




精选近期的10个小案例:
- 分区键妙用表达式
- 默认权限的小误解
- 普通用户禁用触发器失败
- 保存点与自动清理需搭配
- 数据库管道操作安全问题
- 多种方式灵活设置search_path
- char字段使用bpchar转型走索引
- 模拟MySQL的substring_index函数
- 迁移MySQL存储过程返回多个结果集
- PL过程中游标未关闭之前不能执行DDL
分区键妙用表达式
大量数据在一个csv格式的文件里,有三个字段a,b,c,数据文件参考如下:
$ cat data.csv
a,b,c
1,aa1001,data
2,bb1002,data
...
采用copy命令入库时需要截取b字段的前两位形成分区,是否需要借助触发器来实现呢?
PG的声明式分区表,分区键可以直接使用表达式,参考如下:
CREATE TABLE tab(
a varchar,
b varchar,
c varchar
) PARTITION BY LIST(substr(b,1,2));
创建分区
CREATE TABLE tab_aa PARTITION OF tab FOR VALUES IN('aa');
CREATE TABLE tab_bb PARTITION OF tab FOR VALUES IN('bb');
使用copy命令入库
postgres=# \copy tab from data.csv with (format 'csv',header true)
COPY 2
查询验证数据是否符合预期
postgres=# select * from tab;
a | b | c
---+--------+------
1 | aa1001 | data
2 | bb1002 | data
(2 rows)
postgres=# select * from tab_aa;
a | b | c
---+--------+------
1 | aa1001 | data
(1 row)
postgres=# select * from tab_bb;
a | b | c
---+--------+------
2 | bb1002 | data
(1 row)
默认权限的小误解
当我们想要批量管理一些对象的权限时,在14版本之前没有全局的读或写预置角色可以使用,此时需要分两次操作:
- 现有对象使用grant赋权
- 将来创建的对象使用ALTER DEFAULT设置默认权限
不过我们对默认权限进行设置时,可能会存在小误解。
使用ALTER DEFAULT设置对象默认权限时可以设置FOR ROLE以及IN SCHEMA子句,这两个子句可以默认不设置或只设置某一个。
对于默认行为我们需要关注:
- FOR ROLE如果不设置
那我们的操作实际是FOR ROLE current user,也就是当前操作用户创建的对象,这一点不容易被理解,犹如我们可能忘记操作是在哪个database下。
- IN SCHEMA如果不设置
所有schema下创建的对象都会生效,理解这一点对于revoke回收权限尤为重要。
下面是关于默认权限的一个典型案例:
先进行如下准备:
CREATE USER dba_admin SUPERUSER;
CREATE USER testuser CREATEDB;
CREATE DATABASE test OWNER testuser;
接着,使用管理用户dba_admin登录test数据库:
$ psql -U dba_admin test
顺序执行下列语句:
CREATE TABLE public.t1(id int);
GRANT usage, create ON SCHEMA public TO testuser;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT select, insert, update, delete ON TABLES TO testuser;
CREATE TABLE public.t2(id int);
CREATE VIEW v_t1 AS SELECT * FROM t1 ;
最后使用testuser用户测试t1、t2表以及v_t1视图的访问权限,结果如下:
- 无法访问t1表
- 可以访问t2表和v_t1视图
v_t1视图可以被访问,有的人可能不太理解。视图相当于表,对table的默认权限设置也适用于view,修改默认权限语句执行后的t2表和v_t1视图都可以被访问。这也是使用视图非常方便的一个特性,可以减少视图里相关对象的权限设置而允许用户有部分访问权限。
当然我们也可以更安全的控制视图v_t1的权限,让其检测基表的权限,不过这需要在15及以上的版本。使用security_invoker属性,参考设置如下:
alter view v_t1 set (security_invoker = on);
设置security_invoker属性后,v_t1视图引用的t1没有访问权限,那v_t1视图也没有权限。
普通用户禁用触发器失败
PG 14及之前的版本普通用户禁用分区表触发器时会报错无权限:
postgres=> ALTER TABLE ... DISABLE TRIGGER xxx ;
ERROR: permission denied: "xxx" is a system trigger
查看pg_trigger表可以发现分区表触发器的tgisinternal属性为true,这代表它是一个系统内部触发器。
