




ResNet
一般来说,网络越深越复杂,同时网络提取特征的能力也就越强。但是,实验发现,当继续增加网络层数,使得网络越来越深时,网络能力不增反减。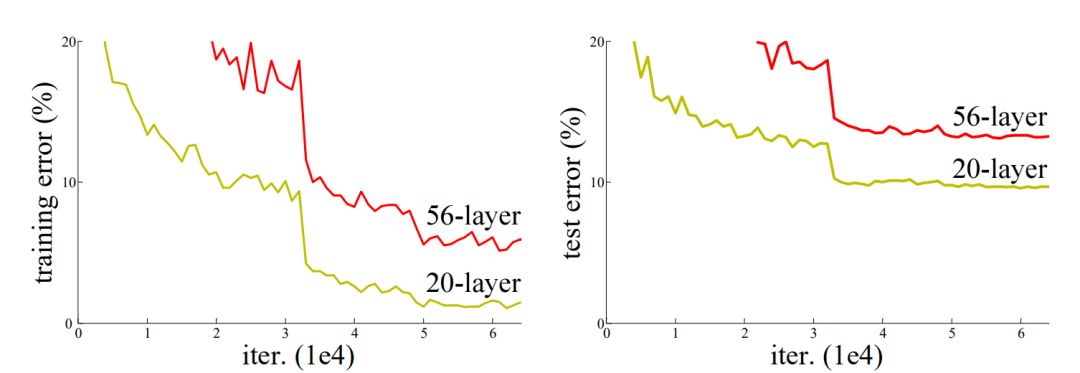
似乎,当网络层数达到一定程度时,就达到了深度学习的天花板了?
ResNet的提出,解决了这一问题。深度学习的天花板还远着呢!
对于一个浅层网络,我们想在此基础上加深网络,同时希望加深后的网络至少能力不能退化。也就是说,新加进来的几层即使不能提升网络的能力,也不要影响到加入这些新的层之前的网络的能力。
具体地,直接将添加新的层之前的网络输出与添加新的层之后的网络输出做一个加法,然后让网络自己去学习新加进来的层是否起作用,起多大的作用。
这样,如果新加进来的层不怎么起作用,那么网络最终的输出就是添加新的层之前的输出,这样就能保证网络的能力至少不会因为网络的加深而退化。
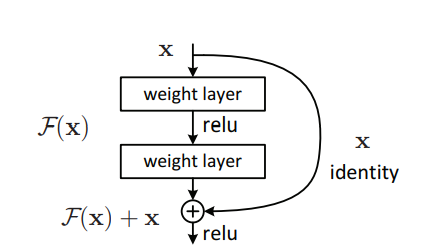
这张图描绘了上述文字所要传达的思想:
对于浅层网络的输出x
,有两个分支,一个分支直线向下,代表映射F
,它将x
映射为F(x)
;另一个分支直接将x
连接到F(x)
处,这被称之为skip connection(跳连)。这样,输出等于浅层网络的输出x
与加深后的网络输出F(x)
之和,即F(x)+x
。
根据这一思想,作者提出了几个不同版本的ResNet,它们都使用了上述结构,于是这些网络相较于其之前的网络变得更深了,提取特征的能力也变得更强了。
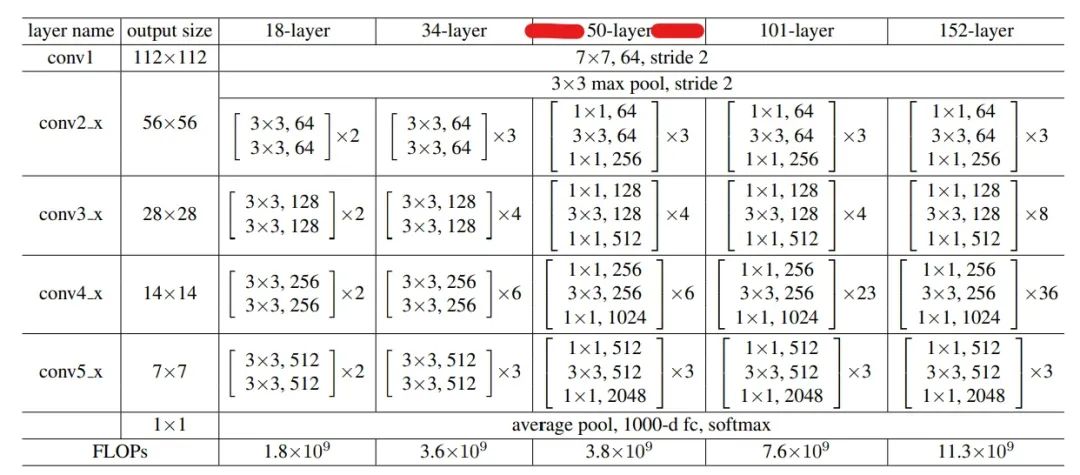
网络结构表
上述列出了5个不同版本的ResNet,主要区别在于层数的不同。
接下来,我们将实现50-layer
版本的ResNet。实现了这个以后,只需在此基础上修改少量代码,就能够实现其余版本的ResNet了。
50-layer
版本的ResNet结构图如下: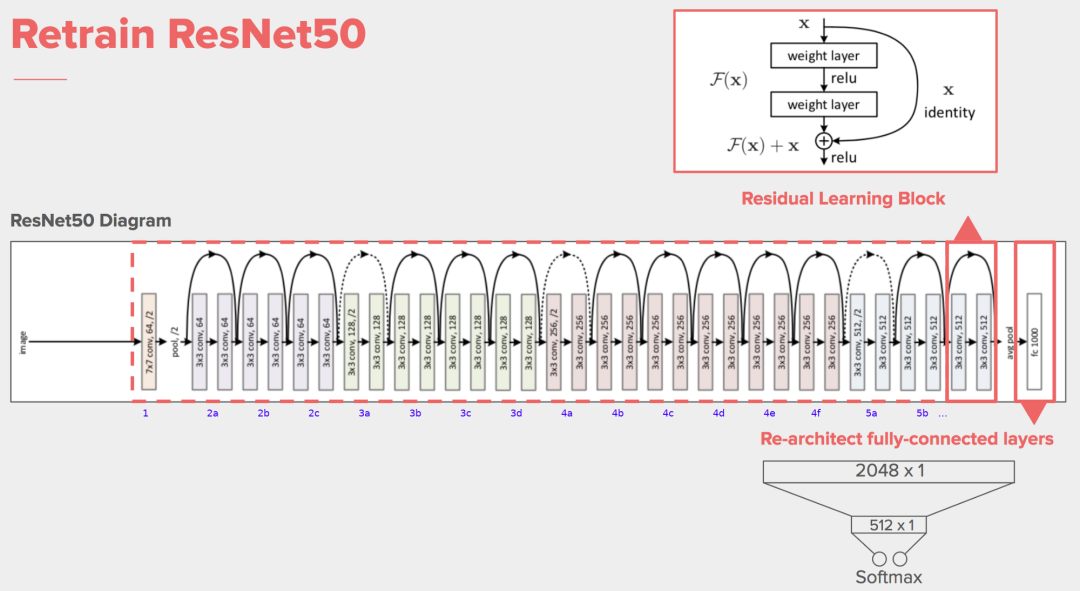
PyTorch 实现 ResNet
在上面的网络结构表中,conv1是不加skip connection
的卷积层,这个很容易实现。
而其余的conv2_x,conv3_x,conv4_,conv5_x都需要做skip connection
。它们每一个都可以看作是一个卷积块,每一个卷积块都包含着若干重复的基本块。其中的x3
,x4
等代表这个基本块重复的次数。现在来实现这个基本块。
class block(nn.Module):
#stride只针对第中间的3x3卷积,默认为1
#1x1卷积的stride始终是1,1x1卷积只改变通道数,不改变特征图尺寸
def __init__(self,in_channels,out_channels,identity_downsample=None,stride=1):
super().__init__()
self.expansion=4
self.conv1=nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=1,padding=0)#不改变尺寸
self.bn1=nn.BatchNorm2d(out_channels)
self.conv2=nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride,padding=1)# if stride=2,尺寸减半;if stride=1,尺寸不变
self.bn2=nn.BatchNorm2d(out_channels)
self.conv3=nn.Conv2d(out_channels,out_channels*self.expansion,kernel_size=1,stride=1,padding=0)#不改变尺寸
self.bn3=nn.BatchNorm2d(out_channels*self.expansion)
self.relu=nn.ReLU()
self.identity_downsample=identity_downsample
def forward(self,x):
identity=x
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.conv2(x)
x=self.bn2(x)
x=self.relu(x)
x=self.conv3(x)
x=self.bn3(x)
if self.identity_downsample is not None:
identity=self.identity_downsample(identity)
#跳连
x+=identity
x=self.relu(x)
return x
这个基本块总共包括了3个卷积层:一个3x3
卷积和两个1x1
卷积。
1x1
