




小朋友都能懂的人工智能⓸ -狗大师的修仙之路
小朋友都能懂的人工智能⓺ -注意,句中高能!
第9集导读
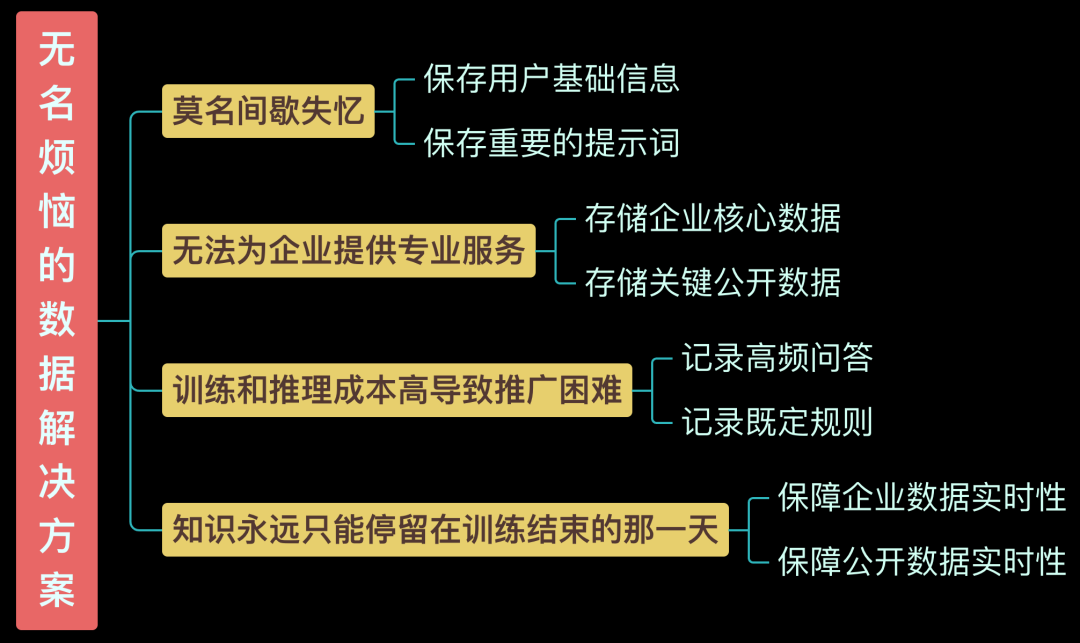
然而,随着信息的积累,处理能力终将到达极限,旧信息必须让路给新信息,于是无名失忆了,此时,终于到了数据库闪亮登场发挥作用的时候!通过将用户基础信息和重要提示词持久化,数据库不仅帮助无名克服了遗忘的困扰,还极大地提升了其效率和准确性。
更深入地看,大模型结合数据库的好处远不止于此。通过记录高频问答和既定规则,从而减轻大模型的计算负担,提高响应速度,大幅降低成本。而存储实时更新的企业核心数据和关键公开数据,则可以助力智能推荐、超级客服、超级助理等逆天能力等,让大模型迈向专业化和和个性化....
Hi AI, Database is all you need!
来,走进第9集,一起体验吧。
「 32. 体检报告与大师论道」
L:无名和老智一路奔波,终于见到了甲骨大师。老甲立即为无名安排了一次全身体检,检查完毕后老甲望着体检报告陷入沉思。老智见状着急地问,这能治好吗?老甲没有直接回应,而是给老智分析起了体检报告,就这样,大师之间的对话开始了。

老甲:原来如此,从报告来看,无名的思考过程分三阶段,第一个是对输入的信息进行处理,首先是分词,把一句话分成一个个有意义的单元,比如单词或词组啥的。然后将这些单元进行编码,转换成无名能读懂的01数字组合。接着将编码过的各单元和嵌入层的高维语义向量空间进行映射,实现了对词的理解,这里的高维语义空间存储了极其丰富的词信息。看来这无名平时下了不少苦功夫进行自我训练吧?
老智:老甲真乃神人也!是的。这个阶段是输入层。无名确实很刻苦,他已经读完数以千万计的书籍论文等资料。


「 33. 流程细解与真相大白」
C妈:L老师,老智和老甲的对话太深奥了,又词语接龙又问答接龙,我都听糊涂了。
A:L老师,这个词语接龙的方式您之前没提起过,我以为就是一口气说出来的,这一个词一个词输出,我还是有些听不明白?
A爸:C妈、小A,你们听的不够仔细吧,我是听明白了词语及问答接龙是啥意思。不过两位大师都明白了无名失忆的问题所在,这我可就不明白啊,问题出在哪呢?
