




Hudi 高效处理数据的奥秘
Hudi 文件布局
Hudi 文件布局是指其在文件系统中组织数据的方式,主要包括以下几种文件类型:
Base File: 存储经过合并后的数据,通常采用列式存储格式(如 Parquet),以便于高效查询。Base File 可能包含多个版本的数据,但通过内部结构(如版本标识符)区分不同版本。
Log File: 在某些合并策略(如 Merge-On-Read, MOR)下,用来记录每次增量写入的操作日志,包括插入、更新和删除的动作。Log File 允许在不立即更新 Base File 的情况下快速进行增量写入,延后合并过程至读取时。
Ingestion File: 初始写入或增量写入时生成的小文件,通常在后续的合并作业中会被合并到 Base File 中。
Compacted File: 经过合并操作后的文件,可能是多个 Ingestion File 合并的结果,或者是 Base File 与其他文件合并后的产物。Compaction 过程旨在减少文件数量、优化存储空间和查询性能。
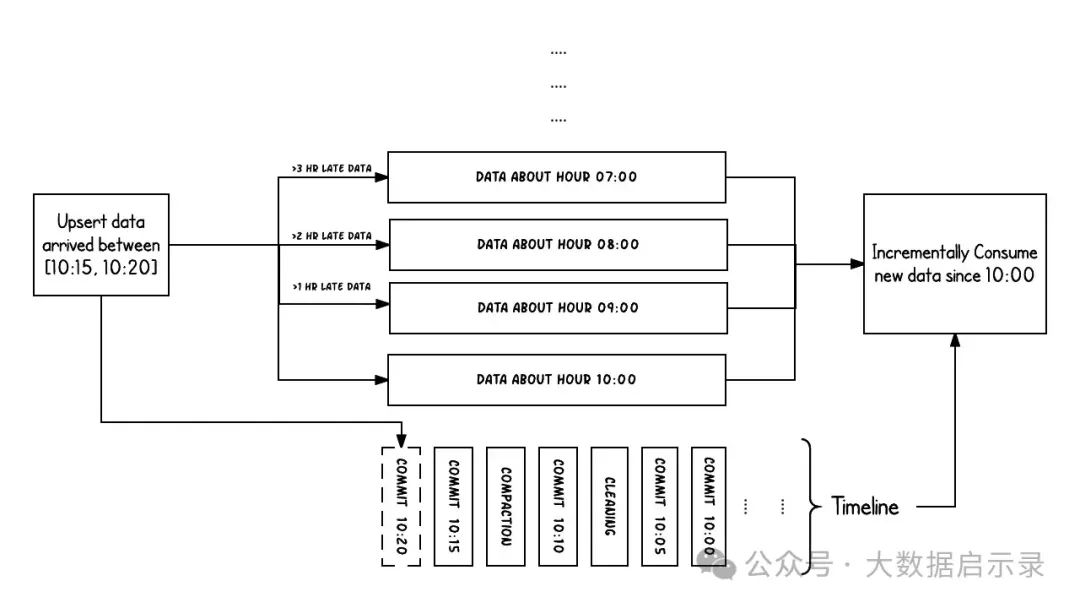
列式存储
采用列式存储格式(如 Parquet),仅加载查询所需的列,减少 I/O 和内存开销,且易于进行压缩和编码优化。
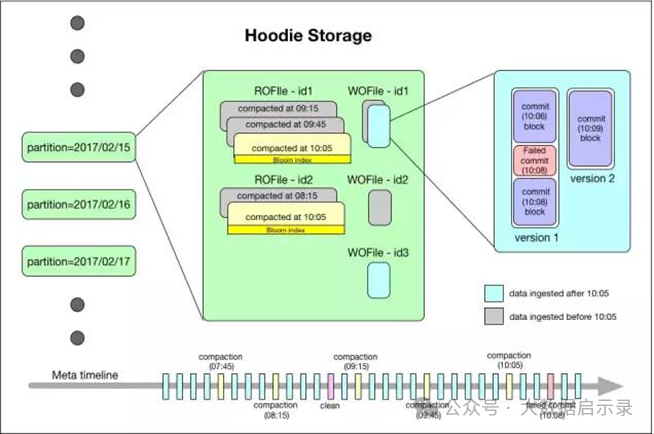
LSM (Log-Structured Merge Tree)
虽然 Hudi 不直接使用传统的 LSM 架构,但其 MOR(Merge-On-Read)模式借鉴了 LSM 的思想。在 MOR 中,数据首先被写入 Log File(类似于 LSM 的 MemTable),然后在后台异步地进行合并(类似于 LSM 的 Compaction)。这样设计的好处在于:
写放大降低:更新和删除操作只需追加写入 Log File,而非直接修改 Base File,减少了磁盘写入次数。
读放大可控:查询时需要同时读取 Base File 和 Log File,但通过高效的合并策略和索引机制可以控制读取的 Log File 数量,从而限制读放大程度。
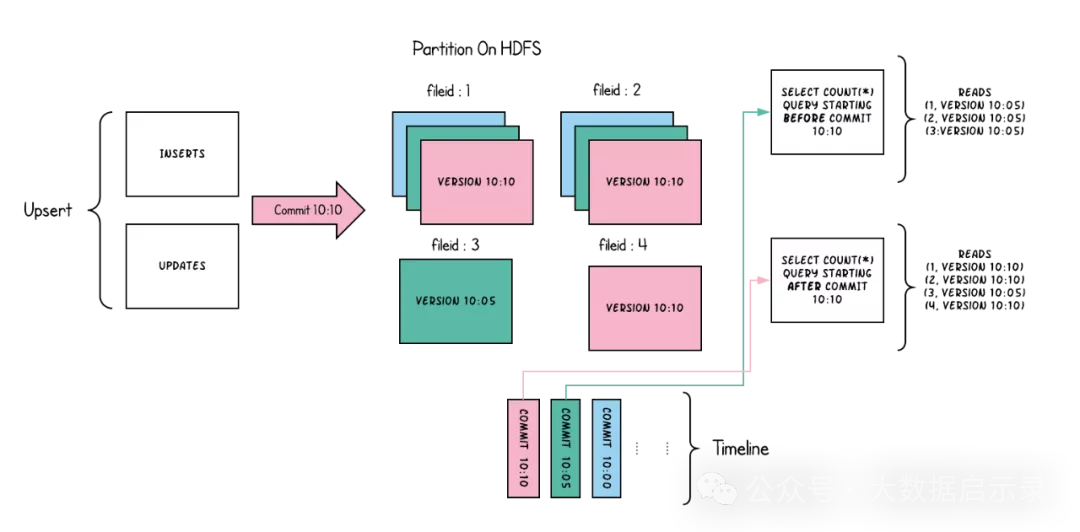
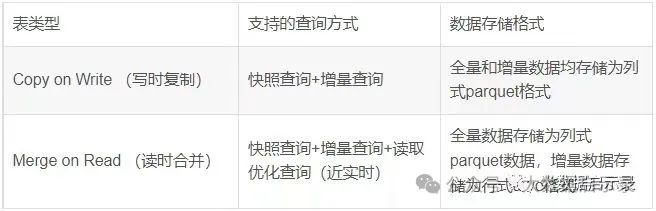
MOR (Merge-On-Read) 与 COW (Copy-On-Write)
MOR (Merge-On-Read):
写入:新数据或更新数据追加写入 Log File,不立即更新 Base File。
读取:查询时同时读取 Base File 和相关 Log File,合并结果返回给查询引擎。合并过程在内存中进行,通常利用索引来加速。
优点:写入速度快,延迟低,尤其适用于高写入频率、低查询频率或查询延迟要求不严格的场景。
缺点:读取时可能需要合并多个文件,存在一定的读取延迟和资源消耗。
COW (Copy-On-Write):
写入:新数据或更新数据触发 Base File 的部分或全部复制,生成新的 Base File 版本。
读取:查询时直接读取最新的 Base File。
优点:读取性能好,无需合并,提供近实时查询能力。
缺点:写入成本较高,尤其是频繁更新时可能导致大量的数据复制和存储空间增长。


多模态索引
