




1)使用LDS数据导入导出功能,需保证服务器数据目录所在磁盘空间足够大,建议至少保证磁盘剩余空间是数据文件大小的两倍以上。
2)若使用文件传输协议模式需要确认所在服务器FTP服务开启,使用如下命令检测:
[manager@dbmgr02 ~]$ service vsftpd status
vsftpd (pid 2208) is running...
命令结果显示FTP服务处于开启状态。
若使用SFTP 服务,默认系统已开启,可直接使用。
LoadServer执行导入导出任务时,需要与MetadataServer,ClusterManager模块进行通信,必须保证以上模块运行正常。可在以上模块安装用户下执行如下命令检测模块运行状态。该命令显示,以上三个模块运行正常。
[manager@dbmgr02 ~]$ dbstate
[metadataserver]The metadataserver process is running, PID:6263
[clustermanager]The clustermanager process is running, PID:6589
[ommagent]The ommagent process is running, PID:6881
在安装用户执行dbtool -loadserver -ls命令检测与MDS、CM节点的通信状态。执行命令结果包含~success~表示LINKON表示通信正常。
1) 该数据目录一般位于用户主目录下的 loaddata (具体依赖配置文件 loadserver.ini),主要用来存放LoadServer 工作工程中产生的数据文件。
2) 主要结构目录如下:
● backup目录:导入任务结束,导入数据文件保存目录,是否保存文件依赖配置文件选项。
● data目录:导入导出loadserver本地缓存表目录。
● in目录:导入数据文件存放目录,该目录中子目录名称为集群号,第一次使用需创建,并且需要将数据文件移到至该目录中。如果使用计算节点通道进行数据导入,那么无需创建名为集群号的目录,直接将导入文件放入in目录下即可。
● insql:导入过程中,失败转SQL存放数据的目录。
● out目录:导出数据文件存放目录。
● errordata目录:导入失败中间数据文件存放目录。
● split/merge目录:导入/导出临时数据文件存放目录。
说明
数据导入使用计算节点通道仅使用 split 目录。
数据导入导出命令由 LoadServer 服务器所在用户的dbtool 客户端发起。命令介绍如下:
Usage: dbtool -loadserver [OPTION]
其中OPTION:
| 选项名称 | dbtool -h content | 注释 |
|---|---|---|
-l[ink]s[tate] | show ModuleName link info | 查看模块链路信息 |
-l[oad-]c[onfig] | dynamic reload config | 动态生效配置参数 |
-l[oad-]l[icense] | dynamic reload license | dynamic reload license 动态加载license |
-V | print middle working message of LoadServer | 显示详细步骤 |
-type | in/out | 命令类型:in-导入;out-导出 |
-load-retry | load retry | 导入重试 |
-convert-to-insert-retry | convert load in failure file to SQL file | 导入失败文件转sql文件 |
-skip-ok-check | it doesn't work, just for keep the interface compatible | 不起实际作用,仅保持业务接口兼容 |
-clusterid | cluster id | 导入导出功能所在集群号 |
-errorignore | the max error data numbers we can ignore when import data | 导入过程容忍最大错误数据条数,超过该值,导入任务失败 |
-backup | backup loadin datafile to the backup directory | 备份导入文件到备份目录 |
-endstate | Loadout : finally state when export a table, value: -1: use the value in the config file, 0: uploaded and merge, 1: uploaded, 2: saved on DN Loadin: | 结束阶段标志: 导出: 0-导出文件在out目录,并合并为一个文件 1-导出文件在out目录,不合并 2-导出文件存放在DBAgent端,在DBAgent端生成文件名规则:g{groupid}_{导出文件名}_{lds ip十六进制}_{lds 端口十六进制},因此当不同库有相同表时,文件会覆盖。 导入: 不填时默认导入全流程 split-导入在拆分阶段后停止 |
-splitpath | 导入在拆分阶段停止时指定拆分文件路径 | |
-sql | SQL Command | SQL命令 |
-host | host ip(or domain name) and port | LoadServer服务器所在IP(域名)及端口 |
-loadin-support-null | whether loadserver support ",," as NULL value; 0:not support 1: support | 是否支持0长度字符串为NULL,0为不支持,1为支持 |
-set-unique-column= | assign the unique column when do a loadin job, attention: when this option occurs, you should list all the loadin columns in the -sql option except this one | 导入时指定文件内唯一列,注意:当使用该option时,需要列出除指定文件内唯一列之外的所有导入列 |
-user= | load data check authentication | 集群鉴权用户名 |
-password= | load data check authentication | 集群鉴权密码 |
-q[uery] -w[ork]l[oad] | query loadserver's workload | 查询导入导出工作负载情况 |
-tablename | load retry table name or table name for convert to SQL file | 重试命令中指定的表名或者导入失败文件转sql文件命令中指定的表名 |
-importdate= | load retry date[YYYY-MM-DD] or date[YYYY-MM-DD] for convert to SQL file | 重试命令指定重试数据日期或者导入失败文件转sql文件命令中指定的数据日期 |
-importdir= | Load in fail directory for convert to SQL file | 导入失败文件转sql文件命令中指定的失败文件目录 |
-exportdir= | SQL file directory | 导入失败文件转sql文件命令中指定的sql文件目录 |
-batchcommit= | how many lines in a batch do we commit when make a ConvertSQL operation;0:all SQL in a batch, default:5000 | 导入失败文件转sql文件时一次提交行数,0:一次提交所有行,默认5000行 |
-linkoffrebuild | link can be rebuilded with this parameter if linkoff happened | Loadserver与Comtool断链重连参数 |
-filenum= | specify the number of loadout files | Endstate=3时,指定导出文件数目 |
-fileline= | specify the number of lines per loadout file | Endstate=3时,指定导出文件最大行数 |
-db-conn-info= | for load in, cluster service information | 集群服务信息 |
批量导入导出命令由 LoadServer 服务器所在用户的batchload.py脚本发起。命令介绍如下:
Usage:切换到loadserver所在用户下,python bin/batchload.py [OPTION]
其中OPTION:
| 选项名称 | Python batchload.py --help | 注释 |
|---|---|---|
-h, --help | show this help message and exit | 帮助信息 |
-u USER, --user USER | Username to use when connecting to CN | CN用户名 |
-p PASSWORD, --password PASSWORD | Password to use when connecting to CN | CN用户密码 |
-H HOST, --host HOST | Host ip to use when Connecting to CN | CN 用户IP连接地址 |
-P PORT, --port PORT | Port number to use when connecting to CN (default: 0) | CN 连接端口 |
--databases [DATABASES [DATABASES ...]] | Databases list to load | 批量导入导出库名列表 |
--do-tables [DO_TABLES [DO_TABLES ...]] | Tables list to load, format: database.table | 批量导入导出指定表名列表 |
--ignore-tables [IGNORE_TABLES [IGNORE_TABLES ...]] | Tables list not to load, format: database.table | 批量导入导出忽略表名列表 |
--clusterid [CLUSTERID] | Cluster ID (default: 0) | 集群ID |
--clustermode [CLUSTERMODE] | Cluster mode (default: multiple) | 集群模式,single or multiple(仅支持文件传输协议通道) |
--type [TYPE] | Batch load type, value is out or in. | 批量导数类型,导出 or 导入 |
--parallel [PARALLEL] | Parallel degree, range in [1,20] (default: 1) | 批量导出并发度 |
--fields-terminated-by [FIELDS_TERMINATED_BY] | Fields in the output file are terminated by the given string (default: ,) | 列分隔符 |
--fields-enclosed-by [FIELDS_ENCLOSED_BY] | Fields in the output file are enclosed by the given character. | 列包裹符 |
--fields-optionally-enclosed-by [FIELDS_OPTIONALLY_ENCLOSED_BY] | Fields in the output file are optionally enclosed by the given character | 可选列包裹符(域名)及端口 |
--fields-escaped-by [FIELDS_ESCAPED_BY] | Fields in the output file are escaped by the given character | 转义字符 |
--lines-terminated-by [LINES_TERMINATED_BY] | Lines in the output file are terminated by the given string (default: \n) | 行分隔符 |
--targetdir [TARGETDIR] | Target directory | 导入导出根目录 |
--suffix [SUFFIX] | Suffix name for load file | 导入导出文件后缀名 |
--encrypt-key [ENCRYPT_KEY] | Encrypt key for zip file. | Zip压缩加密解密密码 |
--charset [CHARSET] | Character set for loadserver | 导入导出字符集类型 |
--endstate [ENDSTATE] | Loadout file final state, 0: uploaded and merge, 1: uploaded, 2: saved on DN, 3: specify the number of loadout files or the number of lines per loadout file(default: 0). | 结束阶段标志: 导出: 0-导出文件在out目录,并合并为一个文件 1-导出文件在out目录,不合并 2-导出文件存放在DBAgent端,参考dbtool -endstate参数选项限制。 3-指定加载文件的数量或每个加载文件的行数 导入:不填时默认导入全流程(仅支持文件传输协议通道) |
--filenum [FILENUM] | LSplit File number, use it with para endstate (default: 0) | endstate=3时,指定导出文件数目(仅支持文件传输协议通道) |
--fileline [FILELINE] | File Lines per loadout file, use it with para endstate (default: 0) | endstate=3时,指定导出文件最大行数(仅支持文件传输协议通道) |
--errorignore [ERRORIGNORE] | Max error data numbers we can ignore when import data (default: 0) | 导入最大忽视错误的行数 |
--retry | Retry batch loadout (default: False) | 导出重试(仅支持文件传输协议通道) |
-C, --compress | Compress file with zip for loadout file (default: False) | 是否支持导入导出压缩 |
--backup | Backup loadin file (default: False). | 是否备份导入文件(仅支持文件传输协议通道) |
--no-data | Not load data (default: False). | 是否导入导出数据文件 |
--no-create-info | Not load create info (default: False). | 是否导入导出DDL文件 |
--add-drop-database | Add a DROP DATABASE before each create (default: False) | 导出生成SQL创建库前添加DROP语句 |
--add-drop-table | Add a DROP TABLE before each create (default: False) | 导出生成SQL创建表前添加DROP语句 |
--loadin-support-null | loadserver support ",," as NULL value (default:False). | 是否支持0长度字符串为NULL,0为不支持,1为支持 |
1. 导入命令中 SQL 语法如下:
LOAD DATA [LOW_PRIORITY | CONCURRENT] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[PARTITION (partition_name,...)]
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char'|ENCLOSED BY'']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var,...)]
[SET col_name = expr,...]
[WHEN when_clause]
[TRAILING NULLCOLS]
[gdb_format 'JCSV']
[gdb_format 'JCSV']
可选项介绍:
LOW_PRIORITY : 使用该选项,数据库等待导入涉及表没有操作时才进行导入,该选项仅对使用表锁存储引擎有效(MYISAM、MERGE、MEMORY等)。
CONCURRENT : 当表满足并发插入数据时,Load data 语句可与Insert语句并行执行。
file_name : 导入数据文件名,若相对路径下则位于loadin_path配置目录。
REPLACE :当数据导入存在主键冲突或唯一索引冲突,替换表中冲突数据。
IGNORE : 当数据导入存在主键冲突或唯一索引冲突,忽略该行导入数据。
tbl_name :数据要导入的库表。
PARTITION : 表所在分区。
FIELDS [TERMINATED BY 'string'] : 行数据列值以 'string' 结尾分割。
FIELDS [[OPTIONALLY] ENCLOSED BY 'char'] :指定OPTIONALLY,非数据列值使用 'char' 字符引用,不指定则列数据值全部被 'char' 引用。
FIELDS [ESCAPED BY 'char'] : 指定数据转义字符 'char'。
LINES [STARTING BY 'string'] : 指定行数据以 'string' 开始。
LINES [TERMINATED BY 'string'] : 指定行数据以 'string' 结尾。(注意:LoadServer 限制该 'string' 长度小于等于64个字节)
IGNORE : 忽略数据文件开始行数。
[(col_name_or_user_var,...)] :指定列导入,若不指定则默认指定全部列导入。(LoadServer数据导入必须指定列)。
[SET col_name = expr,...] :SET语句,用于对数据列值进行需要的转换操作。
WHEN : 条件导入语法,支持表达式运算符:+ 、- 、* 、/ 、=、>=、=<、> < 、<>、substr()、concat()、 in、between、like函数。