L:嗯,两位大师之间的论道确实有些深奥,也难怪C妈和小A听迷糊了,不过请放心,大家肯定可以弄得清清楚楚,明明白白的。
假定问题Q1为“猫是什么颜色的?”,而GPT-4的回答A1为“通常是白色、黑色或橘色。”为更好地进行示例,我们进行一个简单的编码,如下。
问:猫是什么颜色的? 分词后用字母 A = “猫” B = “是” C = “什么” D = “颜色” E = “的” F = “?” |
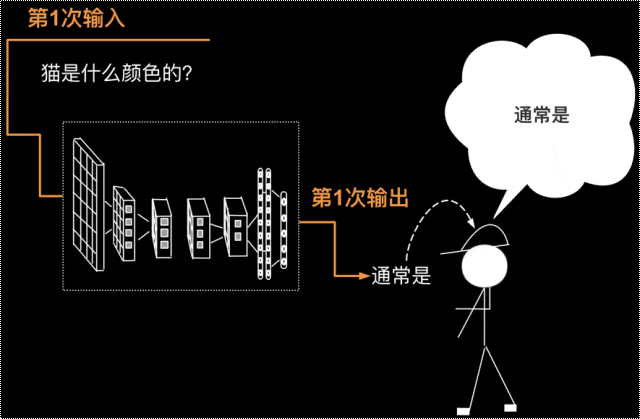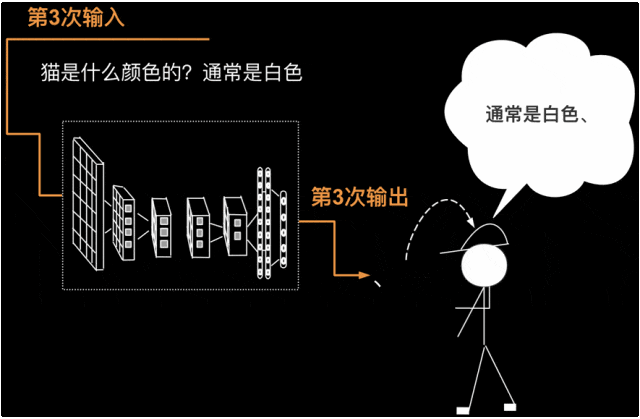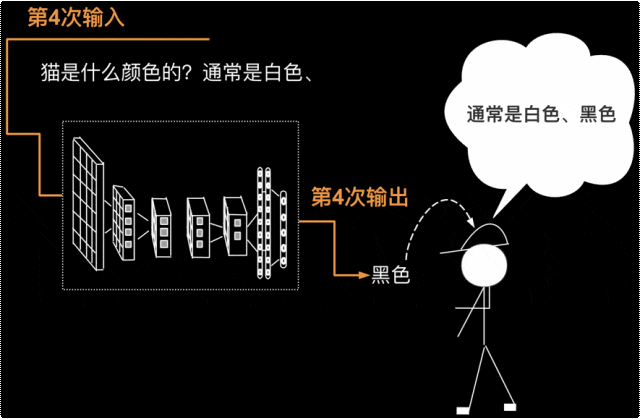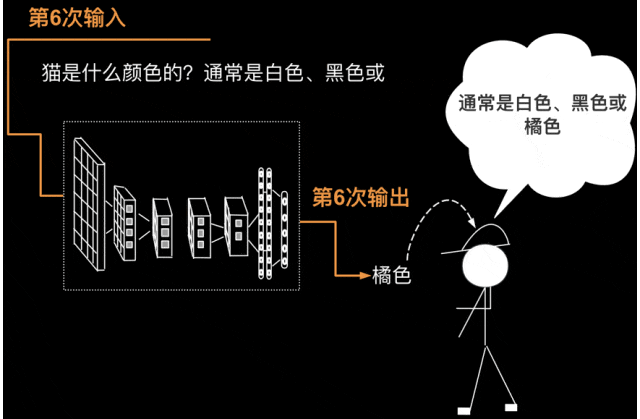