系统内部触发器操作需要超级用户权限,所以普通用户即便是owner也不能禁用它,因此会报错。此时普通用户只能删除触发器后重建创建,或者使用超级用户来禁用。
15版本修改了这个属性,去掉了这个系统内部标识,从15开始,普通用户可以直接禁用而不需要超级用户权限。
保存点与自动清理需搭配
在psql里有一个内置的变量ON_ERROR_ROLLBACK,它允许事务块内的语句遇到错误时,错误是否可以被忽略,不回滚整个事务而继续执行。
下面左右两个窗口演示了ON_ERROR_ROLLBACK变量分别设置为off和on后,事务块内语句执行的区别。

左边窗口ON_ERROR_ROLLBACK设置为off,这是默认行为,一旦语句执行出错,将导致整个事务块被abort。通过PROMPT2提示符的%x也可以跟踪事务运行的状态:显示!表示事务失败。
右边窗口ON_ERROR_ROLLBACK设置为on,语句执行出错可以被忽略,事务继续,整个事务块可以提交成功。它的原理是对事务块里的每个语句执行前都创建一个SAVEPOINT保存点,遇到语句执行出错后ROLLBACK到失败语句的保存点。
ON_ERROR_ROLLBACK变量还可以设置为interactive,这也是更为推荐的设置值,它只对交互式会话生效,读取外部脚本文件时不起作用,演示如下:

右边窗口读取外部脚本文件时,ON_ERROR_ROLLBACK相当于off。
在session的交互式模式下设置ON_ERROR_ROLLBACK变量,遇到错误时自动ROLLBACK到之前的语句,再继续工作:
\set ON_ERROR_ROLLBACK interactive
JDBC里也有一个autosave连接可以设置,功能类似于psql里的ON_ERROR_ROLLBACK。
如果不使用autosave,应用端可能会遇到如下的错误提示信息:
current transaction is aborted, commands ignored until end of transaction block
使用autosave=always参数进行批量插入操作时,也可能遇到导入较慢的问题,这是由于创建较多的保存点引起,因此还需要搭配cleanupSavepoints=true参数及时清理释放保存点。
注意:从JDBC 42.2.6才开始支持cleanupSavepoints参数,如果使用较低版本的JDBC需要升级一下驱动。
数据库管道操作安全问题
数据库的创建及删除应该独立执行,虽然PG支持事务级的DDL,不过数据库的操作比较特殊,创建数据库时会立即触发检查点,不能在transaction里进行操作:
postgres=# START TRANSACTION;
START TRANSACTION
postgres=*# CREATE DATABASE mydb;
ERROR: CREATE DATABASE cannot run inside a transaction block
postgres=!#
数据库的创建及删除必须立即执行,不能进行事务控制。
PG在发布11.19、12.14、13.10、14.7、15.2小版本补丁时,增强了CREATE DATABASE与DROP DATABASE操作的安全性,不允许db的创建或删除与其他语句混合在一个管道里进行操作。
使用JDBC进行如下测试:
String sql = "SELECT 1;DROP DATABASE if exists mydb;";
删除db时有其他语句一起执行时会提示错误信息ERROR: DROP DATABASE cannot be executed within a pipeline
同样下面的创建db语句会提示错误信息ERROR: CREATE DATABASE cannot be executed within a pipeline
String sql = "SELECT 1;CREATE DATABASE mydb;";
如果没有其他语句,DROP DATABASE可以与CREATE DATABASE一起执行,下面的语句在JDBC可以正常执行。
String sql = "DROP DATABASE if exists mydb;CREATE DATABASE mydb;";
多种方式灵活设置search_path
PG相比MySQL多了一层逻辑schema,很多开发人员经常会遇到找不到表对象,需要设置schema。
在JDBC里可以设置currentSchema参数,参考如下:
jdbc:postgresql://ip:port/my_db?currentSchema=my_schema_name
还可使用options万金油方式设置GUC参数
jdbc:postgresql://ip:port/my_db?options=-c%20search_path=my_schema_name
不过更好的方式是在数据库服务端对业务db或者user进行search_path绑定。
alter database my_db set search_path = my_schema_name;
alter user my_user set search_path = my_schema_name;
alter user my_user in database my_db set search_path to my_schema_name;
可以使用上面三种方式中的任意一种,在db、user或者user与db的组合上进行针对性设置。