卷积的stride固定为1,它用于改变通道数,而不改变特征图尺寸;3x3
卷积的stride来自外部传入的参数。
代码中的expansion
用于增加通道数:从网络结构表可以看到,第二个1x1
卷积的输出通道数是其前面层的输出通道数的4倍,于是将expansion
设置为4。
identity_downsample
是一些网络层。因为有时候,浅层网络的输出经过更深的网络层映射后,得到的输出结果和浅层网络的输出结果之间shape不一致,导致无法做加法,此时就可以用identity_downsample
将浅层网络的输出identity
映射到与深层网络的输出shape一致的结果,这样就能够实现跳连了。
现在来实现完整的ResNet
:
class ResNet(nn.Module):
def __init__(self,block,layers,image_channels,num_classes):
super().__init__()
self.in_channels=64
#conv1
self.conv1=nn.Conv2d(image_channels,64,kernel_size=7,stride=2,padding=3)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU()
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
#ResNet layers: conv2_x,conv3_x,conv4_x,conv5_x
self.layer1=self._make_layer(block,layers[0],out_channels=64,stride=1)#stride=1? True ;in_channels=out_channels*4? False
self.layer2=self._make_layer(block,layers[1],out_channels=128,stride=2)#stride=1? False ;in_channels=out_channels*4? False
self.layer3=self._make_layer(block,layers[2],out_channels=256,stride=2)#stride=1? False ;in_channels=out_channels*4? False
self.layer4=self._make_layer(block,layers[3],out_channels=512,stride=2)#stride=1? False ;in_channels=out_channels*4? False
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.fc=nn.Linear(512*4,num_classes)
def forward(self,x):
# 输入x的shape: [4,3,224,224]
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
#print(x.shape)#torch.Size([4, 64, 112, 112]),经过conv1,尺寸减半
x=self.maxpool(x)
#print(x.shape)#torch.Size([4, 64, 56, 56]),经过池化,尺寸减半(严格来说,这个池化层属于conv2_i)
x=self.layer1(x)
#print(x.shape)#torch.Size([4, 256, 56, 56])#经过conv2_x,由于stride=1,尺寸不变
x=self.layer2(x)
#print(x.shape)#torch.Size([4, 512, 28, 28])#经过conv3_x,由于stride=2,尺寸减半
x=self.layer3(x)
#print(x.shape)#torch.Size([4, 1024, 14, 14])#经过conv4_x,由于stride=2,尺寸减半
x=self.layer4(x)
#print(x.shape)#torch.Size([4, 2048, 7, 7])#经过conv5_x,由于stride=2,尺寸减半
x=self.avgpool(x)
x=x.reshape(x.shape[0],-1)
x=self.fc(x)
return x
#每个layer(conv2_i,conv3_i,conv4_i,conv5_i)都有几个重复块,只需要对第一个重复块做downsample就能做跳连了,其余重复块的尺寸和通道数都不会变,因此直接跳连即可
def _make_layer(self,block,num_residual_blocks,out_channels,stride):
