




背景
PolarDB-PG 支持[冷热数据分层存储](https://help.aliyun.com/zh/polardb/polardb-for-postgresql/overview-cold-data)功能,使用OSS等更低成本的存储介质,将冷热数据进行分层存储。将访问频率和更新频率低的数据转存到OSS中,可以有效降低存储成本。当开启冷数据分层存储后,单位存储的价格相较于ESSD PL1降低了约90%,此外还具有诸多优点:
- 易用性好
- SQL透明:数据库的SQL操作完全透明,无需进行任何改写,支持OSS表联合查询;存储到OSS上的数据也支持进行增、删、改、查操作。
- 索引透明:支持针对索引、物化视图等设置归档策略,操作透明。
- 灵活度高
- 支持多种分层存储策略,包括按照表维度进行归档(同时支持索引、物化视图)、按分区维度进行归档、按指定LOB字段进行归档。并且支持不同策略的组合,可以根据业务使用情况进行灵活配置。
- 性能良好
- 查询性能良好,采用了三层缓存设计:UDF内逻辑对象缓存+页面共享缓存+文件持久化缓存,有效减少了对OSS的访问次数,从而将OSS的读写延迟影响降到最低。
- 覆盖场景广泛
- 支持通用、时空、时序数据的归档,例如将时空轨迹、高精度地图等数据归档,大幅降低存储成本。
- 安全可靠
- OSS冷存数据同样支持备份恢复功能,在降低备份成本的同时还保障了高可用能力。
欢迎大家前来了解试用:https://help.aliyun.com/zh/polardb/polardb-for-postgresql/overview-cold-data
概述
PolarDB-PG 可以将数据存储在 对象存储服务 OSSopen in new window 上,但是 OSS 的超高延迟和不支持随机存取的访问模式会导致严重的性能问题,为此设计实现了一层可持久化的缓存,来加速冷数据表的操作。
本功能称为冷数据缓存(SmgrCache),总体设计类似于缓冲池,但是有一些区别:
- 存储的数据存放在持久化存储上,而非存放在内存中
- 映射信息同样需要持久化
- 支持 Replica 一致性读
本缓存可以带来以下好处:
- 降低 I/O 延迟,提高随机 I/O 的吞吐量
- 潜在地实现了 I/O 合并,减少了 I/O 放大
- 提高冷数据表的读写性能
- 加速冷数据的崩溃恢复速度
功能设计
本功能提供一个透明的缓存服务,为慢速设备(特指 OSS 存储、HDFS 等)加速 I/O。具体提供以下功能:
- 提供用户透明的缓存服务
- 支持可靠存储
- 支持在可靠存储上加速崩溃恢复
- 支持 Online Promote 等功能
- 支持 Replica 读写一致性
- 支持在 Standby 上启用
- 支持在线容量调整
原理简介
术语
- Primary:即 RW,主库
- Replica:即 RO,和主库使用同一份共享存储的只读库
- Standby:容灾热备,拥有独立于主库的存储
- buffer pool:缓冲池,数据库会将页面加载到缓冲池中加速数据访问
- pin:钉住,数据库中对页面增加引用计数的操作,确保页面不被换出
- nblocks:块数量,PostgreSQL 中会经常计算的值,用于评估扫描的表文件的大小
整体架构
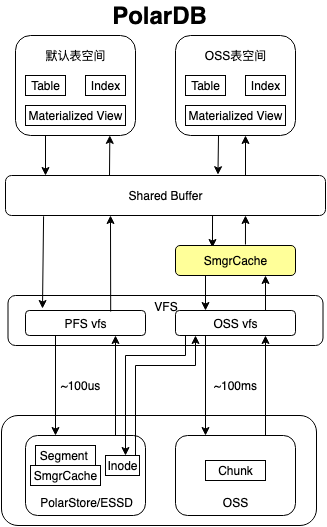
冷数据缓存整体架构如上,使用 OSS 构建一个虚拟的块存储服务,使用 VFS 对接到 PolarDB-PG,基于块存储构建智能的缓存服务,通过 OSS 表空间提供冷热分层的支持。
核心模块:
- OSS 表空间:将冷热分层存储的服务抽象为表空间,对应的底层存储为 OSS。可以将表创建在 OSS 表空间中,或者进行移入移出的操作。
- 冷数据缓存:使用块存储对表数据进行透明缓存,提高冷热分层存储的性能。
- OSS VFS:将 OSS 提供的对象文件存储接口抽象为块存储接口,对接到 VFS 接口层,提供文件切片、文件元信息的管理服务。
为了使缓存的能力最大化,我们做了大量的努力:
- 支持持久化能力
- 支持一写多读架构
- 最大化性能,支持 OSS 友好的读写和换入换出策略
- ...
