




前言:
上一篇为大家介绍了一些我们HaloDB 的特性,本篇正式为大家带来关于HaloDB中备份恢复的操作技巧,最近更新的有些慢,在这里给大家道个歉,确实最近有很多时间在做公司的售前技术交流工作,包括一些活动的出席,另一方面,也在考虑更新一些怎样能切实的帮助到大家的内容,也是做这个专栏的初心。很多小白朋友对备份恢复十分感兴趣,所以为大家带来本篇的分享,坐稳了,我们发车。
容我打个广告哈:
我们的HaloDB 是基于原生PG打造的新一代高性能安全自主可控全场景通用型统一数据库。业内首次创造性的提出插件式内核架构设计,通过配置的方式,适配不同的应用场景,打造全场景覆盖的能力,满足企业大部分数据存储处理需求,从而消除数据孤岛,降低系统复杂度,保护企业既有投资,降低企业成本。同时支持x86、arm等异构平台之间的混合部署。
如果有对我们的产品感兴趣的朋友可以通过主页的联系方式与我取得联系,获取license来安装体验,当然您如果有好的建议也可以提给我们,下面正式开始今天的内容。
一、什么是数据库备份:

通常情况下,一般的数据库备份按照备份方式分为物理备份和逻辑备份两个大类。物理备份顾名思义,通常指拷贝磁盘数据,或者通过数据块拷贝的方式来实现。在我们的HaloDB中,逻辑备份就是将数据库中的对象和数据转储成相应的SQL命令。
但是逻辑备份的这个机制一般不太适用于比较大的数据集的备份,而只适用于较小数据集的备份。而且逻辑备份的数据是静态的,也就意味着只能保存过去某一时间点的数据,可能与最新数据存在较大的差异。实施逻辑备份通常使用的是pg_dump命令。具体实操方式如下:
二、HaloDB中的逻辑备份
1、实验环境:
| 操作系统 | 数据库 |
|---|---|
| Centos 7.9 | HaloDB 1.0.14.10 (231130) |
2、实验步骤:
pg_dump -U your_user_name -F c -b -v -h localhost -p 1921 your_database > backup.dump详细的参数使用方式如下:
-h host,指定数据库主机名,或者IP
-p port,指定端口号
-U user,指定连接使用的用户名
-W,按提示输入密码
dbname,指定连接需要备份的数据库名称。
-a,–data-only,只导出数据,不导出表结构
-c,–clean,是否生成清理该数据库对象的语句,比如drop table
-C,–create,是否输出一条创建数据库语句
-f file,–file=file,输出到指定文件中
-n schema,–schema=schema,只转存匹配schema的模式内容
-N schema,–exclude-schema=schema,不转存匹配schema的模式内容
备份如下:
示例1:备份HaloDB下的halozz数据库,并且以dump文件存储。
[halo@halodb1 ~]$ pg_dump -v -d halozz > halo_zz.dump
pg_dump: last built-in OID is 16383