identity_downsample=None
layers=[]
#只有conv2_x的stride=1,其余都为2
#原始输入需要做些改变,才能做残差连接
if stride !=1 or self.in_channels!=out_channels*4:
#print('stride=1?',stride==1,';in_channels=out_channels*4? ',self.in_channels==out_channels*4)
identity_downsample=nn.Sequential(nn.Conv2d(self.in_channels,out_channels*4,kernel_size=1,stride=stride),#stride=2时,尺寸减半,做downsample才能做跳连
nn.BatchNorm2d(out_channels*4))#stride=1时,尺寸不变,但通道数变了,此时也需要做downsample,这样才能做跳连
layers.append(block(self.in_channels,out_channels,identity_downsample,stride))#stride=2,尺寸减半;或者stride=1,尺寸不变,但输出通道数变了。这也就是需要downsample的原因。
self.in_channels=out_channels*4#更改输入通道数,作为后续重复块的输入通道数,同时也是下一个卷积块的输入通道数
#其余重复块的stride采用默认值1,不改变尺寸
for i in range(num_residual_blocks-1):
layers.append(block(self.in_channels,out_channels))
return nn.Sequential(*layers)
代码有点长,我们一点一点来看。
__init__
中首先定义了conv1,它不包含跳连,因此很容易实现。接着定义了conv2_x中的max pool最大池化层(不改变通道数),也很容易。经过conv1后,输出特征图的通道数为64,这将作为后面层的输入通道数,因此self.in_channels=64
。
再后面定义的是包含跳连的conv2_x部分,conv3_x,conv4_x,conv5_x,它们每一个都可以看作是一个卷积块,分别对应layer1,layer2,layer3,layer4。每一个卷积块都包含着若干重复的基本块。这些卷积块需要借助_make_layer
方法来实现。
_make_layer
总体上做的就是将基本块重复几次,并将这些重复的块顺序连接起来。但如果细究的话,里面还是有些绕的,接下来我会尽量讲清楚。
首先把握一点:
对于每一个基本块,都会重复若干次,但只在第一个重复的基本块中进行特征图尺寸或者通道数的改变,而后续重复块只是增加深度,总体上不改变特征图尺寸和通道数(通道数内部改变,但最后都会恢复)。后续这些重复的基本块大致遵循这样的原则:最开始的1x1
卷积用于降低通道数,接下来的3x3
卷积用于提取特征而不改变特征图尺寸和通道数,最后的1x1
卷积用于恢复通道数。
第一个1x1
卷积使得通道数变小,第二个1x1
卷积使得通道数变大。因此这种基本块也有一个比较形象的名字,叫做bottleneck
,翻译过来是"瓶颈"
图源:https://capacity.com/tech-bottleneck-4-hidden-enterprise-ai-challenges/
对于conv2_x,由于其包含的max pool已经将特征图尺寸减半,因此它的3x3
卷积对应stride为1,于是不再改变特征图尺寸。它总共包含3个重复的基本块,第一个基本块的开始输入通道数为64,开始输出通道数为64,不等于开始输入通道数*4,因此需要使用identity_downsample
,此时仅仅改变通道数,以做跳连(输入通道数为64,输出通道数为64*4,所以需要将输入通道数映射为64*4=256)。第2,第3个重复的基本块的输入通道数=基本块最终输出通道数=64*4=256,特征图尺寸不变,通道数也不变,因此无需identity_downsample
,直接做跳连即可。
对于conv3_x,它的3x3
卷积的stride为2,可以将特征图尺寸减半,且开始输入通道数为256,开始输出通道数为128,不等于开始输入通道数*4,需要做identity_downsample
,将开始输入的特征图尺寸减半,并且将开始输入通道数映射为128*4=512,以做跳连。第2,第3,第4个重复的基本块输入通道数=最终输出通道数=128*4=512,特征图尺寸不变,通道数也不便,因此无需identity_downsample
,直接做跳连即可。
conv4_x,conv5_x与conv3_x的过程类似,此处就不再赘述。
将所有层串联起来,最后通过全连接层输出分类结果,这样就完成了ResNet的搭建。
