




1.pw_bulkload
租户进行数据导入,使用pw_bulkload操作时遇到如下两类问题:
- 提示找不到vbbl这个schema
- 提示vbbl这个schema没有权限
提示的文本信息如下:
NOTICE: BULK LOAD START
ERROR: query failed: ERROR: schema "vbbl" does not exist
DETAIL: query was: SELECT * FROM vbbl.pw_bulkload($1)
NOTICE: BULK LOAD START
ERROR: query failed: ERROR: permission denied for schema vbbl
DETAIL: N/A
DETAIL: query was: SELECT * FROM vbbl.pw_bulkload($1)
对应的截图如下:


pw_bulkload模拟测试
1.首先在db下使用管理员权限账号创建pw_bulkload扩展
CREATE EXTENSION pw_bulkload;
通常连接默认管理库postgres,如果在其他db下使用,也需要在相应的db下执行该操作,否则会出现上面的第1个错误:找不到vbbl这个schema
2.在db下对普通用户赋予vbbl模式的usage权限,使其可调用后续的接口函数
GRANT usage ON SCHEMA vbbl TO admin;
如果不执行该步骤,会出现上面的第2个错误:提示vbbl这个schema没有权限
3.使用pw_bulkload的命令项加载数据
创建测试表
CREATE TABLE test_bulkload(id INT, name VARCHAR);
创建txt文件,写入10个W数据:
$ seq 100000| awk '{print $0"|bulkload"}' > bulkload_output.txt
最后执行如下命令:
$ pw_bulkload \
--input=./bulkload_output.txt \
--output="admin.test_bulkload" \