使用psql方式时,也有如下几种方式进行设置:
方式一:导入文件场景可以使用-f和-c结合
$ psql -c "set search_path to my_schema_name" -f script.sql
方式二:通过环境变量PGOPTIONS进行设置
$ env PGOPTIONS="-c search_path=my_schema_name" psql
方式三:参考libpq连接串变量语法,使用options进行设置
$ psql "dbname=postgres options=-csearch_path=my_schema_name"
char字段使用bpchar转型走索引
下面的示例创建了一个包含2个字段的表。
CREATE TABLE t(a integer, b char(10));
第一个字段包含数字,第二个字段包含ASCII字符。
INSERT INTO t(a,b)
SELECT s.id, chr((32+random()*94)::integer)
FROM generate_series(1,100000) as s(id)
ORDER BY random();
对b字段创建btree索引
CREATE INDEX on t(b);
再插入一条"PostgreSQL"关键字的数据
INSERT INTO t(a,b) values(100001,'PostgreSQL');
收集表的统计信息
ANALYZE t;
下面的查询语句从执行计划看可以走索引
postgres=> EXPLAIN (costs off) SELECT * FROM t WHERE b = 'PostgreSQL';
QUERY PLAN
-------------------------------------
Index Scan using t_b_idx on t
Index Cond: (b = 'PostgreSQL'::bpchar)
(3 rows)
但如果b字段的赋值是由字符串拼接或者有变量运算,则不会走索引:
postgres=> EXPLAIN (costs off) SELECT * FROM t WHERE b ='Postgre' || 'SQL';
QUERY PLAN
---------------------------------------
Seq Scan on t
Filter: ((b)::text = 'PostgreSQL'::text)
(2 rows)
不过可以借助类型转换,使用bpchar转型走索引:
postgres=> EXPLAIN (costs off) SELECT * FROM t WHERE b =('Postgre' || 'SQL')::bpchar;
QUERY PLAN
-------------------------------------
Index Scan using t_b_idx on t
Index Cond: (b = 'PostgreSQL'::bpchar)
(3 rows)
注:bpchar(blank-padded char)是character类型的内部别名,使用char、bpchar类型,数据库都会转换为character类型。
模拟MySQL的substring_index函数
MySQL的substring_index函数使用示例如下:
MariaDB [test]> SELECT substring_index('www.mysql.com', '.', 2);
+------------------------------------------+
| substring_index('www.mysql.com', '.', 2) |
+------------------------------------------+
| www.mysql |
+------------------------------------------+
1 row in set (0.000 sec)
MariaDB [test]> SELECT substring_index('www.mysql.com', '.', -2);
+-------------------------------------------+
| substring_index('www.mysql.com', '.', -2) |
+-------------------------------------------+
| mysql.com |
+-------------------------------------------+
1 row in set (0.000 sec)
使用MariaDB环境替代MySQL模拟。
在PG里有如下几种方式:
场景一:正向只获取一个元素,使用split_part函数实现
postgres=# SELECT split_part('www.mysql.com', '.', 1);
split_part
------------
www
(1 row)
场景二:反向只获取一个元素,使用split_part + reverse函数实现
postgres=# SELECT reverse(split_part(reverse('www.mysql.com'), '.', 1));
reverse
---------
com
(1 row)