接下我们来按照GPT-4生成文本的步骤,说说单次问答的输出与输入之间的词语接龙,到底是怎么回事,来,我详细的给大家演示一下。第1次输入”猫是什么颜色的“。第一次输出“通常是“,如下图所示。
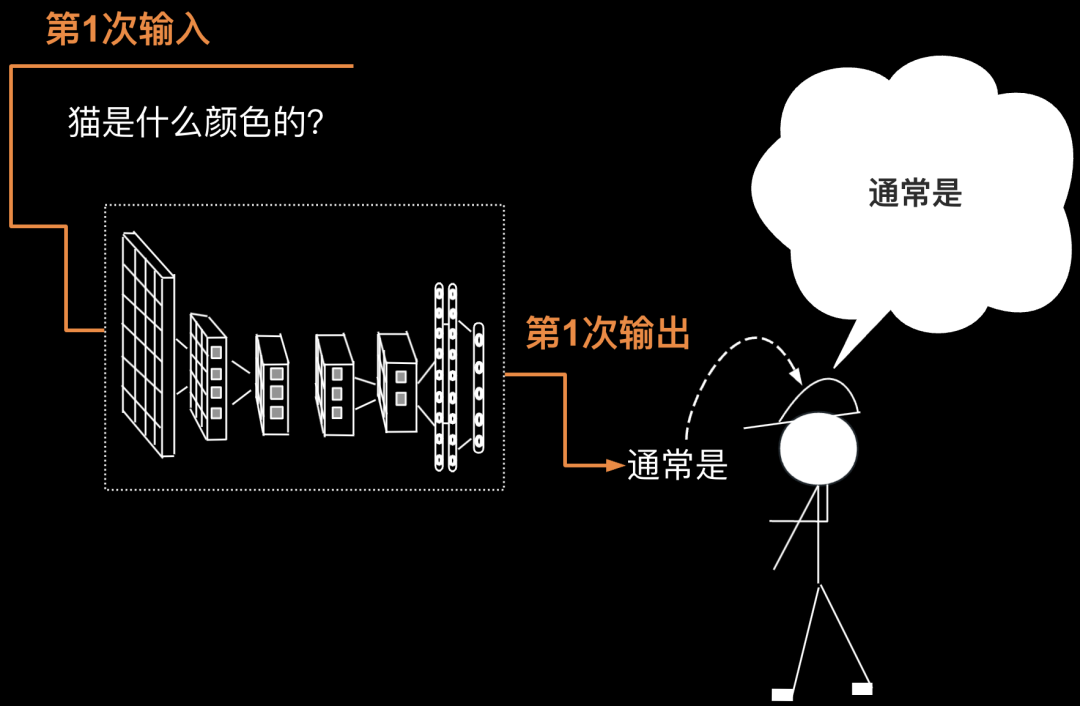
第2次要把第1次的输出返回给输入(第1次的输出为“通常是”)。于是第2次输入为“猫是什么颜色的?通常是”。第2次输出为“白色”,如下图所示。
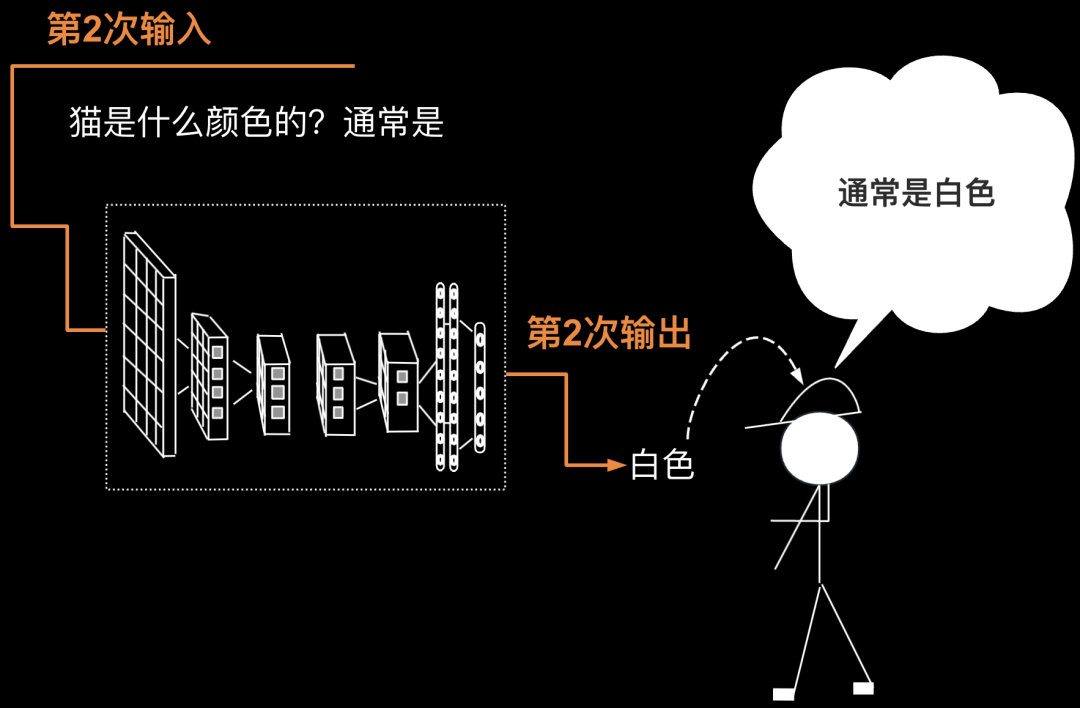
第3次要把第2次的输出返回给输入(第2次的输出为“白色”),则第3次输入为“猫是什么颜色的?通常是白色”,第3次输出为一个符号——顿号。如下图所示。
