





云原生数据库PolarDB分布式版(PolarDB for Xscale,简称PolarDB-X)有极强的线性扩展能力,能够多写多读;它的全局索引能力,是分布式改造的利器,成功解决了传统分布式方案中多维度查询的难题,在《香肠派对》的好友系统上,实现了百亿好友关系20万QPS的毫秒级查询。
真有趣(So Funny)成立于2012年8月,致力于为全球用户提供健康有趣快乐的游戏体验与服务。目前已推出《香肠派对》、《不休的乌拉拉》、《仙侠道》等9款游戏,累计服务2亿多用户。这里聚集着一群有趣的人,秉持用户第一、热爱创作、讲逻辑的理念,为赢得百万人热爱而奋斗!
在TAPTAP上,《香肠派对》有2.3亿的下载量,有着庞大的玩家群体:

用户关系定义
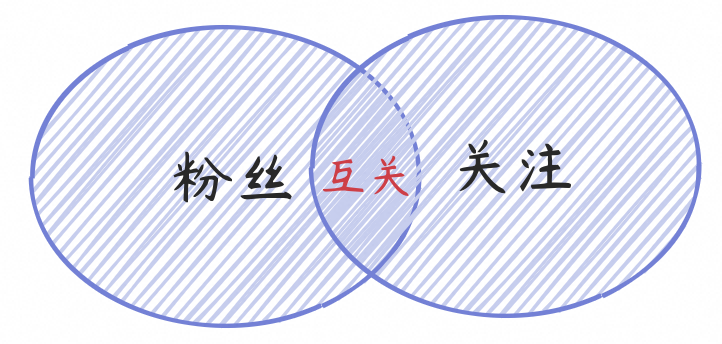
用户关系是游戏类应用非常普遍的场景,需要存储用户或者玩家之间的相互关系,通过社交关系提升用户的活跃度以及黏性,帮助玩家及时找到有关联的好友。在用户关注关系中,主要包含几种状态:
1. 关注我的人->我的粉丝(fans);
2. 我关注的人->我的关注(follow);
3. 相互关注的人->互关(mutual);
用户关系系统架构与特征

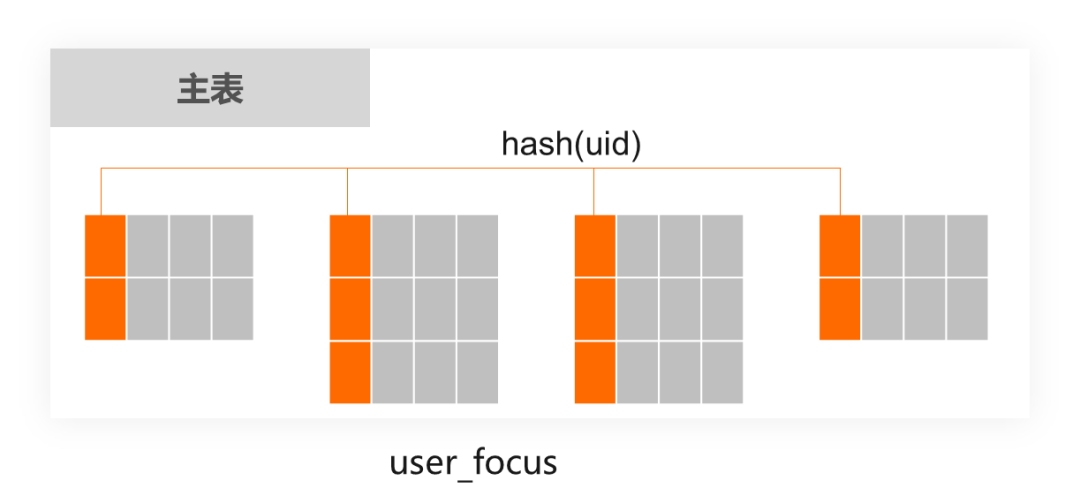
create table user_focus(id bigint primary key,uid bigint, -- 用户IDfocus_uid bigint, -- 关注的用户IDextra varchar(1024), -- 其他业务属性index idx_focus_uid(focus_uid),index idx_uid(uid))
如果一个用户关注了100个人,那么在这张表里有100条记录,目前整个关注表达到了百亿的量级。
这张表有以下几种访问模式:
1. 获取某个用户的关注列表(我关注了谁):
select * from user_focus where uid=xxx;2. 获取某个用户的粉丝列表(谁关注了我):
select * from user_focus where focus_uid=xxx;
3. 圈定一批人,他们关注了谁,谁又关注了他们(用于好友推荐):
select * from user_focus where uid in (xxxx);select * from user_focus where focus_uid in (xxxx);
很容易理解,该表存在uid与focus_uid两种查询维度。
问题与选型
在这个量级下,传统的单机数据库容易出现以下几类问题:
1. 索引idx_focus_uid与idx_uid的写入均为随机写入,B+树频繁的SMO(叶子的分裂、合并等),会有各种各样的锁争抢,导致写入RT上升,CPU消耗变多等;
2. B+树层高变高,查询代价变大等;
3. 索引太大,Buffer Pool被打爆,产生大量的IO(本质上也是随机写入的问题)等;
4. 表的DDL耗时过长,时间不可控等。
无论使用哪种选型,核心是将大表进行拆分。在对该表进行分布式改造时,业务团队有几种选择:
1. 使用Redis、Hbase等NoSQL数据库,这类数据库可以解决扩展性问题,但是:
需要业务合理设计Key。如果将uid作为Key,那么无法按照focus_uid进行查询。只能由业务侧将数据写两份,按照uid写一份,按照focus_uid再写一份,并且由业务侧维护两份数据的一致性;
改变了业务之前使用关系型数据库的习惯,需要调整大量的代码。
2. Elasticsearch、MongoDB等文档型数据库:
1. 最重要的一点,PolarDB分布式版支持全局索引,在对数据做了水平拆分的基础上,还能支持业务的多维度查询的需求;