支持持久化能力
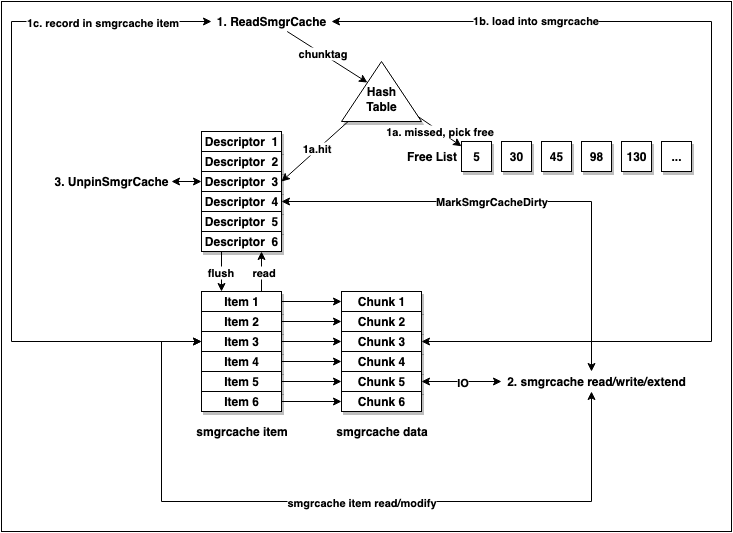
数据库中有个非常典型的冷热分层的基础设施就是 buffer pool,buffer pool 会自动将热数据载入到内存中,提供高速的读写服务。冷数据缓存的设计类似于 buffer pool,有存储在内存中的 cache descriptor、cache table,有存储在磁盘的 cache item 和 cache data。同时还有 free list、nblocks cache 等数据结构辅助功能正常运行。
一个直接的想法是使用 buffer pool 作为缓存,但是这样会存在几个问题:
- 从缓存的分层角度来看,内存和 OSS 间存在太大的 gap,容量、速度和价格之间无法平衡
- 从缓存的粒度上看,buffer pool 会按照 8k 随机读写底层数据,这对 OSS 极为不友好
- 从生命周期上看,buffer pool 重启就会丢失,下次载入代价非常大,还很有可能影响崩溃恢复
因此需要有一层中间缓存来抹平内存和 OSS 间的 gap。
冷数据缓存可以像 buffer pool 一样,不做持久化吗?如果冷数据缓存不支持持久化的话,会带来很多问题:
- 做检查点时,需要将 buffer pool 和缓存中的数据写入到 OSS 中,会导致检查点延迟很长,对 PolarDB-PG 的一写多读架构危害极大
- 如果发生了崩溃恢复,恢复时间会很长
- 重启后需要重新预热载入
因此我们需要做到缓存持久化的特性,并且兼容崩溃恢复、Online Promote 等功能。缓存本质上是在高速存储介质中维护了被缓存数据的副本,为了达到持久化的目的,需要同时持久化缓存数据、缓存数据映射、缓存数据状态,同时需要设计一套确保正确的读写协议,确保它们的一致性。
协议的工作基本原理是:
- 当缓存换入时,先换入数据,再写入映射
- 当缓存换出时,需要先换出数据,再清空映射
- 当缓存 extend 时,需要先写入数据,再写入映射
- 当缓存 truncate 时,需要修改映射
- 当缓存 inavalidate 时,需要清空映射
- ...