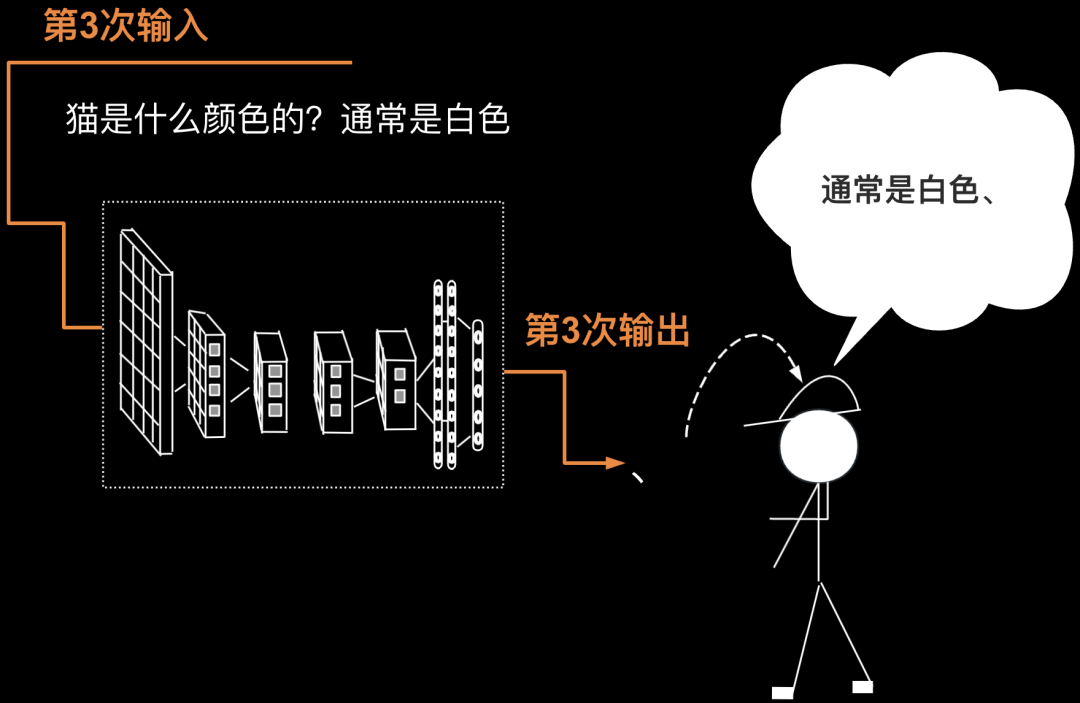
第4次要把第3次的输出返回给输入(第3次的输出为一个符号——顿号),则第3次输入为“猫是什么颜色的?通常是白色、”,第4次输出为”黑色“。如下图所示。
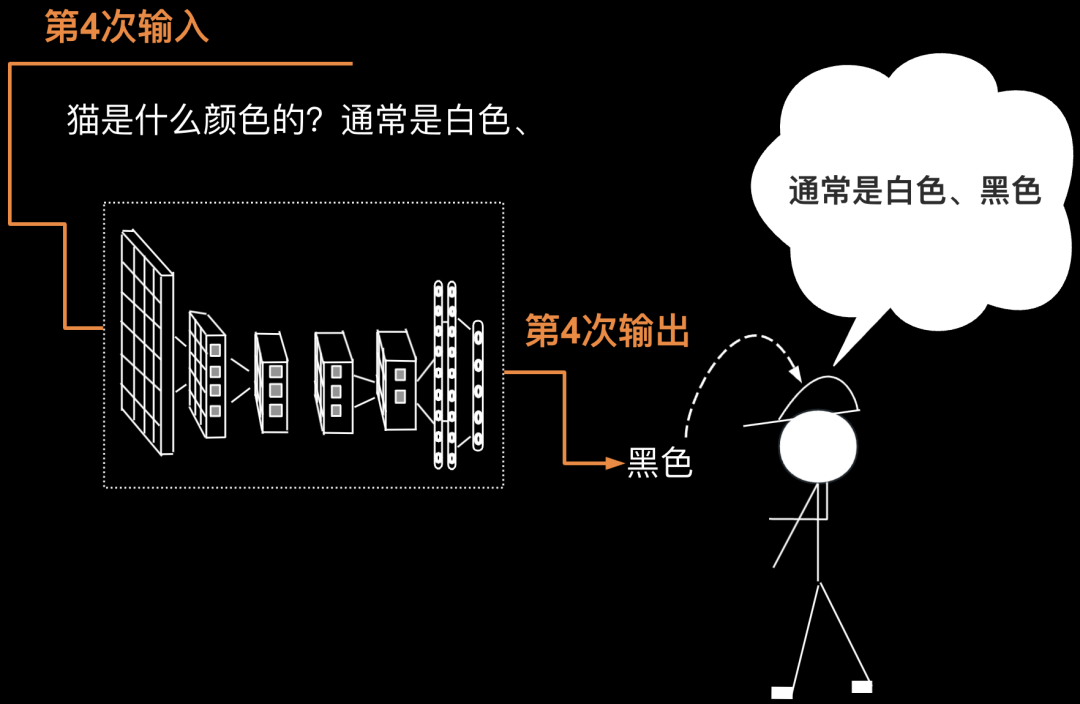
第5次要把第4次的输出返回给输入(第4次的输出为”黑色“),则第4次输入为“猫是什么颜色的?通常是白色、黑色”,第5次输出为”或“。如下图所示。
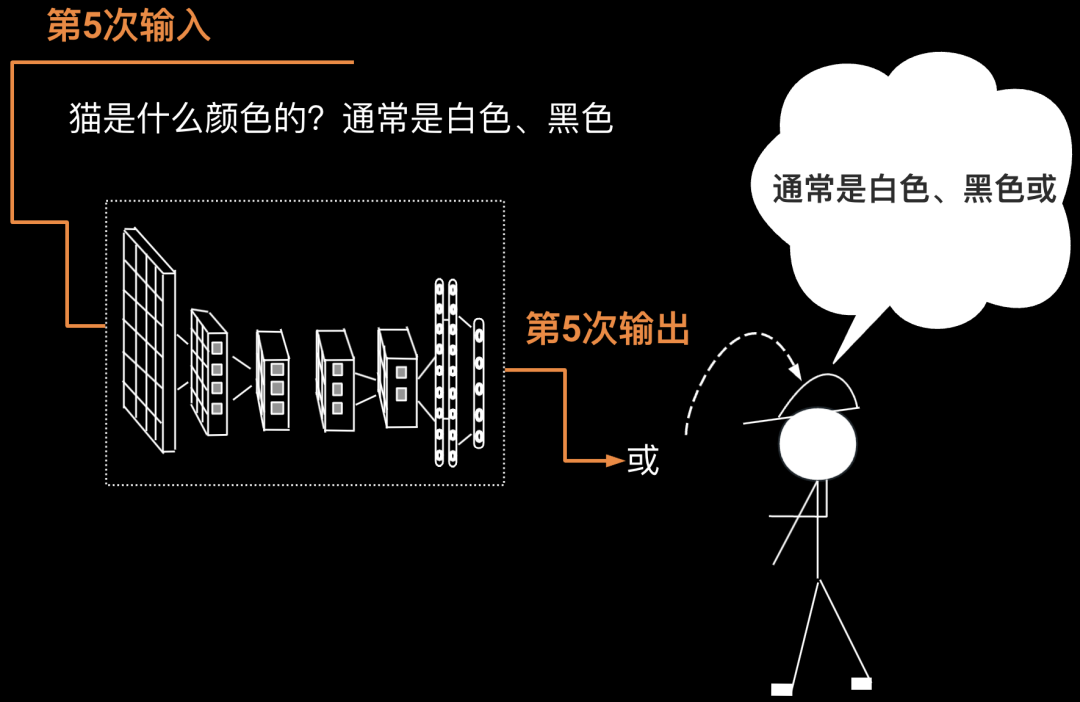
第6次要把第5次的输出返回给输入(第5次的输出为”或“),则第5次输入为“猫是什么颜色的?通常是白色、黑色或”,第6次输出为”橘色“。至此回答圆满结束,对面的人得到了完整的答案”通常是白色、黑色或橘色“。如下图所示。