2. PolarDB分布式版兼容MySQL的语法和协议,应用从单机MySQL迁移过来无需修改代码,应用研发可以保持以前使用MySQL的思路和习惯。
使用PolarDB分布式版GSI解决多维度查询
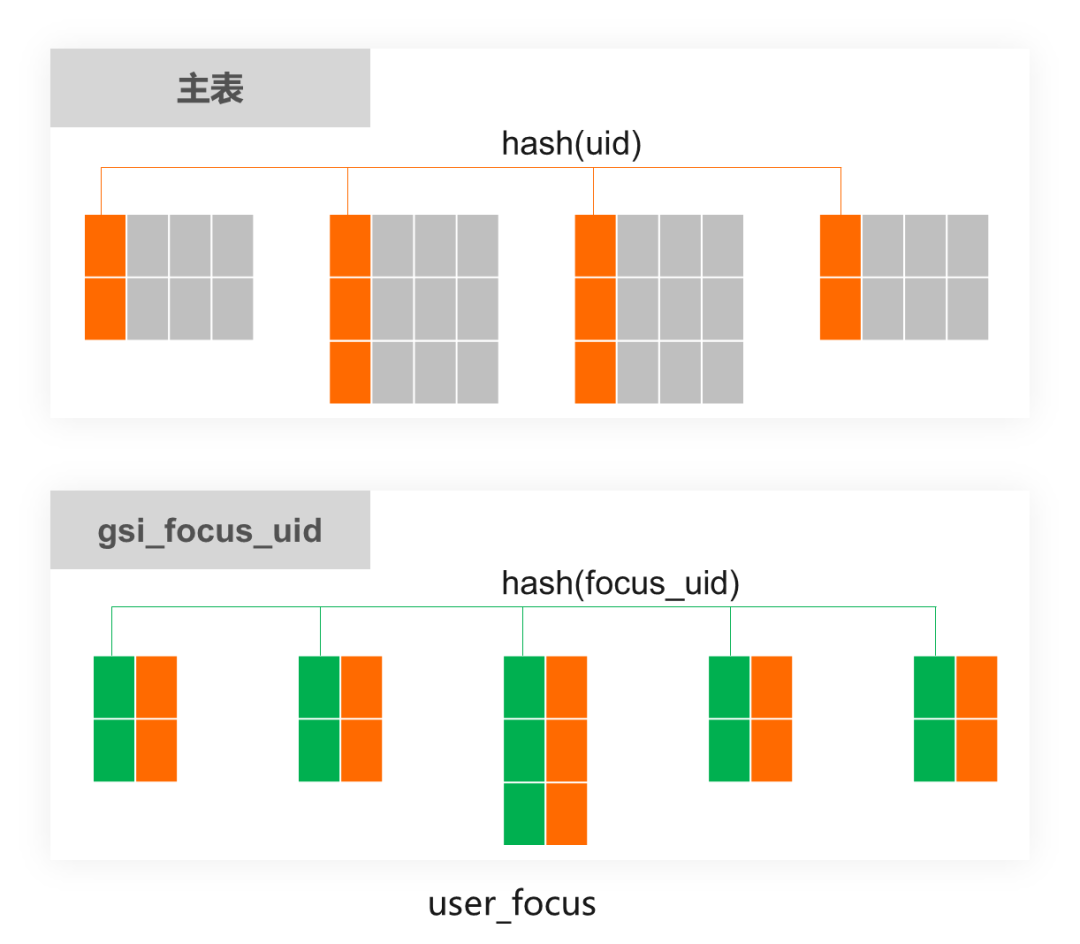
create table user_focus(id bigint primary key,uid bigint, -- 用户IDfocus_uid bigint, -- 关注的用户IDextra varchar(1024), -- 其他业务属性index idx_focus_uid(focus_uid),index idx_uid(uid)) partition by hash(uid);
create global index gsi_focus_uid on user_focus(focus_uid) partition by hash(focus_uid);
全局二级索引本质是一种数据冗余。例如,当执行一条SQL:
INSERT INTO user_focus (id,uid,focus_uid,extra) VALUES (1,99,1000,"xxx");
INSERT INTO user_focus (id,uid,focus_uid,extra) VALUES (1,99,1000,"xxx");INSERT INTO gsi_focus_uid (id,uid,focus_uid) VALUES (1,99,1000);
其中user_focus主表的分区键是uid,gsi_focus_uid的分区键是focus_uid。
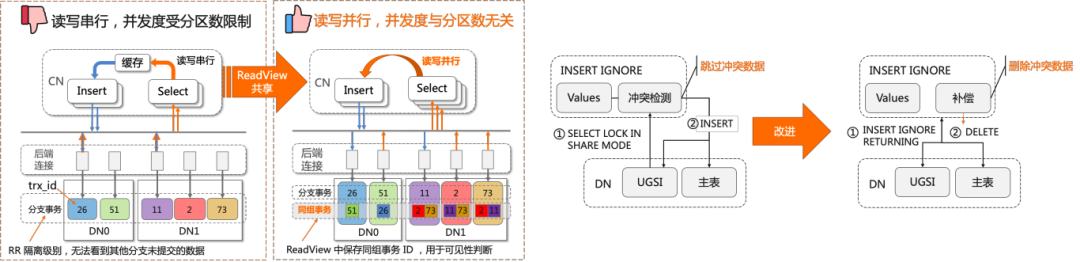
此外,PolarDB分布式版为GSI的性能也做了非常多的优化,例如:
● 多分片的并行写入;
● 唯一约束冲突检测下推;
