




引言
前几天遇到一个线上问题:就是修改了一个实体类的属性(比如加了字段),然后上线代码,而此时生产环境的cache已经把它修改前的序列化缓存下来了(即缓存的exp还未失效),再反序列化就报错,进而影响线上业务。
java.io.NotSerializableException: xxx.xxx.Song
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.defaultWriteFields(Unknown Source)
at java.io.ObjectOutputStream.writeSerialData(Unknown Source)
相信很多人在平时开发过程中只知道将类实现Serializable接口,传输中有个序列化和反序列化的过程。因为很少碰到关于序列化引起的问题,并没怎么关心过序列化的具体原理。最近正好有空对序列化做一些研究。
什么是序列化
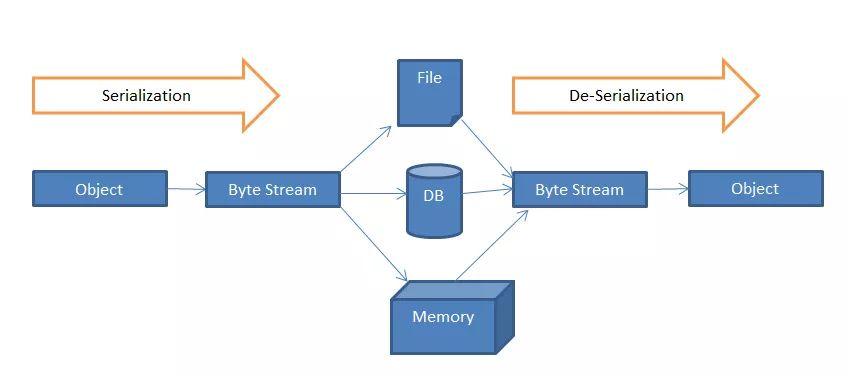
序列化分为两大部分:序列化和反序列化。序列化是这个过程的第一部分,将数据分解成字节流,以便存储在文件中或在网络上传输。反序列化就是打开字节流并重构对象。对象序列化不仅要将基本数据类型转换成字节表示,有时还要恢复数据。恢复数据要求有恢复数据的对象实例。如果某个类能够被序列化,其子类也可以被序列化。需要注意的是声明为static和transient类型的成员数据不能被序列化,因为static代表类的状态,transient代表对象的临时数据。
应用场景
一、对象序列化可以实现分布式对象。主要应用例如:RMI要利用对象序列化运行远程主机上的服务,就像在本地机上运行对象时一样。 二、java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的“深复制“,即复制对象本身及引用的对象本身。
认识serialVersionUID
Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。当实现java.io.Serializable接口的实体类没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID。因此为了实现序列化接口的实体能够兼容先前版本,最好显式地定义一个名为serialVersionUID类型为long的变量,这样就不会存在版本不一致的问题。
敏感信息加密
有时候你在使用序列化时会担心存在安全风险,比如携带用户密码的实体类作序列化和反序列化的时候。也就是说客户端在和服务器之间通信时,有一些敏感信息不便直接在网络上传输,解决方法就是你可以对敏感属性字段进行加密,例如利用DES对称加密,只要客户端和服务器都拥有密钥,便可在反序列化时对加密信息进行读取,这样可以一定程度保证序列化对象的数据安全。下面通过简单的MD5加密来演示一下。
首先新建一个对象,由于在序列化过程中虚拟机会试图调用对象类里的 writeObject 和 readObject 方法进行用户自定义的序列化和反序列化,如果没有这两个方法,则默认调用 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。因此可以在对象里自定义 writeObject 和 readObject 方法,这样就可以完全控制对象序列化的过程,从而可以在序列化的过程中对某些数据进行加解密操作。
public class Student implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private String password;
private Character sex;
private Integer year;
private void writeObject(ObjectOutputStream out) {
try {
//序列化时对password进行base64加密
System.out.println("password: "+password);
byte[] nameByte = password.getBytes("utf-8");
if (nameByte!=null) {
password = new BASE64Encoder().encode(nameByte);
}
System.out.println("encodedPassword: "+password);
out.defaultWriteObject();
} catch (Exception e) {
e.printStackTrace();
}
}
private void readObject(ObjectInputStream in) {
try {
in.defaultReadObject();
//反序列化时对password进行解密
BASE64Decoder decoder = new BASE64Decoder();
byte[] b = null;
if (password!=null) {
b = decoder.decodeBuffer(password);
password = new String(b,"utf-8");
System.out.println("decodedPassword: "+password);
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "Student [name=" + name + ", password=" + password + ", sex="
+ sex + ", year=" + year + "]";
}
public Student(String name, String password, Character sex, Integer year) {
super();
this.name = name;
this.password = password;
this.sex = sex;
this.year = year;
}
public String getName() {
return name;
}
...