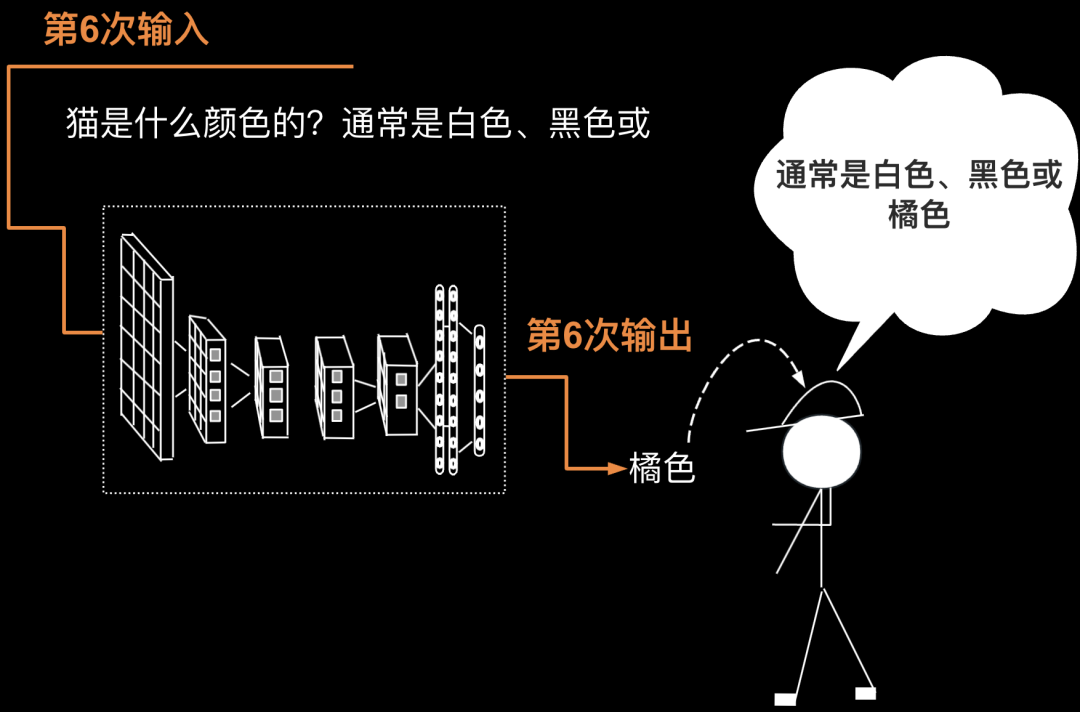
接下来做一个的总结,将全过程整理成表格如下(这里的分词代号见前文)。
轮 次 | 输入 | 输出 | ||
| 输入文字 | 分词代号 | 输出 文字 | 分词 代号 | |
| 1 | 猫是什么颜色的? | ABCDEF | 通常是 | G |
| 2 | 猫是什么颜色的?通常是 | ABCDEF G | 白色 | H |
| 3 | 猫是什么颜色的?通常是白色 | ABCDEF GH | 、 | I |
| 4 | 猫是什么颜色的?通常是白色、 | ABCDEF GHI | 黑色 | J |