--option="TYPE=csv" --option="DELIMITER=|" \
--option="ERROR_RECOVERY=YES" \
--port=17700 --dbname=postgres --username=admin --password
注意:
1.连接到哪个db进行操作,就需要在哪个db下创建扩展
2.output参数表名要加模式前缀
3.设置ERROR_RECOVERY=YES,在导入出错时清理本次导入数据。
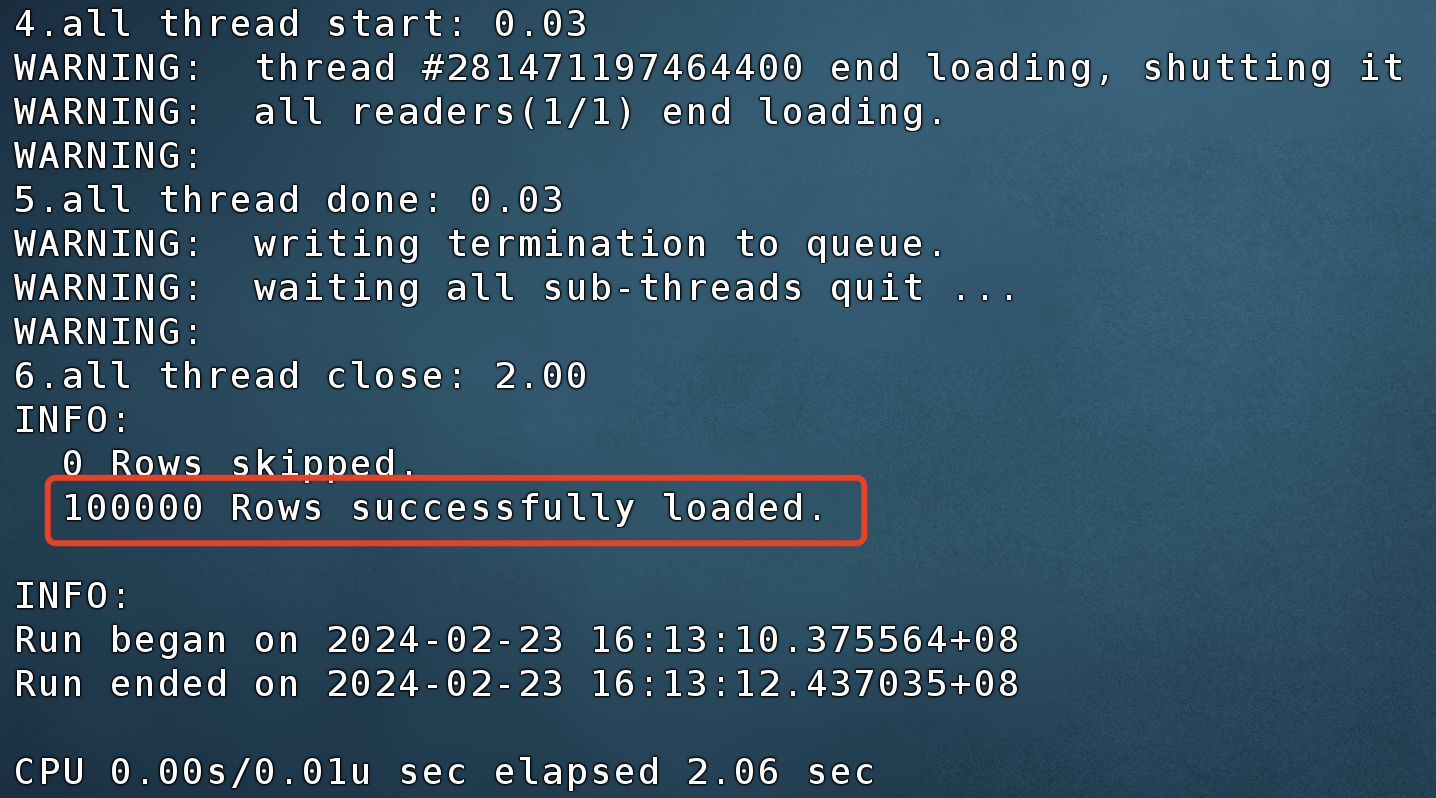
成功导入的截图如下:
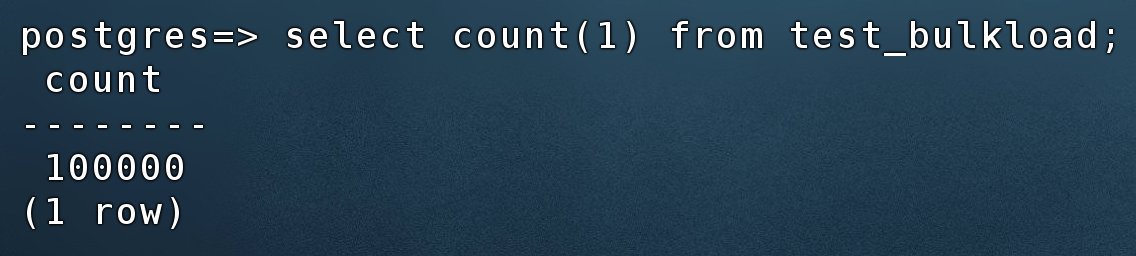
查看数据:
4.使用pw_bulkload的控制文件加载数据
可以先清空导入的数据
TRUNCATE TABLE test_bulkload ;
编写.ctl文件
INPUT=/home/panwei/bulkload_output.txt
OUTPUT = admin.test_bulkload
TYPE = CSV
DELIMITER = |
ERROR_RECOVERY=YES
执行命令:
$ pw_bulkload ./my.ctl \
--port=1521 --dbname=postgres --username=admin --password
最后:pw_bulkload插件的设计应该允许指定到public模式更合适。
2.批量插入
使用psql进行数据插入时可使用copy或\copy元命令对数据文件进行批量操作,在JDBC里有两种方式。
方式一:使用reWriteBatchedInserts参数,可将多条insert合并为一条insert,使用insert…values(?),(?)…多values的形式
jdbc:panweidb://ip:port/database_name?reWriteBatchedInserts=true&batchMode=off
注意需要设置batchMode=off,否则会出现如下错误:
batchMode and reWriteBatchedInserts can not both set true!