pg_dump: reading extensions
pg_dump: identifying extension members
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: reading schemas
.......
pg_dump: saving encoding = UTF8
pg_dump: saving standard_conforming_strings = on
pg_dump: saving search_path = pg_catalog
pg_dump: implied data-only restore
我们简单看下生成的demo.dump文件的内容。
文件的开头是头部信息,主要内容为版本信息以及字符集信息。因为是空库所以没用更多信息。那我们建立一张测试表,继续观察有什么变化。
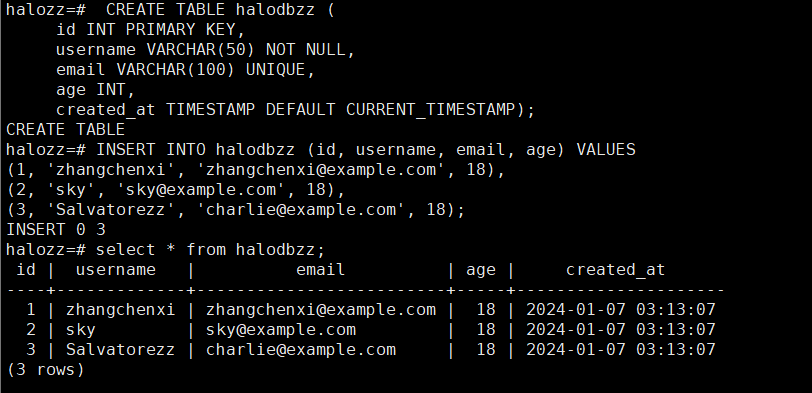
这个测试用例之前的文章有使用过,语句如下,方便大家粘贴
CREATE TABLE halodbzz (
id INT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
age INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP);
INSERT INTO halodbzz (id, username, email, age) VALUES
(1, 'zhangchenxi', 'zhangchenxi@example.com', 18),
(2, 'sky', 'sky@example.com', 18),
(3, 'Salvatorezz', 'charlie@example.com', 18);重新备份该数据库,再次查看dump文件,如图所示:
如下述两张图所示,我们可以发现,在dump文件中,记录了我们的SQL操作过程。在dump文件中,头部信息后基本都是些数据对象及数据。
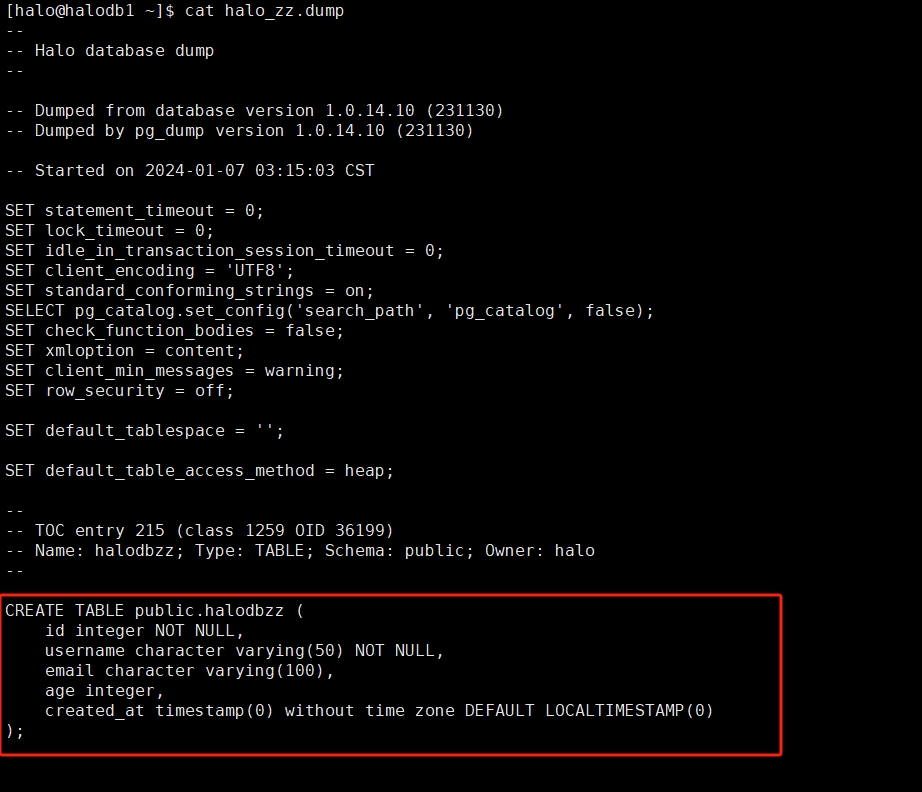
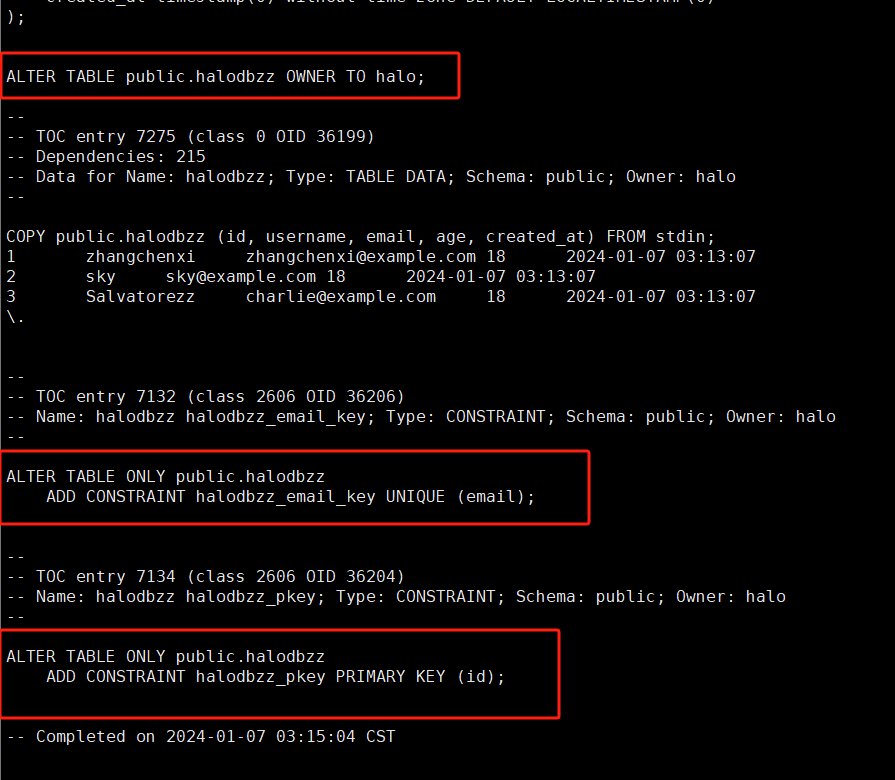
我们仔细观察可以发现,数据采用了COPY方式,当然也可以导出为INSERT,需要在pg_dump命令中加上—inserts指令。如果不是用于跨平台的数据迁移,建议还是使用COPY,该方式拥有更高的性能。当然逻辑备份也支持只对部分表进行备份,这也是逻辑备份的优点之一。下面用一个小例子来展示下,就备份我刚才所创建的测试表halodbzz。
示例2:导出HaloDB的单张表,以.sql格式存储
导出语句如下:
[halo@halodb1 ~]$ pg_dump -d halozz -t halodbzz > zz.sql
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
........
