




搭建集群
服务器列表
| HOSTNAME | IP | 用途 |
|---|---|---|
| sqlnode1 | 192.168.130.110 | SQLNode |
| sqlnode2 | 192.168.130.111 | SQLNode |
| sqlnode3 | 192.168.130.112 | SQLNode |
| datanode1 | 192.168.130.113 | DataNode |
| datanode2 | 192.168.130.114 | DataNode |
| datanode3 | 192.168.130.115 | DataNode |
本次部署的详细拓扑图和端口如下所示:

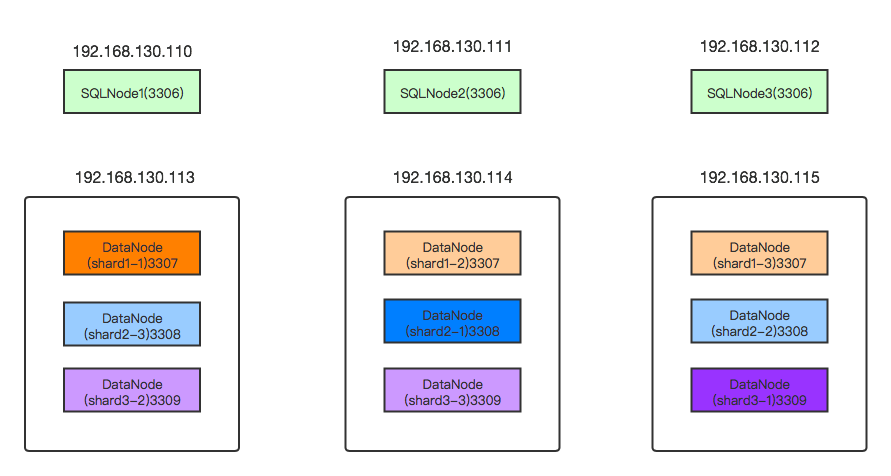
上图中括号中的数字表示对应实例的端口号。
目录规划
SQLNode和DataNode均需要设置配置文件和数据目录。SQLNode的数据目录用于存放集群元数据,DataNode数据目录用于存放用户数据。
为了方便管理,我们统一将配置文件设置在/etc/greatdb-cluster目录下,数据目录设置在/var/lib/greatdb-cluster目录下。
shell> mkdir /var/lib/greatdb-cluster
shell> mkdir /etc/greatdb-cluster
每个节点和文件及目录的对应关系如下:
| 机器 | 实例 | 配置文件 | 数据目录 |
|---|---|---|---|
| sqlnode1 | greatsqld(3306) | /etc/greatdb-cluster/3306.cnf | /var/lib/greatdb-cluster/3306 |
| sqlnode2 | greatsqld(3306) | /etc/greatdb-cluster/3306.cnf | /var/lib/greatdb-cluster/3306 |
| sqlnode3 | greatsqld(3306) | /etc/greatdb-cluster/3306.cnf | /var/lib/greatdb-cluster/3306 |
| datanode1 | greatdbd(3307) | /etc/greatdb-cluster/3307.cnf | /var/lib/greatdb-cluster/3307 |
| datanode1 | greatdbd(3308) | /etc/greatdb-cluster/3308.cnf | /var/lib/greatdb-cluster/3308 |
| datanode1 | greatdbd(3309) | /etc/greatdb-cluster/3309.cnf | /var/lib/greatdb-cluster/3309 |
| datanode2 | greatdbd(3307) | /etc/greatdb-cluster/3307.cnf | /var/lib/greatdb-cluster/3307 |
| datanode2 | greatdbd(3308) | /etc/greatdb-cluster/3308.cnf | /var/lib/greatdb-cluster/3308 |
| datanode2 | greatdbd(3309) | /etc/greatdb-cluster/3309.cnf | /var/lib/greatdb-cluster/3309 |
| datanode3 | greatdbd(3307) | /etc/greatdb-cluster/3307.cnf | /var/lib/greatdb-cluster/3307 |
| datanode3 | greatdbd(3308) | /etc/greatdb-cluster/3308.cnf | /var/lib/greatdb-cluster/3308 |
| datanode3 | greatdbd(3309) | /etc/greatdb-cluster/3309.cnf | /var/lib/greatdb-cluster/3309 |
配置文件模板
SQLNode和DataNode的配置文件模板与MySQL配置方式一致,为了简化生成配置文件的复杂度,我们针对单机快速部署提供如下bash脚本create_config.sh,内容如下。
#!/bin/bash
set -ex
ip=$1
port=$2
echo "[mysqld]
datadir=/var/lib/greatdb-cluster/$port
socket=/var/lib/greatdb-cluster/$port/greatdb.sock
user=greatdb
port=$2
server_id=$RANDOM
max_connections=1000
report-host=$1
## group replication configuration
binlog-checksum=NONE
enforce-gtid-consistency
gtid-mode=ON
loose-group_replication_start_on_boot=OFF
loose_group_replication_recovery_get_public_key=ON
loose-group_replication_local_address= \"$1:1$2\""
此模板接收两个参数,node名称和端口号,这里使用create_config.sh创建不同节点的配置文件。
# 在sqlnode1上生成计算实例的配置文件
bash create_config.sh 192.168.130.110 3306 > /etc/greatdb-cluster/3306.cnf
# 在sqlnode2上生成计算实例的配置文件
bash create_config.sh 192.168.130.111 3306 > /etc/greatdb-cluster/3306.cnf
# 在sqlnode3上生成计算实例的配置文件
bash create_config.sh 192.168.130.112 3306 > /etc/greatdb-cluster/3306.cnf
