




Xception
Xception将Inception中的Inception模块替换为深度可分离卷积。在几乎不增加参数量的前提下,Xception在一些图像分类任务中的表现超越了Inception V3。
我们之前介绍的深度可分离卷积是先做逐通道卷积,再做逐点卷积,而在Xception的论文描述中,这两步的顺序正好相反(见下图)。不过没关系,论文中也指出,这里的顺序并不影响效果(理由:in particular because these operations are meant to be used in a stacked setting.)。
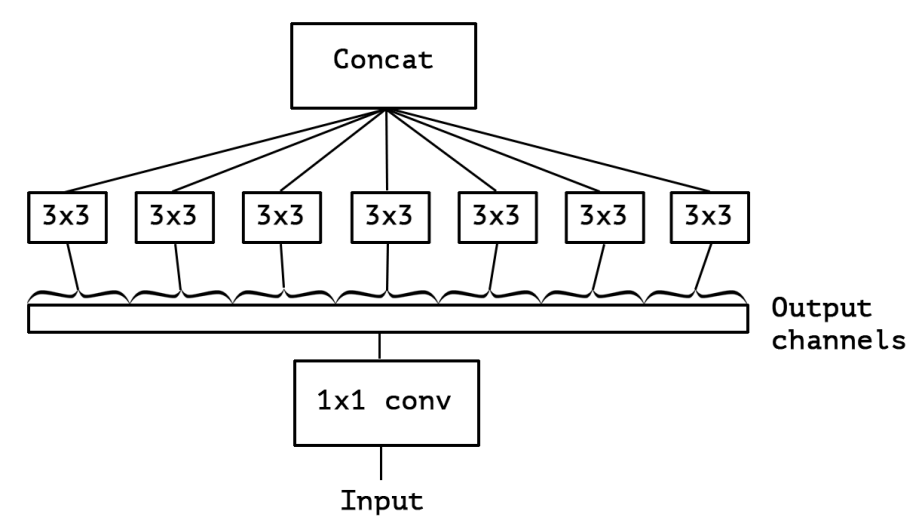
同时,经过实验发现,深度可分离卷积中的卷积层之间不加非线性激活函数的效果相较于加入非线性激活函数来说会更好一些。
Xception的网络结构如下: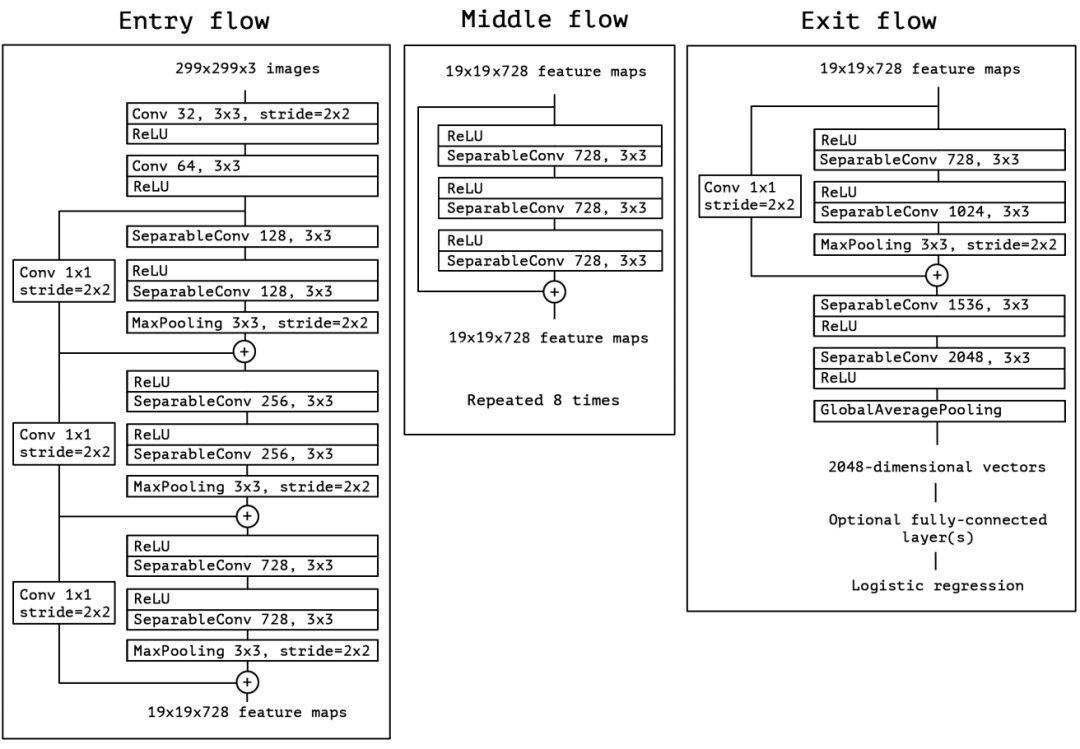 网络总共可以分为3个部分:Entry flow,Middle flow,以及Exit flow,并且借鉴了ResNet的思想,引入了跳连(skip connection)。注意每个卷积(包括普通卷积与深度可分离卷积)之后都做了批归一化操作,只是没在网络结构图中画出。
网络总共可以分为3个部分:Entry flow,Middle flow,以及Exit flow,并且借鉴了ResNet的思想,引入了跳连(skip connection)。注意每个卷积(包括普通卷积与深度可分离卷积)之后都做了批归一化操作,只是没在网络结构图中画出。
PyTorch 实现Xception
现在,根据上面的网络结构图,来实现Xception。
观察网络结构图,发现SeparableConv,也就是深度可分离卷积被重复使用,因此先来实现它:
#深度可分离卷积
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,padding,dilation=1,bias=False):
super(SeparableConv2d,self).__init__()
#逐通道卷积:groups=in_channels=out_channels
self.conv1 = nn.Conv2d(in_channels,in_channels,kernel_size,stride,padding,dilation,groups=in_channels,bias=bias)
#逐点卷积:普通1x1卷积
self.pointwise = nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=1,padding=0,dilation=1,groups=1,bias=bias)
def forward(self,x):
x = self.conv1(x)
x = self.pointwise(x)
return x
上面的代码很简单,就是之前提到的逐通道卷积和逐点卷积的堆叠。
现在来实现Xception:
class Xception(nn.Module):
def __init__(self, num_classes=1000):
super(Xception, self).__init__()
self.num_classes = num_classes#总分类数
################################## 定义 Entry flow ###############################################################
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3,stride=2,padding=0,bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64, kernel_size=3,stride=1,padding=0,bias=False)
self.bn2 = nn.BatchNorm2d(64)
#do relu here
# Block中的参数顺序:in_filters,out_filters,reps,stride,start_with_relu,grow_first
self.block1=Block(64,128,2,2,start_with_relu=False,grow_first=True)
self.block2=Block(128,256,2,2,start_with_relu=True,grow_first=True)
self.block3=Block(256,728,2,2,start_with_relu=True,grow_first=True)
################################### 定义 Middle flow ############################################################
