




本文分享两种经典协同过滤算法的Python实现:
基于物品的协同过滤算法:ItemCF. 基于用户的协同过滤算法:UserCF.
代码来自Github开源项目:fun-rec.
在开始之前,先导入用到的库:
import pandas as pd
import numpy as np
import warnings
import random, math, os
from tqdm import tqdm
from sklearn.model_selection import train_test_split
warnings.filterwarnings('ignore')
数据准备
本次使用的数据是一份电影评分数据:
::
将数据集划分成4列,从左到右分别代表:用户id,电影id,评分值,时间戳。
首先将原始数据转换成pandas的数据框表示: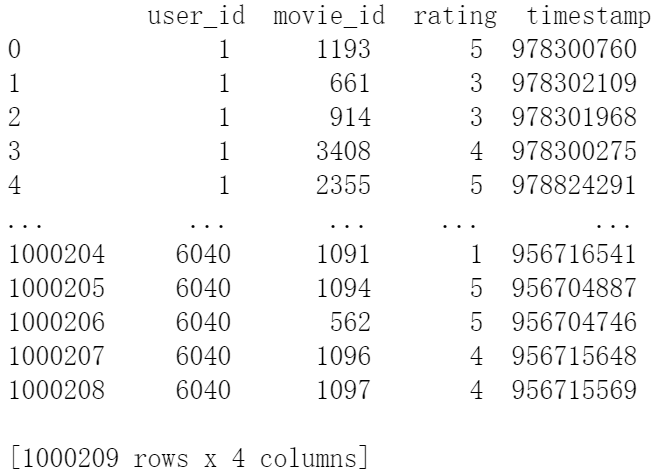
然后提取每个用户评价过的电影,格式如下:
稍后的ItemCF和UserCF都将使用这个表。
数据处理完整代码如下:
def get_data(root_path):
# 读取数据
rnames = ['user_id','movie_id','rating','timestamp']
ratings = pd.read_csv(os.path.join(root_path, 'rating.dat'), sep='::', engine='python', names=rnames)
print('ratings:\n',ratings)
# 分割训练和验证集
trn_data, val_data, _, _ = train_test_split(ratings, ratings, test_size=0.2)
trn_data = trn_data.groupby('user_id')['movie_id'].apply(list).reset_index()
val_data = val_data.groupby('user_id')['movie_id'].apply(list).reset_index()
print('trn_data:\n',trn_data)
trn_user_items = {}
val_user_items = {}
# 将数组构造成字典的形式{user_id: [item_id1, item_id2,...,item_idn]}
for user, movies in zip(*(list(trn_data['user_id']), list(trn_data['movie_id']))):
trn_user_items[user] = set(movies)
for user, movies in zip(*(list(val_data['user_id']), list(val_data['movie_id']))):
val_user_items[user] = set(movies)
return trn_user_items, val_user_items
###########读取数据###########
root_path = './data'
trn_user_items, val_user_items = get_data(root_path)
定义评价指标
定义一些指标来评估推荐算法的好坏,直接上代码:
# 评价指标
# 推荐系统推荐正确的商品数量占用户实际点击的商品数量
def Recall(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rel_set)
return round(hit_items / all_items * 100, 2)
# 推荐系统推荐正确的商品数量占给用户实际推荐的商品数
def Precision(Rec_dict, Val_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Val_dict: 用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
hit_items = 0
all_items = 0
for uid, items in Val_dict.items():
rel_set = items
rec_set = Rec_dict[uid]
for item in rec_set:
if item in rel_set:
hit_items += 1
all_items += len(rec_set)
return round(hit_items / all_items * 100, 2)
# 所有被推荐的用户中,推荐的商品数量占这些用户实际被点击的商品数量
def Coverage(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
rec_items = set()
all_items = set()
for uid in Rec_dict:
for item in Trn_dict[uid]:
all_items.add(item)
for item in Rec_dict[uid]:
rec_items.add(item)
return round(len(rec_items) / len(all_items) * 100, 2)
# 使用平均流行度度量新颖度,如果平均流行度很高(即推荐的商品比较热门),说明推荐的新颖度比较低
def Popularity(Rec_dict, Trn_dict):
'''
Rec_dict: 推荐算法返回的推荐列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