方式二:使用batchMode=on
jdbc:panweidb://ip:port/database_name?batchMode=on
行存表场景建议使用batchMode=on,插入性能提升更明显。
3.自动保存
psql可使用内置变量ON_ERROR_ROLLBACK,设置为on时允许事务块内的语句遇到错误时,可以被忽略,不回滚整个事务而继续执行。
它的原理是对事务块里的每个语句执行前都创建一个SAVEPOINT保存点,遇到语句执行出错后ROLLBACK到失败语句的保存点,然后继续往下执行。
JDBC里也可以设置autosave参数,功能类似于psql里的ON_ERROR_ROLLBACK。
jdbc:panweidb://ip:port/database_name?autosave=always
使用autosave=always参数进行批量插入时,会创建较多的保存点,可能造成导入较慢,因为保存点未及时清理释放。
注意:从JDBC 42.2.6才开始支持cleanupSavepoints参数,如果使用较低版本的JDBC需要升级一下驱动。
4.B模式下自增主键:auto increment
磐维2.0还支持B模式下auto increment语法,但auto increment语法不支持序列语法方式修改
ALTER LARGE SEQUENCE tab1_id_seq RESTART WITH 1;
ERROR: cannot alter sequence owned by auto_increment column
需要使用如下方式修改:
ALTER TABLE tab1 AUTO_INCREMENT = 1;
5.localhost监听问题
创建函数或者存储过程时,提示
error:autonomous transaction failed to create autonomous session
该问题与数据库监听有关,服务端没有配置localhost的监听,在创建存储过程的时候,会创建一个自治事务,这个自治事务的本质上就是服务端自己建立一个目标为localhost的无密码连接,如果localhost无法登录,就会报这个错。
例如监听配置:listen_addresses=“192.168.20.100”
解决方案:配置listen_addresses="*"。
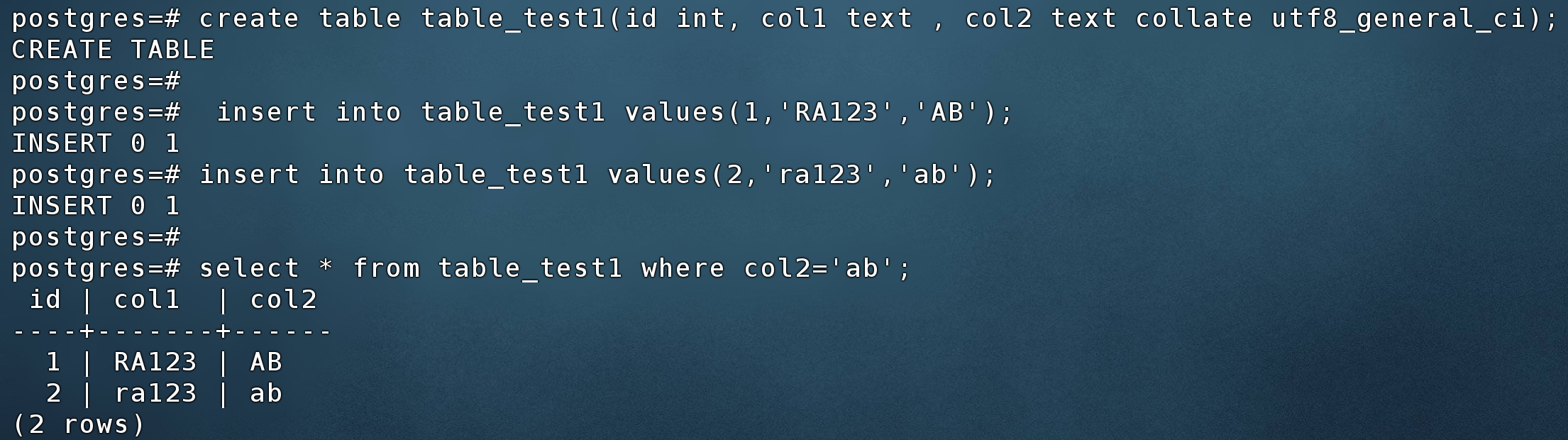
6.数据内容大小写不敏感
PG可以使用citext插件创建citext数据类型,citext数据类型是一个不区分大小写的文本类型,允许在进行文本比较时忽略大小写。
使用场景:citext类型通常用于存储需要忽略大小写的文本数据,如用户名、密码等。通过使用citext数据类型,可以在进行文本比较时更加方便和快速。
在磐维里:PG和A模式下编译citext插件创建citext类型,B模式下对字段设置collate utf8_general_ci即可。
7.如何使用job
磐维2.0支持A模式下使用DBMS_JOB接口函数使用job
提交job: submit
方式一:
DBMS_JOB.SUBMIT ( in id bigint, in content text, in next_date timestamp without time zone default sysdate, in interval text default 'null', out job integer);
方式二:
DBMS_JOB.SUBMIT ( job OUT BINARY_INTEGER, what IN VARCHAR2, next_date IN DATE DEFAULT sysdate, interval IN VARCHAR2 DEFAULT 'null', no_parse IN BOOLEAN DEFAULT FALSE, instance IN BINARY_INTEGER DEFAULT any_instance, force IN BOOLEAN DEFAULT FALSE);
方式二在传参时使用参数名=>参数值的写法,该用法仅在数据库兼容模式为Oracle时支持
create table t_test(insert_date timestamp);
create or replace procedure p_test()
as
begin
insert into t_test values(sysdate);
COMMIT;
end;
/
DECLARE
JOB_NUM NUMBER;
BEGIN
DBMS_JOB.SUBMIT(JOB=>JOB_NUM,
WHAT => 'p_test;',
NEXT_DATE => SYSDATE,
INTERVAL => 'TRUNC(SYSDATE,''MI'')+(1)/(24*60)');
COMMIT;
END;
/
运行job: run
DECLARE
JOB_NUM NUMBER;
BEGIN
SELECT A.JOB INTO JOB_NUM FROM DBA_JOBS A WHERE WHAT = 'p_test;';
dbms_job.run(JOB_NUM);
COMMIT;
END;
/
修改job: change
修改job名称:
DECLARE
JOB_NUM NUMBER;
BEGIN
SELECT A.JOB INTO JOB_NUM FROM DBA_JOBS A WHERE WHAT = 'p_test;';