self.block4=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block5=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block6=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block7=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block8=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block9=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block10=Block(728,728,3,1,start_with_relu=True,grow_first=True)
self.block11=Block(728,728,3,1,start_with_relu=True,grow_first=True)
#################################### 定义 Exit flow ###############################################################
self.block12=Block(728,1024,2,2,start_with_relu=True,grow_first=False)
self.conv3 = SeparableConv2d(1024,1536,3,1,1)
self.bn3 = nn.BatchNorm2d(1536)
#do relu here
self.conv4 = SeparableConv2d(1536,2048,3,1,1)
self.bn4 = nn.BatchNorm2d(2048)
self.fc = nn.Linear(2048, num_classes)
###################################################################################################################
#------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#-----------------------------
def forward(self, x):
################################## 定义 Entry flow ###############################################################
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
################################### 定义 Middle flow ############################################################
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
#################################### 定义 Exit flow ###############################################################
x = self.block12(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.relu(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
上述代码分别实现了Entry flow,Middle flow,以及Exit flow。
代码中的Block模块,可以看作是一个深度可分离卷积堆叠模块,它包括(ReLu,SeparableConv,ReLU,SeparableConv,MaxPooling)。当然,有些层并不完全包含其中,再看这张网络结构图就能明白: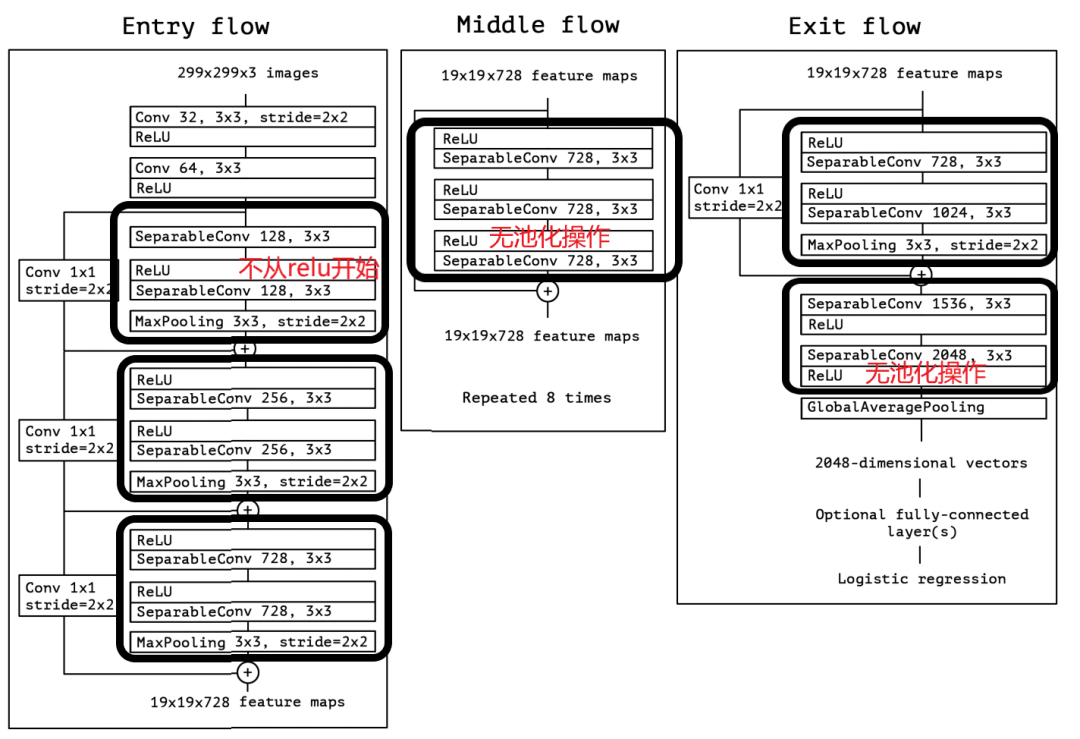
具体细节在Block的代码实现中进行了控制。
对于Entry flow,首先使用了两个3x3卷积(conv1,conv2)降低特征图尺寸,同时增加了特征图个数;接着是3个含跳连的深度可分离卷积堆叠模块。
对于Middle flow,包含了8个一模一样的含跳连的深度可分离卷积堆叠模块。
对于Exit flow,首先是一个含跳连的深度可分离卷积堆叠模块,接着是一些深度可分离卷积层以及全局平均池化层,最后用全连接层输出分类结果。
实现了网络总体结构之后,现在来完成其中Block(深度可分离卷积堆叠模块)代码的编写。
class Block(nn.Module):
def __init__(self,in_filters,out_filters,reps,strides=1,start_with_relu=True,grow_first=True):
#:parm reps:块重复次数
super(Block, self).__init__()
#Middle flow无需做这一步,而其余块需要,以做跳连
# 1)Middle flow输入输出特征图个数始终一致,且stride恒为1
# 2)其余块需要stride=2,这样可以将特征图尺寸减半,获得与最大池化减半特征图尺寸同样的效果
if out_filters != in_filters or strides!=1:
self.skip = nn.Conv2d(in_filters,out_filters,kernel_size=1,stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters)
else:
self.skip=None
self.relu = nn.ReLU(inplace=True)
rep=[]
filters=in_filters
if grow_first:
rep.append(self.relu)
#这里的卷积不改变特征图尺寸
rep.append(SeparableConv2d(in_filters,out_filters,kernel_size=3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
filters = out_filters
for i in range(reps-1):
rep.append(self.relu)
#这里的卷积不改变特征图尺寸
rep.append(SeparableConv2d(filters,filters,kernel_size=3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(filters))
if not grow_first:
rep.append(self.relu)
#这里的卷积不改变特征图尺寸
rep.append(SeparableConv2d(in_filters,out_filters,kernel_size=3,stride=1,padding=1,bias=False))
rep.append(nn.BatchNorm2d(out_filters))
if not start_with_relu:
rep = rep[1:]
else:
rep[0] = nn.ReLU(inplace=False)
#Middle flow 的stride恒为1,因此无需做池化,而其余块需要
#其余块的stride=2,因此这里的最大池化可以将特征图尺寸减半
if strides != 1:
rep.append(nn.MaxPool2d(kernel_size=3,stride=strides,padding=1))
self.rep = nn.Sequential(*rep)
def forward(self,inp):
x = self.rep(inp)
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else:
skip = inp
x+=skip
return x
Block中的参数:in_filters
:输入特征图个数
out_filters
:输出特征图个数
reps
:重复'ReLU-SeparableConv-BN'的次数(注意网络结构图中没有画出BN)
stride
:卷积/池化步长
start_with_relu
:是否Block的第一层是ReLU
grow_first
:是否先改变(增大)通道数再堆叠重复的'ReLU-SeparableConv-BN'
Block中的卷积层不会改变特征图尺寸,特征图尺寸的改变是通过最大池化操作完成的。
其中的start_with_relu
参数针对的是Entry flow,因为其中有一个实例化的Block的结构为(SeparableConv,ReLU,SeparableConv,MaxPooling),不包含ReLu,因此这个Block对应的start_with_relu=False
,而其余实例化的Block都以ReLU开始,因此它们的start_with_relu
都是True。
现在,考虑何时需要对跳连操作前的输入施加变换。
和ResNet的思想一样,如果经过映射后的特征图尺寸和通道数没有改变,就可以直接做跳连,否则需要先对输入做变换,之后再做跳连。
具体地,Middle flow中的Block通道数不变(in_channels=out_channels
),且特征图尺寸也不变(stride=1
),因此无需对输入做变换,可直接做跳连。而其余的Block中不满足这两个条件中的任意一个,因此在做跳连之前需要对输入做些变换。
那做什么变换呢?
前面说过,Block中的卷积层不会改变特征图尺寸,特征图尺寸的改变是通过最大池化操作完成的,并且做的是尺寸减半操作。所以,要变的只有两个地方:
通道数:通过改变输出特征图个数实现
特征图尺寸:通过令卷积层的stride=2来实现与最大池化操作同样的效果,即:特征图尺寸减半。
以上便是Xception的代码及实现过程分析。
现在来测试一下:
最后,给出Xception的网络结构:
Xception(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(block1): Block(
(skip): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(skipbn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): SeparableConv2d(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(pointwise): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): SeparableConv2d(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(pointwise): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(block2): Block(
(skip): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(skipbn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(pointwise): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(pointwise): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(block3): Block(
(skip): Conv2d(256, 728, kernel_size=(1, 1), stride=(2, 2), bias=False)
(skipbn): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(pointwise): Conv2d(256, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(block4): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block5): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block6): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block7): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block8): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block9): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block10): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block11): Block(
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace=True)
(7): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(8): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(block12): Block(
(skip): Conv2d(728, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(skipbn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(rep): Sequential(
(0): ReLU()
(1): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(2): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU(inplace=True)
(4): SeparableConv2d(
(conv1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728, bias=False)
(pointwise): Conv2d(728, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(5): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(conv3): SeparableConv2d(
(conv1): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024, bias=False)
(pointwise): Conv2d(1024, 1536, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(bn3): BatchNorm2d(1536, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv4): SeparableConv2d(
(conv1): Conv2d(1536, 1536, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1536, bias=False)
(pointwise): Conv2d(1536, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(bn4): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
南极Python交流群已成立,长按下方二维码添加我的微信,备注加群即可,欢迎进群学习交流(划水 )
)

原创不易,感谢点赞,分享和在看的你!