## 在datanode1上生成数据节点的配置文件
bash create_config.sh 192.168.130.113 3307 > /etc/greatdb-cluster/3307.cnf
bash create_config.sh 192.168.130.113 3308 > /etc/greatdb-cluster/3308.cnf
bash create_config.sh 192.168.130.113 3309 > /etc/greatdb-cluster/3309.cnf
## 在datanode2上生成数据节点的配置文件
bash create_config.sh 192.168.130.114 3307 > /etc/greatdb-cluster/3307.cnf
bash create_config.sh 192.168.130.114 3308 > /etc/greatdb-cluster/3308.cnf
bash create_config.sh 192.168.130.114 3309 > /etc/greatdb-cluster/3309.cnf
## 在datanode3上生成数据节点的配置文件
bash create_config.sh 192.168.130.115 3307 > /etc/greatdb-cluster/3307.cnf
bash create_config.sh 192.168.130.115 3308 > /etc/greatdb-cluster/3308.cnf
bash create_config.sh 192.168.130.115 3309 > /etc/greatdb-cluster/3309.cnf
从上面可以看出,SQLNode和DataNode配置是一样的,只有datadir, socket, port, loose-group_replication_local_address,server_id这几个参数需要根据各自的数据目录,端口号等进行配置。
loose-group_replication_local_address这个参数需要进行配置,保证端口号不冲突,此参数用于集群内部的group replication的设置,用户只需要设置这一个参数即可。
max_connections可以尽量设置大点,如果超过最大句柄数限制,可以通过ulimit -n unlimited进行调整。
优化配置选项
生成配置文件后,需要根据机器的配置以及单台物理机器上的实例数,对配置文件中的选项进行优化。需要重点关注如下几个选项的配置:
| 选项名 | 建议值 | 备注 |
|---|---|---|
| backlog | 100 | 同时接收最大建立连接数 |
| bind-address | 0.0.0.0 | 监听地址 |
| max_connections | 1000 | 最大连接数上限 |
| character_set_server | utf8mb4 | 字符集相关 |
| collation_server | utf8mb4_general_ci | 字符集相关 |
| max_allowed_packet | 32M | 包最大限制 |
| skip_name_resolve | 1 | 地址解析 |
| table_definition_cache | 4096 | 字典缓存 |
| table_open_cache | 4096 | table缓存 |
| innodb_buffer_pool_size | sqlnode物理机器内存30% datanode 中主副本占物理内存50%,其它副本占物理内存15% | 根据具体场景可以适当调整 |
| innodb_buffer_pool_instances | 16 | |
| innodb_flush_method | O_DIRECT | |
| innodb_purge_threads | 4 | |
| innodb_read_io_threads | 8 | |
| innodb_write_io_threads | 8 | |
| innodb_thread_concurrency | 设置为CPU核数的2倍 | 如果开启了线程池功能,这个参数可以设置为0 |
| innodb_flush_log_at_trx_commit | 1 | 根据具体场景可以适当调整 |
| sync_binlog | 1 | 根据具体场景可以适当调整 |
| group_replication_ip_whitelist | AUTOMATIC(默认值),或者内网IP,或者子网,如172.16.70.1/24 | 如果配置默认值 AUTOMATIC,集群允许所有的节点加入集群 如果配置为内网IP集合,或者子网集合,则只允许符合IP条件的节点加入集群 |
初始启动节点
创建好各自的配置文件后,直接使用greatdb_init初始化各个节点,greatdb_init会自动初始化数据库节点实例,并启动实例。
初始启动SQLNode
在sqlnode1,sqlnode2,sqlnode3上,分别进入/usr/local/greatdb-cluster目录,使用greatdb_init初始并启动SQLNode。
## 在sqlnode1上初始化计算实例的数据目录
[root@sqlnode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode
## 在sqlnode2上初始化计算实例的数据目录
[root@sqlnode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode
## 在sqlnode3上初始化计算实例的数据目录
[root@sqlnode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3306.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=sqlnode
初始启动DataNode
在datanode1,datanode2,datanode3上,分别进入/usr/local/greatdb-cluster目录,使用greatdbd初始化DataNode的数据目录。