Trn_dict: 训练集用户实际点击的商品列表, 形式:{uid: {item1, item2,...}, uid: {item1, item2,...}, ...}
'''
pop_items = {}
for uid in Trn_dict:
for item in Trn_dict[uid]:
if item not in pop_items:
pop_items[item] = 0
pop_items[item] += 1
pop, num = 0, 0
for uid in Rec_dict:
for item in Rec_dict[uid]:
pop += math.log(pop_items[item] + 1) # 物品流行度分布满足长尾分布,取对数可以使得平均值更稳定
num += 1
return round(pop / num, 3)
# 将几个评价指标指标函数一起调用
def rec_eval(val_rec_items, val_user_items, trn_user_items):
print('recall:',Recall(val_rec_items, val_user_items))
print('precision',Precision(val_rec_items, val_user_items))
print('coverage',Coverage(val_rec_items, trn_user_items))
print('Popularity',Popularity(val_rec_items, trn_user_items))
ItemCF
基于物品的协同过滤算法,根据物品之间的相似度进行推荐。
通俗来讲就是看看与当前用户交互(这里的交互可以是评分,购买等行为)过的物品相似的物品(且这些物品不曾与当前用户交互过)都有哪些,然后拿过来给用户做推荐。
具体步骤如下:
1.建立user->item的倒排表trn_user_items,它存储了每一个用户交互过的物品的集合,格式如下: trn_user_items={user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...}
2.计算物品之间的相似度:
遍历每一个user交互过的items列表,统计两个不同的item共同被user(不止一个,而是trn_user_items中的所有user)交互的总次数,以及每个物品总共被交互(评分)的次数,据此计算两个物品之间的余弦相似度;
将两两物品之间的相似度统计结果存入sim,格式如下: sim = {item_id1: {item_id2: num1, item_id3: num3,...}, item_id3: {item_id4: num2,...}, ...}.
比如{ item_id3: {item_id4: num2} 意味着id=3的物品与id=4的物品之间的相似度得分是num2.
3.根据2.中得到的物品之间的相似度,获取与当前测试用户交互过的物品最相似的前K个物品,然后对这K个用户交互的物品中除当前测试用户训练集中交互过的物品以外的物品计算最终的相似度分数,存入items_rank: items_rank={user1:{item1:score1,item2:score2,...},user2:{item6:score6,item9:score9,...}}
4.只取items_rank中得分前N的物品,将其作为最终的推荐结果。
注意,这里的余弦相似度的计算公式是离散的,物品和物品之间的余弦相似度计算公式如下: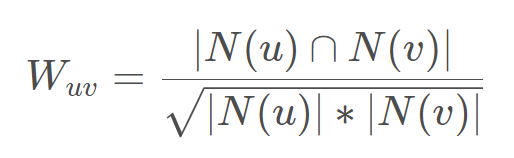
和分别表示物品和物品被交互(评分)的总次数,分子表示物品和物品同时被用户交互(评分)的总次数(用户一般不止一个)。
ItemCF的完整代码如下:
def Item_CF(trn_user_items, val_user_items, K, N):
'''
trn_user_items: 表示训练数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
val_user_items: 表示验证数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
K: K表示的是相似商品的数量,为每个用户交互的每个商品都选择其最相似的K个商品
N: N表示的是给用户推荐的商品数量,给每个用户推荐相似度最大的N个商品
'''
# 建立user->item的倒排表
# 倒排表的格式为: {user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...} 也就是每个用户交互过的所有商品集合
# 由于输入的训练数据trn_user_items,本身就是这中格式的,所以这里不需要进行额外的计算
# 计算商品协同过滤矩阵
# 即利用user-items倒排表统计商品与商品之间被共同的用户交互的次数
# 商品协同过滤矩阵的表示形式为:sim = {item_id1: {item_id2: num1, item_id3: num3,...}, item_id3: {item_id4: num2,...}, ...}
# 商品协同过滤矩阵是一个双层的字典,用来表示商品之间共同交互的用户数量
# 在计算商品协同过滤矩阵的同时还需要记录每个商品被多少不同用户交互的次数,其表示形式为: num = {item_id1:num1, item_id2:num2, ...}
sim = {}#两个物品同时被某些用户喜欢的总次数(不止一个用户)
num = {}#每个物品的总共的 被喜欢(交互)数
print('构建相似性矩阵...')
