




Date Finished: 2024-04-11
《postgresql_internals-14》
1、B-tree索引重要的特性:
- balanced:搜索任何值都需要相同的时间
- 多分支的:depth深度小
- ordered:数据存储是有序的(非递增或非递减),且叶子节点是双链的
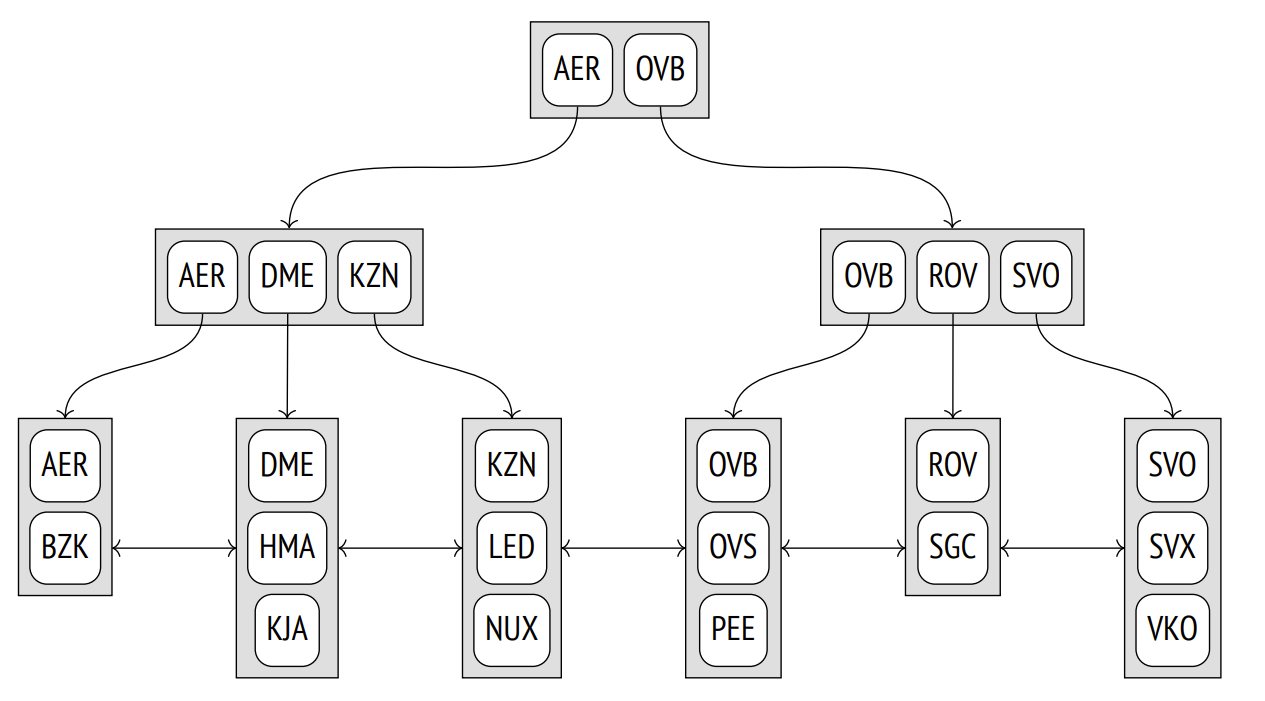
2、插入的例子:
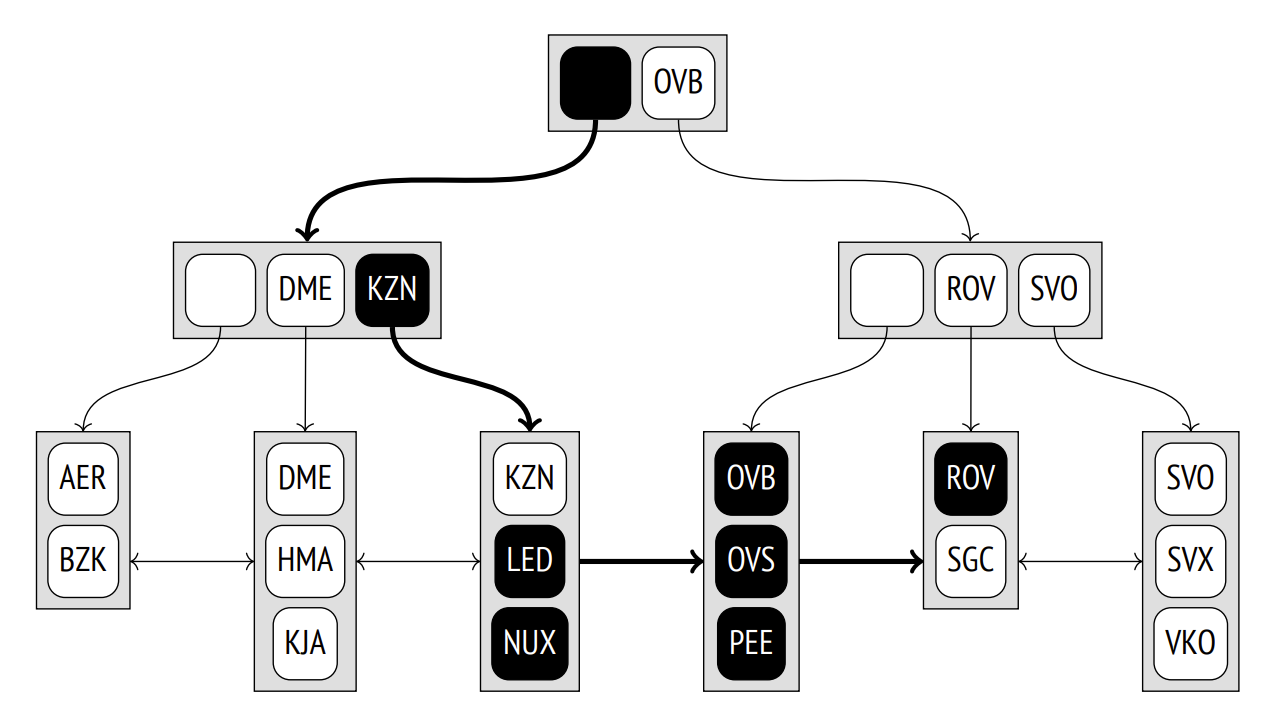
插入数据:TJM。TJM插入最后一个leaf node,overfilled -> split 成两个 -> 父节点 overfilled -> split 成两个 -> root 节点。
如果根节点需要split,分裂后的成为新的root节点,且树的深度(depth)会增加。
插入后的索引:
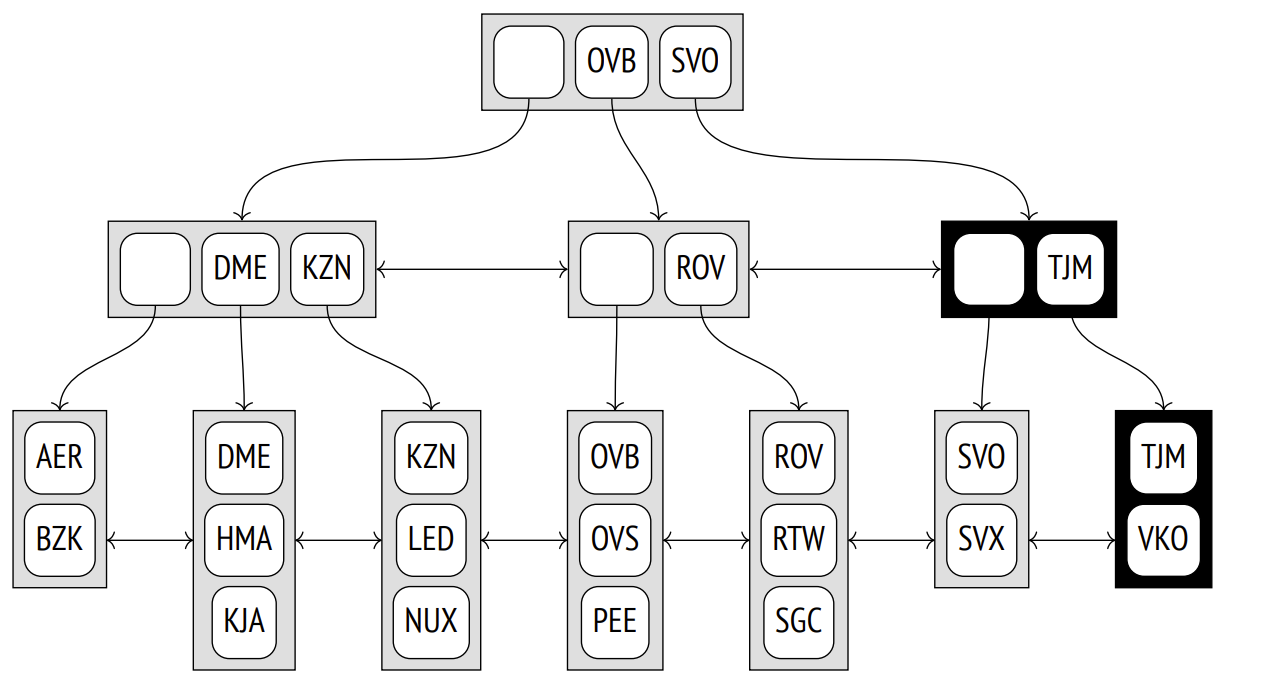
注意:节点一旦发生split,不会再发生合并。所以当尝试插入时发现full,首先会尝试进行修剪掉多余的数据来清理空间,避免额外的split
3、Deduplication
1)non-unique indexes(非唯一索引)