Hudi通过索引机制提供高效的Upsert操作,该机制会将一个RecordKey+PartitionPath组合的方式作为唯一标识映射到一个文件ID,而且这个唯一标识和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。
Hudi 提供了多模态索引机制以加速查询:
Bloom Filter Index: 用于快速判断某个键是否存在于数据集中,减少不必要的文件扫描。
Global/Partition Index: 提供对数据全局或分区范围内的快速查找,尤其适用于点查或范围查询。
Min-Max Index: 记录每个分区或文件中数据的最小和最大值,支持数据Skipping(跳过无关数据块)。
Inverted Index: 用于高效处理基于值的查询,如全文搜索、标签匹配等。
1)、全局索引:在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。
2)、非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路。
Data Skipping
Data Skipping 是一种查询优化技术,通过利用索引信息提前过滤掉无关数据,减少查询过程中实际读取的数据量。在 Hudi 中,主要通过以下方式实现:
Min-Max Index: 查询时利用 Min-Max 索引快速判断文件内数据是否与查询条件相交,如果完全不相交,则跳过该文件。
Column Statistics: 对数值型或日期型字段统计平均值、标准差、分位数等统计信息,辅助查询优化器做出更准确的成本估算,决定是否跳过部分数据。
Sort & ZOrder
排序和 ZOrder 编码是进一步优化查询性能的手段:
Sort: 对数据按照一个或多个键进行排序,有利于范围查询和聚合操作,同时可以提高压缩效率。在 Hudi 中,可以在写入时对数据进行排序,或者在合并过程中对数据进行重新排序。
ZOrder: 一种多维排序技术,将多列数据交织在一起形成一个新的排序键。相比单一列排序,ZOrder 更能有效地减少范围查询时需要读取的数据块数量,尤其在多维分析场景下效果显著。Hudi 支持在 Compaction 过程中应用 ZOrder,对数据进行重新布局。
总结来说,Hudi 通过精心设计的文件布局、借鉴 LSM 思想的 MOR 模式、多模态索引、Data Skipping 技术以及 Sort 和
iceberg 高效处理的奥秘
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾,例如:
00000-0-root_20211212192602_8036d31b-9598-4e30-8e67-ce6c39f034da-job_1639237002345_0025-00001.parquet 就是一个数据文件。
列式存储
高效查询:只需读取查询涉及的列,显著减少 I/O 操作,尤其适用于仅需访问少量列的分析查询。 高效压缩:由于同一列内的数据类型相同,可以采用更高效的压缩算法,降低存储空间占用。 向量化执行:与现代查询引擎的向量化执行模式天然契合,能批量处理大量数据,提高CPU利用率。
LSM (Log-Structured Merge Tree)
Compaction
在 Iceberg 中,compaction 是一种数据管理操作,用于合并小文件、删除无效数据、更新元数据统计信息,并优化数据布局。Compaction 可以是手动触发或根据策略自动进行,有助于减少文件数量、提升查询性能,并保持数据集的整体健康状态。