[TRAILING NULLCOLS]:数据文件缺少的最后面的列,导入时用NULL补充。
[gdb_format 'JCSV']:对导入数据不做转义处理,‘\’不作为转义符,作为普通字符导入。
2. 导出命令中 SQL 语法如下:
SELECT (col_name[,...]) FROM tbl_name [WHERE where_clause] INTO
OUTFILE 'file_name'
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']]
[gdb_format {'JCSV'|'nospace_filling'}]
[storagedb g1,g2]
(col_name[,...]) : 指定数据列导出,部分或全部,不支持*代表全部列。
tbl_name :导出数据的库表。
file_name :导出数据存放文件,若相对路径则存放在loadout_path配置目录。
WHERE : where字句与标准SQL语句相同。
FIELDS、LINES使用与导入语句相同。
[gdb_format 'nospace_filling']:导出数据下档格式没有分隔符。
[gdb_format 'JCSV']:特殊字符导出时不做转义处理。
[storagedb g1,g2]: 仅导出分片1、2数据。
数据导入使用计算节点通道或是使用文件传输协议通道依赖配置,默认使用计算节点通道,参考配置:
# whether to use ftp or not;
# unit: NA, range: {0: not to use ftp, 1: use ftp}, default: 1, dynamic: yes;
load_enable_ftp = 0
支持命令行指定计算节点连接信息,命令行优先级高于配置选项,参考命令行选项
-db-conn-info="127.0.0.1:5012|127.0.0.1:5013"
# database connection infomation;
# unit: NA, range: {clusterid:ip:port|...}, default: NA dynamic: yes;
# for example db_conn_info = 1:127.0.0.1:8880|2:127.0.0.2:8880|...
db_conn_info =
说明
若命令行指定了计算节点,此时-clusterid=参数无效,可以不携带;若命令行未指定计算节点,配置文件中指定了计算节点,则会根据-clusterid=指定的集群ID来选择对应的结算节点。
使用文件传输协议,请参考相关配置:ftp_port/ftp_type/ftp_user/ftp_pwd。
数据导入使用计算节点通道或是使用文件传输协议通道依赖配置,默认使用计算节点通道,参考配置:
# whether to use ftp or not;
# unit: NA, range: {0: not to use ftp, 1: use ftp}, default: 1, dynamic: yes;
load_enable_ftp = 0
导入命令行需要指定导入用户和密码,导入用户既可以使用安装生成的CN管理用户,也可以使用自定义创建的用户,使用计算节点通道进行数据导入的导入用户需要被赋予select、insert、file、delete权限,使用文件传输协议通道进行数据导入的导入用户需要被赋予file、insert、delete权限。:
导入功能介绍如下:
1.使用 dbtool 客户端发起导入数据命令,导入表全字段如下::
数据导入命令示例:
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'loadout.data' into table load_manual.t0101_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' ;" -user="userA" -password="passA"
2.导入数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。:
17,"fanchuan",2016,6,2,217
15,"haokai",2013,5,3,216
19,"haokai",2018,5,1,318
4,"jinjiang",1998,2,1,218
3.数据导入表数据如下::
mysql> select * from load_manual.t0101_in;:
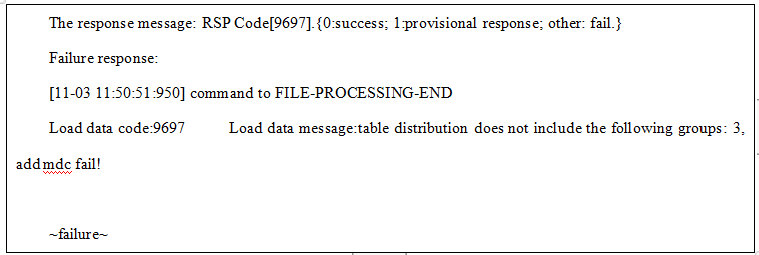
4.利用文件传输协议通道导入数据,客户端返回命令中包含FILE-PROCESS-END 和 success表示导入成功
其中,汇总信息每个统计项的意义解释如下:
file split result:切片任务的结果;
Cluster Mode:集群模式;
datafile:导入数据的文件名;
total seconds:导入消耗的总时间,单位:秒;
sessionid:导入任务的sessionid编号;
GroupId:切片文件所在分片号;
failure rows:导入任务失败的行数;
missing rows:导入任务缺失的行数;
file rows:导入数据文件的总行数;
success rows:导入任务成功的行数;
unwanted rows:导入任务忽略的总行数;
error rows:导入数据存在异常的行数;
split file num:导入文件被切片的个数;
success file num:导入成功的切片个数;
failure file num:导入失败的切片个数;
5.利用计算节点导入数据,客户端返回命令中包含success表示导入成功
其中,汇总信息每个统计项的意义解释如下:
datafile:导入数据的文件名;
total seconds:导入消耗的总时间,单位:秒;
tablename:指明导入的数据库名和表明,格式:数据库名.表名;
sessionid:导入任务的sessionid编号;
file rows:导入数据文件的总行数;
success:导入任务成功的行数;
failure:导入任务失败的行数;
error:导入数据存在异常的行数;
whenfilter:不满足 when 导入条件的函数;
ignore:导入文件跳过的行数;
dbtool -loadserver -V -type="in" -clusterid=1 -sql="load data infile 'loadout.data' into table load_manual.t0101_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' (id,hotelname,year ,month ,day , rent,@b) set test=unhex(@b);" -user="userA" -password="passA"
限制:
1)导入数据文件每行必须包含命令指定行结束符,若最后一行不包含行结束符,则之前数据全部导入成功,但最行一行数据丢失。
2)导入数据中含有blob(test)字段,则导入命令有所变化(形式上与导入部分字段类似):
1.使用 dbtool 客户端发起导入数据命令,导入表部分字段id、hotelname和year,其中month、day和rent字段为忽略字段,需要在字段名前加入“@”符号:
数据导入命令示例:
dbtool -loadserver -type="in" -clusterid=6 -sql="load data infile 'loadout.data' into table load_manual.t0101_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' ( id,hotelname,year,@month,@day,@rent) ;" -user="userA" -password="passA"
2.导入数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
17,"fanchuan",2016,6,2,217
15,"haokai",2013,5,3,216
19,"haokai",2018,5,1,318
4,"jinjiang",1998,2,1,218
3.数据导入表数据如下:
mysql> select * from load_manual.t0101_in;
4.客户端返回命令中包含FILE_PROCESS_END和success表示数据导入成功
1.使用 dbtool 客户端发起导入数据命令,导入表数据使用set子句如下:数据导入命令示例(文件传输通道):
dbtool -loadserver -type="in" -clusterid=6 -sql="load data infile 'loadout.data' into table load_manual.t0101_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n'( id,@var,year,@month,@day,@rent) set hotelname=concat(@var, ‘+’) ;" -user="userA" -password="passA"
2.导入数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
17,"fanchuan",2016,6,2,217
15,"haokai",2013,5,3,216
19,"haokai",2018,5,1,318
4,"jinjiang",1998,2,1,218
3.数据导入表数据如下:
mysql> select * from load_manual.t0101_in;
4.客户端返回命令中包含FILE_PROCESS_END和success表示数据导入成功
1.使用 dbtool 客户端发起导入数据命令,导入表数据使用when子句如下:数据导入命令示例(文件传输通道):
dbtool -loadserver -type="in" -clusterid=6 -sql="load data infile 'loadout.data' into table load_manual.t0101_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' ( id,hotelname,year,@month,@day,@rent) when year>2013 ;" -user="userA" -password="passA"
2.导入数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
17,"fanchuan",2016,6,2,217
15,"haokai",2013,5,3,216
19,"haokai",2018,5,1,318
4,"jinjiang",1998,2,1,218
3.数据导入表数据如下:
mysql> select * from load_manual.t0101_in;
4.客户端返回命令中包含FILE_PROCESS_END 和 success表示数据导入成功
仅支持文件传输协议通道。
导入失败数据重试
当客户端处于数据导入过程中,发生异常导致数据导入中断或失败时,在loadserver服务端失败文件目录或导入临时文件目录存放本次导入失败的文件,同时dbtool客户端打印本次数据文件成功拆分的原始文件行数。用户可以选择将已经拆分成功但导入失败的文件重新导入到数据库中,导入重试命令会将失败目录下和分裂文件临时目录中,该库表的所有失败文件查询并导入。
1.导入失败数据重试命令:
dbtool -loadserver -load-retry -clusterid=6 -tablename=load_manual.normal -user="userA" -password="passA"
2.loadserver服务器查询到失败文件所在目录如下:
Intermediate response:
Find the sql file; FilePath:[/mnt/raid/loaddata/errordata/82017051214255543], FileName:[/mnt/raid/loaddata/errordata/82017051214255543/loadout.data.sql]
Intermediate response:
event: LOAD_READ_FAILED_FILE
result code:0
result message:read failed file success
3.客户端返回 LOAD_DELETE_FILE_END表示最终数据导入成功
导入失败数据指定日期重试
1. 导入失败数据重试命令:
dbtool -loadserver -load-retry -clusterid=6 -importdate='2017-07-07' -tablename=load_manual.normal -user="userA" -password="passA"
2.loadserver服务器查询到失败文件所在目录如下:
Intermediate response:
Find the sql file; FilePath:[/home/dbagentd/loaddata/split/2017-07-07/load_test_manual.normal/20170707190611266.3], FileName:[/home/dbagentd/loaddata/split/2017-07-07/load_manual.normal/20170707190611266.3/normal.data.sql]
Intermediate response:
Find the sql file; FilePath:[/home/dbagentd/loaddata/errordata/2017-07-07/load_test_manual.normal/20170707190611266.3], FileName:[/home/dbagentd/loaddata/errordata/2017-07-07/load_manual.normal/20170707190611266.3/normal.data.sql]
Intermediate response:
event: LOAD_READ_FAILED_FILE
result code:0
result message:read failed file success
3.客户端返回LOAD_DELETE_FILE_END和sussecc表示最终数据导入成功
导入重试支持指定路径
1.导入重试支持指定路径命令参数如下:
dbtool -loadserver -load-retry -clusterid=2 -splitpath="/home/lds/split" -user="userA" -password="passA"
1)-load-retry:指定任务类型为重试;
2)-clusterid:重试任务所在集群号;
3)-splitpsth:导入重试文件存放的绝对路径;-tablename 与 -splitpsth 必须且仅能指定其中一个。
2.导入重试支持指定路径运行结果如下:
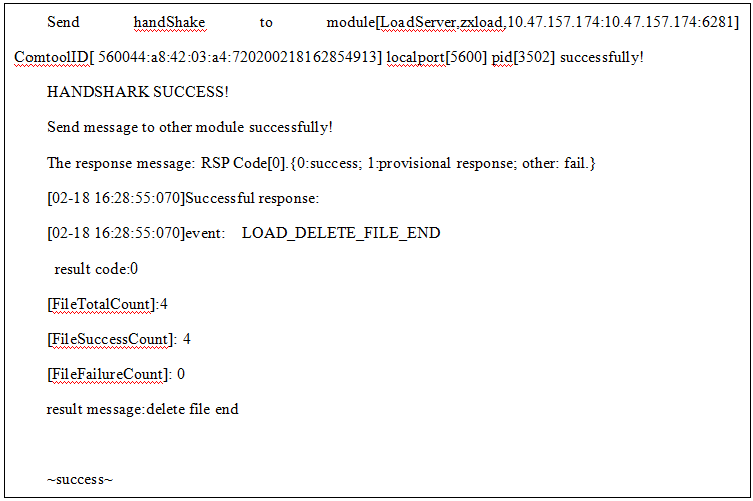
上面执行结果各个字段含义如下:
1)FileTotalCount:重试任务总文件个数;
2)FileSuccessCount:重试任务总文件成功个数;
3)FileFailureCount:重试任务总文件失败个数。
空列导入介绍
loadserver导入导出时支持数据文件中字段空列处理,用以兼容DB2/Oracle等数据库的导出数据格式。
功能介绍:
支持空列时,两个列分隔符之间无内容为NULL值。
示例:||等价于导入数据|NULL|,|为示例列分隔符。
不支持空列时,两个列分隔符之间无内容可能报错,如整形、时间等不支持空的数据类型,不支持空列为数据库默认行为。
命令格式 :
dbtool -loadserver -type="in" [-loadin-support-null=1] -clusterid=2 [-errorignore=10] -sql="load data infile 'loadin.data' into table DN_name.table_name fields terminated by ',' lines terminated by 'n'(id, name);" -user="userA" -password="passA"
-loadin-support-null :是否支持零长度字符串配置项(1为支持零长度字符串,0为不支持零长度字符串,缺省时按照配置文件配置值:loadin_support_null)
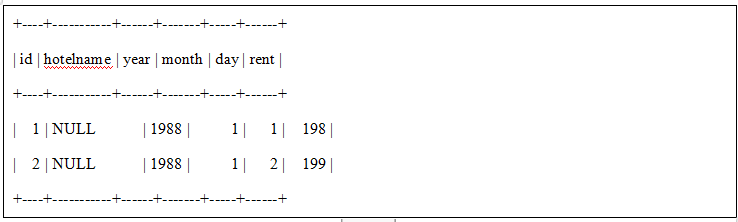
空列导入示例
1.导入数据
1|"N"|1988|1|1|198
2||1988|1|2|199
2.支持NULL字符串导入命令:
dbtool -loadserver -type="in" -loadin-support-null=1 -errorignore=6 -clusterid=1 -sql="load data infile 'loadout_469735.data' into table test_all.t469735 fields terminated by '|' optionally enclosed by '"' lines terminated by 'n';" -user="userA" -password="passA"
3.最终数据导入如下:
仅支持文件传输协议通道。
loadserver支持转sql功能
1.转sql功能命令格式如下:
dbtool -loadserver -convert-to-insert {-tablename='load_manual.t0101_in' [-importdate='2018-04-09'] | -importdir='/home/manager1/loaddata/errordata/2018-04-09/load_manual.t0101_in/20180409114404478.5'} [-exportdir='/home/manager1/sql]'
转sql有两种输入方式调用命令时可以任选一组:
(1)-tablename指定表名,将error目录下该表所有load失败的文件转为sql(要求所有同名表结构相同),可选参数-importdate可以指定转化某天的load失败的error文件
(2)-importdir指定目录转化,要求指定的目录存在.sql的表结构。
2.实现的功能:
将拆分成功load失败的文件按各自分发的节点分类,转化成insert文件。
1.现阶段只支持通过loadserver拆分产生的文件转sql,不支持人工修改文件。
2.当前不支持导入SQL中带set字句的失败文件转换。
loadserver实现转sql功能
1.loadserver实现转sql命令:
dbtool -loadserver [-V] -convert-to-insert -importdir='/home/manager/2018-04-14/test_all.t3/20180414110653350.7' -exportdir='/home/manager/sql'
2.load失败文件最终转化成sql文件成功客户端返回如下:

仅支持文件传输协议通道。
导入时支持增加文件级别唯一字段
1.使用 dbtool 客户端发起导入数据命令,导入表命令如下:
数据导入命令示例:
dbtool -loadserver -type="in" -clusterid=1 -set-unique-column=unique_c -sql="load data infile 'unique_in.data' into table load_unique.unique_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' (card_number,account_id,makecard_time,card_balance,makecard_bank_id) ;" -user="userA" -password="passA"
条件:
1)新增option:-set-unique-column=,内容为指定的唯一序列字段;
2)需要列出导入文件全部导入字段,不能多列,也不能少列;
3)指定的唯一序列字段,必须为数据库表中存在的字段;
4)指定的唯一序列字段,不能在导入字段中列出;
5)指定的唯一序列字段,必须是一个字段,不能为多个字段;
6)指定的唯一序列字段,建表时建议为int或者bigint字段类型,其他数据类型不保证有效性;
导入时实现增加文件级别唯一字段
1.loadserver导入时实现增加文件级别唯一字段:
dbtool -loadserver -type="in" -clusterid=1 -set-unique-column=unique_c -sql="load data infile 'unique_in.data' into table load_unique.unique_in fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' (card_number,account_id,makecard_time,card_balance,makecard_bank_id) ;" -user="userA" -password="passA"
2.导入数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’:

3.数据导入表数据如下:
mysql> select card_number,account_id,makecard_time,card_balance,makecard_bank_id,unique_c from unique_in;
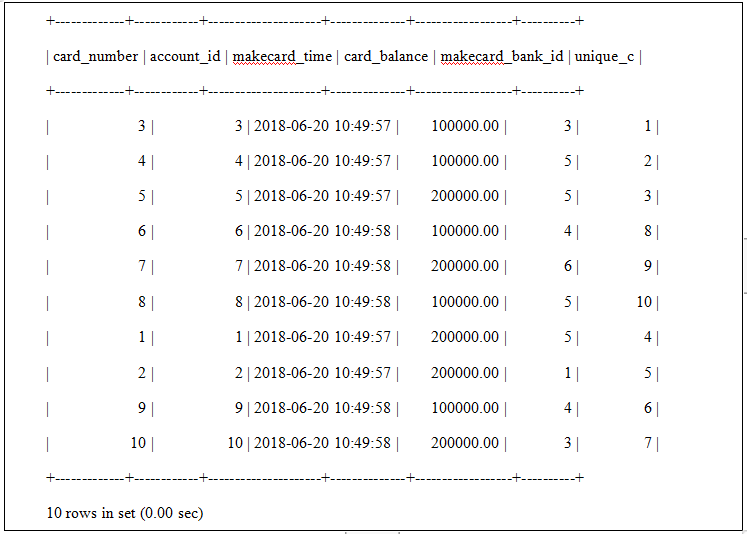
4.loadserver导入时实现增加文件级别唯一字段导入成功客户端返回如下:

仅支持文件传输协议通道。
支持数据切片功能介绍
为使数据导入功能具有更好的灵活性以适用于更多的应用场景,规划数据导入可分阶段执行,支持数据导入切片后结束(以下简称数据切片功能),即本模块支持单纯数据切片,不实际导入数据库。典型的应用场景如数据库某存储节点扩容、对导入文件只获取指定分片数据等。数据切片功能生成的文件,可使用数据导入重试功能将切片数据导入到数据库中。 本次需求新增数据切片功能,用户数据导入时可选择数据切片或者数据导入功能,默认数据导入功能,即将数据直接导入数据库。
支持数据切片使用介绍
1.数据切片命令格式如下:
dbtool -loadserver -type="in" -endstate="split" -splitpath="/home/lds/split/file" -clusterid=2 -sql="load data infile 'loadin.data' into table DN_name.table_name fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
1)-endstate:当前仅支持取值split,表明执行数据切片任务;
2) -splitpath:用户可自定义切片文件存放的绝对路径,无该参数时默认为配置项中split_path指定的路径。
2.数据切片执行结果如下:

上面执行结果各个字段含义如下:
1)datafile:切片任务的数据文件名字;
2)Total seconds:本次切片任务总耗时,单位为秒;
3)Sessionid:执行切片任务时,LoadServer内部sessionid编号;
4)GroupId:切片文件所在分片号;
5)file num:该集群拆分文件总个数;
6)total rows:该集群拆分文件总行数;
7)success rows:本次切片任务成功的总行数;
8)error rows:本次切片任务失败的总行数;
9)ignore rows:本次切片任务忽略的总行数。
导入指定字段长度无分隔符文件功能介绍
1.导入需支持无分隔符文件的导入,要求:
1)使用mysql中substring函数指定各字段导入的长度,支持指定字段长度无分隔符文件导入;
2)通过character set binary方式支持字节方式截取固定长度字段导入;
3)支持的导入表字段类型如下(使用全字段表测试后得出):
int , tinyint,smallint, mediumint,bigint,float,double,decimal(18,2),date,time,timestamp,datetime,year,char(2),varchar(20),binary(50) ,varbinary(50),blob,text;
导入指定字段长度无分隔符文件使用介绍
1.无分隔符文件的导入命令如下:
dbtool -loadserver -type=in -clusterid=1 -sql="load data infile '/home/goldendb/zxload1/loaddata/out/1/qqq.txt' into table load_shl.alltype2 character set binary fields terminated by 'n' (@a) set ID=substring(@a, 1, 11),TINYINT_COL=substring(@a, 12, 11),MEDIUMINT_COL=substring(@a, 23, 11),INTEGER_COL=substring(@a, 34, 11),BIGINT_COL=substring(@a, 45, 11),FLOAT_COL=substring(@a, 56, 11),DOUBLE_COL=substring(@a, 67, 11),DECIMAL_COL=substring(@a, 78, 11),NUMERIC_COL=substring(@a, 89, 11),DATE_COL=substring(@a, 100, 8),TIME_COL=substring(@a, 108, 8),TIMESTAMP_COL=substring(@a, 116, 17),DATETIME_COL=substring(@a, 133, 17),YEAR_COL=substring(@a, 150, 5),CHAR_COL=substring(@a, 155, 2),VARCHAR_COL=substring(@a, 157, 10),BINARY_COL=substring(@a, 167, 50),VARBINARY_COL=substring(@a, 217, 50),BLOB_COL=substring(@a, 267, 20),TEXT_COL=substring(@a, 287, 20);" -V -user="userA" -password="passA"
2.支持字节方式截取固定长度字段:命令中指定character set binary;“汉字” 通过substring(@a,1,6)进行截取,utf8文件中一个汉字占3个字节;"ab" 通过substring(@a,1,2)进行截取,utf8文件中一个字母占1个字节。
dbtool -loadserver -type=in -clusterid=1 -sql="load data infile '/home/goldendb/zxload1/a.dtf' into table load_shl.fix_lds character set binary (@a) set var1=substring(@a, 1, 12), var2=substring(@a, 13, 18), var3=substring(@a, 31, 11),var4=substring(@a, 42,6);" -V -user="userA" -password="passA"
注意:若设置字符集为utf8字符,一个汉字占3个字节,若设置字符集为binary,substring函数长度必须为3的倍数,否则会报错;若设置字符集为utf8mb4,substring函数是按字符个数取数据,一个汉字占两个字符。
LoadServer新导入精准报错
1.功能介绍
在使用LoadServer导入过程中,发现LoadServer对于逻辑错误的处理机制存在一定不足,比如数据中存在主键冲突等,会将一个批次的数据(默认5000)全部失败。
为了实现精准报错,用户可以在导入结束后再对失败文件,添加命令行控制事务的大小做二次导入,两次调度完成完整的导入动作。
如果部分成功,部分失败,LoadServer自动调用定制脚本,脚本中对失败数据执行二次导入,同时改变事务大小,完成用户定制行为。
2.使用说明
在LoadServer配置文件loadserver.ini中新增配置项enable_loader_customize,可以配置0或1,其中0表示不支持定制导入结果,1表示支持定制导入结果,enable_loader_customize默认配置为0,即不支持定制导入结果。
开启定制导入结果开关,enable_loader_customize=1,该配置项需要重启LoadServer生效。
例如使用以下命令往表load_manual_lz导入数据:
dbtool -loadserver -type="in" -clusterid=1 -sql="load data infile 'loadout.data_lz' into table load_manual_lz.t0101_in_lz fields terminated by ',' optionally enclosed by '"' lines terminated by 'n' (id,name,year,month,day,rent) ;" -user="dbproxy" -password="***"
导入结果屏幕统计不准确,精准报错信息需要查看失败目录下的customize_result_task.info文件,屏幕结果显示如下:

在失败目录下会生成如下文件:
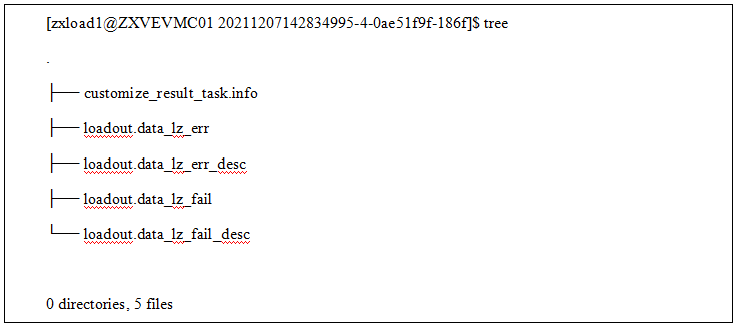
其中loadout.data_lz_err为数据失败文件,loadout.data_lz_fail为执行失败文件,loadout.data_lz_err_desc为数据失败描述文件, loadout.data_lz_fail_desc为执行失败描述文件。两个描述文件针对的是第一次导入失败的数据,因此报错行数和报错数据在原始导入文件的行数会出现不一致的情况。customize_result_task.info汇总了两次导入的最终结果,内容如下:
file rows:10 success:7 failure:1 error:2 whenfilter:0 ignore:0 ~failure~
如果在导入命令中增加-disable-customize,那么即便打开了enable_loader_customize配置项开关,也不会执行精准报错功能。
LoadServer支持错误日志路径可配置
1.功能介绍
多个LoadServer部署在不同的服务器上,调度任务同时调用多个LoadServer进行导数,出错的日志分散在多个服务器上,不利于统一管理。
目前导入设计行为:当导入中遇到数据错误、执行错误时会在临时工作目录合并落盘为错误数据文件及描述文件,执行错误文件及描述文件,任务结束后屏幕汇总:数据错误行数,执行错误行数,并通知用户失败目录位置。
通过调用定制化脚本,能够将数据错误描述文件和执行错误描述文件复制到用户执行的目录下,方便用户查看导入错误日志。
2.使用说明
该功能和精准报错功能共用一个定制脚本loader_customize,确保loadserver.ini文件的enable_loader_customize=1,表示开启定制功能。在脚本里需要用户配置指定目录,默认路径为g_dest_dir=/home/goldendb/zxload1/LoaderErrorFail/,导入数据命令和结果见2.3.11.1,该功能会将执行失败描述文件和数据失败描述文件复制到指定的目录的子目录下,该子目录名和失败目录名同名,格式为time-sessionid-ip-port,查看指定目录内容如下:
[zxload1@ZXVEVMC01 ~]$ cd ~/LoaderErrorFail/20211207142834995-4-0ae51f9f-186f
[zxload1@ZXVEVMC01 20211207142834995-4-0ae51f9f-186f]$ ls
loadout.data_lz_err_desc loadout.data_lz_fail_desc
多个LDS导入出错的日志统一拷贝到指定的服务器目录的配置实例说明:
| 服务器 | 说明 |
|---|---|
10.1.1.1 | LDS组件 |
10.1.1.2 | LDS组件 |
10.1.1.3 | 导入出错日志统一拷贝到该服务器 |
1)在10.1.1.3上创建一个目录/home/lds_logs,设置目录权限chmod 770 ldsdata/,配置echo '/home/lds_logs/ *(rw,async,no_root_squash)' >> /etc/exports,执行exportfs -a生效;启动nfs服务。
2)分别在10.1.1.1和10.1.1.2上启动nfs服务,挂载共享目录mount -t nfs 10.1.1.3:/home/lds_logs /home/goldendb/zxload1/LoaderErrorFail/,用df -h查看是否挂载。
3)分别在10.1.1.1和10.1.1.2登录zxload1用户查看LoaderErrorFail用户权限是否为root,是root就执行chown zxload1:goldendb /home/goldendb/zxload1/LoaderErrorFail/;使用zxload1用户在目录中创建文件并修改保存,如果保存成功说明挂载目录权限正确,再到10.1.1.3上查看/home/lds_logs目录中是否存在新建的文件,如存在,说明挂载成功,如失败,查看目录权限是否正确,挂载命令是否执行成功。
导出命令行需要指定导出用户和密码,导出用户既可以使用安装生成的CN管理用户,也可以使用自定义创建的用户,使用文件传输协议通道进行数据导出的导出用户需要被赋予file、select权限。
1.使用 dbtool 客户端发起导出数据命令:
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' optionally enclosed by '"' lines terminated by 'n';" -user="userA" -password="passA"
2.表数据如下:
mysql> select * from load_manual.t0101_in;