非唯一索引存在指向不同堆元组的重复数据,多次出现的重复数据会造成空间的浪费。为了解决这一问题,重复的数据放在同一个索引条目中。deduplication可以减少索引的大小。
=> SELECT itemoffset, htid, left(tids::text,27) tids, data_to_text(data) AS data FROM bt_page_items('tickets_book_ref_idx',1) WHERE itemoffset > 1;
itemoffset | htid | tids | data
−−−−−−−−−−−−+−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−--−+−−−−−−−−
2 | (32965,40) | | 000004
3 | (47429,51) | | 00000F
4 | (3648,56) | {"(3648,56)","(3648,57)"} | 000010
5 | (6498,47) | | 000012
...
271 | (21492,46) | | 000890
272 | (26601,57) | {"(26601,57)","(26601,58)"} | 0008AC
273 | (25669,37) | | 0008B6
(272 rows)
2)unique indexes(唯一索引)
由于MVCC的原因,唯一索引也可能存在重复的数据。HOT更新可以减少由于row version引起的索引膨胀
只有当叶子节点没有足够的空间来容纳新元组时,才会使用deduplication来处理重复数据。如果重复数据比较少,也可通过关闭deduplicate_items禁用
索引是否支持deduplication,主要的限制是:是否可以通过简单的二元比较来检查键的相等性
metapage的allequalimage字段可以查看索引是否可以使用deduplication:
=> CREATE INDEX ON tickets(book_ref);
=> SELECT allequalimage FROM bt_metap('tickets_book_ref_idx');
allequalimage
−−−−−−−−−−−−−−−
t
(1 row)
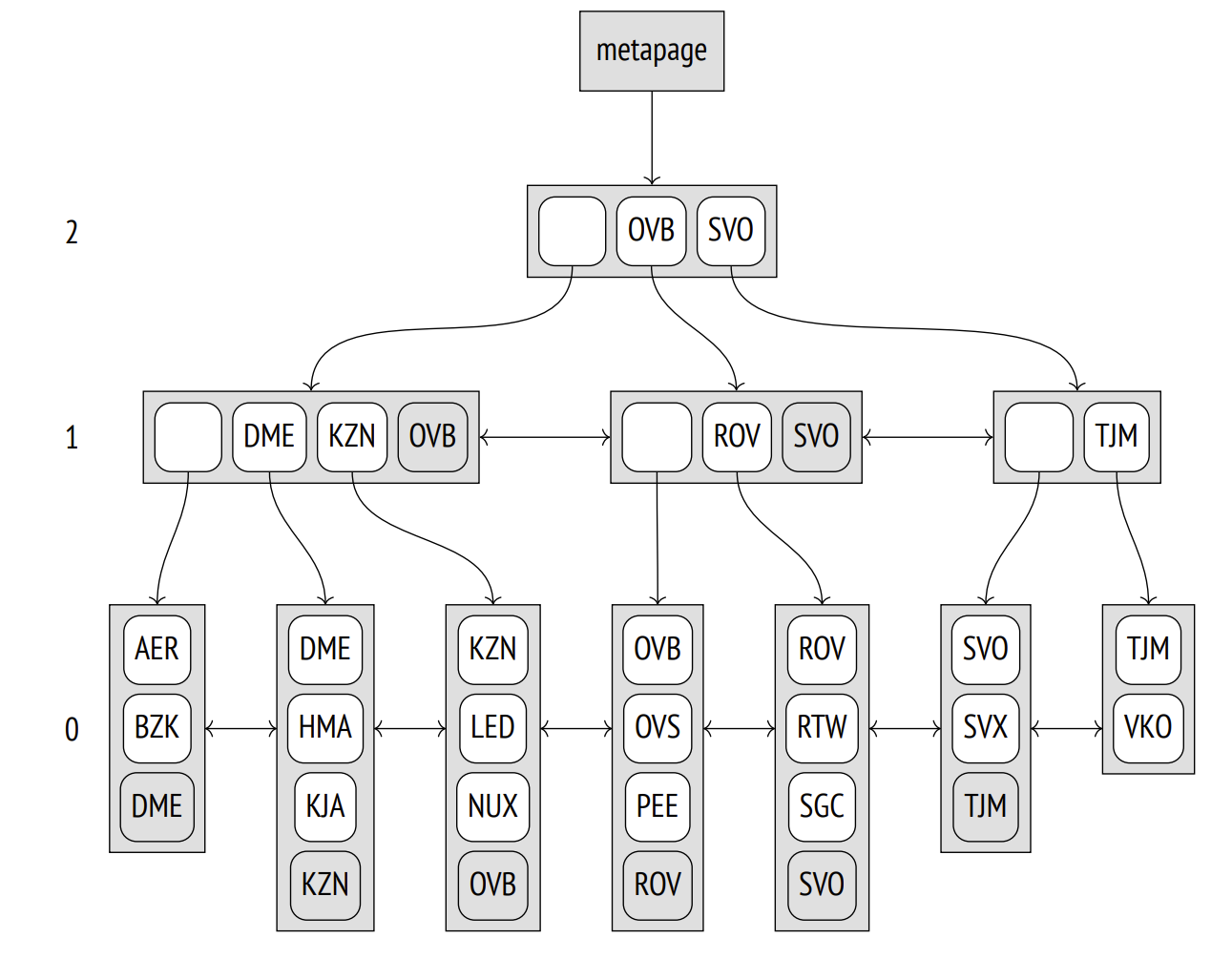
4、页面布局 - Page Layout
1)B-tree索引的每个节点占用一个page
2)metapage:零号页面,包含root page的ID
=> SELECT root, level
FROM bt_metap('bookings_pkey');
root | level
−−−−−−+−−−−−−−
290 | 2
(1 row)
3)先从root page进行查找
4)除了最右边的节点,其他所有节点都包含一个“high key”,表示在这个page中所有的数据都小于它。(下图中标深色的key)
"high key"在第一行,以避免每次页面内容更改时都移动它
=> SELECT itemoffset, ctid, data_to_text(data)
FROM bt_page_items('bookings_pkey',5135);
itemoffset | ctid | data_to_text
−−−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−−−
1 | (5417,1) | EF6FEA <------ high key
2 | (5132,0) |
3 | (5133,1) | E2D71D
4 | (5134,1) | E2E2F4
5 | (5136,1) | E2EDE7
...