DataSkipping
Iceberg 支持 DataSkipping 算法,允许查询引擎跳过无关数据块。这通常通过在元数据中存储数据文件的统计信息(如 min/max 值)实现,查询时可以利用这些信息进行谓词下推,避免读取不符合查询条件的数据。
Sorted Tables
Iceberg 支持创建排序表(Sorted Tables),其中数据在某个或某几个列上预排序。排序表对于涉及范围查询、窗口函数或者需要特定顺序的数据处理任务非常有利,可以进一步优化查询性能。
分区与隐藏分区(Hidden Partition)
表演化(Table Evolution)
模式演化(Schema Evolution)
ADD:向表或者嵌套结构增加新列。 Drop:从表或嵌套结构中移除列。 Rename:重命名表中或者嵌套结构中的列。 Update:将复杂结构(Struct、Map<Key,Value>,list)中的基本类型扩展类型长度,比如:tinyint修改成int。 Reorder:改变列的顺序,也可以改变嵌套结构中字段的排序顺序 。
增加列时不会从另一个列中读取已存在的数据 删除列或者嵌套结构中的字段时,不会改变任何其他列的值。 更新列或者嵌套结构中字段时,不会改变任何其他列的值。 改变列或者嵌套结构中字段顺序的时候,不会改变相关联的值。
分区演化(partition Evolution)
列顺序演化(Sort Order Evolution)
ZOrder
Parquet BloomFilter
binPack 压缩策略
CALL catalog.system.rewrite_data_files(
table => 'streamingtable',
strategy => 'binpack',
where => 'created_at between "2023-01-26 09:00:00" and "2023-01-26 09:59:59" ',
options => map(
'rewrite-job-order','bytes-asc',
'target-file-size-bytes','1073741824',
'max-file-group-size-bytes','10737418240',
'partial-progress-enabled', 'true'
)
)
MOR-Position/Equality Delete
copy on write:实现方式类似Spark的overwrite merge on read:Iceberg对merge on read的实现是写时生成DeleteFile,在读的时候将DeleteFile应用到DataFile上
(1)Position Delete
文件里记录的是哪个文件(file_path)的第几条记录(pos)需要被删除。 写Position Delete需要先读取DataFile,然后根据过滤条件判断哪些记录需要被删除,再写成Position DeleteFile。写入较慢,因为需要先进行task scan找到对应的文件,然后再写数据。 Spark的MOR目前只支持Position Delete。
(2)Equality Delete
文件里记录的是过滤条件,写入的速度快,读的速度慢,因为并不能准确的定位到文件,可能读了很多的DataFile,但是并不一定被删除,即apply的过程较慢。 Flink的CDC场景记录的就是这种方式。