## 在datanode1上初始化数据节点的数据目录
[root@datanode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode1]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3309.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
## 在datanode2上初始化数据节点的数据目录
[root@datanode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode2]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3309.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
## 在datanode3上初始化数据节点的数据目录
[root@datanode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3307.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3308.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
[root@datanode3]# bin/greatdb_init --defaults-file=/etc/greatdb-cluster/3309.cnf --cluster-user=greatdb --cluster-host=% --cluster-password=greatdb --node-type=datanode
创建集群
使用root登陆任意一个SQLNode,进行初始化集群操作,随后进行添加SQLNode和DataNode的操作,这里以sqlnode1作为初始化节点。
## 登陆sqlnode1
[root@localhost greatdb-cluster]# bin/greatsql -h127.0.0.1 -P3306 -uroot
## 初始化集群
GreatDB Cluster> call mysql.greatdb_init_cluster('greatdb_cluster', 'greatdb', 'greatdb');
Query OK, 1 row affected (4.24 sec)
## 添加SQLNodesqlnode2
GreatDB Cluster> call mysql.greatdb_add_sqlnode('192.168.130.111', 3306);
## 添加SQLNodesqlnode3
GreatDB Cluster> call mysql.greatdb_add_sqlnode('192.168.130.112', 3306);
Query OK, 1 row affected (4.24 sec)
## 添加shard1的数据节点并初始化
GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn1', '192.168.130.113', 3307, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn2', '192.168.130.114', 3307, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard1', 'sd1_dn3', '192.168.130.115', 3307, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_init_shard('shard1');
Query OK, 1 row affected (4.24 sec)
## 添加shard2的数据节点并初始化
GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn2', '192.168.130.114', 3308, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn3', '192.168.130.115', 3308, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard2', 'sd2_dn1', '192.168.130.113', 3308, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_init_shard('shard2');
Query OK, 1 row affected (4.24 sec)
## 添加shard3的数据节点并初始化
GreatDB Cluster> call mysql.greatdb_add_datanode('shard3', 'sd3_dn3', '192.168.130.115', 3309, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard3', 'sd3_dn1', '192.168.130.113', 3309, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_add_datanode('shard3', 'sd3_dn2', '192.168.130.114', 3309, 'NODE_MGR');
Query OK, 1 row affected (0.03 sec)
GreatDB Cluster> call mysql.greatdb_init_shard('shard3');
Query OK, 1 row affected (4.24 sec)
至此,整个集群变搭建完成,用户可以通过连接SQLNode,把整个集群当成单机MySQL使用。
如果向集群中添加sqlnode/datanode时,提示:"the time diff of the new datanode and the cluster exceeded xxx ms" 或者 "the time diff of the new sqlnode and the cluster exceeded xxx ms"时,参考 添加sqlnode/datanode失败