使用双写的方式确保了数据的安全性,这会带来些许的性能开销,但是相比于 100ms 级别的 OSS 访问时间,这些额外开销并不算什么。
为了达到兼容崩溃恢复的目的,设计时还需要完成自依赖,不能依赖上层的任何数据,否则会造成循环依赖问题。
适配一写多读架构
当 Replica 进行数据读取时,如果不通过缓存读取,可能会发生读不到数据或者读到旧版本数据的情况。如果从缓存中读取时,但当 Primary 进行换出时,可能读取到错误的块。同时 Replica 无法读写缓存数据,无法完成缓存的换入换出。因此,需要设计一套机制确保 Replica 能够正确读取到数据。
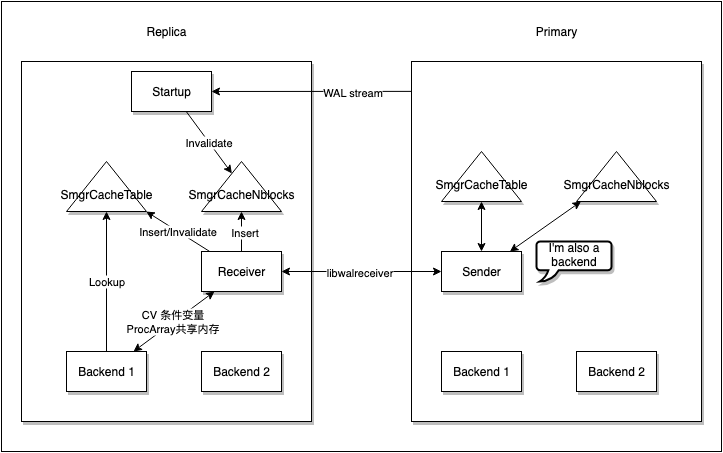
在数据库中,我们通过一套 pin 的机制来确保需要读取的缓存不被换出。在一写多读架构的适配中,我们通过 remote pin 机制进行缓存的换入和读取,使用一组代理进程进行请求的处理。同时在 Replica 增加对上述请求的缓存(pin/unpin/nblocks),确保最优的性能表现:
- pin/unpin 优化:当 Replica 会话进程进行 unpin 操作时,不立即到 Primary 进行 unpin,而是延迟进行 unpin 操作,防止反复的网络交互
- nblocks 的缓存存放在了 Replica 本地的 hashtable 中,这会带来缓存的维护问题,这里适配了回放逻辑,当涉及到表大小的改动的 WAL 日志回放时,就会把相关的缓存 Invalidate 掉
同时需要处理各种异常场景,例如连接断开、主库不可用、主备库参数不一致等情况。为此设计了一套缓存版本机制和租约机制确保异常能正确处理,同时需要设计合理的状态机来确保这些状态相互之间顺序转换。Replica 缓存共有六种状态:本地待初始化、本地缓存绕过、本地缓存读取、远程缓存绕过、远程缓存读取、远程缓存不可用。
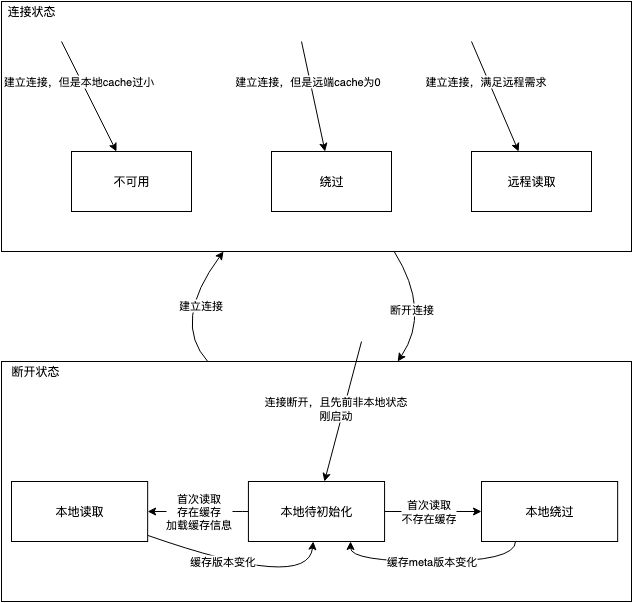
上图是状态机的工作原理。当缓存发生换入换出时,缓存的版本会发生变化。当主库重启、重新启用缓存时,缓存的 meta 版本会发生变化。
这里我们假设一个连接断开但是主库可用的场景,来看上述机制是如何发挥作用的:
- 开始 Replica 在正常运行中(远程读取),通过 remote pin 机制读取缓存中的数据