Parquet Vectorized Read Decimal
import org.apache.iceberg.Table
import org.apache.iceberg.NullOrder
val table:Table = null
table.replaceSortOrder()
.asc("user_id", NullOrder.NULLS_LAST)
.desc("user_name", NullOrder.NULLS_FIRST)
// .commit()
import org.apache.iceberg.expressions.Expressions
import org.apache.iceberg.Table
val table:Table = null
// =========Partition更新==========
table.updateSpec()
// 添加分区字段user_id,且一个分区内分桶数量为10
.addField(Expressions.bucket("user_id", 10))
// 删除分区字段country
.removeField("country")
// .commit()
CALL catalog.system.rewrite_data_files(
table => 'iceberg_03',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST, name ASC NULLS FIRST'
)
文件布局
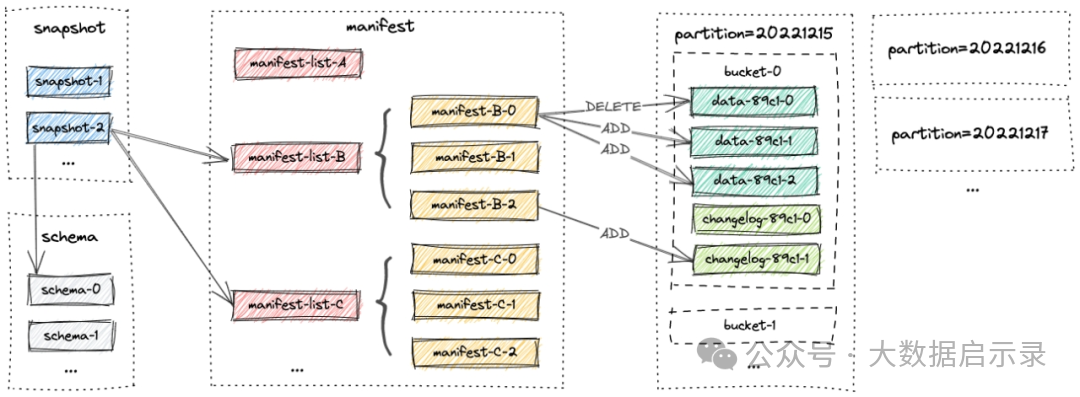
1 Snapshot Files
2 Manifest Files
3 Data Files
4 LSM Trees
4.1 Sorted Runs
4.2 Compaction
列式存储:
数据布局:Paimon 采用列式存储格式,即数据按列而非按行组织在磁盘上。这种布局方式使得在进行数据分析时,只需读取查询涉及的特定列,而不是整个数据记录,从而减少了I/O操作,显著提升了查询性能,特别是在处理大量数据的聚合查询和过滤查询时。
高效压缩:列式存储天然有利于数据压缩,因为同一列内的数据具有相同的类型和相似的值分布,可以使用针对特定数据类型的高效压缩算法(如Run-Length Encoding、Delta Encoding、Dictionary Encoding等),进一步减少存储空间需求,同时在解压时仍能保持较高的效率。
高效压缩:
压缩算法:Paimon 应用高效的压缩算法来减少数据在存储和传输过程中的空间占用。这可能包括无损压缩(如gzip、lz4等)以及专门针对列式存储优化的压缩技术,如前面提到的列专用编码。
资源节省:通过高效压缩,Paimon 不仅降低了存储成本,还减少了数据在磁盘、内存和网络之间的移动量,间接提升了整体系统的性能和效率。
DataSkipping:
查询优化:Dataskip 是一种查询优化技术,通过在数据块或索引中嵌入额外的元信息(如统计摘要、布隆过滤器等),使得查询引擎能在读取数据之前快速判断该数据块是否包含查询所需的数据。如果数据块与查询无关,就可以直接跳过,避免不必要的I/O操作,显著提升查询性能。
减少无效扫描:尤其是在处理大规模数据集时,数据跳过技术能够极大地减少无效数据扫描,使得系统能够专注于处理真正相关的数据,对于大数据分析和复杂查询尤为关键。
异步Compaction :