● 分布式事务的Grouping优化、一阶段提交优化等。
性能效果
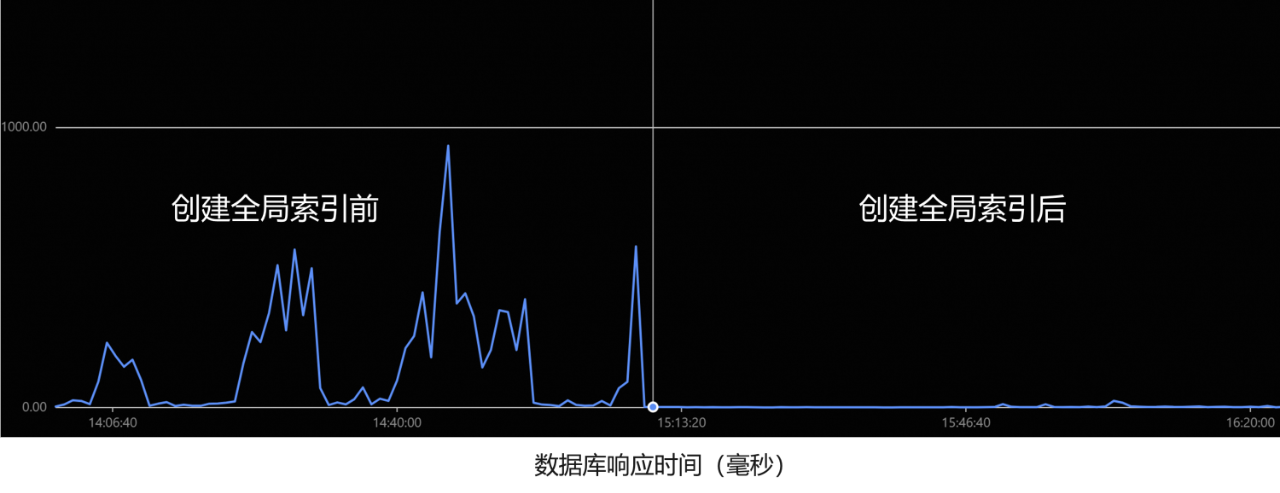
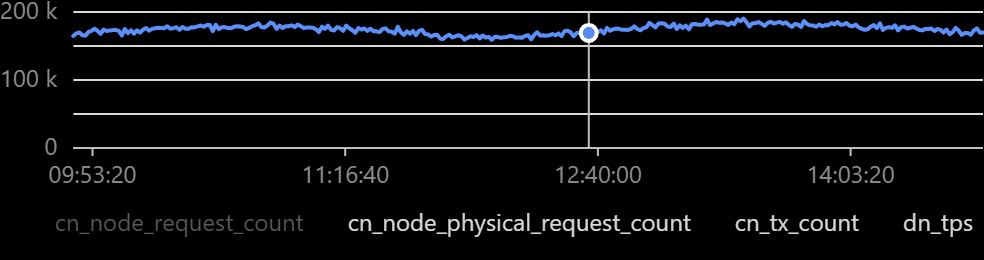
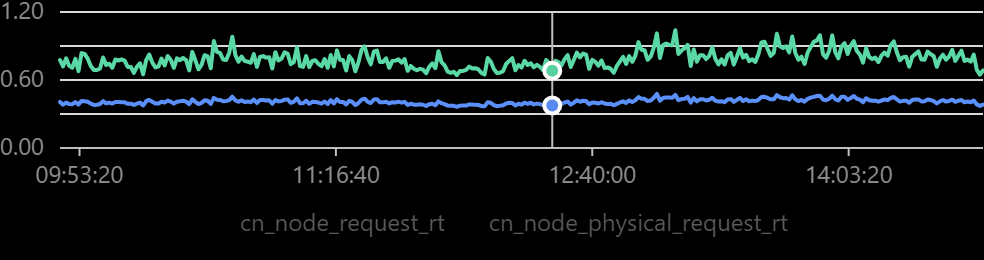
下图是业务上线后的效果,使用8个节点,在峰值达到20W QPS的情况下,依然保持着1ms的响应时间:
PolarDB分布式版GSI的最佳实践
1. 全局索引的数量不宜过多,通常一个表在2个以内。全局索引通常代表某种业务维度,例如,本例中典型的是关注和被关注,对于其他字段的查询加速,应使用本地索引。在某些场景下,我们也可以使用CO_HASH来实现多维度的查询,可参考《从淘宝订单号的秘密说起......》
2. 在一对多的场景下,使用聚簇的全局索引,可以有效减少回表的代价。关于聚簇的全局索引,请参考:《PolarDB-X全局二级索引》
3. 时间、日期等字段,不宜建全局索引,通常使用本地索引即可。
4. 使用索引诊断功能(执行INSPECT INDEX即可),可以找到一些冗余、未使用的全局索引,避免不必要的空间、资源消耗,可参考:《聊聊数据库中的烂索引》、《如何进行索引诊断》
🔗 https://help.aliyun.com/zh/polardb/polardb-for-xscale/index-diagnostics
总结
1. 它是强一致的并内聚的,不需要业务通过第三方组件来实现,不需要业务去维护索引数据的一致性;
2. 它的全局索引本身就是分区的,不需要担心全局索引本身的扩展性问题;
3. 它上线多年,稳定可靠,有超过80%的PolarDB分布式版用户都在使用全局索引;
—— 阿里云游戏行业架构师 范建文(瑛宸)




 点击 阅读原文 了解 PolarDB分布式版
点击 阅读原文 了解 PolarDB分布式版