#遍历每一个user交互过的items列表,统计两个不同的item共同被user(不止一个,而是trn_user_items中的所有user)交互的总次数
for uid, items in tqdm(trn_user_items.items()):
#对于当前items列表中的每一个item
for i in items:
#统计item i 被用户交互的总次数
if i not in num:
num[i] = 0
num[i] += 1
#统计 item i 和 item j 被共同交互的总次数
if i not in sim:
sim[i] = {}
for j in items:
if j not in sim[i]:
sim[i][j] = 0
if i != j:
sim[i][j] += 1
# 计算物品的相似度矩阵
# 商品协同过滤矩阵其实相当于是余弦相似度的分子部分,还需要除以分母,即两个商品被交互的用户数量的乘积
# 两个商品被交互的用户数量就是上面统计的num字典
print('计算协同过滤矩阵...')
for i, items in tqdm(sim.items()):
for j, score in items.items():
if i != j:
sim[i][j] = score / math.sqrt(num[i] * num[j])
#查看一下sim
for k ,v in sim.items():
print(k,v)
break
# 对验证数据中的每个用户进行TopN推荐
# 在对用户进行推荐之前需要先通过商品相似度矩阵得到 与 当前测试用户交互过的商品最相似的前K个商品,
# 然后对这K个用户交互的商品中除当前测试用户训练集中交互过的商品以外的商品计算最终的相似度分数
# 最终推荐的候选商品的相似度分数是由多个相似商品对该商品分数的一个累加和
items_rank = {}
print('给用户进行推荐...')
for uid, _ in tqdm(val_user_items.items()):
items_rank[uid] = {} # 存储用户候选的推荐商品
for hist_item in trn_user_items[uid]: # 遍历该用户历史喜欢的商品,用来下面寻找其相似的商品
# 回顾:sim = {item_id1: {item_id2: num1, item_id3: num3,...}, item_id3: {item_id4: num2,...}, ...}
# 回顾:trn_user_items = {user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...}
#print(sim[hist_item])# {item_id2: num1, item_id3: num3,...}
for item, score in sorted(sim[hist_item].items(), key=lambda x: x[1], reverse=True)[:K]:
if item not in trn_user_items[uid]: # 进行推荐的商品一定不能在历史喜欢商品中出现
#计算当前uid对当前item的打分
if item not in items_rank[uid]:
items_rank[uid][item] = 0
items_rank[uid][item] += score
print('为每个用户筛选出相似度分数最高的N个商品...')
#print(items_rank)#{user1:{item1:score1,item2:score2,...},user2:{item6:score6,item9:score9,...}}
items_rank = {k: sorted(v.items(), key=lambda x: x[1], reverse=True)[:N] for k, v in items_rank.items()}
items_rank = {k: set([x[0] for x in v]) for k, v in items_rank.items()}
return items_rank
#测试ItemCF
rec_items = Item_CF(trn_user_items, val_user_items, 80, 10)
rec_eval(rec_items, val_user_items, trn_user_items)
UserCF
基于用户的协同过滤算法,根据用户之间的相似度进行推荐。
通俗来讲就是看看与当前用户相似的其他用户交互(这里的交互可以是评分,购买等行为)过的物品(且这些物品不曾与当前用户交互过)都有哪些,然后拿过来给用户做推荐。
具体步骤如下:
1.建立item->user的倒排表item_users,它存储了每一个与某物品交互过的用户的集合,格式如下: item_users={item_id1: {user_id1, user_id2, ... , user_idn}, item_id2: ...}
2.计算用户之间的相似度:
遍历每一个item交互过的users列表,统计两个不同的user与相同item(不止一个,而是item_users中的所有item)交互的总次数,以及每个用户的总交互(评分)次数,据此计算两个用户之间的余弦相似度;
将两两用户之间的相似度统计结果存入sim,格式如下: sim = {user_id1: {user_id2: num1,user_id5: num5,...}, user_id3:{user_id4: num2,...}, ...}
比如 user_id3:{user_id4: num2,}意味着id=3的用户与id=4的用户之间的相似度得分是num2.
3.根据2.中得到的用户之间的相似度,获取与当前测试用户最相似的前K个用户,然后对这K个用户交互的物品中除当前测试用户训练集中交互过的物品以外的物品计算最终的相似度分数,存入items_rank: items_rank={user1:{item1:score1,item2:score2,...},user2:{item6:score6,item9:score9,...}}
4.只取items_rank中得分前N的物品,将其作为最终的推荐结果。
UserCF的完整代码如下:
def User_CF_Rec(trn_user_items, val_user_items, K, N):
'''
trn_user_items: 表示训练数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
val_user_items: 表示验证数据,格式为:{user_id1: [item_id1, item_id2,...,item_idn], user_id2...}
K: K表示的是相似用户的数量,每个用户都选择与其最相似的K个用户
N: N表示的是给用户推荐的商品数量,给每个用户推荐相似度最大的N个商品
'''
# 建立item->users倒排表
# 倒排表的格式为: {item_id1: {user_id1, user_id2, ... , user_idn}, item_id2: ...} 也就是每个item对应有那些用户有过点击
# 建立倒排表的目的就是为了更好的统计用户之间共同交互的商品数量
print('建立倒排表...')