写入优化:在处理大量写入操作时,Paimon 可能采用异步合并(或称为Compaction)策略,将频繁的小规模写入操作合并成较少的大规模写操作。这种策略有助于减少磁盘随机写入次数,提高写入性能和磁盘寿命。
数据整理:异步合并过程还负责整理数据,如合并小文件、删除无效数据、更新索引等,以保持数据集的整洁和查询效率。由于是异步进行,不会阻塞正常的读写操作,保证了系统的响应速度和可用性。
LSM 这种原生异步的 Minor Compaction,它可以通过异步 Compaction 落到最下层,也可以在上层就发生一些 Minor 的 Compaction 和 Minor 的合并,这样压缩之后它可以保持 LSM 不会有太多的 level。保证了读取 merge read 的性能,且不会带来很大的写放大。
另外,Flink Sink 会自动清理过期的快照和文件,还可以配置分区的清理策略。所以整个 Paimon 提供了吞吐大的 Append 写,消耗低的局部 Compaction,全自动的清理以及有序的合并。所以它的写吞吐很大,merge read 不会太慢。
大规模实时更新
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:
高性能更新:LSM 的 Minor Compaction,保障写入的性能和稳定性
高性能合并:LSM 的有序合并效率非常高
高性能查询:LSM 的 基本有序性,保障查询可以基于主键做文件的 Skipping
数据表局部更新和跨分区更新
丰富的表类型
Read Optimized
Z-order
数据布局优化:通过对存储在数据湖中的多维数据(如时空数据、地理坐标等)进行Z-order编码,可以重新组织数据的物理存储布局,使得相关数据在磁盘上相邻存储,提高数据读取的局部性,从而提升查询性能。 压缩效率提升: Z-order编码后,数据的值域分布通常更连续, 有 利于采用更高效的压缩算法 。通过压缩,Paimon可以减少存储空间需求,加速数据传输。 索引构建:基于Z-order的特性,Paimon可以 构建适应Z-order编码的数据索引结构,如Z-order B-tree、Z-order R-tree、minmax等索引 ,这些索引可以直接支持高效的多维范围查询,避免全表扫描,大幅缩短查询响应时间。 负载均衡:在分布式数据湖环境中,Z-order编码有助于将多维数据均匀分布到不同的存储节点上,避免热点区域,确保查询和处理任务在集群中的均衡分布,提高系统整体处理能力和稳定性。
| |||
读/写特性 | |||
ACID事物支持 | 支持✅ | 支持✅ | 支持✅ |
Copy-On-Write( 写时复制) | 支持 ✅ | 支持✅ | 不支持 ❌ |
Merge-On-Read(读时合并) | 支持✅ | 不完备 ❌ 无法平衡查询性能,需要手动Compaction | 不完备 ❌ |
批量加载(Bulk Load) | 支持 ✅ | 不支持❌ | 不支持 ❌ |
具有记录级索引的高效合并写入 | 支持✅ | 不支持 ❌ | |
是否可以将数据就地升级到系统中而无需重写数据 | 支持✅ | 支持 ✅ | 不支持❌ |
增量查询 | 支持✅ | 不完备 ⚠️ | 支持 ✅ |
Time Travel | 支持✅ | 支持✅ | 支持✅ |
数据摄入 | 支持 ✅ | 不支持❌ | 支持 ✅ |
并发控制 | 支持 ✅ | 不完备 ⚠️ | 支持 ✅ |