3.导出数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
17,"fanchuan",2016,6,2,217
15,"haokai",2013,5,3,216
19,"haokai",2018,5,1,318
4,"jinjiang",1998,2,1,218
4.数据导出成功客户端返回命令如下:
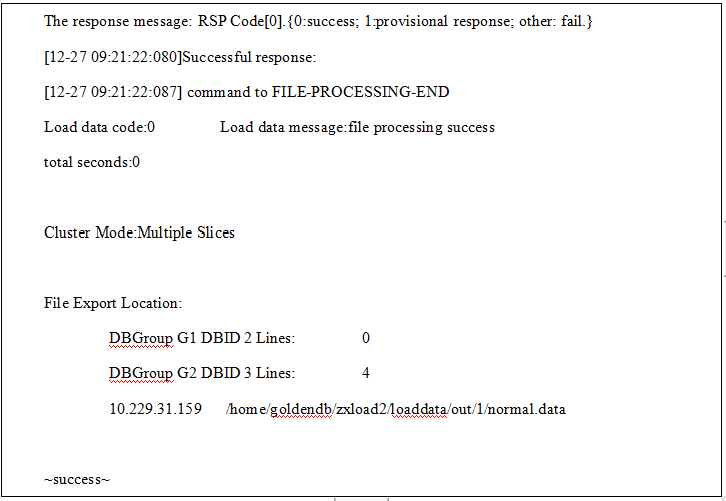
其中,汇总信息每个统计项的意义解释如下:
● total seconds:导出消耗的总时间,单位:秒;
● Cluster Mode:集群模式;
● File Export Location:列出了文件导出的相关信息,包括导出数据所在数据库分片信息和最终的导出文件路径。
● DBGroup:导出数据所在的分片;
● DBID:导出数据所在的DB节点编号;
● Lines:导出数据的行数;
特例:
1)若导出数据中含有blob(test)字段,则导出命令有所变化:
dbtool -loadserver -type="out" -clusterid=2 -sql="select id,hotelname,year ,month ,day , rent, hex(test) from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
1.使用 dbtool 客户端发起导出数据命令:
dbtool -loadserver -type="out" -clusterid=2 -sql="select id, hotelname,year from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
2.表数据如下:
mysql> select * from load_manual.t0101_in;

3.导出数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
17,"fanchuan",2016
15,"haokai",2013
19,"haokai",2018
4,"jinjiang",1998
4.数据导出成功客户端返回命令如下:

1. 使用 dbtool 客户端发起导出数据命令:
dbtool -loadserver -type="out" -clusterid=2 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal where id<10 into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
2.表数据如下:
mysql> select * from load_manual.t0101_in;

3.导出数据文件如下示:数据文件格式为:列分隔符 ‘,’,行结束符 ‘\n’,字符串包含符‘””’。
4,"jinjiang",1998,2,1,218
4.数据导出成功客户端返回命令如下:

仅支持文件传输协议通道。
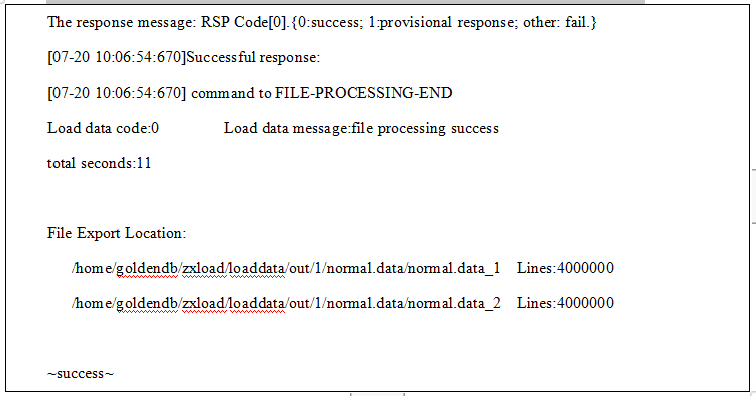
导出支持指定结果文件个数
1.使用 dbtool 客户端发起导出数据命令,指定结果文件个数为2;
数据导出命令示例如下:
dbtool -loadserver -type="out" -clusterid=5 -endstate=3 -filenum=2 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
指定导出结果文件个数见命令红色部分,条件:
1)endstate为可选参数,值为3时,导出支持指定结果文件个数或行数;
2)filenum指定导出结果文件个数,当且仅当endstate=3时有效;-fileline与-filenum 有且仅有一个,其他情况报错;
2.loadserver实现导出指定结果文件个数成功客户端返回如下:
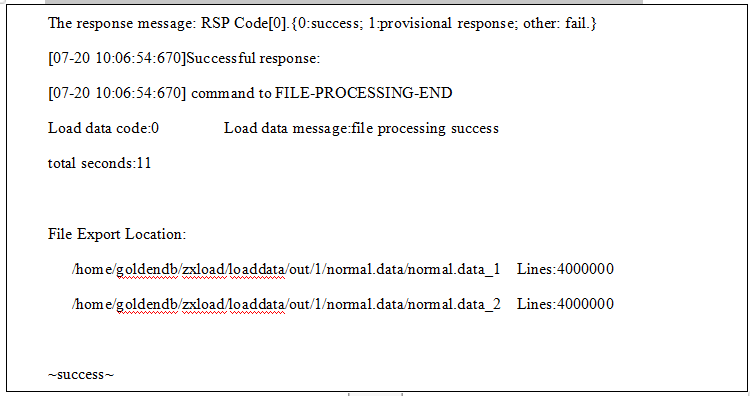
导出支持指定结果文件行数
1.使用 dbtool 客户端发起导出数据命令,指定结果文件行数为4000000;
数据导出命令示例如下:
dbtool -loadserver -type="out" -clusterid=5 -endstate=3 -fileline=4000000 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
指定导出结果文件行数见命令红色部分,条件:
1)endstate为可选参数,值为3时,导出支持指定结果文件个数或行数;
2)fileline指定导出结果文件行数,当且仅当endstate=3时有效;-fileline与-filenum 有且仅有一个,其他情况报错;
2.loadserver实现导出指定结果文件行数成功客户端返回如下:
导出支持指定结果文件个数或行数报错情况说明
1.导出路径已存在报错
导出支持指定结果文件个数或行数的结果文件,默认输出路径为:loadserver用户下~/loaddata/out/集群id/导出文件名称/,例如:/home/goldendb/zxload/loaddata/out/1/normal.data/;
支持指定绝对路径。若导出之前校验该路径已存在,则导出报错如下:

2.导出总行数不匹配报错
导出支持指定结果文件个数或行数功能,不支持字段值包含换行符(导出时约定的换行符)的情况。当导出文件字段值中包含换行符时,导出文件总行数不匹配,报错如下:

4.导出严格按照用户指定的文件个数或行数进行导出,当导出文件个数不足用户指定数量时,使用空文件补足(例如一个空文件,指定导出3个小文件时,将得到3个行数为0的空文件)。
导出数据支持无分隔符格式
LoadServer支持在不指定分隔符时导出没有额外空格的文件,其中定长由函数或者字段类型来实现。LoadServer原有功能在不指定分隔符时,导出文件会有很长的空格。
1.使用 dbtool 客户端发起导出数据命令:
数据导出命令示例:
dbtool -loadserver -type="out" -clusterid=5 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields enclosed by '' terminated by '' lines terminated by 'n' gdb_format 'nospace_filling';" -user="userA" -password="passA"
条件:
1)当指定fields enclosed by '' terminated by '' gdb_format 'nospace_filling' 时(enclosed by '' 可选),导出文件中,字段间无分隔符,不产生多余的空格。
2)当指定 gdb_format 'nospace_filling',但未指定fields terminated by ''或 enclosed by 有包含符,则报错。
2.无分隔符格式导出成功客户端返回如下:
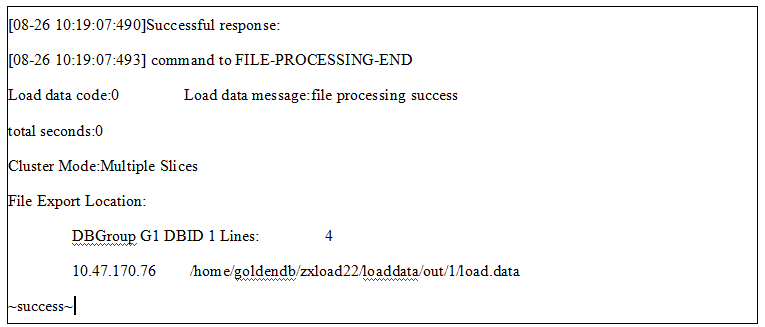
3.无分隔符格式导出数据结果如下:
1rujia198811198
2rujia198812199
3rujia198813199
4jinjiang199821218
支持指定分片导出数据功能介绍
为满足业务跑批时,针对单个分片数据做导出,从而可以进行多个分片的并行处理。导出命令支持storagedb语法,指定分片节点进行导出操作。
支持指定分片导出数据使用介绍
若要指定分片进行导出,导出命令select语句中需增加storagedb语句,且storagedb语句必须放在select语句最末尾。其中storagedb语句中指定的分片应属于表分布的分片,否则报错。
1.指定在g1,g2分片导出,若导出成功,则显示指定分片的详细导出信息:
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n' storagedb g1,g2;" -V -user="userA" -password="passA"