item_users = {}
for uid, items in tqdm(trn_user_items.items()): # 遍历每一个用户的数据,其中包含了该用户所有交互的item
for item in items: # 遍历该用户的所有item, 给这些item对应的用户列表添加对应的uid
if item not in item_users:
item_users[item] = set()
item_users[item].add(uid)
# 计算用户协同过滤矩阵
# 即利用item-users倒排表统计用户之间交互的商品数量,用户协同过滤矩阵的表示形式为:sim = {user_id1: {user_id2: num1,user_id5: num5,...}, user_id3:{user_id4: num2,...}, ...}
# 协同过滤矩阵是一个双层的字典,用来表示用户之间共同交互的商品数量
# 在计算用户协同过滤矩阵的同时还需要记录每个用户所交互的商品数量,其表示形式为: num = {user_id1:num1, user_id2:num2, ...}
sim = {}#两个用户同时喜欢(交互)某些物品的总次数(不止一个物品)
num = {}#每个用户的总共 喜欢(交互)数
print('构建协同过滤矩阵...')
#回顾:item_users = {item_id1: {user_id1, user_id2, ... , user_idn}, item_id2: ...}
for item, users in tqdm(item_users.items()): # 遍历所有的item去统计,用户两两之间共同交互的item数量
for u in users:
if u not in num: # 如果用户u不在字典num中,提前给其在字典中初始化为0,否则后面的运算会报key error
num[u] = 0
num[u] += 1 # 统计每一个用户,交互的总的item的数量
if u not in sim: # 如果用户u不在字典sim中,提前给其在字典中初始化为一个新的字典,否则后面的运算会报key error
sim[u] = {}
for v in users:
if u != v: # 只有当u不等于v的时候才计算用户之间的相似度
if v not in sim[u]:
sim[u][v] = 0
sim[u][v] += 1
# 计算用户相似度矩阵
# 用户协同过滤矩阵其实相当于是余弦相似度的分子部分,还需要除以分母,即两个用户分别交互的item数量的乘积
# 两个用户分别交互的item数量的乘积就是上面统计的num字典
print('计算相似度...')
# 回顾:sim = {user_id1: {user_id2: num1,user_id5: num5,...}, user_id3:{user_id4: num2,...}, ...}
for u, users in tqdm(sim.items()):
for v, score in users.items():
sim[u][v] = score / math.sqrt(num[u] * num[v]) # 余弦相似度分母部分
# 对验证数据中的每个用户进行TopN推荐
# 在对用户进行推荐之前需要先通过相似度矩阵得到与当前用户最相似的前K个用户,
# 然后对这K个用户交互的商品中除当前测试用户训练集中交互过的商品以外的商品计算最终的相似度分数
# 最终推荐的候选商品的相似度分数是由多个用户对该商品分数的一个累加和
print('给测试用户进行推荐...')
items_rank = {}
for u, _ in tqdm(val_user_items.items()): # 遍历测试集用户,给测试集中的每个用户进行推荐
items_rank[u] = {} # 初始化用户u的候选item的字典
# 回顾:sim = {user_id1: {user_id2: num1,user_id5: num5,...}, user_id3:{user_id4: num2,...}, ...}
# 回顾:trn_user_items = {user_id1: [item_id1, item_id2,...,item_idn], user_id2: ...}
# print(sim[u]) # {user_id2: num1,user_id5: num5,...}
for v, score in sorted(sim[u].items(), key=lambda x: x[1], reverse=True)[:K]: # 选择与用户u最相似的K个用户
for item in trn_user_items[v]: # 遍历相似用户之前交互过的商品
if item not in trn_user_items[u]: # 如果相似用户交互过的商品,测试用户在训练集中出现过,就不用进行推荐,直接跳过
if item not in items_rank[u]:
items_rank[u][item] = 0 # 初始化用户u对item的相似度分数为0
items_rank[u][item] += score # 累加所有相似用户对同一个item的分数
print('为每个用户筛选出相似度分数最高的N个商品...')
items_rank = {k: sorted(v.items(), key=lambda x: x[1], reverse=True)[:N] for k, v in items_rank.items()}
items_rank = {k: set([x[0] for x in v]) for k, v in items_rank.items()} # 将输出整合成合适的格式输出
return items_rank
#测试UserCF
rec_items = User_CF_Rec(trn_user_items, val_user_items, 80, 10)
rec_eval(rec_items, val_user_items, trn_user_items)
参考代码:
https://github.com/datawhalechina/fun-rec/tree/master/codes
南极Python交流群已成立,长按下方二维码添加我的微信,备注加群即可,欢迎进群学习交流(划水 )
)