dbms_job.change(JOB_NUM,'newname;',sysdate,'''1min''::interval');
COMMIT;
END;
/
查看任务当前执行状
select broken from dba_jobs where what ='newname;';
停止/恢复job: broken
DECLARE
JOB_NUM NUMBER;
BEGIN
SELECT A.JOB INTO JOB_NUM FROM DBA_JOBS A WHERE WHAT = 'newname;';
DBMS_JOB.BROKEN(JOB_NUM,TRUE, SYSDATE);
COMMIT;
END;
/
删除job: remove
select dbms_job.remove(2108);
DECLARE
JOB_NUM NUMBER;
BEGIN
SELECT A.JOB INTO JOB_NUM FROM DBA_JOBS A WHERE WHAT = 'newname;';
dbms_job.remove(JOB_NUM);
COMMIT;
END;
/
与兼容性无关的使用方式:
create table t_sub(insert_date timestamp);
select dbms_job.submit(1,'insert into t_sub values(now());',now()::timestamp without time zone,'''1min''::interval');
select dbms_job.run(1);
select dbms_job.broken(1,true);
select dbms_job.remove(1);
8.Java里的double类型存储到varchar精度丢失问题
数据库表结构如下:
create table t1(a varchar);
Java使用double类型插入数据主要代码如下:
String sql = "insert into t1 values(?)";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setObject(1, new Double(48)); ps.execute();
ps.setObject(1, new Double(48.1)); ps.execute();
ps.setObject(1, new Double(48.9)); ps.execute();
应用端应该使用如下几种方式改写:
insert into t1 values(?::numeric)
String.valueOf(new Double(48.1))
new BigDecimal("48.1")
9.存储过程如何返回多个查询结果集
表结构如下:
create table fiverows(id serial primary key,data text);
insert into fiverows(data) values('one'),('two'),
('three'),('four'),('five');
存过定义如下
create or replace procedure curtest(
out cur1 refcursor,out cur2 refcursor)
as
begin
open cur1 for select id,data from fiverows where id between 1 and 3;
open cur2 for select id,data from fiverows where id between 4 and 5;
end;
/
gsql里测试调用:
postgres=> BEGIN;
BEGIN
postgres=> CALL curtest(NULL,NULL);
cur1 | cur2
--------------------+--------------------
<unnamed portal 1> | <unnamed portal 2>
(1 row)
postgres=> FETCH ALL "<unnamed portal 1>";
id | data
----+-------
1 | one
2 | two
3 | three
(3 rows)
postgres=> FETCH ALL "<unnamed portal 2>";
id | data
----+------
4 | four
5 | five
(2 rows)
JAVA测试关键代码如下:
conn.setAutoCommit(false);
CallableStatement stmt = null;
ResultSet resultSet = null;
stmt = conn.prepareCall("{call curtest(?,?)}");;
stmt.registerOutParameter(1, Types.REF_CURSOR);
stmt.registerOutParameter(2, Types.REF_CURSOR);
stmt.execute();
resultSet = (ResultSet) stmt.getObject(1);
...
resultSet = (ResultSet) stmt.getObject(2);
while(resultSet.next()){
Integer id = (Integer)resultSet.getInt(1);
String data = (String) resultSet.getString(2);
}