场景三:正向获取多个元素,使用regexp_split_to_array + array_to_string函数实现
postgres=# SELECT array_to_string((regexp_split_to_array('www.mysql.com', '\.'))[:2],'.');
array_to_string
-----------------
www.mysql
(1 row)
上面数组元素边界引用使用了简写方式,只指定下边界,参考9.6版本引入的数组元素动态引用特性。
场景四:正反向获取多个元素,使用自定义函数:
CREATE OR REPLACE FUNCTION public.substring_index (
str text,
delim text,
count integer = 1,
out substring_index text
)
RETURNS text AS
$body$
BEGIN
IF count > 0 THEN
substring_index = array_to_string((string_to_array(str, delim))[:count], delim);
ELSE
DECLARE
_array TEXT[];
BEGIN
_array = string_to_array(str, delim);
substring_index = array_to_string(_array[array_length(_array, 1) + count + 1:], delim);
END;
END IF;
END;
$body$
LANGUAGE 'plpgsql'
IMMUTABLE
CALLED ON NULL INPUT
SECURITY INVOKER
COST 5;
自定义函数来源于:
https://stackoverflow.com/questions/19230584/emulating-mysqls-substring-index-in-pgsql
函数的实现利用了数组元素动态引用的特性。
迁移MySQL存储过程返回多个结果集
MySQL可以在存储过程中使用多个查询语句一次性返回多个记录集,存过示例如下:
DELIMITER //
CREATE PROCEDURE curtest()
BEGIN
SELECT * FROM tab1 WHERE ...;
SELECT * FROM tab2 WHERE ...;
END //
DELIMITER ;
迁移到PG,存过需要做一些调整,下面先创建表结构:
CREATE TABLE fiverows(id serial primary key,data text);
INSERT INTO fiverows(data)
VALUES ('one'),('two'),('three'),('four'),('five');
存过定义如下:
CREATE OR REPLACE PROCEDURE curtest(
OUT cur1 REFCURSOR,OUT cur2 REFCURSOR)
AS $$
BEGIN
OPEN cur1 FOR SELECT id,data FROM fiverows WHERE id BETWEEN 1 AND 3;
OPEN cur2 FOR SELECT id,data FROM fiverows WHERE id BETWEEN 4 AND 5;
END;
$$ LANGUAGE PLPGSQL;
接着在psql里进行测试:
postgres=> START TRANSACTION;
START TRANSACTION
postgres=*> CALL curtest(NULL,NULL);
cur1 | cur2
--------------------+--------------------
<unnamed portal 1> | <unnamed portal 2>
(1 row)
postgres=*> FETCH ALL "<unnamed portal 1>";
id | data
----+-------
1 | one
2 | two
3 | three
(3 rows)
postgres=*> FETCH ALL "<unnamed portal 2>";
id | data
----+------
4 | four
5 | five
(2 rows)
postgres=*> COMMIT;
COMMIT
在Java里进行调用测试,主要代码如下:
conn.setAutoCommit(false);
CallableStatement stmt = null;
stmt = conn.prepareCall("{call curtest(?,?)}");;
stmt.registerOutParameter(1, Types.REF_CURSOR);
stmt.registerOutParameter(2, Types.REF_CURSOR);
stmt.execute();
ResultSet resultSet = (ResultSet) stmt.getObject(1);
while(resultSet.next()){
Integer id = (Integer)resultSet.getInt(1);
String data = (String) resultSet.getString(2);
}
resultSet = (ResultSet) stmt.getObject(2);
...