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1
pg_dump: NOTICE: >>>> fxu-debug GenericType1截图如下:
sql文件如下,各位请参考:
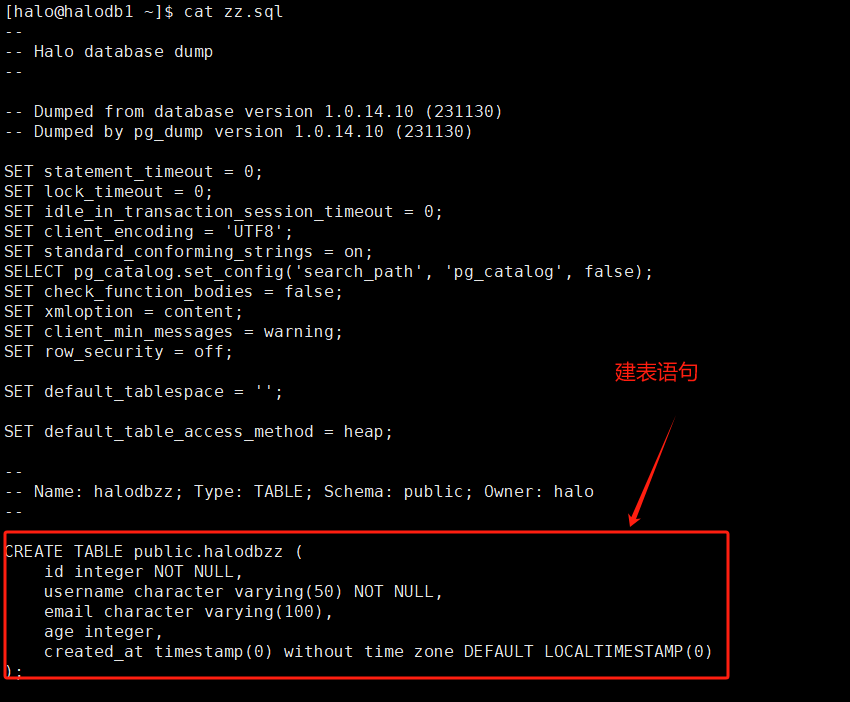
当然除此之外,pg_dump 还支持仅导出表结构,导出数据库单独排除某张表等操作,总体来说,使用较为灵活方便。由于篇幅原因,不做详细展示,我提供命令,各位可以自己动手操作,学习数据库,最好的办法,动手操作!薛老师曾经说过一句话,好的DBA都是用失败的经验堆积起来的,各位共勉。
pg_dump -d (你的数据库名称)-s > (自定义文件名).sqlHaloDB仅导出数据,不导出表结构
pg_dump -d (你的数据库名称) --inserts -a > (自定义文件名).sqlHaloDB数据库,导出某个数据库但是排除某张表
pg_dump -d (连接的数据库名称) -T (排除的表名称) --inserts >(自定义文件名称).sql三、HaloDB中的物理备份
1、初始化备份路径:
$ export BACKUP_PATH=/data/halo_backup
$ rman init
2、开始物理备份:
$ rman backup -b full --validate-backup
3、备份归档日志
$ rman backup -b archive --validate-backup物理备份先给大家做个小小的铺垫,在后面的文章为大家展开。
最后:
虽然是慢工,但是不是什么细活,