| 5 | 猫是什么颜色的?通常是白色、黑色 | ABCDEF GHIJ | 或 | K |
| 6 | 猫是什么颜色的?通常是白色、黑色或 | ABCDEF GHIJK | 橘色 | L |
| 7 | 猫是什么颜色的?通常是白色、黑色或橘色 | ABCDEF GHIJKL | 。 | M |
问题1=Q1 回答1=A1 | Q2:猫可以吃巧克力吗? A2: 不可以,巧克力对猫有毒。 | 问题3=Q3 回答3=A3 |
接着问答接龙开启了:具体给大家演示一下,第1轮循环:Q1: “猫是什么颜色的?”A1: “通常是白色、黑色或橘色。” 如下图所示。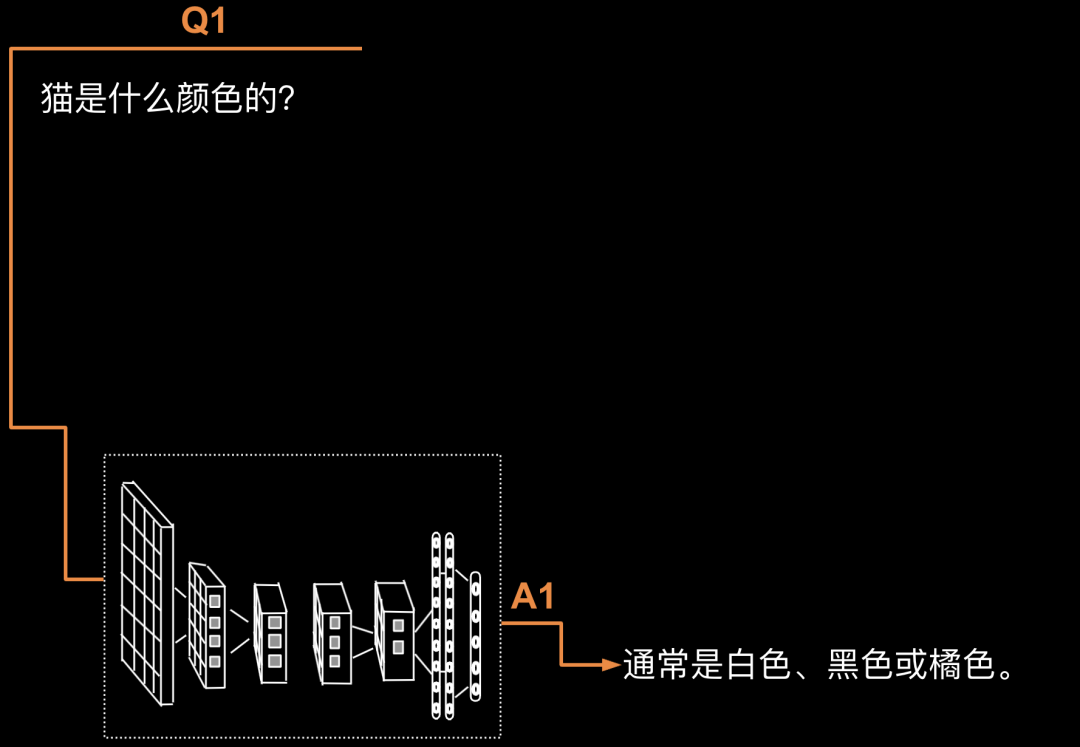
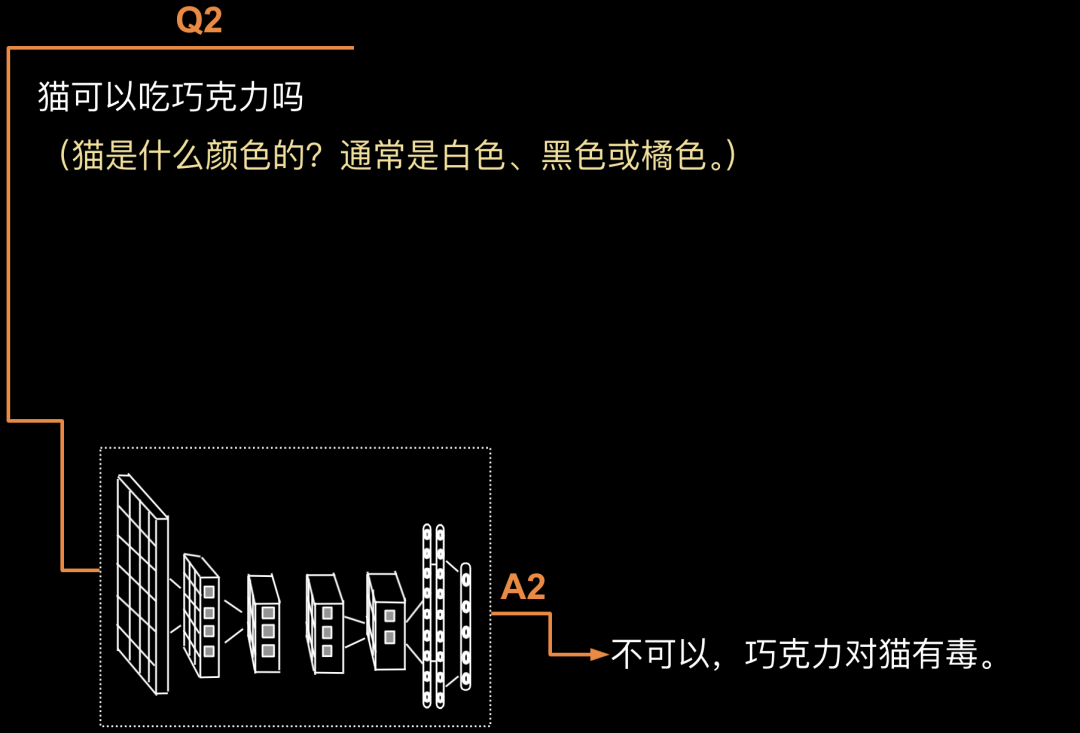