上面在psql里测试时,通过FETCH命令获取数据时需要先获取游标名称,但存过返回的游标名称是自动生成的,名称可能会变, 这一点不太友好。
下面尝试改写为函数:
CREATE OR REPLACE FUNCTION curtest2(cur1 REFCURSOR,cur2 REFCURSOR)
RETURNS SETOF REFCURSOR
AS $$
BEGIN
OPEN cur1 FOR SELECT id,data FROM fiverows WHERE id BETWEEN 1 AND 3;
RETURN NEXT cur1;
OPEN cur2 FOR SELECT id,data FROM fiverows WHERE id BETWEEN 4 AND 5;
RETURN NEXT cur2;
END;
$$ LANGUAGE PLPGSQL;
再使用psql测试
START TRANSACTION;
SELECT curtest2('mycur1', 'mycur2');
FETCH ALL IN "mycur1";
FETCH ALL IN "mycur2";
COMMIT;
此时可以自定义游标的名称,FETCH调用时会更加方便。
PL过程中游标未关闭之前不能执行DDL
在PL过程中执行TRUNCATE TABLE时报错如下:
ERROR: cannot TRUNCATE "tab_cursor_trunc" because it is being used by active queries in this session
CONTEXT: SQL statement "TRUNCATE TABLE tab_cursor_trunc"
模拟表结构如下:
CREATE TABLE tab_cursor_trunc(a int);
测试代码如下:
DO $$
DECLARE
c CURSOR IS SELECT * FROM tab_cursor_trunc;
x INT;
BEGIN
OPEN c;
LOOP
FETCH c INTO x;
EXIT WHEN NOT FOUND;
END LOOP;
EXECUTE 'TRUNCATE TABLE tab_cursor_trunc';
END $$;
同一个transaction中,PL过程里的游标未关闭之前,被引用的表不能立即执行DDL操作。
游标使用完需要及时显式close,或者执行动态语句之前先commit,也能自动关闭游标。
因此该问题对应如下两种解法:
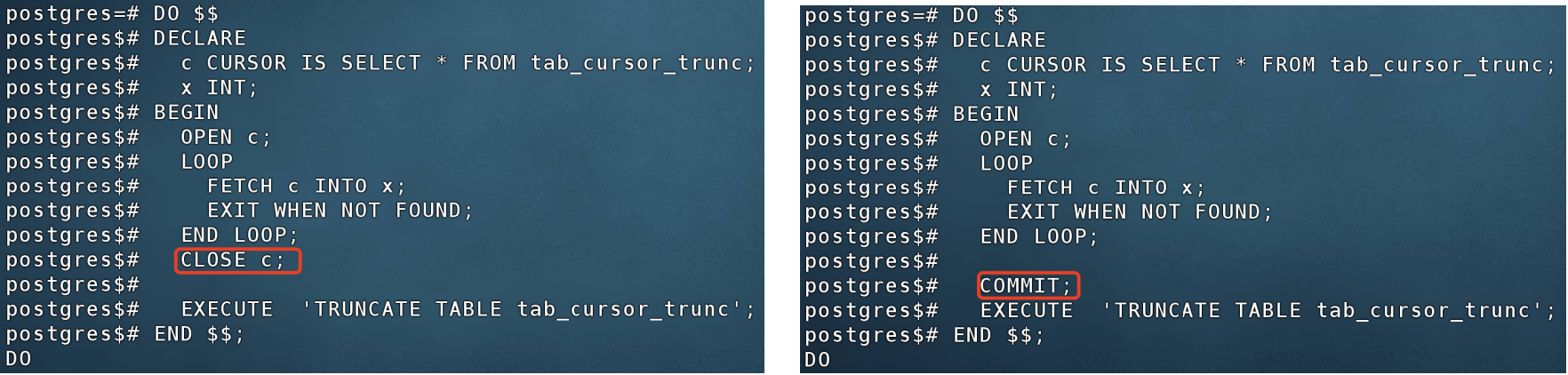
方案一:及时关闭游标
DO $$
DECLARE
c CURSOR IS SELECT * FROM tab_cursor_trunc;
x INT;
BEGIN
OPEN c;
LOOP
FETCH c INTO x;
EXIT WHEN NOT FOUND;
END LOOP;
CLOSE c;
EXECUTE 'TRUNCATE TABLE tab_cursor_trunc';
END $$;
方案二:先commit再执行DDL
DO $$
DECLARE
c CURSOR IS SELECT * FROM tab_cursor_trunc;
x INT;
BEGIN
OPEN c;
LOOP
FETCH c INTO x;
EXIT WHEN NOT FOUND;
END LOOP;
COMMIT;
EXECUTE 'TRUNCATE TABLE tab_cursor_trunc';
END $$;
本文到此结束,欢迎留言评论或指正。