2.指定在g3分片导出,若表分片信息不包含指定分片,报错:
dbtool -loadserver -type="out" -clusterid=1 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n' storagedb g3;" -V -user="userA" -password="passA"
仅支持文件传输协议通道。
导出支持输出控制文件功能介绍
1.使用lds下档,在单个下档任务结束时,能够具备数据文件、过程文件和控制文件。
1)数据文件是符合下档格式要求的文本;
2)过程文件记录了下档的速度,文件位置以及最终记录行数;
3)控制文件记录了数据文件的字段定义和字段的长度区间。
导出支持输出控制文件使用介绍
1.loadserver导出支持输出控制文件命令格式如下:
dbtool -loadserver -V -type="out" -clusterid=1 -controlfile=1 -logfile=1 -controlpath="/home/goldendb/zxload/control.ctl" -logpath="/home/goldendb/zxload/log.log" -sql="select to_char(ID,'9999999999'),rpad(' ', 10, ' '), ifnull(to_char(tinyint_col,'9990.0'),rpad(' ', 11,' ')), rpad(' ',128,' ' )smallint_col, to_char(mediumint_col,'9999999999'), to_char(integer_col,'9999999999'), to_char(bigint_col,'9999999999'), to_char(float_col,'9999999999'), to_char(double_col,'9999999999'), to_char(decimal_col,'9999999999'), to_char(numeric_col,'9999999999'), to_char(date_col,'YY-MM-DD'), to_char(time_col,'hh:mi:ss'), to_char(timestamp_col,'YY-MM-DD hh:mi:ss'), to_char(datetime_col,'YY-MM-DD hh:mi:ss'), to_char(year_col,'9999'), lpad(char_col,2,' '), lpad(varchar_col,10,' '), lpad(binary_col,50,' '),lpad(varbinary_col,50,' '),lpad(blob_col,20,' '),lpad(text_col,20,' ') from load_shl.alltype into outfile 'test.csv' fields terminated by '' enclosed by '' lines terminated by 'n' gdb_format 'jcsv';" -user="userA" -password="passA"
1)导出控制文件新增命令参数如下:
● -controlfile:是否输出控制文件,优先级高于配置项loadout_control_file_flag;值为0时,不输出控制文件;值为1时输出控制文件;
● -logfile:是否输出日志文件,优先级高于配置项loadout_log_file_flag;值为0时,不输出控日志文件;值为1时输出日志文件;
● -controlpath:指定控制文件位置(带文件名),不指定时默认与导出数据文件位置相同;
● -logpath:指定日志文件位置(带文件名),不指定时默认与导出数据文件位置相同。
2.loadserver新增配置项:
#whether output the control file of loadout;0:not support, 1:support; default:0
loadout_control_file_flag=0
#whether output the log file of loadout;0:not support, 1:support; default:0
loadout_log_file_flag=0
1)loadout_control_file_flag默认值为0,不输出控制文件,支持动态生效;当命令参数中指定-controlfile时,优先级高于配置项loadout_control_file_flag;
2)loadout_log_file_flag默认值为0,不输出日志文件,支持动态生效;当命令参数中指定-logfile时,优先级高于配置项loadout_log_file_flag。
1.上述导出命输出的控制文件如下:
1)control.ctl

2)log.log

2.导出输出控制文件支持的使用场景如下:
1)支持的函数:to_char,LPAD,RPAD,ifnull,
RPAD函数支持以下使用方式(LPAD使用方式同下):
a.RPAD(id,10-length(id)+char_length(id),' ')
b.RPAD(' ',128,' ' )smallint_col
c.RPAD(' ',10,' ')
d.RPAD(varbinary_col,50,' ')
ifnull函数支持以下使用方式:
a.ifnull(smallint_col,rpad(' ', 11,' '))
b.ifnull(to_char(smallint_col,'9990.0'),rpad(' ', 11,' '))
c.ifnull(rpad(smallint_col,11,' '),rpad(' ', 11,' '))
2)列的长度为实际select结果长度,如果没有函数处理,直接输出列定义的长度,如果经过函数处理,则输出函数处理后函数内字段原定义的长度。
3)RPAD(id,10-length(id)+charlength(id)),ifnull 两种函数返回的长度为函数内原字段列定义长度。
4)当是字符串类型时,字段POSITION位置输出暂不支持汉字。
5)如果不支持的函数,且要输入控制文件,则直接报错,不进行数据导出操作。
6)限制:建行场景不支持null类型字段的导出和导入。
1.使用 dbtool 客户端发起导入数据命令,导入表全字段如下:
数据导入命令示例:([ ]可选)
dbtool -loadserver -type="in" [-V] [-loadin-support-null=1] -clusterid=2 -backup [-errordata="/home/lds/data.error"][ -errorignore=10] -sql="load data infile 'loadin.data' into table DN_name.table_name fields terminated by ',' lines terminated by 'n'(id, name);" [-host="127.0.0.1:5012"] -user="userA" -password="passA"
-V 为在终端上打印详细过程 缺省时不打印
-loadin-support-null 为是否支持零长度字符串配置项(1为支持零长度字符串,0为不支持零长度字符串,缺省时按照配置项loadin_support_null配置情况)
-errordata指定错误文件输出目录,缺省时采用默认目录
-errorignore为导入时忽略拆分错误的数量缺省时为不忽略
-host远程执行时使用
返回值0为成功、1为失败、2为未知
2.使用 dbtool 客户端发起导出数据命令,导出表全字段如下:
dbtool -loadserver -type="out" [-V] -clusterid=1 -sql="select id, tinyint_u_1, smallint_u_1, mediumint_u_1, int_u_1, integer_u_1, bigint_u_1,tinyint_s_1, smallint_s_1, mediumint_s_1, int_s_1, integer_s_1, bigint_s_1,double_u_1, float_u_1, decimal_u_1, decimal_u_2, numeric_u_1, numeric_u_2,double_s_1, float_s_1, decimal_s_1, decimal_s_2, numeric_s_1, numeric_s_2,date_1,time_0,time_1,time_2,time_3,time_4,time_5,time_6,timestamp_01,timestamp_02,timestamp_1,timestamp_2,timestamp_3,timestamp_4,timestamp_5,timestamp_6,datetime_0,datetime_1, datetime_2,datetime_3,datetime_4,datetime_5,datetime_6,year_1, char_0, char_N, varchar_0, varchar_N,binary_0, binary_N, varbinary_0, varbinary_N from test_all.t490255 into outfile '/home/manager/support_pwd/loadout_490255.data' fields terminated by ',' optionally enclosed by '"' lines terminated by 'n';" [-host="127.0.0.1:5012"] -user="userA" -password="passA"
数据导入命令示例:([ ]可选)
-V 为在终端上打印详细过程 缺省时不打印
返回值0为成功、1为失败、2为未知
3.loadserver实现转sql命令:
dbtool -loadserver -convert-to-insert [-V] -importdir='/home/manager/2018-04-14/test_all.t3/20180414110653350.7' -exportdir='/home/manager/sql'
-V 为在终端上打印详细过程 缺省时不打印
返回值0为成功、1为失败
转sql不提供远程功能
1.loadserver导入提供远程调用接口:
# dbtool -loadserver -type="in" -V -clusterid=1 -sql="load data infile '/home/manager/support_pwd/loadout_t490279.data' into table test_all.t490255 fields terminated by ',' optionally enclosed by '\"' lines terminated by '\n';" -host='192.168.100.2:6254' -user="userA" -password="passA"
说明
data文件在loadserver所在服务器
2.loadserver实现指定路径导入成功客户端返回如下:

3.loadserver实现指定路径导入失败客户端返回如下:

4.loadserver导出提供远程调用接口:
dbtool -loadserver -type="out" -V -clusterid=1 -sql="select id, tinyint_u_1, smallint_u_1, mediumint_u_1, int_u_1, integer_u_1, bigint_u_1,tinyint_s_1, smallint_s_1, mediumint_s_1, int_s_1, integer_s_1, bigint_s_1,double_u_1, float_u_1, decimal_u_1, decimal_u_2, numeric_u_1, numeric_u_2,double_s_1, float_s_1, decimal_s_1, decimal_s_2, numeric_s_1, numeric_s_2,date_1,time_0,time_1,time_2,time_3,time_4,time_5,time_6,timestamp_01,timestamp_02,timestamp_1,timestamp_2,timestamp_3,timestamp_4,timestamp_5,timestamp_6,datetime_0,datetime_1, datetime_2,datetime_3,datetime_4,datetime_5,datetime_6,year_1, char_0, char_N, varchar_0, varchar_N,binary_0, binary_N, varbinary_0, varbinary_N from test_all.t490255 into outfile '/home/manager/support_pwd/loadout_490255.data'fields terminated by ',' optionally enclosed by '"' lines terminated by 'n';" -host='192.168.100.2:6254' -user="userA" -password="passA"
data文件在loadserver所在服务器

5.loadserver实现指定路径导出成功客户端返回如下:

仅支持文件传输协议通道。
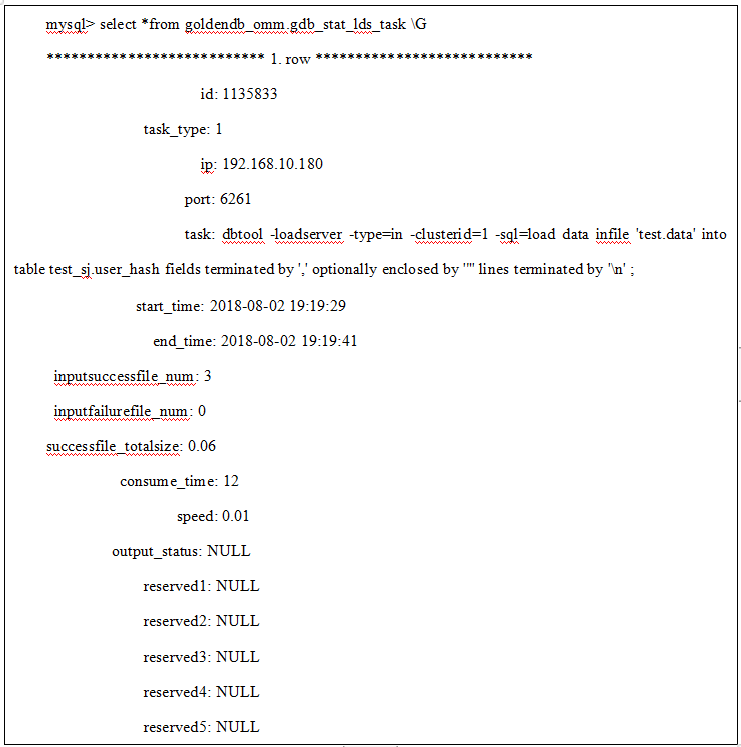
1.loadserver导入操作定时和实时上报字段:
loadserver IP、loadserver端口、任务说明(导入命令)、任务开始时间、任务结束时间、导入成功数量(切分文件,任务级累计)、导入失败数量(切分文件)、导入文件总大小(导入成功切分文件,任务级累计,单位M保留小数点后两位)、导入耗时(当前时间-开始时间)、导入平均速度(M/S,小数点后两位)。
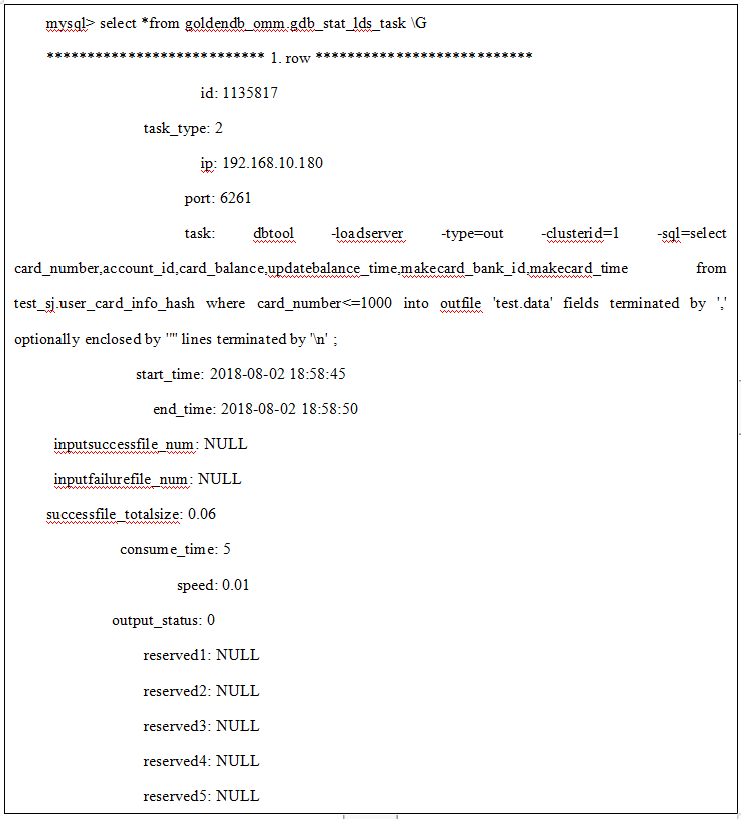
2.loadserver导出操作定时和实时上报字段:
loadserver IP、loadserver端口、任务说明(导出命令)、任务开始时间、任务结束时间、导出文件大小(成功导出小文件和)、导出耗时、导出平均速度、导出状态。
3.上报数据到omm数据库goldendb_omm.gdb_stat_lds_task表中。
1)导入上报数据样例:
2)导出上报数据样例:
说明
导入导出状态上报项 task命令格式中不得含有XML数据格式禁止字符【0x00-0x08/0x0b-0x0c/0x0e-0x1f】,否则将导致本次上报信息入库存储失败。
1.loadserver 实时查询功能命令格式如下:
dbtool -loadserver -q[uery] -w[ork]l[oad]
2.loadserver 实时查询结果示例:

1)task load:当前运行任务数统计;
2)cluster id:集群id;
3)session num:任务session个数;
4)sessionid:任务session id;
5)loadtype:任务类型(out:导出,in:导入);
6)loading-out:当前sessionid导出任务正在导出文件个数;
7)merging:当前sessionid导出任务合并状态(1:正在合并文件,0:不在合并阶段);
8)spliting:当前sessionid导入任务切分状态(1:正在切分文件,0:切分文件结束或未开始);
9)loading-in:当前sessionid导入任务正在导入文件个数;
10)task statistic:当前运行任务状态统计;
11)statistic summary:状态统计信息汇总;
12)statistic detail:状态统计信息明细;
13)split stage:导入-切分阶段:
success:切分成功文件数;
failure:切分失败文件数(1:切分失败,且errorignore;0:切分失败,没有errorignore或者切分成功);
failure rows:切分失败行数;
size(MB):切分成功文件大小,单位MB,保留小数点后两位;
time(s):切分耗时,单位秒s;
vel(MB/s):平均切分速度,单位MB/s;
14)loadin stage:导入-传输和导入数据阶段:
success:导入成功文件数;
failure:导入失败文件数;
size(MB):导入成功文件大小,单位MB,保留小数点后两位;
time(s):导入耗时,单位秒s;
vel(MB/s):平均导入速度,单位MB/s;
15)loadout stage:导出-传输和导出数据阶段:
success:导出成功文件数;
failure:导出失败文件数;
size(MB):导出成功文件大小,单位MB,保留小数点后两位;
time(s):导出耗时,单位秒s;
vel(MB/s):平均导出速度,单位MB/s;
16)merge stage:导出-合并阶段:
success:合并成功文件数;
size(MB):合并成功文件大小,单位MB,保留小数点后两位;
time(s):合并耗时,单位秒s;
vel(MB/s):平均合并速度,单位MB/s;
2.6.3告警
2.6.3.1告警码20001
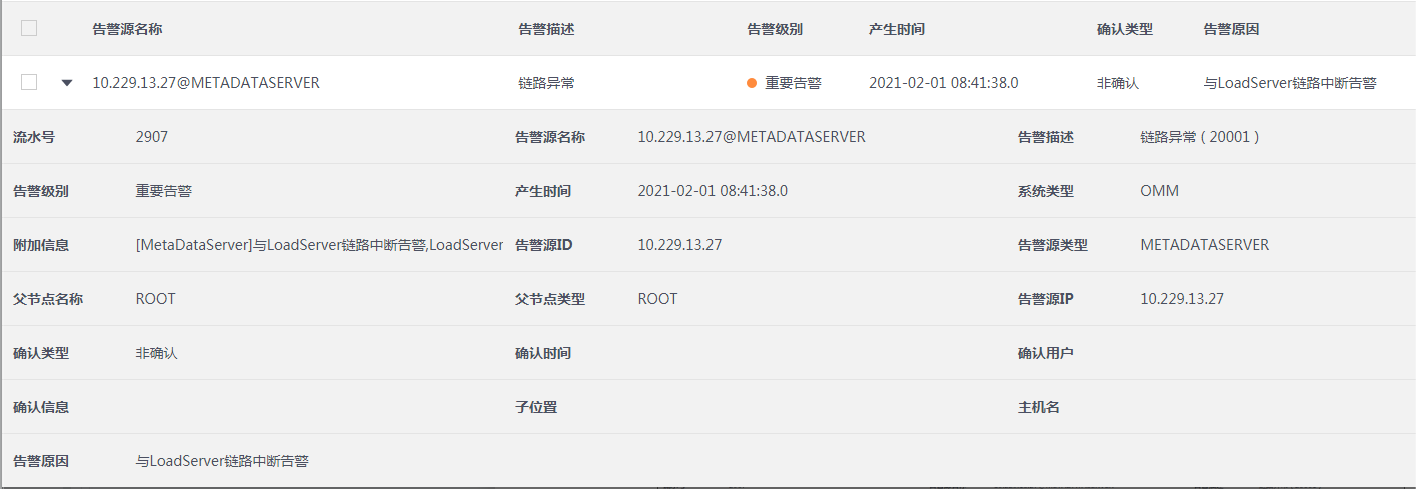
1.loadserver进程异常,与mds断链:
告警由mds处理,并在Insight界面告警管理显示;
2.mds进程异常,与loadserver断链,输出告警信息到告警文件alarm.info,示例如下:
2018-08-03 15:05:21|20001|5|192.168.10.180|||链路异常|LoadServer[192.168.10.180:6261]与MetaDataServer[192.168.10.175:6406]链路断开
3.cm进程异常,与loadserver断链,输出告警信息到告警文件alarm.info,示例如下:
2018-08-03 15:05:21|20001|5|192.168.10.180|||链路异常|LoadServer[192.168.10.180:6261]与ClusterManager[192.168.10.175:6016]链路断开
4.新增loadserver.ini配置项:

1)alarm_file_directory:告警文件alarm.info的目录绝对路径,组件安装成功后默认为空值,空值取默认值 $HOME/log;
2)alarmconf_file_path:告警配置文件绝对路径,组件安装成功后默认为空值,空值取默认值 $HOME/etc/loadserver-alarmconf-utf8.txt;
5.新增告警配置文件loadserver-alarmconf-utf8.txt,文件内容:
20001 5 2000119 链路异常 LoadServer[%s:%d]与%s[%s:%d]链路断开
告警码20002
1.loadserver启动之后,会自动加载License文件,如果License文件不存在或损坏,则会触发告警,并在Insight界面告警管理显示。
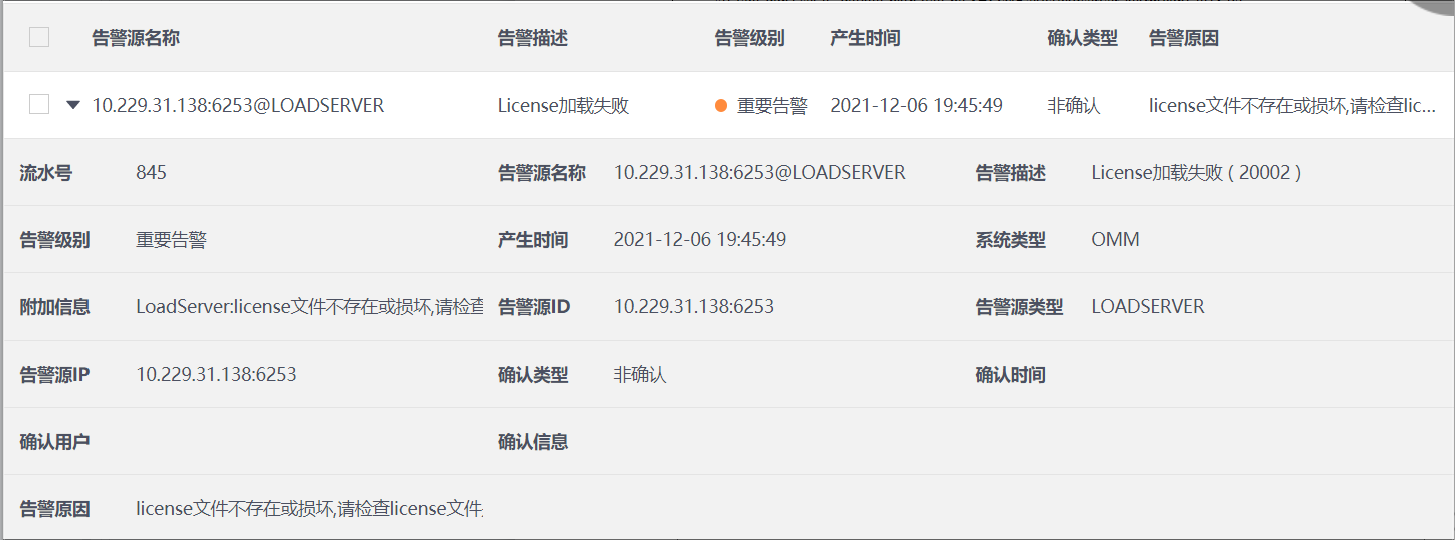
2.输出告警信息到告警文件alarm.info,示例如下:
2021-12-06 19:45:49|20002|5|10.229.31.138|2000221||LoadServer:license文件不存在或损坏,请检查license文件是否正常
3.告警配置文件新增License加载告警码,内容如下:
20002 5 2000221 License加载失败 LoadServer:license文件不存在或损坏,请检查license文件是否正常
4.除了loadserver启动时自动加载License文件,还可以使用dbtool命令动态加载,命令如下:
dbtool -loadserver -load-license或者dbtool -lds -ll
如果dbtool动态加载失败,并且Insight界面没有出现过License加载失败告警,那么会在Insight界面显示失败告警,后续的License加载失败告警会进行归并,最终只显示一条License失败告警。
5.License分为标准版和商用版,只有商用版支持卸数功能。如果在标准版的环境下执行卸数功能,会提示如下信息:
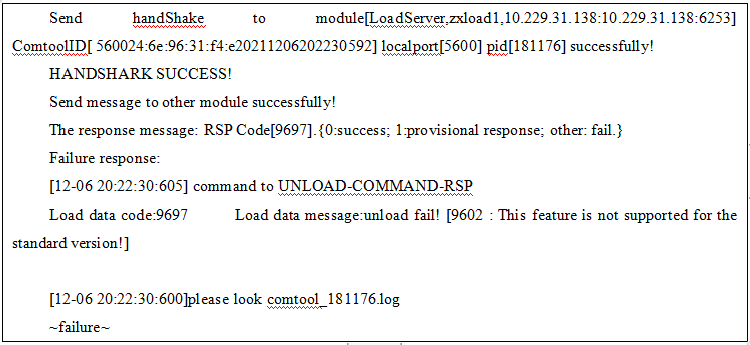
仅支持文件传输协议通道。
1.使用 dbtool 客户端发起导入数据命令:
数据导入命令示例:
dbtool -loadserver -type="in" -clustermode=single -clusterid=1 -sql="load data infile 'loadin.data' into table DN_name.table_name fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
条件:
1)新增参数clustermode,值为single时表示单分片集群模式,不指定该参数时,默认多分片集群模式;
2)单分片集群模式导入不支持数据切片,参数-clustermode=single与-endstate=split同时存在时报错;
2.单分片导入成功客户端返回如下:

3.单分片导入执行数据切片失败客户端返回如下:

4.多分片集群模式下,指定为单分片导入时,导入失败,报错信息如下:

说明:多分片集群模式下,指定为单分片导入时,报错信息为not single group cluster,此时由于找不到单分片集群的分片,groupid显示为0。
5.单分片集群模式下,未指定clustermode=single时,将按照多分片导入进行,报错信息如下:

1.使用 dbtool 客户端发起导出数据命令:
数据导出命令示例:
dbtool -loadserver -type="out" -clustermode=single -clusterid=5 -sql="select id,hotelname,year ,month ,day , rent from load_manual.normal into outfile 'normal.data' fields terminated by ',' lines terminated by 'n';" -user="userA" -password="passA"
条件:
1)新增参数clustermode,值为single时表示单分片集群模式,不指定该参数时,默认多分片集群模式;
2.单分片导出成功客户端返回如下:

3.多分片集群模式下,指定为单分片导出时,导出失败,报错信息如下:

4.单分片集群模式下,未指定clustermode=single时,将按照多分片导出进行,报错信息如下:

由于单分片导入导出相比于多分片,没有获取元数据及拆分(导入)阶段,因此原多分片通过mds及dbutils实现的功能,单分片都不支持,梳理如下:
1.不支持的功能若有对应的导入导出参数,则在参数校验阶段报错:单分片不支持该功能,见如下表格。
| 参数 | 注释 |
|---|---|
-errorignore= | 【导入过程容忍最大错误数据条数,超过该值,导入任务失败】,单分片不支持 |
-endstate=split | 【导入指定拆分阶段】单分片不支持 |
-set-unique-column= | 【导入时指定文件内唯一列】向mds获取元数据阶段实现,单分片不支持该功能 |
2.不支持的功能若没有对应的导入导出参数,则在DN中导入时由mysql返回错误原因,eg:
(1)单分片不支持导入when子句
导入sql语句中含有when关键字,需要dbutils拆分数据阶段根据when指定的条件选择符合的数据导入到DN,单分片时无此阶段,导入到DN时,mysql会报错:mysql:1064:You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'when id < 100' at line 1,lds将错误信息返回客户端。
python bin/batchload.py --host=10.229.43.223 --user=dbproxy --port=7788 --password=*** --databases test --clusterid=1 --type=out --targetdir=/home/zxloadt/test/ --fields-terminated-by=',' --fields-enclosed-by='"' --lines-terminated-by='n' --charset=gbk --suffix=txt --do-tables test.t1 test.t2
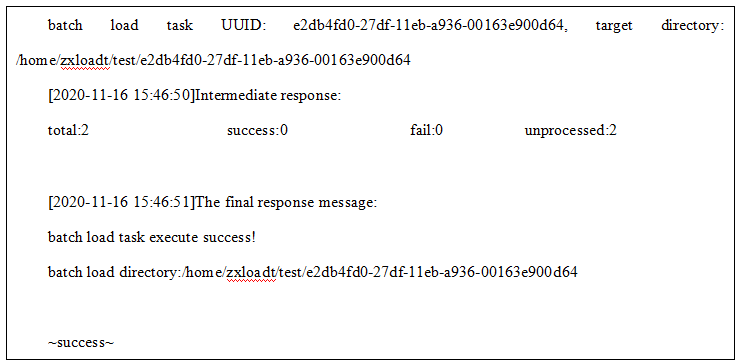
1.使用 batchload.py脚本发起批量导出数据命令:
2.数据批量导出成功客户端返回命令如下,其中可通过UUID在log/batchload.log目录下检索该任务的日志,批量导出文件在target directory指定的目录下:
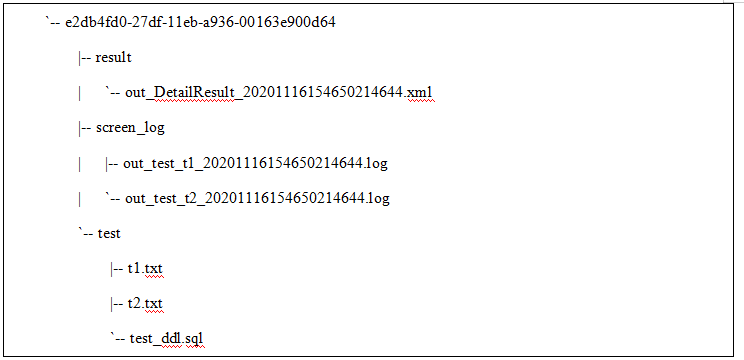
3.导出结果目录如下,其中result为批量导出任务的汇总结果信息, screen_log目录保存各张表的导出comtool打屏日志,其余目录为导出库名,其下则为该库导出表的文件:
1.使用 batchload.py脚本发起批量导入数据命令:
python bin/batchload.py --host=10.229.43.223 --user=dbproxy --port=7788 --password=*** --databases test --clusterid=1 --type=in --targetdir=/home/zxloadt/test/e2db4fd0-27df-11eb-a936-00163e900d64 --fields-terminated-by=',' --fields-enclosed-by='"' --lines-terminated-by='n' --charset=gbk --suffix=txt --do-tables test.t1 test.t2
2.数据批量导入成功客户端返回命令如下,其中可通过UUID在log/batchload.log目录下检索该任务的日志,批量导入不创建库表目录,基于指定目录:
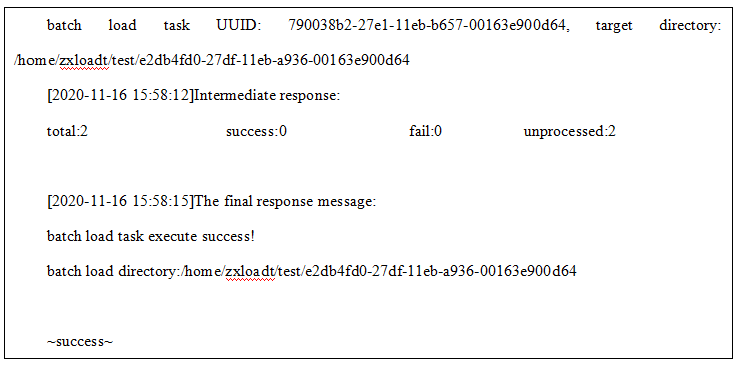
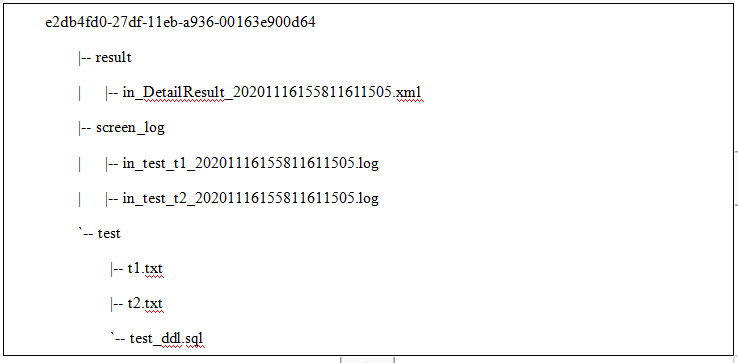
3.导出结果目录如下,其中result为批量导出任务的汇总结果信息, screen_log目录保存各张表的导出comtool打屏日志,其余目录为导出库名,其下则为该库导出表的文件:
4.连接CN查看导入数据信息,数据导入成功:

LDS 的常用部署方式是在LDS端开启文件传输服务(FTP/SFTP),集群中的各数据节点以客户端的方式来获取数据文件。
为了适配现场可能出现的单向组网限制(即只允许LDS作为客户端访问数据节点,不允许数据节点作为客户端访问LDS节点),故支持该反向FTP功能。
本功能的部署方式为集群中的各数据节点开启文件传输服务,LDS在数据导入导出过程中作为客户端将数据文件上传到各数据节点服务器。
LDS配置文件新增配置项:ftp_rule=0,支持配置0:lds act as a server, 1:lds act as a client,默认为LDS作为服务端,支持动态修改配置。
数据节点配置文件增加了该节点的文件服务连接配置参数,使用该功能请确保配置正确且各数据节点启动文件传输服务。
其他使用方式未发生变更。