282 | (5413,1) | EF41BE
283 | (5414,1) | EF4D69
284 | (5415,1) | EF58D4
285 | (5416,1) | EF6410
(285 rows)
5、操作符 - Operator Class
=> SELECT amopopr::regoperator AS opfamily_operator,
case when amopstrategy = '1' then 'less than'
when amopstrategy = '2' then 'less than or equal to'
when amopstrategy = '3' then 'equal to'
when amopstrategy = '4' then 'greater than or equal to'
when amopstrategy = '5' then 'greater than' END as strategies
FROM pg_am am
JOIN pg_opfamily opf ON opfmethod = am.oid
JOIN pg_amop amop ON amopfamily = opf.oid
WHERE amname = 'btree'
AND opfname = 'bool_ops'
ORDER BY amopstrategy;
opfamily_operator | strategies
---------------------+--------------------------
<(boolean,boolean) | less than
<=(boolean,boolean) | less than or equal to
=(boolean,boolean) | equal to
>=(boolean,boolean) | greater than or equal to
>(boolean,boolean) | greater than
(5 rows)
6、属性 - Properties
1)Access Method Properties
- can_order:对数据进行排序
- can_unique:是否唯一
- can_multi_col:支持多列的索引
- can_exclude:支持exclusive 约束
- can_include:INCLUDE 列
=> SELECT a.amname, p.name, pg_indexam_has_property(a.oid, p.name)
FROM pg_am a, unnest(array[
'can_order', 'can_unique', 'can_multi_col',
'can_exclude', 'can_include'
]) p(name)
WHERE a.amname = 'btree';
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
btree | can_order | t
btree | can_unique | t
btree | can_multi_col | t
btree | can_exclude | t
btree | can_include | t
(5 rows)
2)Index-Level Properties
- clusterable:CLUSTER
- index_scan:支持 index scan
- bitmap_scan:支持 bitmap scan
- backward_scan:由于叶子节点是双向的,也支持相反的排序
=> SELECT p.name, pg_index_has_property('flights_pkey', p.name)
FROM unnest(array[
'clusterable', 'index_scan', 'bitmap_scan', 'backward_scan'
]) p(name);
name | pg_index_has_property
---------------+-----------------------
clusterable | t
index_scan | t
bitmap_scan | t
backward_scan | t
=> EXPLAIN (costs off) SELECT * FROM bookings ORDER BY book_ref DESC;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Index Scan Backward using bookings_pkey on bookings
(1 row)
3)Column-Level Properties
- orderable:orderable属性表示数据是有序的(asc,desc)
- nulls_first/nulls_last:默认nulls_last,NULL是最大值
- search_nulls:NULL值也会被查找
- distance_orderable
- search_array:支持数组的查询
- returnable:可以返回结果而无需访问heap
=> SELECT p.name,
pg_index_column_has_property('flights_pkey', 1, p.name)
FROM unnest(array[
'asc', 'desc', 'nulls_first', 'nulls_last', 'orderable',
'distance_orderable', 'returnable', 'search_array', 'search_nulls'
]) p(name);
name | pg_index_column_has_property
--------------------+------------------------------
asc | t
desc | f
nulls_first | f
nulls_last | t
orderable | t
distance_orderable | f
returnable | t
search_array | t
search_nulls | t
