据导入到 db1.tbl1 中。
02 举例说明
db2.tbl2 中数据导入到 db1.tbl1 中。CREATE JOB my_job ON SCHEDULE AT '2025-01-01 00:00:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2; 创建周期性的 Job,未指定结束时间:在 22025-01-01 00:00:00 时开始每天执行 1 次,将 db2.tbl2 中数据导入到 db1.tbl1 中。
CREATE JOB my_job ON SCHEDULE EVERY 1 DAY STARTS '2025-01-01 00:00:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2 WHERE create_time >= days_add(now(),-1); 创建周期性的 Job,指定结束时间:在 2025-01-01 00:00:00 时开始每天执行 1 次,将 db2.tbl2 中的数据导入到 db1.tbl1 中,在 2026-01-01 00:10:00 时结束。
CREATE JOB my_job ON SCHEDULER EVERY 1 DAY STARTS '2025-01-01 00:00:00' ENDS '2026-01-01 00:10:00' DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2 create_time >= days_add(now(),-1); db2.tbl2 中的数据导入到 db1.tbl1 中,这里只需要指定 JOB 为一次性任务,且开始时间设置为当前时间即可。CREATE JOB my_job ON SCHEDULE AT current_timestamp DO INSERT INTO db1.tbl1 SELECT * FROM db2.tbl2;
基于 Catalog 与 Job Scheduler 的数据自动同步
以某电商场景为例,用户常常需要从 MySQL 中提取业务数据,并将这些数据同步到 Doris 中进行数据分析,从而支持精准的营销活动。而 Job Scheduler 可与数据湖能力 Multi Catalog 配合,高效完成跨数据源的定期数据同步。

以上表为例,用户希望查询符合总消费金额、最后一次访问时间、性别、所在城市这几个数值条件的用户,并将满足条件的用户信息导入到 Doris 中,以便后续的定向推送。
CREATE TABLE IF NOT EXISTS user_activity
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);2. 其次,创建对应 MySQL 库的 Catalog
CREATE CATALOG activity PROPERTIES (
"type"="jdbc",
"user"="root",
"jdbc_url" = "jdbc:mysql://127.0.0.1:9734/user?useSSL=false",
"driver_url" = "mysql-connector-java-5.1.49.jar",
"driver_class" = "com.mysql.jdbc.Driver"
);
3. 最后,将 MySQL 数据导入到 Doris 中。采用 Catalog + Insert Into 的方式来导入全量数据,由于全量导入操作可能会引发系统服务波动,通常选择在业务闲暇时进行操作。
CREATE JOB one_time_load_job
ON SCHEDULE
AT '2024-8-10 03:00:00'
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity 周期调度:用户也可以创建一个周期性的调度任务,定期更新最新的数据。
CREATE JOB schedule_load
ON SCHEDULE EVERY 1 DAY
DO
INSERT INTO user_activity FROM SELECT * FROM activity.user.activity where create_time >= days_add(now(),-1)设计与实现
高效的调度通常伴随着大量的资源消耗,高精度的调度更是如此。传统的实现方式是直接使用 Java 内置的定时调度能力——定时调度线程周期访问,或采用一些定时调度的工具类库,但其在精度以及内存占用上存在较大的问题。为更好保障性能的前提下降低资源的占用,我们选择 TimingWheel 算法与 Disruptor 结合,实现秒级别的任务调度。
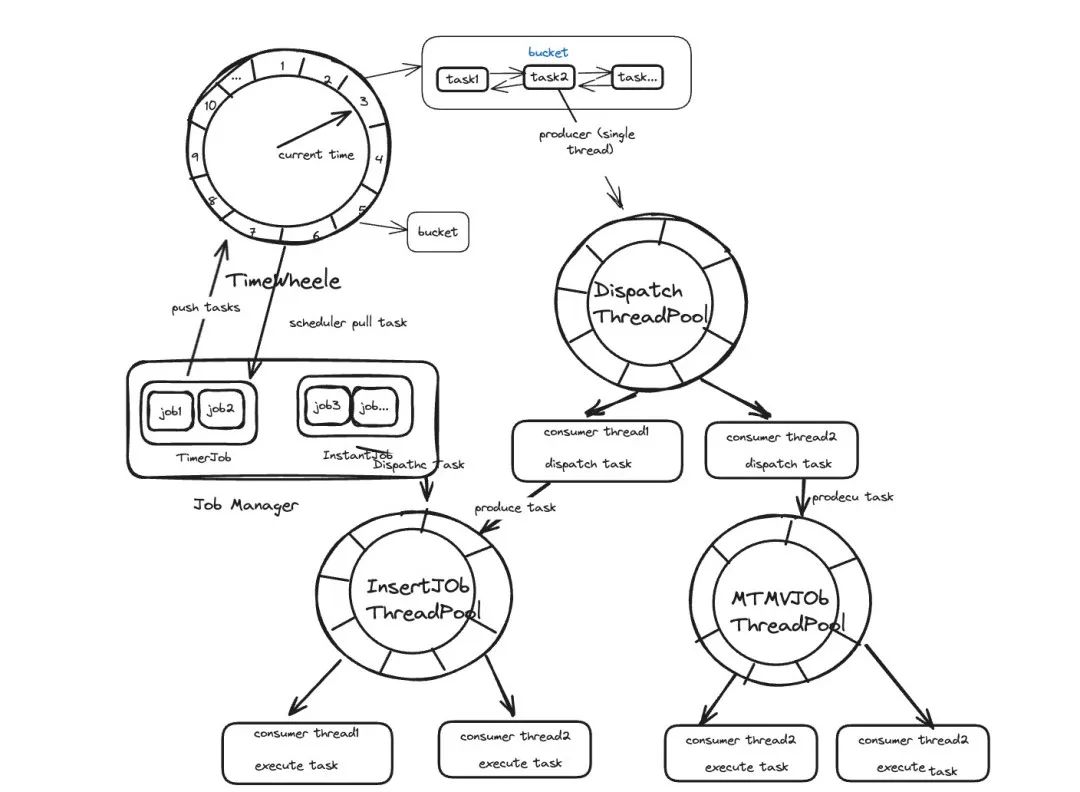
结束语
Doris Job Scheduler 是一款强大且灵活的任务调度工具,是数据处理中必不可少的功能之一。除了在数据湖分析、内部 ETL 等常见场景的应用外,Job Scheduler 对于异步物化视图的实现也起到关键的作用。异步物化视图是一个预先计算并存储的结果集,其数据更新的频率与源表的变动紧密相关。当源表数据更新频繁时,为确保物化视图中数据保持最新状态,就需要对物化视图定期刷新。因此在 2.1 版本中,我们巧妙地利用 JOB 定时调度功能,保障了物化视图与源表数据的一致性,大幅降低了人工干预的成本。
支持通过 UI 界面查看不同时段执行的任务分布情况。 支持 JOB 流程编排,即 DAG JOB。这意味着我们可以在内部实现数仓任务编排,与 Catalog 功能叠加将会更高效地完成数据处理和分析工作。 支持对导入任务、UPDATE、DELETE 操作进行定时调度。