第2轮循环:Q2: “猫可以吃巧克力吗?”此时,模型会把Q1+A1+Q2作为新的输入来生成A2。A2: “不可以,巧克力对猫有毒。”如下图所示。
第3轮循环:Q3: “那狗可以吃巧克力吗?”根据Q1+A1+Q2+A2+Q3,模型生成A3。A3: “狗也不能吃巧克力,对它们有害。”如下图所示。
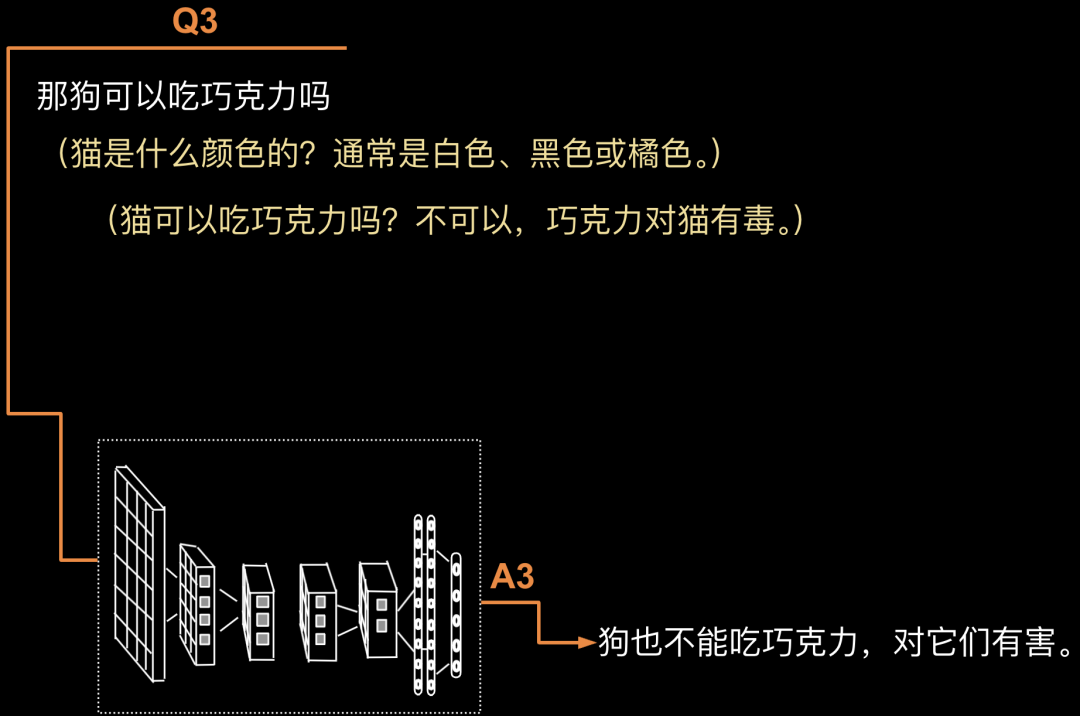
前面已经详细介绍了得出A1是一个循环过程。于是这里出现了内外两套循环,是不是很有趣。
C妈:L老师,回答单个问题的词语接龙这种循环方式我能理解,边说边揣摩,思路建立在自己说出来的话中。但是问答接龙这种循环方式我就有点不明白了,把以前问过的问题和解答再输入到新问题中,有啥意义呢?