现在,可以来具体构建一个版本的ResNet了,这里我们构建50-layer
的版本,只需要传入每个卷积块中基本块的重复次数,50-layer
版本的是[2,4,6,3]
。
def ResNet50(img_channels=3,num_classes=1000):
return ResNet(block,[3,4,6,3],img_channels,num_classes)
测试一下:
如果你想实现101-layer
或者152-layer
版本的ResNet,只需要改变每个卷积块中基本块的重复次数即可,比如101-layer
的是[3,4,23,3]
。
如果你想实现18-layer
或者34-layer
版本的ResNet,需要修改下基本块block,具体地,将2个1x1
卷积和1个3x3
卷积替换成2个3x3
卷积;每一个卷积块内的通道数无需做改变,因此expansion
可设置为1。
最后给出ResNet50的网络结构:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): block(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(identity_downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): block(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): block(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(layer2): Sequential(
(0): block(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(identity_downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): block(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): block(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(3): block(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(layer3): Sequential(
(0): block(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(identity_downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): block(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): block(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(3): block(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(4): block(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(5): block(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(layer4): Sequential(
(0): block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(identity_downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): block(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): block(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
参考:
[1] https://www.youtube.com/watch?v=DkNIBBBvcPs&list=PLhhyoLH6IjfxeoooqP9rhU3HJIAVAJ3Vz&index=19 [2] https://stackoverflow.com/questions/54207410/how-to-split-resnet50-model-from-top-as-well-as-from-bottom/54207766
南极Python交流群已成立,长按下方二维码添加我的微信,备注加群即可,欢迎进群学习交流(划水 )
)

原创不易,感谢点赞,分享和在看的你!