Primary Key | 支持✅ | 不支持❌ | 支持✅ |
列统计和Data SKip | 支持 ✅ | 支持 ✅ | 支持 ✅ |
基于内置函数的Data Skip | 不完备⚠️ | 支持 ✅ | 不支持❌ |
Partition Evolution 分区演变 | 不支持 ❌ | 支持 ✅ | 支持✅ |
重复数据删除 | 支持 ✅ Precombine Utility Customizations 从插入中删除重复内容 | 不完备 ⚠️ | 支持 ✅ |
表服务 | |||
文件大小调整 | 支持 ✅ | 不完备 ⚠️ | 不支持❌ |
Compaction | 支持 ✅ | 不完备 ⚠️ | 支持 ✅ Dedicated Compaction |
自动清理 | 支持 ✅ | 不完备 ⚠️ | 不完备 ⚠️ |
分区清理 | 支持 ✅ | 支持 ✅ | 支持✅ |
索引管理 | 支持 ✅ | 不支持 ❌ | 支持 ✅ |
线性聚类 | 自动集群可用于性能调整、用户定义的分区器 | 不支持 ❌ | 不支持 ❌ |
Multidimensional Z-Order/Space Curve Clustering | Z-Order + Hilbert 曲线与自动异步聚类 | 不支持❌ | 不支持❌ |
模式演化 | 不完备 ⚠️ | 支持 ✅ | 支持 ✅ |
元数据可扩展 | 支持 ✅ | 不完备 ⚠️ | 不完备 ⚠️ |
平台支持 | |||
CLI | 支持 ✅ | 不支持 ❌ | 不支持 ❌ |
数据质量验证 | 支持 ✅ | 不支持 ❌ | 不支持❌ |
Pre-commit Transformers | 支持 ✅ | 不支持❌ | 不支持 ❌ |
Commit 通知 | 支持 ✅ | 不支持 ❌ | 不支持 ❌ |
失败的提交保障措施 | 支持 ✅ | 不支持 ❌ | 不支持 ❌ |
监控 | 用于自动监控的 MetricsReporter | 不支持 ❌ | 支持 ✅ |
Savepoint and Restore | 支持 ✅ 用于保存特定版本的 Savepoint 命令。 使用时间旅行版本或保存点恢复命令 | 不支持 ❌ | 不完备 ⚠️ |
生态系统支持 | |||
Apache Spark | Read + Write | Read + Write | Read + Write |
Apache Flink | Read + Write | Read + Write | Read + Write |
Presto | Read | Read + Write | Read |
Trino | Read | Read + Write | Read |
Hive | Read | Read + Write | Read |
DBT | Read + Write | 不支持 ❌ | 不支持 ❌ |
Kafka Connect | Write | 不支持 ❌ | |
Kafka | Write | 不支持 ❌ | 不支持 ❌ |
Pulsar | Write | Write | 不支持 ❌ |
Debezium | Write | Write | 不支持 ❌ |
Kyuubi | Read + Write | Read + Write | 不支持 ❌ |
ClickHouse | Read | 不支持 ❌ | 不支持 ❌ |
Apache Impala | Read + Write | Read + Write | 不支持 ❌ |