- 连接断开,Replica 开始进入本地待初始化状态,新的缓存读取操作 hang 住,在 1s 后开始清理本地的缓存映射,已有的读取也会在 1s 内超时,进入进入本地待初始化状态完成,RW 在 2s 后释放相关的 pin
- Replica 收到新的读取请求,第一次读取会直接从本地加载缓存进入映射表中,并维护 nblocks 缓存。后续的读取如果命中缓存,则会从缓存中读取,如果未命中,则会从 OSS 中读取
上述机制确保了在异常场景下 Replica 依旧能够读取 OSS 数据,但是性能会受到严重影响,因为此时 Replica 无法使用缓存换入 OSS 数据。与 Primary 恢复连接,或者 Replica promote 后,就能恢复正常的读写性能。
最大化性能
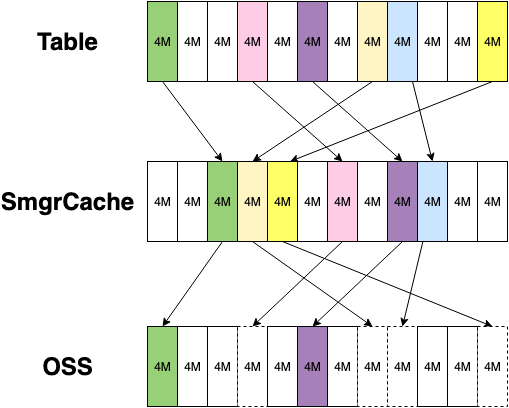
为了提供尽可能接近原生块存储的性能,我们也做了非常多的努力。
冷数据缓存如果只是 OSS 数据的缓存的话,就会导致一个问题:凡是缓存上有的数据 OSS 上都需要有。在一些场景下,会导致严重的性能问题,例如导入时会触发表扩展,需要同步扩展 OSS 数据,会导致极大的延迟!因此需要转变下设计思路,SmgrCache 不是 OSS 数据的副本缓存,而是表的缓存,或者也可以称为 Write Back 的缓存写入策略。该策略允许 OSS 中存在空洞,这样来最大化地确保性能。这个设计也导致了很多实现上的复杂度,SmgrCache 需要在运行时缓存一部分表的元信息,其中最主要的就是表的逻辑大小。同时,逻辑大小的缓存也加速了表大小的查找,不需要调用缓慢的 lseek。
缓存的每次换入都需要进行映射的写入,但是很多情况下是非必要的,例如换入的缓存只发生过读取,那么这块缓存丢失也没有关系,因此可以将缓存的映射持久化推迟到缓存发生写入时进行。
缓存的刷脏模式和 buffer 刷脏会很不一样,主要体现在缓存的粒度大,对应的底层存储极慢,换入换出的成本高。因此需要有新的缓存的管理模式来适配 OSS 存储。具体而言是这些优化:
- 使用 TTL 的方式进行缓存的后台写回,防止频繁的写回
- 需要确保始终有空闲的缓存,这样当进程需要换入时,就能及时地获取到而不用触发同步换出
- 换入时需要更多的轮次获取到需要的缓存,因为缓存的数目更少,且换出成本高,不容易找到空闲的缓存块
- 并行的后台写回进程