}
然后创建一个主测试类:
public class TestSerializable {
public static void main(String[] args) {
try {
//序列化
File file = new File("~/Documents/src/student.out");
ObjectOutputStream oout = new ObjectOutputStream(new FileOutputStream(file));
Student student = new Student("jessehzx", "secret", 'M', 2018);
System.out.println("origin Object:" + student);
oout.writeObject(student);
oout.close();
//反序列化
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(file));
Student deseriStudent = (Student)oin.readObject();
oin.close();
System.out.println("recieve Object:" + deseriStudent);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行得到以下结果,可以看到password在网络通信中被加密为c2VjcmV0,接收端接收到后对其解密得到的值secret与原值相同。
origin Object:Student [name=jessehzx, password=secret, sex=M, year=2018]
password: secret
encodedPassword: c2VjcmV0
decodedPassword: secret
recieve Object:Student [name=jessehzx, password=secret, sex=M, year=2018]
序列化的存储
Java序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用。反序列化时,恢复引用关系,使得以下代码清单中的 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
package top.jessehzx.basic;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class StoreTest implements Serializable {
private static final long serialVersionUID = 1L;
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj"));
StoreTest test = new StoreTest();
// 试图将对象两次写入文件
out.writeObject(test);
out.flush();
System.out.println(new File("result.obj").length());
out.writeObject(test);
out.close();
System.out.println(new File("result.obj").length());
ObjectInputStream oin = new ObjectInputStream(new FileInputStream("result.obj"));
// 从文件依次读出两个文件
StoreTest t1 = (StoreTest) oin.readObject();
StoreTest t2 = (StoreTest) oin.readObject();
oin.close();
// 判断两个引用是否指向同一个对象
System.out.println(t1 == t2);
}
}
第三方序列化工具
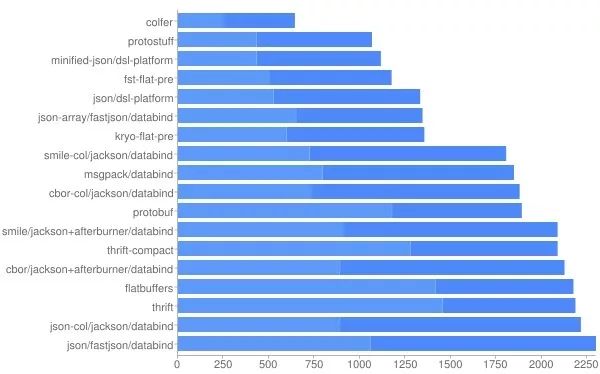
Java 世界最常用的几款高性能序列化方案有 Kryo Protostuff FST Jackson Fastjson。只需要进行一次 Benchmark,然后从这5种序列化方案中选出性能最高的那个就行了。DSL-JSON 使用起来过于繁琐,不在考虑之列。Colfer Protocol Thrift 因为必须预先定义描述文件,使用起来太麻烦,所以不在考虑之列。至于 Java 自带的序列化方案,貌似没有什么问题,其实不然。JDK提供的序列化技术相对而已效率较低。在转换二进制数组过程中空间利用率较差。github上有个专门对比序列化技术做对比的数据:jvm-serializers
Ser Time+Deser Time (ns)
Size, Compressed size [light] in bytes
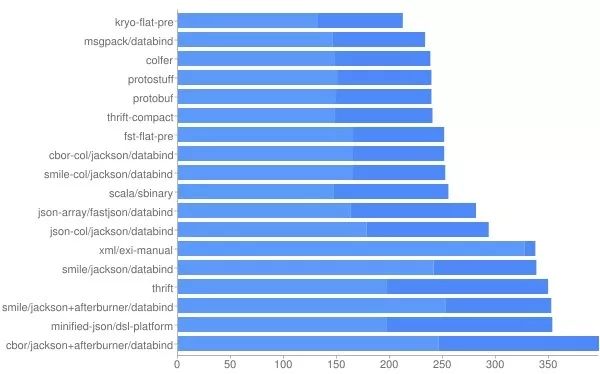
其中看的出来性能最优的为google开发的colfer 。这个框架尽管性能优秀,但它太过于灵活,灵活到Schema都要开发者自己指定,所以对开发者不是很友好。我推荐使用Protostuff,其性能稍弱与colfer,但对开发者很友好,同时性能远远高于JDK提供的Serializable。
Protostuff实践
在工程的pom.xml添加依赖:
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.4.4</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.4.4</version>
</dependency>
使用Protostuff工具实现序列化和反序列化,示例代码:
private static RuntimeSchema<Student> schema = RuntimeSchema.createFrom(Student.class);
public void protostuffTest() {
// 序列化
Student crab = new Student();
crab.setName("jessehzx");
// Object -> byte[]
byte[] bytes = ProtostuffIOUtil.toByteArray(crab, schema, LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));
// 反序列化
Student newCrab = schema.newMessage();
// byte[] -> Object
ProtostuffIOUtil.mergeFrom(bytes, newCrab, schema);
System.out.println("Hi, My name is " + newCrab.getName());
}
不要小瞧这种方式,它的压缩时间是你之前的1/5-1/10,压缩速度差不多减少了2个数量级。另外,这里需要注意一点:
要求这个对象必须是一个标准的有setter/getter方法的POJO,而不能是一个String/Long这样的类型,也不能是List/Map,否则会报concurrentModificationException
总结
通过几个小节,介绍了 Java 序列化的一些高级知识,虽说高级,并不是说读者们都不了解,希望用笔者介绍的情景让读者加深印象,能够更加合理的利用 Java 序列化技术,在未来开发之路上遇到序列化问题时,可以及时的解决。
参考文献
https://github.com/eishay/jvm-serializers/wiki
Java中的序列化Serialable高级详解
(全剧终)