L:这个意义可大了!你想想,你和一个人聊天,双方都记不住之前聊的内容,万一新的交谈和之前的问答有依赖关系,请问咋办?
C妈:哦,对啊,我怎么没想到这一点。
L:其实说穿了很简单,你想想看,如果问答的模式一直继续,那就是Q1+A1+Q2+A2+Q3+A3+Q4+A4....+Qn+An。但是这么一直循环下去,问答所需处理的信息量不断增加,必然会产生性能瓶颈,所以我们必须只保留一定数目的问答,换句话说就是要抛弃旧的问答,比如抛弃Q1A1Q2A2,变成Q3+A3+Q4+A4....+Qn+An。你们现在明白无名为什么失忆了吗?
A爸:哦,我明白了!事情的过程应该是这样的。老智在Q1或Q2等早期问答中给无名做了自我介绍,但是到后期,无名为保障性能不得不将早期问答丢弃掉。这样老智的自我介绍等信息就没了。于是无名就不知道老智是谁了,失忆了!
L:是的,回答正确!此外,无名参加AI盟主争霸赛这事,老智自然是告诉过无名的,同样出于性能保障的原因,无名把自己参赛的信息丢弃了,所以无名便不知道自己手上拿的AI盟主令牌到底是什么。
众人会心一笑,无名的病因至此真相大白!
「 34. 无名有救了!」
L:好,了解了大模型工作机制后,大家也就知道了无名为何失忆,那该怎么治疗呢?
A:那信息不要丢弃,一直保留,给无名吃点什么神药,让他处理越来越多的文字信息也没问题。
L:这个神药去哪里找啊?不过小A其实说的也有道理,对应到大语言模型GPT-4倒还是真有神药,那就是配置更多、更先进的服务器、GPU等。只是这需要大量的资金投入,而且并不能保证持续有效啊。
A爸:那怎么办,我也没想好啊。
L:大家知道我们说的无名就是特指大语言模型,无名记不住自己是谁,记不住老智是谁,也记不住自己来这里参加什么比赛,其实就是指向大语言模型存在的一个问题,缺乏长期记忆。怎么办?其实也不难,那就把这些信息单独记录下来保存起来存进数据库中,让大语言模型在回答问题时首先调用数据库检索基本信息,再进行回答问题,不就OK了吗?
C妈:数据库?您的意思是GPT-4这类大语言模型,在运行阶段并没有使用数据库?
L:是的,其实道理讲起来也很直白简单,大家知道无论是常用汉语还是常用英文单词,其个数都是非常有限的。GPT-4的原理是依赖内部参数和算法来组合这些有限的汉字和英文单词,最终输出回复结果。也就是说,它是“思考”出答案,非从数据库中找到现成的答案,所以从这个角度来看,GPT-4确实不需要数据库来存储大量的数据。

但是从和一个人的交流来看,对面前的人了解的越多,你就越能有针对性的给予更好的帮助。比如这个人的姓名、性别、国籍、年龄、学历、职业、特长、宗教信仰....
这些信息表面上看可能和交流的问题无关,实际上影响着交流的质量,比如知道你是一个小朋友,就会尽量用通俗易懂的方式来和你交流,让你更易于理解,他了解你的职业就会针对你的职业做更专业的回答。
此外,在使用GPT时有一个很有用的技巧,那就是提示词。比如你在提问时增加一句,”请一步一步思考,有依据,不瞎编” 就能大幅降低GPT在回复时胡言乱语的可能性。比如你在提问时增加一句“请回答的越详细越好”,就会避免有些问题回答的过于简单。比如你在提问时增加一句“请出图时,提供图片的generation id",则可以后续根据这个id进行调整,确保图片风格的一致性,包括为其设定角色,比如说“你是一个人工智能专家”,GPT就会飘飘然起来,真把自己当专家了,然后回答的特别认真....关于提示词有很多很多,也非常经典实用。后续我们可以详细介绍,这里就不再赘述了。这类提示词也是可以保存进数据库中的,这样就不用每次提问的时候都重复这样的提示。
C妈:提示词听起来真有趣,以后您一定得找一个时间和我们说说。
L:好!
A爸:看来,无名有救了!
「 35. Hi AI, Database is all you need」
L:是的,我们继续听听两位大师的论道。话说老甲诊断完毕,心中有数了,当即写下治疗方案递给老智,老智定睛一看,赫然写着五个大字“植入数据库”。


L:至此无名求医之路完美收官,两人心情大好。返回途中名心无旁骛只顾着欣赏沿途美景,而此刻老智的心中,却在酝酿着一个更为宏大的计划。
A爸:什么计划?
L:暂时保密。对了,老智给无名植入的数据库是两种不同模型数据库的集合体哦,分别是关系模型数据库和向量模型数据库。你们知道这两种数据库的差异吗,知道这两种数据库分别存储了哪些不同的数据吗?
众人纷纷摇头。
L:接下来咱们就细说数据库,内容将非常的有趣、有料,易懂且实用,时候不早了,咱们下回分解。
预告:《超融合数据库》即将出版,关注梁老师公众号,敬请期待。

